

 作者 | 把酒问青天
作者 | 把酒问青天
导读
经过近几年的技术演进,语义模型在百度搜索场景中被广泛地应用,消耗了大量的GPU资源,模型压缩技术也随之得到大量研究和实践。通过兼顾推理性能、业务效果和迭代效率的优化目标,我们成功地将INT8量化技术大面积地应用到了搜索场景中,极大地提高了资源效能。此外,目前大模型正在被研究和应用,算力资源已经成为瓶颈,如何以更低的成本进行落地是一个非常热点的问题。基于对模型压缩技术的实践和积累,我们能够更好地助力大模型的探索和应用。
全文6287字,预计阅读时间16分钟。
01 搜索语义模型现状
ERNIE: Enhanced Representation through Knowledge Integration是百度在2019年4月的时候,基于BERT模型做的进一步优化,在中文的NLP任务上得到了state-of-the-art的结果。
近年来,ERNIE 1.0/2.0/3.0等语义模型在搜索各个重点业务场景下得到了广泛应用,包括相关性、排序等多个子方向,消耗了大量GPU资源。每个业务方向一般由多个模型组成链路来完成最终计算,整体搜索业务所涉及的模型数量多、迭代快。目前,线上全流量模型超过几百个,月级迭代近百次。语义模型的大量应用对搜索产生了巨大影响,相关业务指标对模型精度的变化非常敏感。总的来说,在模型压缩技术的工程实践中,推理性能、业务指标和迭代效率三者的优化目标应当统一考虑:
1、推理性能:采用INT8量化,ERNIE模型的性能加速平均达25%以上。其主要影响因素包含输入数据量大小(batch size、sequence length等)、隐藏节点数、非标准网络结构与算子融合优化。
2、业务指标:以某相关性场景下的ERNIE模型为例,模型输出在数值上的diff率不超过1%,在离线测试集上的评价指标达到几乎无损。
3、迭代效率:离线量化达小时级,流水线式快速产出量化模型,不阻塞模型全生命周期的相关环节(如模型多版本迭代、小流量实验、全量化推全等)。
02 模型量化简述
简而言之,模型量化就是将高精度存储(运算)转换为低精度存储(运算)的一种模型压缩技术。优势如下:
-
更少的存储开销与带宽需求:如每层权重量化后,32位比特压缩到8比特甚至更低比特,模型占用空间变小;内存访问带宽的压力自然也会变小。
-
更快的计算速度:单位时间内执行整型计算指令比浮点计算指令更多;另,英伟达安培架构芯片还有专用INT8 Tensor core。
如果我们从不同的技术角度来看待它,那么:
-
从映射函数是否是线性,分为线性和非线性。非线性量化计算较为复杂,一般主要研究线性量化,其公式如下:
Q = clip(round(R/S) + Z),其中R: high precision float number,Q:quantized integer number,s:scale,z:zero point。
-
从零点对应位置区分,线性量化又分为对称和非对称。
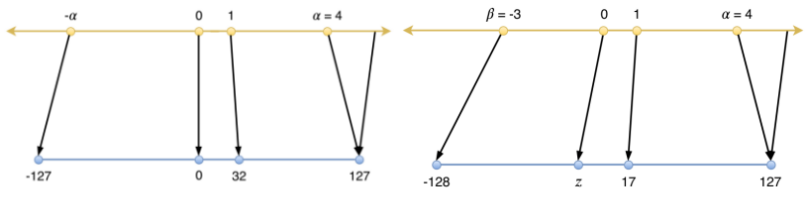
△1:对称与非对称量化
以矩阵乘为例,计算公式如下:
𝑹𝟏𝑹𝟐 = 𝒔𝟏𝑸𝟏𝒔𝟐𝑸𝟐 = 𝒔𝟏𝒔𝟐𝑸𝟏𝑸𝟐
𝑹𝟏𝑹𝟐 = 𝒔𝟏(𝑸𝟏 − 𝒛𝟏) 𝒔𝟐(𝑸𝟐 − 𝒛𝟐) = 𝒔𝟏𝒔𝟐𝑸𝟏𝑸𝟐 − 𝒔𝟏𝒔𝟐𝒛𝟐𝑸𝟏 − 𝒔𝟏𝒔𝟐𝒛𝟏𝑸𝟐 + 𝒔𝟏𝒔𝟐𝒛𝟏𝒛𝟐
在实际应用中,两者精度差异不大,对称量化在推理上更容易实现、计算更快。
-
从量化粒度上,分为逐层量化、逐组量化和逐通道量化。第一种在推理上最易实现,性能更好,一般应用在输入矩阵。第二和第三种在推理上难实现,但业务精度好,一般应用在权重矩阵。
-
从浮点矩阵中统计最大值是否截断上,分为饱和量化和非饱和量化。一般权重采用非饱和量化;输入/输出矩阵数据分布不均匀,采用饱和量化。
-
从是否参与训练上,分为训练后量化(Post-Traning Quantization,PTQ)和量化感知训练(Quantization Aware Training, QAT)。从实践上看,前者性价比最高,在精度损失可接受范围内能够快速产出量化后模型,并获得不错的性能加速;后者需要结合训练来看,往往是在PTQ造成精度损失过大时采取的进一步手段。

△图2:PTQ与QAT流程
- 从是否在推理中动态生成尺度因子,分为在线(动态)量化和离线(静态)量化。在线量化需要在推理过程中根据实际激活计算量化参数,会影响推理速度。
03 训练后量化
结合实际的应用场景,我们率先对训练后INT8量化技术进行了细致研究和大规模实践。本文中涉及到的硬件测试环境为GPU A10,CUDA 11.2,TensorRT8,工具链包括PaddlePaddle、PaddleInference、PaddleSlim等。
3.1 量化损失的精细化分析
低精度表示空间远远小于高精度表示空间,无论采用何种校准方法和校准数据,量化一定会带来不同程度上的数值误差。为了尽可能的减小误差、不影响模型业务指标,那么误差的来源和解决方案应当被全面细致地探究与分析。比如,哪些算子适合量化,每个算子量化后带来的端到端误差如何衡量,能否将误差较大的部分算子不作量化等问题。
3.1.1 量化算子的选择
通常情况下,应该优先对计算密集型算子(如mul、matmul;conv2d、depthwise_conv2d;pooling(pool2d);concat;elementwise_add等)进行量化,对非线性算子(如softmax,tanh,sigmoid,GeLU等)和非计算密集layer的算子不做量化。

△图3:ERNIE模型经过算子融合后的FP16推理耗时占比情况
在ERNIE模型推理时,利用性能分析工具(nsight等)观察会发现,FC(对应paddle中mul)相关kernel耗时占比超过70%,BGEMM(对应paddle中matmul)相关kernel占比接近10%。因此可以重点从这两类算子入手进行量化,某线上ERNIE模型(输入数据batch size=10,max sequence length=128)的测试情况如下:

△图4:ERNIE模型FP16和INT8推理时性能加速与离线指标对比
对于FC,如果按照在推理时算子融合后网络中所处的位进行划分的话,可以人为地分成4类:
-
QKV FC:推理时Q、K、V位置的3个FC会被融合在1个kernel进行计算,后续将其作为一个整体来看待。
-
multi-head att-FC:经过多头注意力计算后的线性算子。
-
FFN FC:FFN中的2个FC,第1个FC和激活函数(如relu)会融合成1个kernel,第2个FC是独立的kernel。
-
业务FC(未体现在示意图中):在主体ERNIE结构后增加若干FC进行微调,应用于不同的业务场景。推理时可能也会有算子融合操作。
之所以按照上述方式进行划分:一是划分粒度更精细,便于观察和判定量化误差来源;二是尽可能与当前的推理实现逻辑保持一致,减少不必要的复杂改动。在算子类别+数量的多重组合下,更细粒度的量化,能更好地平衡性能加速和精度。
3.1.2 量化算子的敏感性
某层算子量化不当所带来的损失会在层间逐渐传递累积,模型层数越深、宽度越大,损失可能也会越大。每层内算子的量化误差对端到端指标的影响也是不一样的。在实践中,不同业务场景或者不同模型版本之间,量化后的业务指标损失不同,不一定都能在可接受范围内。这种情况下,最直接的方法是找出造成损失较大的算子,并将其跳过不做量化。被量化的算子减少,损失也会随之降低。一个12层ERNIE模型结构中至少有12*6个FC算子,绝大部分按INT8计算,只有几个仍按FP16计算,其性能加速变化不会大,模型指标损失却能更小。通过遍历每个FC算子对模型指标的敏感性大小,就能判定哪些FC可以不做量化。
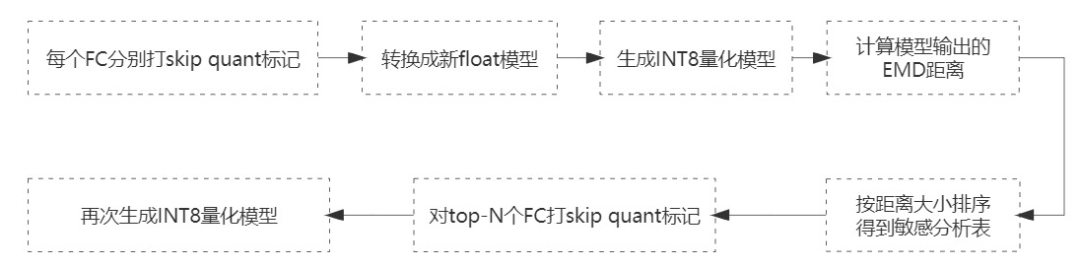
△图5:量化算子的敏感性分析方法
其中,打skip quant标记的粒度与上一节中提到的FC划分方法保持一致,比如QKV内3个FC全量化或全不量化。EMD距离是指量化前后在某个小数据集上的输出值之间的分布距离,距离越小则被认为敏感性越强。
案例1:线上某ERNIE模型经过多次微调迭代后,全FC量化后的离线评价指标下降了约1.4%。利用敏感性分析方法后,跳过前8个敏感FC后,量化模型的离线评价指标损失已经很小,性能加速仍有30%以上。

△图6:全FC量化与跳过4个FC不作量化时的推理加速与离线指标对比
案例2:线上某ERNIE模型,全FC量化后的离线评价指标下降了2%左右。只跳过前1个敏感FC后,就很好地拉回了离线评价指标。

△图7:全FC量化与跳过1个FC不做量化时的推理加速与离线指标对比
通过这个方法,我们能很好地兼顾性能加速和模型精度。经过大量实验后发现,FFN内FC往往更加敏感,对业务指标的影响更大。
3.1.3 数值统计分析
量化过程本质上是寻找合适的映射函数,让量化前后的输入/出矩阵或权重矩阵更加拟合。溯源分析,输入/出矩阵和权重矩阵分布情况从根本上决定了量化效果的好坏。对于量化效果极差的模型,一般会对相关矩阵再进行可视化地数值统计分析,这样我们能够发现是否存在大量异常点,校准算法是否适用等,进而倒推出更优的解决方法。
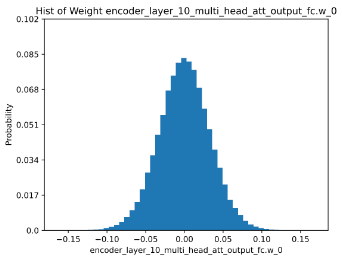
△图8:ERNIE模型某FC权重数值分布的直方图统计
3.2 校准数据增强
校准数据的优劣是决定量化损失大小的重要因素之一。
在搜索某资讯业务场景中,使用了多头输出(一个输出打分对应一个子任务)的ERNIE模型,如下:
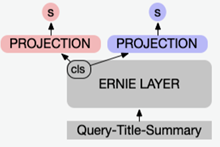
△图9:多头输出的模型结构示意图
针对这个模型进行量化时,采用了训练时部分数据作为校准集,结果发现子任务二的离线效果变得很差。通过分析模型训练微调的过程后,将子任务一和子任务二的训练数据进行等比例混合随机后再作为校准集,量化后的离线效果均得到了满足。
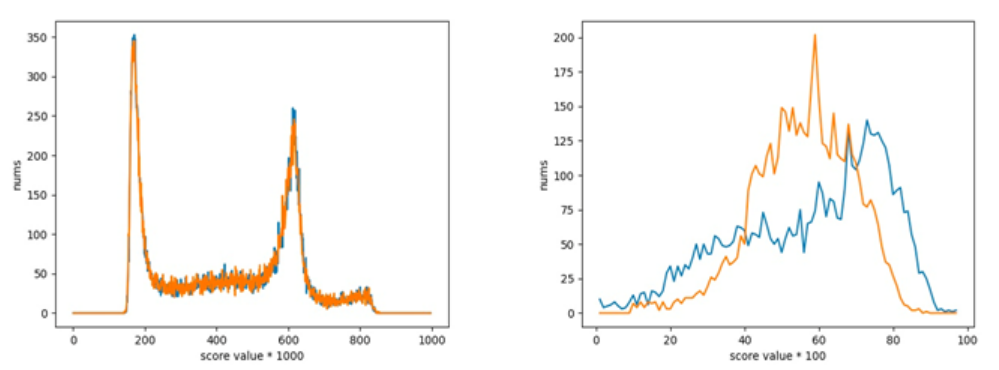
△图10:数据增强前,子任务一和子任务二在测试集上的打分分布情况
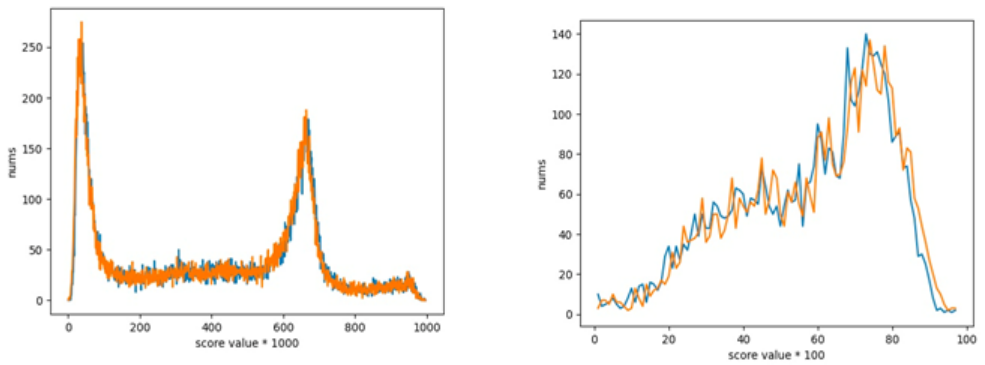
△图11:数据增强后,子任务一和子任务二在测试集上的打分分布情况
校准数据是从训练/测试数据中抽取的一个小集合,应当尽可能地保持数据分布的一致性。有些模型的离线测试集并不完善,离线指标不能很好的反应量化损失,也可能会出现离线效果与在线实验评价不一致的情况,此时可以将在线数据混入离线数据共同作为校准数据。另外,模型迭代通常是在解决bad case,校准数据中也应当注意bad case的比例。
3.3 超参自动寻优
量化包括不同的校准算法(正在使用avg、abs_max、mse、KL、hist等)、校准数据量大小(batch size/num)、是否开启偏置校准等超参,不同模型采用一组相同的量化参数,其损失变化也不同,因此超参自动寻优是必不可少的。一方面,通过自动化可以提高迭代效率;另一方面,更大的搜索空间能够获得比人工调参更优的量化后模型。
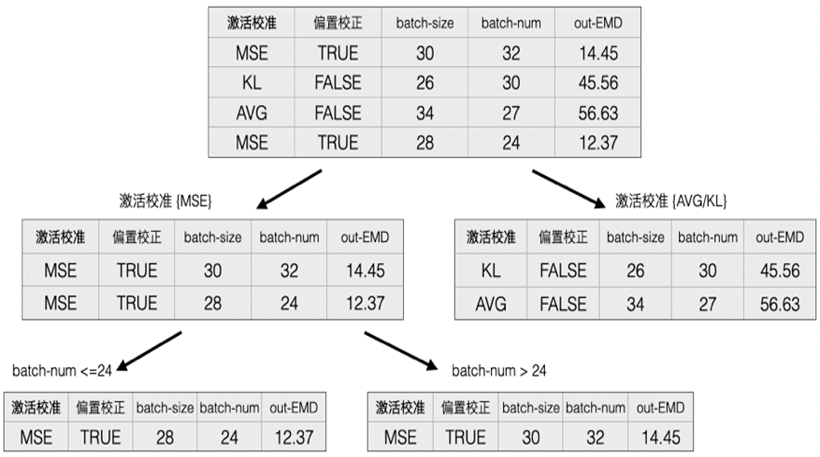
△图12:超参自动寻优方法
具体实现步骤:
-
选择初始若干组参数产出量化后模型,推理计算量化前后模型在校准集上的输出值之间的分布距离(earth mover’s distance,EMD)
-
根据超参和分布距离,构建随机树
-
随机采样若干组不同的参数组合,依次插入随机树内进行推理并计算相关距离
-
按照上一个步骤中分布距离最短的若干组参数进行实际量化
-
从第一步再循环执行,直到分布距离收敛
相比于人工调优,这种方法能够更快地搜寻到更优的量化后模型。比如:

△图13:超参自动寻优实践案例
实际上,同类型业务场景下,模型结构不会有很大变动,多次微调迭代后,超参自动寻优的参数往往会被锁定在一个小范围内。因此,我们会以类漏斗形式进行量化模型寻优,即优先在事先圈定的小范围参数内遍历量化,损失不满足要求后再进行大范围的搜索。
3.4 效果评估
搜索业务场景多种多样,离线评价方式各异。如果考虑量化方案的通用性和多维度评估能力,建设独立量化损失评价指标是必要的。类似于EMD的距离度量,打分分桶分布等方法可以作为辅助性指标来使用。

△图14:一组模型量化前后在测试集上打分/输出的数值diff情况
04 量化感知训练
相对于训练后量化,量化感知训练的模型精度更好,但流程较为复杂。一般情况下,量化感知训练作为改善训练后量化损失的进阶技术手段。
4.1 无侵入式量化训练
为了降低量化训练难度,实际上我们会采用无侵入式方法,即推理模型+训练数据。首先,对推理模型进行梯度恢复,转换成参数可训练的网络,并插入fake quant op再转换成量化后网络;然后使用量化推理模型对量化后网络进行块量化损失监督,进而降低量化损失。
4.2 全算子量化
因为精度问题,训练后量化中一般只对部分算子做量化。进一步提升推理性能,对全算子量化的话,需要和量化感知训练结合起来。全算子量化是除了mul或者matmul算子进行量化外,又增加了layer norm相关算子和中间传参过程。
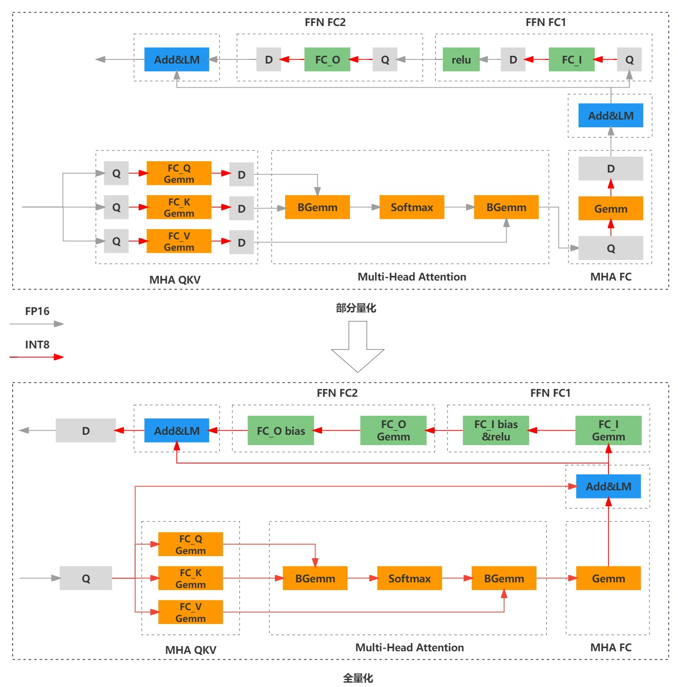
△全算子与部分算子INT8量化的模型网络示意图
全算子量化在中文场景下表现出一些特异性:
-
量化后激活分布异常值多,推理端量化累计误差变大。
-
QKV的输出激活scale值较大,推理端中间层输出为0,导致精度错误。
经过摸索,可行的解决方案如下:
-
先进行训练后量化,采用直方图校准方式,将激活scale值限制在某个较小范围内。
-
固定离线量化产出的激活scale值,再进行权重逐通道的量化训练。
在搜索相关性某ERNIE模型上,输入数据batch size=20,max sequence length=128时,具体实验情况如下:

△图16:全算子INT8量化的性能加速与离线评价实验结果
4.3 SmoothQuant
SmoothQuant是无训练、保持精度和通用的训练后量化方案,试图解决大模型(>6.7B)量化问题。简单来说,基于权重易量化、激活不易量化的事实,通过离线的数学等价变换将激活的难度迁移到权重上,将激活和权重都变得较容易量化。
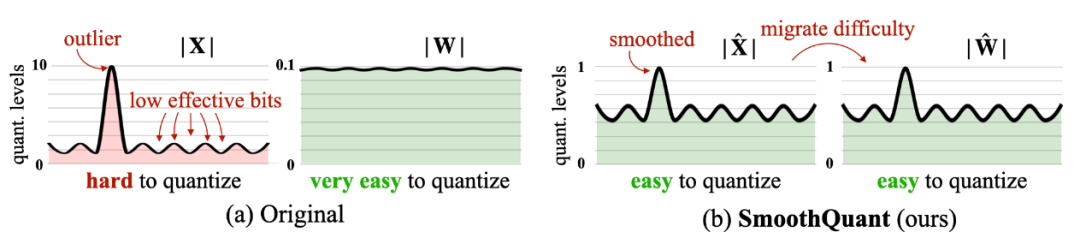
△17:SmoothQuant核心原理 [1]
在某些量化损失较大的小模型上,我们采用量化感知训练+SmoothQuant进行了相关实验,也能有不错的表现。比如:

△图18:SmoothQuant实验结果
05 展望
目前INT8量化技术已经在线上大规模应用,使整体GPU资源利用效率得到了极大提升,也支撑了更多更复杂模型的演进。
通过总结大量实践经验和技术调研,更低比特量化(如INT4)、INT8量化+Token剪枝多压缩手段融合等正在实验和落地中。
因为线上业务子方向众多,模型多&迭代快,将实践经验抽象出通用方案势在必行,建设平台化、流水线式管理模型整个生命周期能够大幅度提高效率。同时,也可以将通用方法论应用到其他模型压缩技术的工程应用上。
近期,大模型相关技术方向的研究相当火热,模型压缩也是热点之一。初步调研后,在小模型上有效的技术手段有一部分是可以直接平迁到大模型上的,有一些则需要改进。比如,大模型训练相当复杂,量化感知训练看起来不是那么经济。根据相关业界动态,PTQ-Weight Only,LLM.int8(),SmoothQuant等技术正在被研究和使用。
——END——
参考资料:
[1]https://arxiv.org/pdf/2211.10438.pdf
推荐阅读:
如何设计一个高效的分布式日志服务平台
视频与图片检索中的多模态语义匹配模型:原理、启示、应用与展望
百度离线资源治理
百度APP iOS端包体积50M优化实践(三) 资源优化
代码级质量技术之基本框架介绍
基于openfaas托管脚本的实践
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
