
Python的Beautiful Soup库和find_all()方法
在Web爬虫中,我们需要从网页中找到特定的HTML标记或属性,以便提取我们需要的数据。对于Python开发人员而言,Beautiful Soup是最流行的解析HTML和XML的库之一。该库可以让我们轻松地从HTML解析器中提取数据。
什么是Beautiful Soup?
Beautiful Soup是一种用于解析HTML和XML文档的Python包。 它可用于提取信息,例如 标题和段落,或者链接和表格 以及其他结构化数据。它创建了一个解析树,以便轻松地遍历文档的标签树,使数据提取等任务变得更加简单。
如何使用Beautiful Soup的find_all()方法?
find_all()是Beautiful Soup包中的一个方法,用于在文档中查找所有符合指定标签和属性条件的标签。例如,如果我们想要找到一个HTML页面中所有的超链接,我们可以使用以下形式的一个find_all()方法:
from bs4 import BeautifulSoup
import requests
url = 'http://www.example.com/'
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
links = soup.find_all('a')
在这个例子中,我们首先从requests库中导入了request类,以便从网址获取页面,并将其存储到res变量中。我们实例化一个BeautifulSoup对象soup,它将解析整个HTML页面。find_all()方法被用于查找所有的超链接标记。
使用find_all()在HTML中定位指定标记
我们可以使用Beautiful Soup的find_all()方法定位指定的HTML标签或元素,以便从页面中提取所需的数据。例如,如果我们要提取一篇新闻文章的所有段落,我们可以使用以下代码:
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# Find all paragraphs
paragraphs = soup.find_all('p')
# Print the text for each paragraph
for paragraph in paragraphs:
print(paragraph.text)
在这个例子中,我们使用Beautiful Soup的find_all()方法,查找HTML文档中的所有段落标记
。 随后,我们打印出每个段落标记的文本。
在HTML标记中查找特定属性
我们还可以使用find_all()方法,以定位具有特定属性的HTML标记。例如,如果我们只想查找链接标记,而且它们包含href属性和class属性,则可以使用以下代码:
from bs4 import BeautifulSoup
html_doc = """
The Dormouse's story
The Dormouse's story
Once upon a time there were three little sisters; and their names were
Elsie,
Lacie and
Tillie;
and they lived at the bottom of a well.
...
"""
soup = BeautifulSoup(html_doc, 'html.parser')
# Find all links with href and class attributes
links = soup.find_all('a', href=True, class_='sister')
# Print the href attribute for each link
for link in links:
print(link['href'])
在这个例子中,我们使用Beautiful Soup的find_all()方法查找HTML文档中的所有链接标记,其中包含href和class属性。在查找到符合筛选条件的链接后,我们打印出每个链接的href属性。
结论
Beautiful Soup与Python结合使用,是一种有效的方法来搜索解析HTML和XML文档数据,以及较大的数据集。find_all()方法允许开发人员轻松地过滤、查找和提取数据。 为此,我们应该熟练掌握find_all()方法,以便在未来的项目中更加高效地工作。
最后的最后
本文由chatgpt生成,文章没有在chatgpt生成的基础上进行任何的修改。以上只是chatgpt能力的冰山一角。作为通用的Aigc大模型,只是展现它原本的实力。
对于颠覆工作方式的ChatGPT,应该选择拥抱而不是抗拒,未来属于“会用”AI的人。
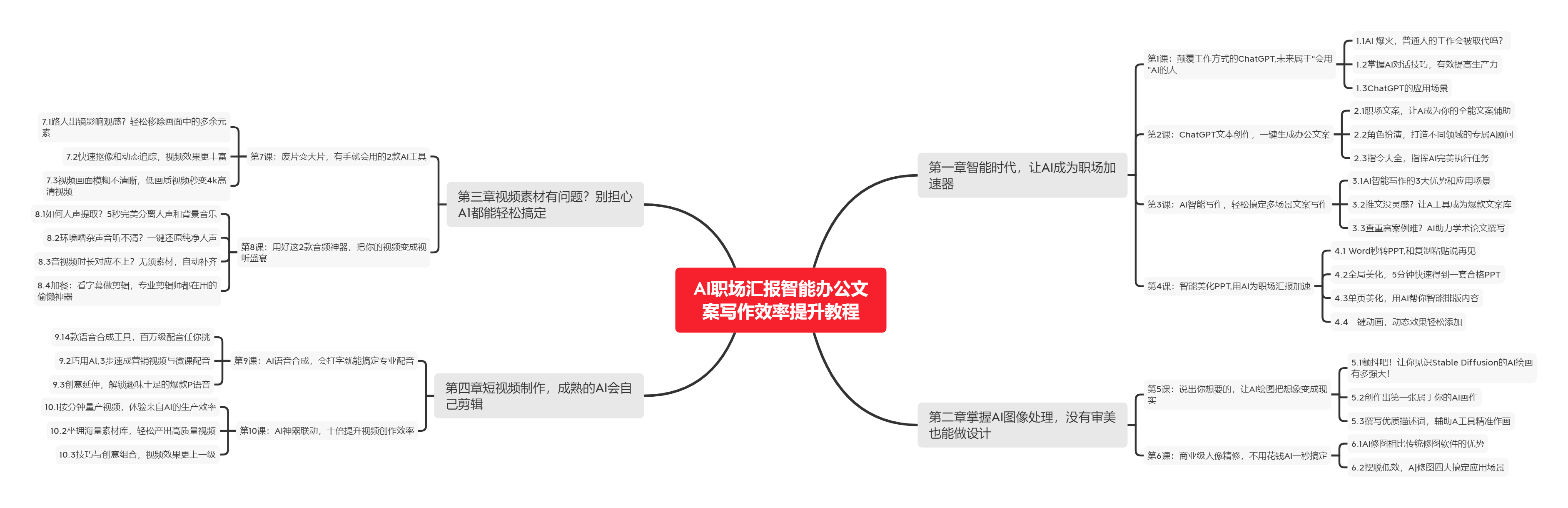
🧡AI职场汇报智能办公文案写作效率提升教程 🧡 专注于AI+职场+办公方向。
下图是课程的整体大纲

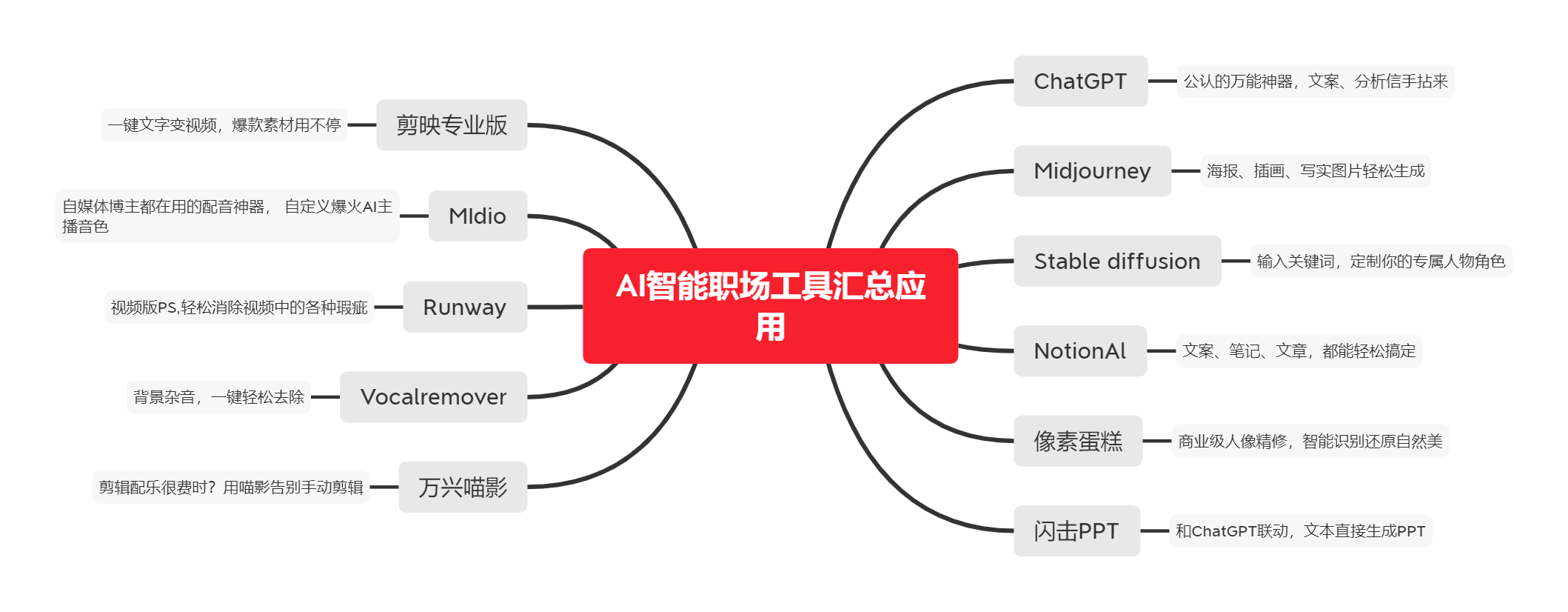
下图是AI职场汇报智能办公文案写作效率提升教程中用到的ai工具
🚀 优质教程分享 🚀
- 🎄可以学习更多的关于人工只能/Python的相关内容哦!直接点击下面颜色字体就可以跳转啦!
| 学习路线指引(点击解锁) | 知识定位 | 人群定位 |
|---|---|---|
| 🧡 AI职场汇报智能办公文案写作效率提升教程 🧡 | 进阶级 | 本课程是AI+职场+办公的完美结合,通过ChatGPT文本创作,一键生成办公文案,结合AI智能写作,轻松搞定多场景文案写作。智能美化PPT,用AI为职场汇报加速。AI神器联动,十倍提升视频创作效率 |
| 💛Python量化交易实战 💛 | 入门级 | 手把手带你打造一个易扩展、更安全、效率更高的量化交易系统 |
| 🧡 Python实战微信订餐小程序 🧡 | 进阶级 | 本课程是python flask+微信小程序的完美结合,从项目搭建到腾讯云部署上线,打造一个全栈订餐系统。 |
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
碰到这种问题,其实你的接口已经通了,但是在页面上就是访问不通过。 你可以把API请求地址单独拎出来新开个网站打开看请求是否成功,成功,但是你的项目不通。 有那么几个可能吧: 1、请求头设置错误 headers = { ‘Content-Type’: ‘ap…
