
linux进程间通信的主要方式
- 管道(Pipe):管道可在具有亲缘关系的进程间搭建通道,用于PROCESS-PROCESS之间的通信。
- 信号量(Semaphore):主要作为进程间以及同一进程不同线程之间的一种锁机制,用于进程间的同步。
- 消息队列(Message queue):消息队列是由消息的链表,存放在内核中并由消息队列标识符标识的一种通信机制。
- 共享内存(Shared memory):映射一段可以被其他进程所共享的内存区域,这段共享内存区域可供多个进程进行读写,从而交换数据。
- 套接字(Socket):更为一般的进程间通信机制,可用于不同机器上的进程间的通信。底层可以是TCP或UDP协议。
此外,Linux也支持其他的一些IPC方式,比如信号(Signal)、文件(File)、命名管道(Named pipe)等。这些IPC机制为进程间通信提供了不同的选择,它们各有特点,使用场景也不尽相同。合理选用可以提高多进程协同工作的效率。
管道(使用最简单)
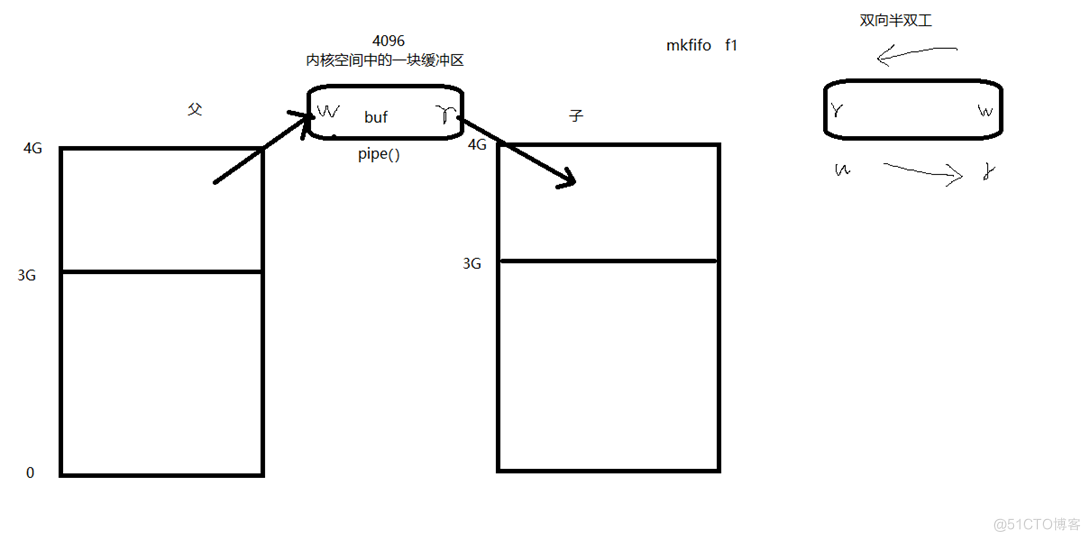
特性
- 伪文件:匿名管道在文件系统中没有对应的文件名,因此被称为伪文件。
- 管道中的数据只能一次读取:一旦数据被读取,它就不再存在于管道中。
- 数据在管道中,只能单向流动:匿名管道是单向的,数据只能从一个进程流向另一个进程。
局限性
- 自己写,不能自己读:进程无法从自己写入的管道中读取数据。
- 数据不可以反复读:一旦数据被读取,它就不再存在于管道中,因此不能反复读取。
- 半双工通信:匿名管道只能实现单向通信,而无法实现双向通信。
- 血缘关系进程间可用:匿名管道只能用于具有父子或兄弟关系的进程之间的通信。
管道缓冲区的大小
可以使用ulimit-a 命令来查看当前系统创建管道文件所对应的内核缓冲区的大小,通常为:
pipe size (512 bytes, -p) 8
也可以使用fpathconf函数,借助参数选项来查看:
头文件
unistd.h
原型
long fpathconf(int fd, int name)
参数
fd:文件描述符,指向要查询的文件的已打开的文件描述符。
name:要查询的配置变量的名称,可以是以下之一:
_PC_LINK_MAX:返回目录中允许的链接数的最大值。
_PC_NAME_MAX:返回文件名的最大长度。
_PC_PATH_MAX:返回路径名的最大长度。
_PC_PIPE_BUF:返回管道的最大原子写入长度。
_PC_CHOWN_RESTRICTED:返回是否对文件的所有者的更改受到限制。
_PC_NO_TRUNC:返回是否对文件名进行截断。
返回值
如果成功,返回相应的配置变量值。
如果出错,返回 -1,并设置全局变量 errno 来指示错误的类型。管道的优劣
优点
简单,相比信号,套接字实现进程间通信简单很多
缺点
只能单向通信,双向通信需要建立两个管道
只能用于父子,兄弟进程,该问题后来使用fifo有名管道解决FIFO 有名管道
FIFO常被称。为有名管道,以区分管道(pipe)。管道(pipe)只能用于有血缘关系的进程间,但通过FIFO,不相关进程也能进行数据交换。
FIFO时Linux基础文件类型中的一种,但FIFO文件再磁盘中没有数据块,仅仅用来表示内核中的一条通道。各进程可以打开这个通道进行读写,实际上是在读写内核通道,这样就实现了进程间的通信。
常用的有名管道创建方式有两种:
命令
mkfifo[管道名]
函数
int mkfifo(const char *pathname, mode_t mode)
一旦使用mkfifo创建服务器托管网了一个FIFO,就可以使用open打开它,常见的i/o函数都可用于fifo管道的读写行为
读管道:
1. 管道有数据:read返回实际读到的字节数。
2. 管道无数据: 1)无写端,read返回0 (类似读到文件尾)
2)有写端,read阻塞等待。
写管道:
1. 无读端: 异常终止。 (SIGPIPE导致的)
2. 有读端: 1) 管道已满, 阻塞等待
2) 管道未满, 返回写出的字节个数。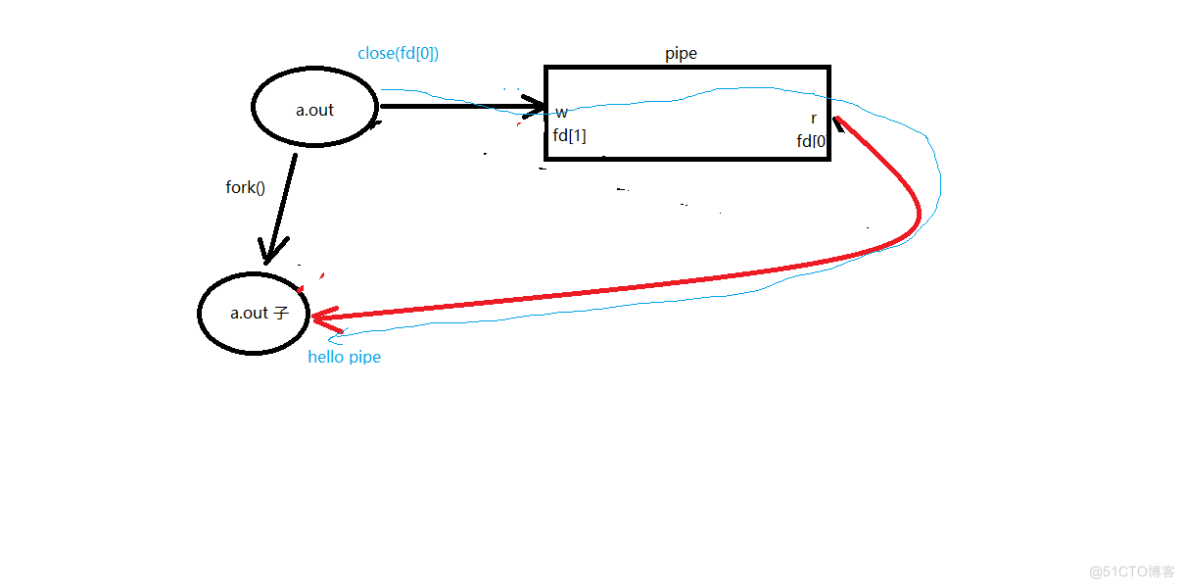
管道通信相关API函数
创建匿名管道
头文件
#include
原型
int pipe(int pipefd[2])
参数
int pipefd[2] 函数的参数是一个整型数组,用于存储文件描述符。pipefd[0] 用于读取,pipefd[1] 用于写入
返回值
成功 0
失败 -1创建有名管道
头文件
sys/types.h
sys/stat.h
原型
int mkfifo(const char *pathname, mode_t mode)
参数
const char *pathname 指向要创建的FIFO的路径名的指针
mode_t mode 指定新创建的FIFO 的权限位
返回值
成功 0
失败 -1关闭管道
头文件
#include
原型
int close(int fd)
参数
int fd 要关闭的文件描述符
返回值
成功 0
失败 -1向管道里写
头文件
#include
原型
ssize_t write(int fd, const void *buf, size_t count)
参数
int fd 管道的文件描述符
const void *buf 向管道里写入的数据
size_t count 写入数据的大小
返回值
成功 写入的字节数
失败 -1从管道里读
头文件
#include
原型
ssize_t read(int fd, void *buf, size_t count)
参数
int fd 管道的文件描述符
void *buf 用于存储读取的数据的缓冲区
size_t count 要读取的字节数
返回值
成功 读取到的字节数
失败 -1管道例程分享
匿名管道例程简介
这个例程首先创建了一个管道,然后创建了一个子进程。父进程关闭了管道的读端,然后睡眠3秒钟,接着关闭了管道的写端。子进程关闭了管道的写端,然后从管道中读取数据,打印读取的字节数,并将读取的数据写入标准输出,最后关闭了管道的读端。
匿名管道例程分享
#include
#include
#include
#include
#include
#include
void sys_err(const char *str)
{
perror(str); // 打印出错信息
exit(1); // 退出程序
}
int main(int argc, char *argv[])
{
int ret;
int fd[2]; // 用于存储管道的文件描述符
pid_t pid; // 进程ID
服务器托管网 char *str = "hello pipen"; // 要写入管道的字符串
char buf[1024]; // 用于存储从管道中读取的数据
ret = pipe(fd); // 创建管道
if (ret == -1)
sys_err("pipe error"); // 出错处理
pid = fork(); // 创建子进程
if (pid > 0) { // 父进程
close(fd[0]); // 关闭读端
sleep(3); // 等待子进程
//write(fd[1], str, strlen(str)); // 向管道写入数据
close(fd[1]); // 关闭写端
} else if (pid == 0) { // 子进程
close(fd[1]); // 关闭写端
ret = read(fd[0], buf, sizeof(buf)); // 从管道中读取数据
printf("child read ret = %dn", ret); // 打印读取的字节数
write(STDOUT_FILENO, buf, ret); // 将读取的数据写入标准输出
close(fd[0]); // 关闭读端
}
return 0;
}有名管道例程简介
第一个例程是一个读取数据的程序。它的作用是打开一个命名管道文件,并从管道的读端获取数据,然后将数据输出到标准输出。具体步骤如下:
- 程序首先检查是否提供了命令行参数,如果没有则打印提示信息并返回。
- 然后使用
open函数打开指定的命名管道文件,以只读方式打开。如果打开失败,则输出错误信息并退出程序。 - 进入一个无限循环,不断从管道文件中读取数据,并将数据输出到标准输出。在每次循环中,程序会先读取数据,然后使用
write函数将数据输出到标准输出。之后程序会休眠3秒,以放大效果。 - 最后关闭管道文件,程序结束。
第二个例程是一个写入数据的程序。它的作用是打开一个命名管道文件,并向管道中写入数据。具体步骤如下:
- 程序首先检查是否提供了命令行参数,如果没有则打印提示信息并返回。
- 然后使用
open函数打开指定的命名管道文件,以只写方式打开。如果打开失败,则输出错误信息并退出程序。 - 进入一个无限循环,不断向管道文件中写入数据。在每次循环中,程序会生成一段格式化的字符串,然后使用
write函数将该字符串写入到管道中。之后程序会休眠1秒。 - 最后关闭管道文件,程序结束。
有名管道例程分享
fifo_r.c
#include
#include
#include
#include
#include
#include
#include
void sys_err(char *str)
{
perror(str);
exit(1);
}
int main(int argc, char *argv[])
{
int fd, len;
char buf[4096];
if (argc fifo_w.c
#include
#include
#include
#include
#include
#include
#include
void sys_err(char *str)
{
perror(str);
exit(-1);
}
int main(int argc, char *argv[])
{
int fd, i;
char buf[4096];
if (argc 服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
目录 前言: 一.配置环境 1.安装clickhouse驱动 2.配置clickhouse环境 二.spark 集成clickhouse 直接上代码,里面有一些注释哦! 前言: 在大数据处理和分析领域,Spark 是一个非常强大且广泛使用的开源分布式计算框架。…
