
一、应用背景简介
ClickHouse 是 Yandex(俄罗斯最大的搜索引擎)开源的一个用于实时数据分析的基于列存储的数据库,其处理数据的速度比传统方法快 100-1000 倍。ClickHouse 的性能超过了目前市场上可比的面向列的 DBMS,每秒钟每台服务器每秒处理数亿至十亿多行和数十千兆字节的数据。它是一个用于联机分析(OLAP)的列式数据库管理系统;(OLAP是仓库型数据库,主要是读取数据,做复杂数据分析,侧重技术决策支持,提供直观简单的结果)
那 ClickHouse OLAP 适用场景有:1)读多于写;2)大宽表,读大量行但是少量列,结果集较小;3)数据批量写入,且数据不更新或少更新;4)无需事务,数据一致性要求低;5)灵活多变,不适合预先建模。
MySQL是一个关系型数据库管理系统,广泛用于各种应用程序和网站开发。MySQL容易上手和学习,已经被广泛应用于各种生产环境中有良好的稳定性和可靠性,MySQL支持事务处理,能够保证数据的完整性和一致性,适合需要复杂数据处理和事务控制的应用。
在我们应用中的使用场景来看,简单来说通常会看中了clickhouse在处理大批量数据的写入和读取分服务器托管网析方面的性能,MySQL会主要负责一些基于模型进行指标二次加工的高频查询及复杂join的查询。
二、实际应用中存在的问题
在数据相关应用处理过程中,一般会按下图的分层进行数据处理;
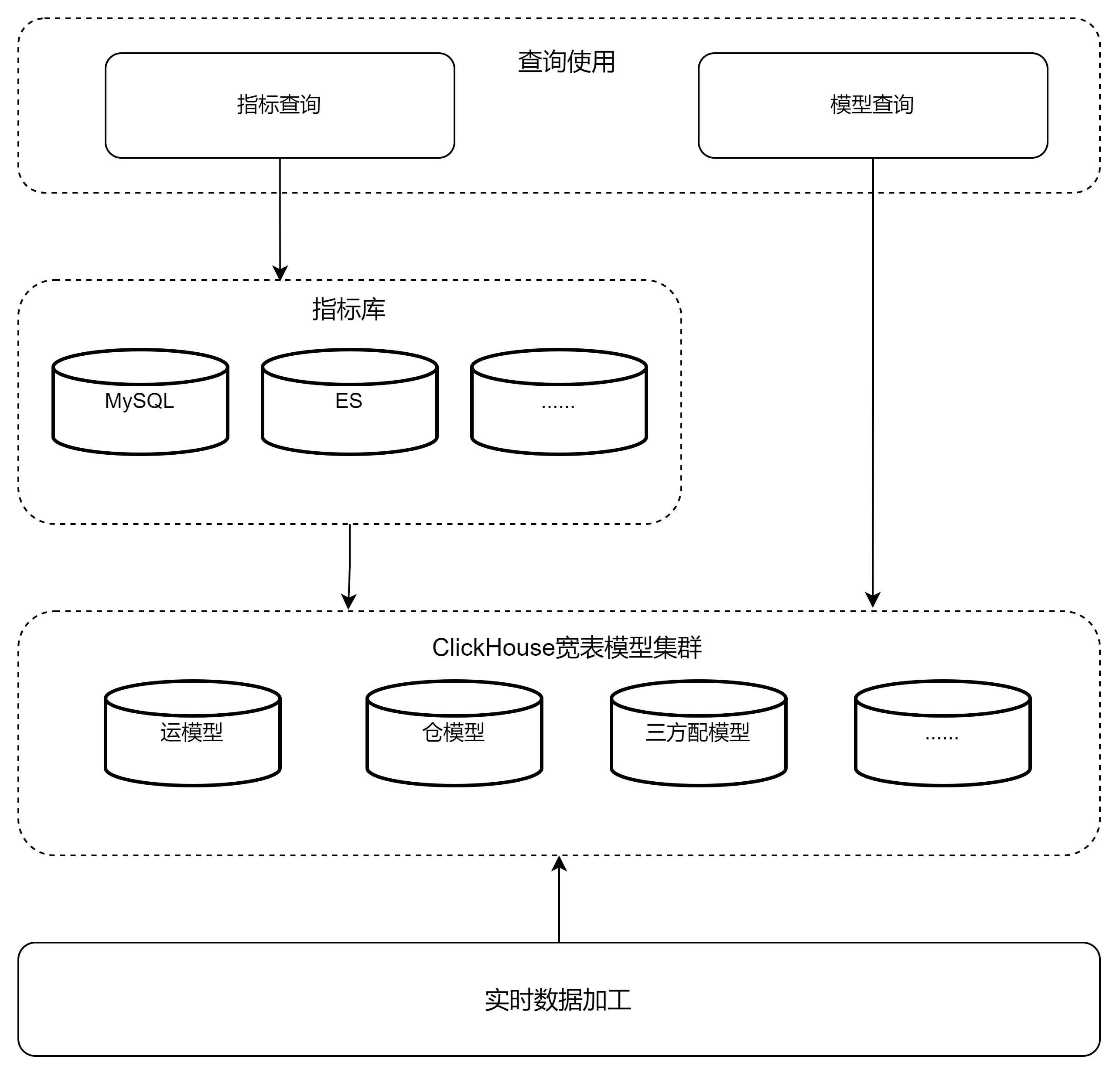
- 现有的一个实际应用场景中,会把MySQL中的数据进行全量的更替,即在新一批基于ck模型加工的数据插入MySQL库表时删除原表全量数据,来实现对于最新全量数据的刷新;
- 该处理机制因为完全不用考虑历史数据的包袱,每批次都是全量加工和替换,是一种运行简单、有效、数据加工的准确率高的机制,在小业务量场景下可以节省开发量和时间,弊端是在大业务场景下性能端会出现与之关联的多种问题;这些告警可能包括因为读写频率高引起的CPU使用率过高、因为binlog产生量过大导致的磁盘使用量告警等;负责加工的后端应用也可能也会因数据加工量过大而引发内存使用率过高的风险。
基于现有架构设计和问题背景,需要对相关的问题进行一定的调研,来探索优化的可能性;
三、几种处理方法及适配的场景分析
1. 使用数据库触发器(Trigger):在 ClickHouse 表中创建触发器,当订单数据发生变化时,触发器可以将更新操作发送到 MySQL 表中进行更新。触发器可以监视 ClickHouse 表中的 INSERT、UPDATE 和 DELETE 操作,并将相应的操作转发到 MySQL 表中。在类似于同步数据表的场景下,触发器场景比较合适,但是在面对需要高度定制化的数据加工场景下,就显得不太合适了,也不方便调试。
2.此外,也会有通过外部触发器结合消息队列的方案可以支持处理这种情况。这里边会涉及到需要监听ClickHouse的binlog记录或者CDC(Change Data Capture)流,在数据发生变化时进行解析和转发。
3.也可以在应用层面,来监听ClickHouse数据库的数据变化,并在变化发生时发送相关的消息到消息队列。例如使用Debezium库来监听ClickHouse数据库的数据变化。你可以根据自己的需求来配置连接信息、监听的表等,并在监听器中编写业务逻辑处理数据变化事件。
这几种处理方式相对来说对于处理的变化量来说是比较大的,即所有对于数据库的操作过程都会被监听端响应处理,所以如果数据变化量非常大的话,那么监听消费端的压力也会随之上升;
4. 轮询查询:Java 应用可以定期轮询查询 ClickHouse 表的变化,通过比对新的订单数据和已有的订单数据,找出有变动的数据行,并进行相应的加工处理和更新操作。这其中的关键就是采用何种方法进行比对了。
- 比对方法可以通过逐个字段的比对来筛选该行数据是否有变化,这种方法简单有效,但是服务器托管网瓶颈也比较明显:不适合处理大量数据,因为性能不算好;
- 也可以通过把数据行进行哈希算法和摘要处理,来实现更快速的字段变化的比对,这种方式相对来说会更适合处理数据量大一些的场景;
当然,处理过程并不限于查询过程,有些场景是在查询阶段并不需要筛选数据,而是基于原始模型加工完的数据结果上进行字段值比对或哈希处理,用来标记处理完的数据结果是否有变化,有变化的更新无则不处理,从而减小对指标结果数据的更新范围;
以上内容是对于所与到问题的处理方法的一个浅显分析,如果您还有什么指标加工方面好的经验,欢迎指正和交流。
作者:京东物流 陈鲲
来源:京东云开发者社区 自猿其说Tech 转载请注明来源
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
