
分页列表缓存的延迟构建
首先,先来讲一下业务场景,用户会在 APP 中去分享内容,那么假如用户分享的是美食菜谱内容,在用户分享之后,先将这个美食菜谱的内容作为 k-v 进行缓存,但是呢,其实对于用户分享的美食菜谱内容其实是会进行分页查询的,比如说别人点击进入你的主页,肯定是分页查询你主页分享的内容,那么我们就要考虑一下什么时候对这个分页查询的缓存列表进行构建呢?
那么这里列表缓存的构建时机有两个:
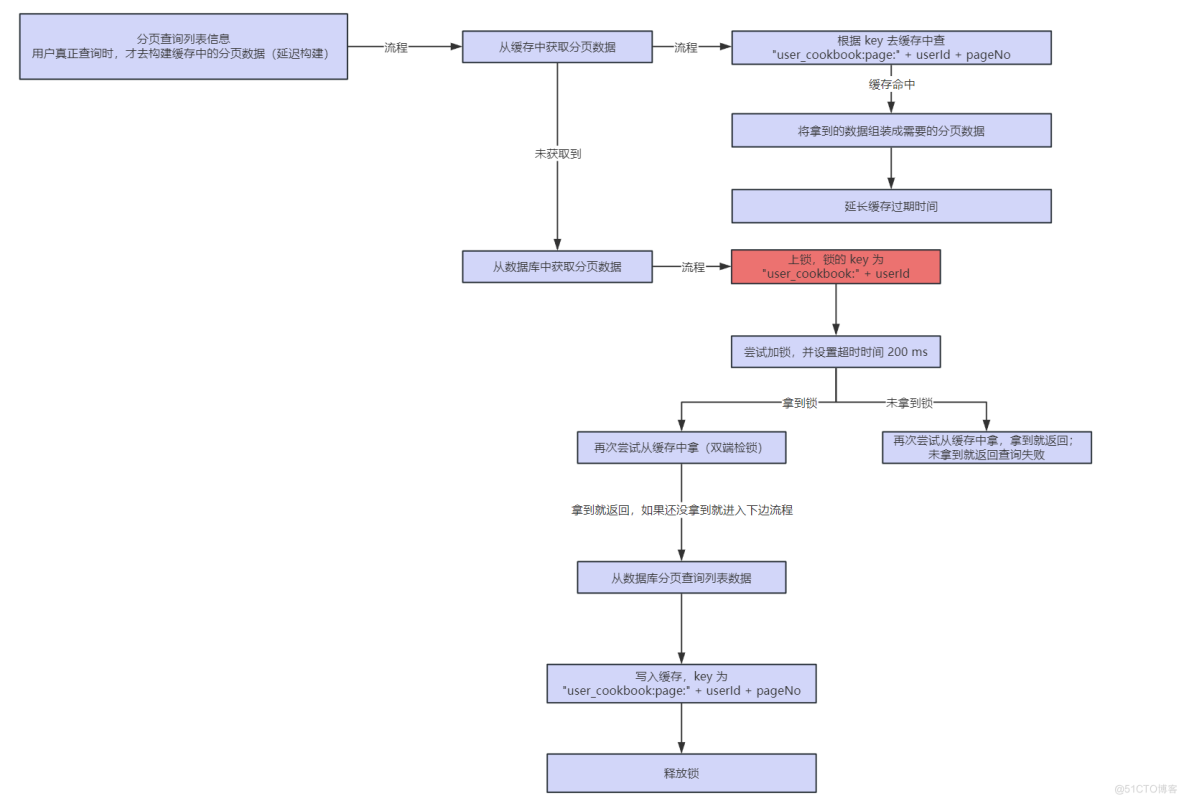
- 第一个是真正来查询该用户分享的内容列表时(延迟构建,在真正查询时再进行构建,避免占用 Redis 内存),此时先在数据库中查询分页数据,再去缓存中构建分页缓存
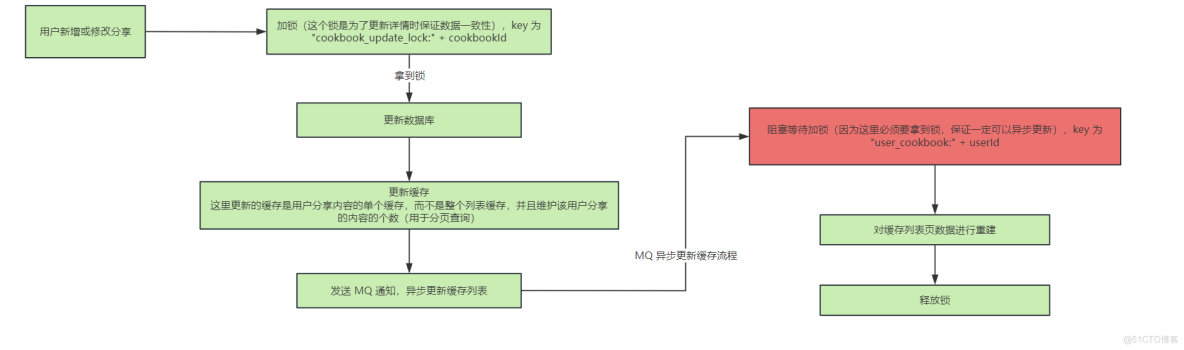
- 第二个是用户修改或者新增分享的内容时,此时通过 RocketMQ 来异步通知,去对缓存中的分页列表进行重新的构建
那么可以来看一种并发下的极端情况:
当用户 A 新增分享的时候,另一个用户 B 此时正好来查询用户 A 的分享列表,用户 B 线程先去缓存中查询,发现没有,再去数据库中查询用户 A 的分享列表,此时 B 拿到了 A 新增分享之前的旧数据,此时如果用户 A 新增分享并落库,并且去缓存中对用户 A 的列表缓存进行重建,那么此时缓存列表中是用户 A 的最新数据,但是此时用户 B 的线程在数据库中已经查到了用户 A 的旧数据,用户 B 的线程继续执行,将用户 A 的旧数据给放入到列表缓存中,覆盖掉了用户 A 更新的缓存,那么此时就会导致缓服务器托管网存数据库不一致
解决办法就是在这两处构建缓存的时候都加上分布式锁即可,加分布式锁的地方在下图标红的位置:
查询用户列表时,分页缓存的构建流程:
用户新增或修改分享时,对分页缓存的重建流程:
那么同样的,既然在查询的时候加了锁,就还存在冷门用户突然火了的情况,大量用户线程来查询这个用户的分享列表,发现缓存中没有,去竞争这把锁,解决方法仍然为:将大量用户线程竞争锁由串行改为并行
解决方案就是,将查询用户的分享列表获取锁的地方添加一个获取锁的超时时间,这样大量用户线程阻塞在获取锁的地方,如果超过这个锁获取的超时时间,就直接返回查询失败,只要有一个用户线程将这个列表加载到了缓存当中,那么其他用户再次查询的话,就直接从缓存中查了,不会再大量阻塞在获取锁的地方
那么上边只说了整体的分页列表缓存的延迟构建的整体的一个流程,那么具体的分页列表缓存是如何来进行构建的呢?key 是如何进行设计的呢?
分页列表的缓存的 key 为:user_cookbook:page:{userId}:{pageNo},主要有 userId 和 pageNo 来进行控制,pageNo 的话表示查询的是缓存中的第几页
那么在数据库中直接根据 pageNo 和 pageSize 查询到分页数据,再将分页数据转为 JSON 串存入 Redis 缓存当中,用户需要查询哪一页的数据直接根据 pageNo 来进行控制即可
总结
- 在查询时,给获取锁添加超时时间,避免突然大量请求访问冷门数据,大量线程阻塞等待锁
- 如果多处操作缓存和数据库,要注意加同一把锁,来保证数据的一致性
- 在 MQ 的通知中,加锁的话,注意需要阻塞等待加锁,而不是拿不到锁就退出,因为 MQ 中的通知需要修改缓存,收到通知后是一定要修改的
- 分页缓存的 key 的设计:
user_cookbook:page:{userId}:{pageNo} - 对于数据库中不存在的数据,在 Redis 中使用 服务器托管网
{}来进行缓存,避免缓存穿透,空缓存就可以将过期时间设置的短一些,避免大量空缓存占用缓存空间
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
引言: 在数字时代,数据被认为是新的石油,而大数据则是数据世界的燃料。大数据分析正在改变我们的生活方式、业务运营和决策制定。本文将深入探讨大数据的概念、应用、技术和挑战,以及它对不同领域的影响。 1. 什么是大数据? 大数据是指规模庞大、多样性、高速度和复杂性…
