
1.背景
我们所在的效能团队,对这个需求最原始的来源是在一次“小项目”的评审中,增长的业务同学提出来的,目的在于保障前端页面稳定性的同时减少大量测试人力的回归成本。页面稳定性提升,之前迭代遇见过一些C端的线上问题,比如页面白屏、页面报错等不同类型的问题,严重影响了用户体验,需要针对这一专项进行优化,提高用户体验。回归投入成本大,H5页面巡检在用户稳定性提升上具有较大意义,在每个迭代大概有近十万个页面需要巡检(比如双旦、情人节等大促活动期间则更多)。
> 本文中的部分技术调研、演示代码块、疑惑问题等,均由ChatGPT提供
2.建设
开局先放一张平台完整的使用流程图(跟着箭头的顺序)
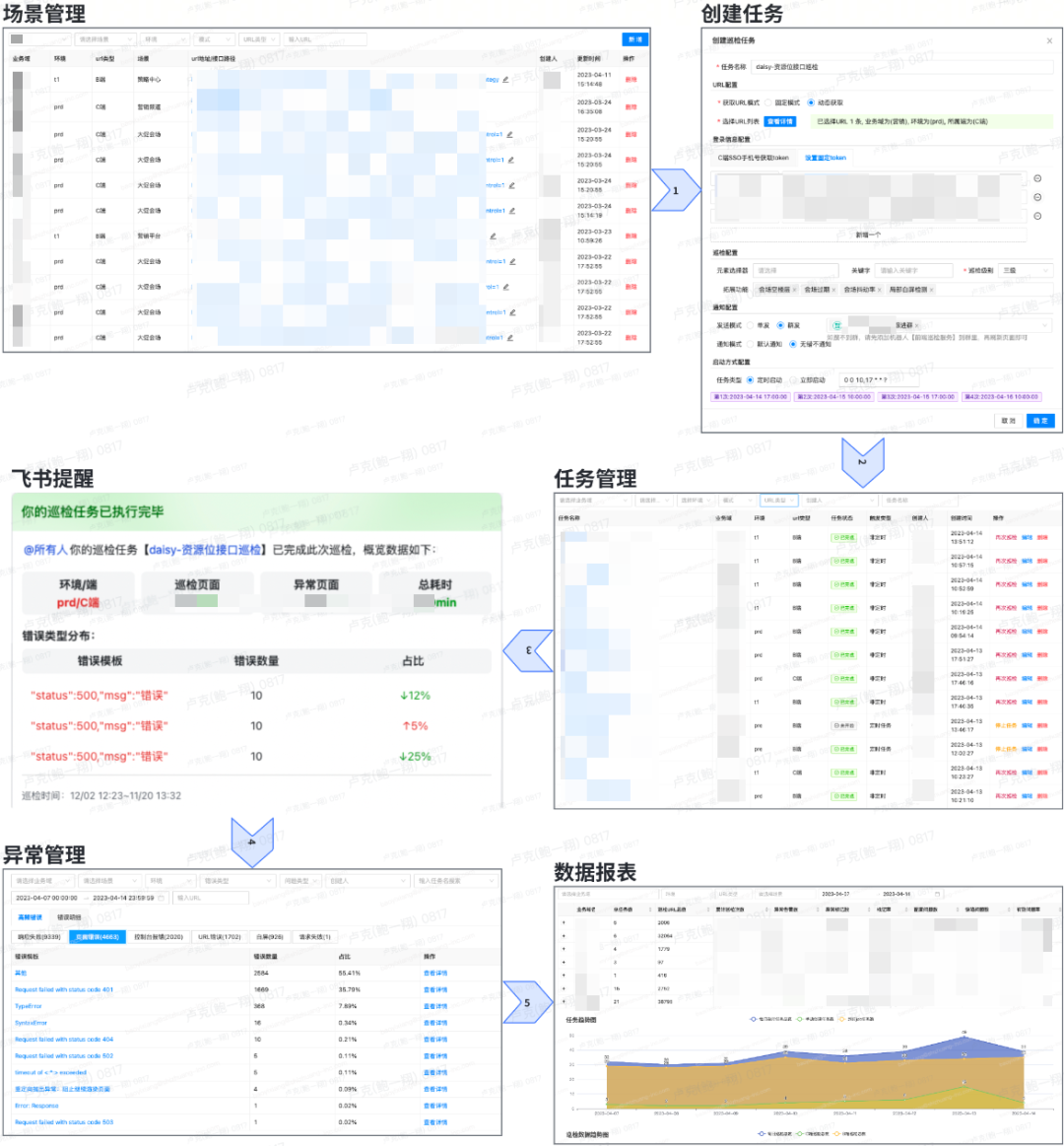
部门内以“小项目”的形式立项之后,我们就开始了巡检平台的建设。
首先是在业务目标方面
增长的测试同学作为业务方,给我们这个项目定了“三高”目标,大概可以概括为三高:“平台使用效率高”、“巡检执行效率高”、“告警准确性高”。同时也很贴心的给我们列举了大概需要的功能模块一期巡检平台功能设计PRD
其次是在技术实现方面
我们当时备选的基础语言语言有Python和Node,Python是我们比较熟悉的,在当时项目时间比较紧张的背景下Python看来是一个比较不错的选择;但考虑到要做的是前端巡检,Node本身是一个基于Chrome V8引擎的JavaScript运行时,可以让JavaScript在服务器端运行,在这个项目中的表现应该会比Python更友好一些,于是最终选择了Node。
自动化测试工具方面,我认为仁者见仁智者见智,能为之所用的就是好工具,剩下的就是过程中“佛挡杀佛,鬼挡杀鬼”式地解决种种问题就是了。我挑选了几个市面上常见的,问了下ChatGpt的意见,给大家参考。

2.1 性能
在原先回归2000个页面,要等1个多小时才知道结果,这显然是不能满足“巡检执行效率高”这个目标的;于是我们从架构上做了优化,最终巡检性能从0.4个页面/秒提升到4个页面/秒。
优化前后的两个方案对比流程图如下
-
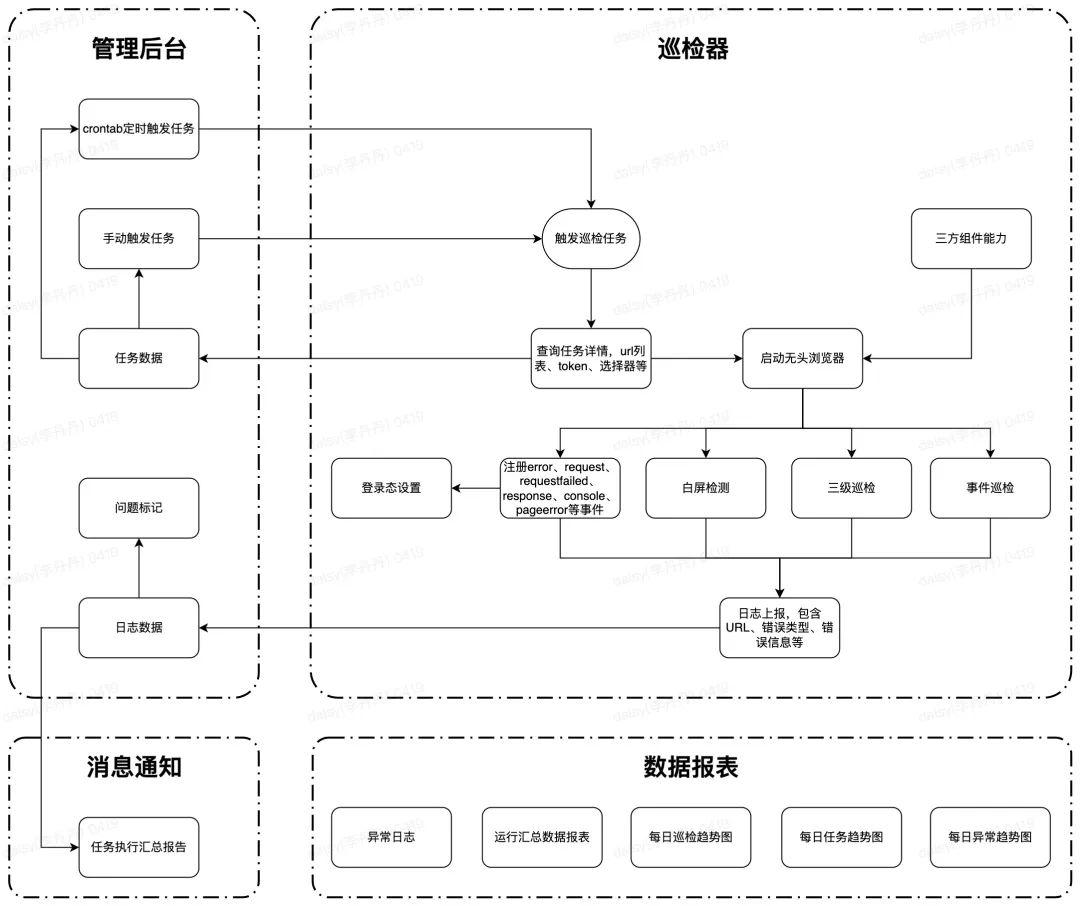
方案一的主要流程如下:
- 任务启动模式:支持手动、定时两种
- 下发任务:由巡检后端调用巡检器服务进行任务执行,负载模式有ingress内部处理(轮询)
- 日志上报:巡检完成后上传日志,后台更新任务状态
-
方案二的主要流程如下:
- 任务启动模式:支持手动、定时两种
- 任务拆解:将任务关联的url按一定大小拆分为一批子任务。比如一个任务有1000个url,每个子任务分配50个url,则会拆分为20个子任务,插入到子任务表
- 巡检器领取任务:每个pod循环调用领取任务接口,任务调度中心根据先进先出、任务状态等逻辑返回子任务,未领取到任务则进入下一次循环
- 日志上报:巡检完成后上传日志,后台更新子任务状态,当某个批次的子任务全部执行完成后认为当次任务执行完成
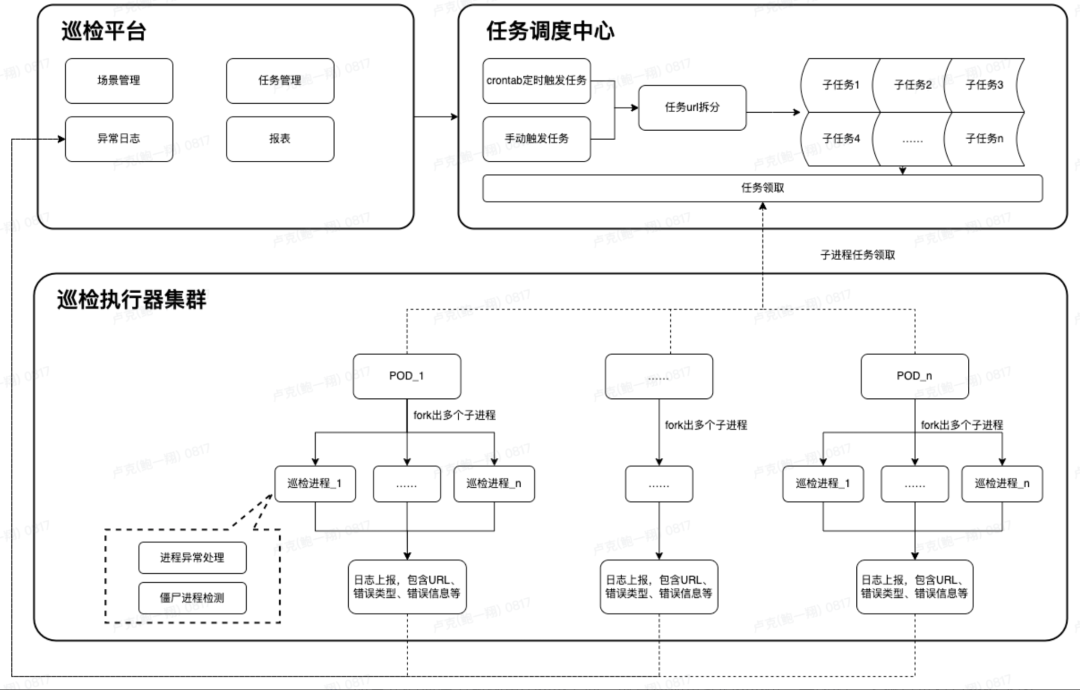
“方案二”相比于“方案一”,在以下4个方面带来了改善
-
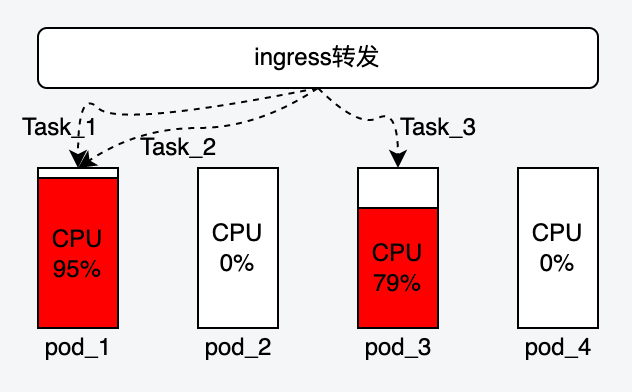
解决pod单点负载过高的问题
- 由于“方案一”是由后端直接发起的任务,这个任务具体会由哪个巡检器处理是未知的,完全交给容器的ingress负载均衡策略,容易造成某个pod被分配多个任务导致CPU飙升,其余pod却是空闲情况;改成执行器主动获取之后就可以把每个资源都利用起来
-
巡检任务繁重时可动态扩容
- 如果我们把压力放到单个pod上面,就算增加再多的pod也是无效的,大概意思有点类似下图
-
多消费者模式加速任务执行
- 理论上来说,只要我们多起几个pod,就可以更快速地把任务队列中的待巡检URL执行完成
-
巡检异常支持“断点续传”
- 如下图,如果因为巡检器故障、容器重新部署、网络等原因导致SUB_TASK_4执行异常之后,后台会有重试逻辑允许该任务可以被其他pod再次消费,已经执行的不会再次被执行

这样做了之后,从巡检耗时、资源使用情况来看,都还算比较合理

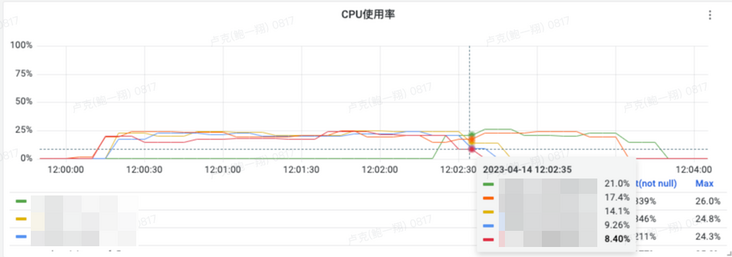
2.2 稳定性
我们想压榨单个pod更大的资源进行巡检任务处理,于是使用了一个主进程+多个子进程的方式来做,这样在必要的时候,就可以在单pod上并行处理。但是在过程中发现了2个问题:
- 子进程异常退出导致任务“无疾而终”
-
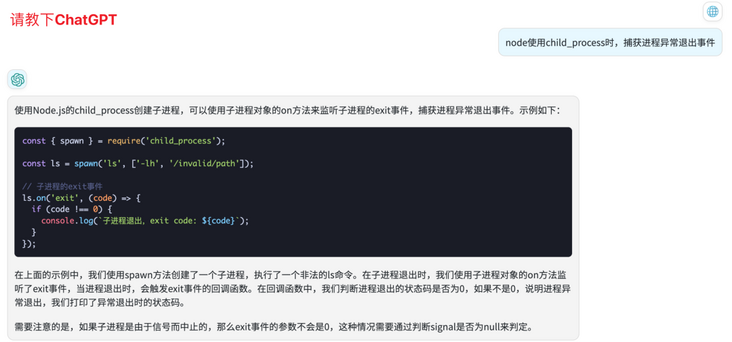
- 因为我对Node.js并不是很熟悉,查阅了资料之后发现通过
child_process起子进程之后,主进程是可以通过事件注册捕获异常的。通过这个方法我们捕获到了70%的进程异常退出事件,并将该事件上报给后端,做后续的处理
- 因为我对Node.js并不是很熟悉,查阅了资料之后发现通过
-
子进程还是有30%的概率会异常退出
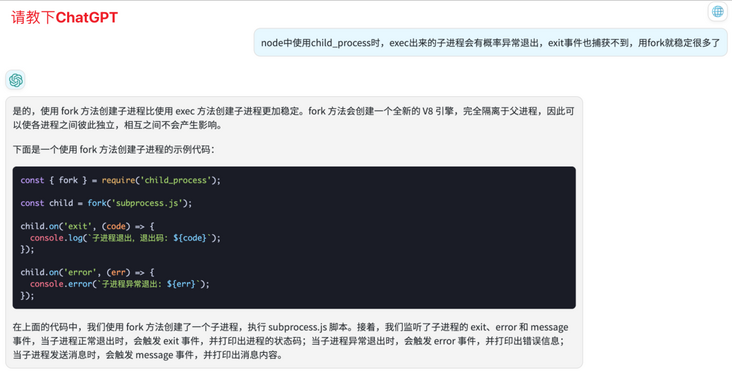
- 上面说到捕获了70%的异常,剩下30%的异常退出更加隐蔽;表现就是毫无任何征兆的情况下,子进程就是会异常挂掉,
top看了服务器进程也没有发现zombie进程之类的,/var/logs/message下也没有任何异常日志 - 甚至想过要不要在父子进程之间建立一个通信管道,或者加入
supervisor进行保活。最终凑巧使用fork解决了这个问题
- 上面说到捕获了70%的异常,剩下30%的异常退出更加隐蔽;表现就是毫无任何征兆的情况下,子进程就是会异常挂掉,
3.合作
3.1 巡检组件
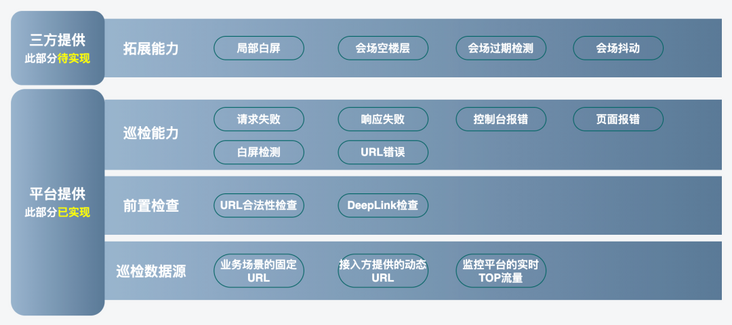
我们相信个人的能力是有局限性的,开源+合作才是正确的思路。所以在该项目中,我们除了提供平台的架构和基础异常检测服务,还和前端平台合作,把巡检器的巡检能力做了丰富,比如会场抖动检测、局部白屏等都是前端平台贡献的组件。
巡检能力根据提供方,可分为2部分
- 平台提供:由效能平台提供常用的巡检能力
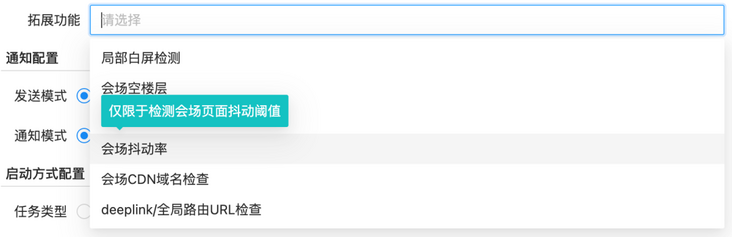
- 三方提供:由前端平台提供定制化巡检能力,接入巡检平台的巡检器中,目前已完成了6个巡检组件的接入
巡检能力Git demo、平台适配及合作文档巡检功能拓展接入方案和demo
4.体验
4.1 接入成本
此处感谢我们的业务方(增长域的质量同学),为我们的项目运营和接入提供了很大的支持,梳理了规范的接入手册和运营机制,最终将一个新平台的接入成本降低到很低。
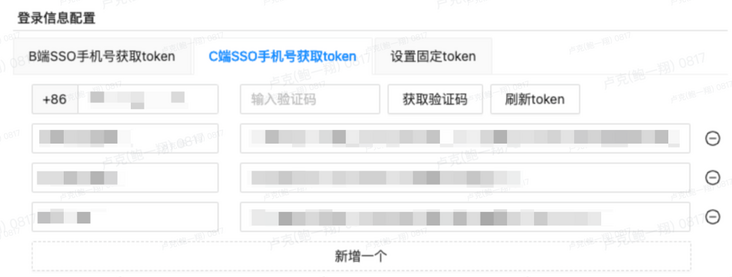
由于B端页面很多是需要登录的,比如stark商家后台、策略平台、工单后台等,为了B端巡检的接入成本更低一下,我们还支持了在任务创建时使用SSO手机号的方式动态获取登录token,更复杂的登录场景也支持设置“固定Token”,以此兼容所有场景
4.2 时间成本
迭代页面回归使用巡检平台解决,以往100个页面需要60分钟,现在仅需花10分钟跟进巡检报告,主要的时间可以用于其他质保工作。
4.3 排错成本
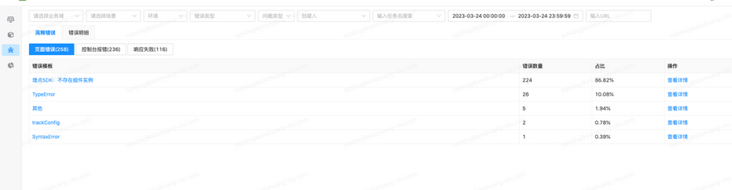
高频错误聚合,大大减少问题排查的时间,尤其是200+错误聚合。
5.后续规划
5.1 前端页面100%覆盖
因为巡检是一项低成本的质保手段,当前的巡检器仅使用了20%左右的CPU资源。因此,我们有足够的余地来执行更多的巡检任务。
考虑到生产环境中的页面数量巨大,我们目前已经单次回归测试了超过数万个H5页面,还有许多B端页面和渠道H5页面,可以加入到巡检中来。尽可能使用自动化的方式,为线上稳定保驾护航。目前,我们已经支持从监控平台拉取指定应用的实时流量巡检。
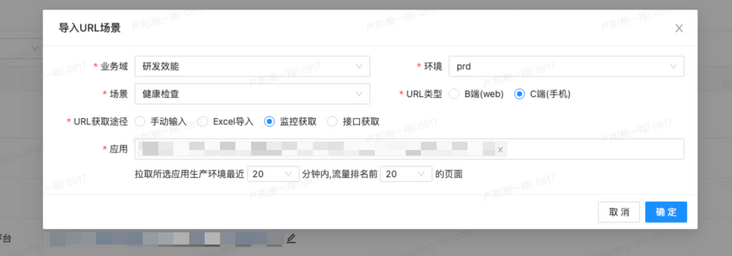

5.2 小程序巡检
在和业务方的交流中,我们也关注到线上小程序的冒烟点也是一个重头,所以Q2我们也会在小程序巡检方面做一些尝试。争取通过低人力投入、自动化的方式前置发现一些问题。
6.总结
> 以下总结80%由ChatGPT完成
> 总的来说,我们致力于为用户提供更加稳定、高效的前端巡检体验,减轻测试回归成本带来的负担。在业务目标方面朝着“三高”目标持续迭代;巡检性能从0.4个页面/秒提升到4个页面/秒,稳定性方面也会持续关注。
> 该项目后续还会有一些工作需要完成,比如巡检范围的扩大、小程序巡检的实现、巡检组件的继续完善等等。希望在团队的共同努力下,为线上前端稳定性和迭代回归人效提升出一份力。
文:卢克
线下活动推荐:
时间: 2023年6月10日(周六) 14:00-18:00主题: 得物技术沙龙总第18期-无线技术第4期地点: 杭州·西湖区学院路77号得物杭州研发中心12楼培训教室(地铁10号线&19号线文三路站G口出)
活动亮点: 本次无线沙龙聚焦于最新的技术趋势和实践,将在杭州/线上为你带来四个令人期待的演讲话题,包括:《抖音创作工具-iOS功耗监控与优化》、《得物隐私合规平台建设实践》、《网易云音乐-客户端大流量活动的日常化保障方案实践》、《得物Android编译优化》。相信这些话题将对你的工作和学习有所帮助,我们期待着与你共同探讨这些令人兴奋的技术内容!
点击报名: 无线沙龙报名
本文属得物技术原创,来源于:得物技术官网
未经得物技术许可严禁转载,否则依法追究法律责任!
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: MySQL创建数据库、数据表 | 零基础自学SQL课程系列Day3
大家好,我是宁一。 今天是SQL教程的第三课,会教大家创建一个数据库,方便我们后面课程的学习。 目录可以点击这里查看:SQL课程目录 上节课链接:手把手教你安装MySQL数据库 1、WorkBench常用操作 我们上节课刚安装了WorkBench这个数据库图形…
