
背景
PolarDB-X作为一款云原生分布式数据库,具有在线事务及分析的处理能力(HTAP)、计算存储分离、全局二级索引等重要特性。在HTAP方面,PolarDB-X对于AP引擎的向量化已经有了诸多探索和实践,例如实现了列式内存布局,MPP,面向列存的执行器等高级特性(参考PolarDB-X 向量化执行引擎(1)及PolarDB-X 向量化引擎(2))。

PolarDB-X正在全面自研列存节点Columnar,负责提供列式存储数据,结合行列混存 + 分布式计算节点构建HTAP新架构。近期即将正式上线公有云,未来也会同步发布开源。
另外,在面向列存场景最典型的就是向量化,SIMD指令作为向量化中的关键一环,已经被诸多主流AP引擎用来提升计算速度。然而由于Java语言本身的限制,PolarDB-X CN计算引擎无法在JDK 17前主动调用SIMD指令,而在JDK 17版本中Java官方提供了对SIMD指令的封装,即Vector API。本文将介绍PolarDB-X对于向量化SIMD指令的探索和实践,包括基本用法及实现原理,以及在具体算子实现中的思考和沉淀。
SIMD简介
SIMD(Single Instruction Multiple Data) 是一种处理器指令类型,即单个指令可以同时处理多个数据。
以下为加法的标量(Scalar)与SIMD(Vector)两种执行方式:
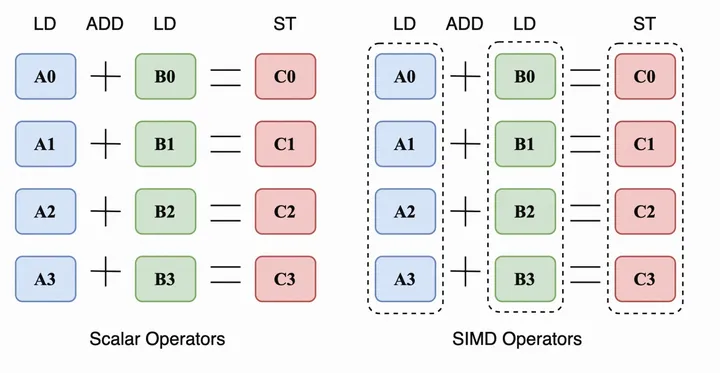
为了支持SIMD编程,CPU提供了一系列的特殊寄存器与指令
- 寄存器:
- SSE指令集中的128位寄存器XMM0-XMM15
- AVX指令集中的256位寄存器YMM0-YMM15
- 算术运算:PADDB,计算两组 8 bits 整型的和, 每组包含16 个 8 bits (SSE2),可同时用于计算 unsigned 和 signed 类型
- 比较运算:PCMPEQB,比较两组 8 bits 是否相等, 每组包含16 个 8 bits(SSE2), 32 个 (AVX2), 64 个 (AVX512BW)
- 位运算
- PAND:对两个寄存器的值作按位与(AND)
- POR:同 PAND,OR 操作
- PXOR:同 PAND,XOR 操作
- Load/Store指令
- MOVAPS:每次移动128bits的值
Vector API简介
在JDK 17以前,Java并不能主动的调用SIMD指令,但是在JDK 17版本中,Java官方提供了对SIMD指令的封装- Vector API。Vector API提供了IntVector, LongVector等寄存器,其会根据底层CPU自动选择合适的指令集,这使得开发人员无需考虑具体的CPU架构来快速进行SIMD编程。同时它也提供了add, sub, xor, or等操作来进行SIMD运算,以及fromArray, intoArray等来一次性读取多位数据。
Vector API的基本用法
我们以一个数组相加的例子来快速入门Vector API
在Vector API中,每一个Vector代表一个寄存器,其可以存放若干个元素,取决于寄存器的大小和元素类型,例如当寄存器大小为128位时,可以存放4个int类型(每个int占32位)
public class LongSumBenchmark {
//定义SPECIES,表示Vector的类型
private static final VectorSpecies SPECIES = LongVector.SPECIES_PREFERRED;
private int count;
private long[] longArr;
private long[] longArr2;
private long[] longArr3;
public void normalSum() {
for (int i = 0; i
FMA计算
为了展现Vector API对计算性能的提升,我们复现了FMA计算的例子
FMA加法是指:c = c + a[i] * b[i]。其中a和b都是float/double类型的数组
@Benchmark
public double normalSum() {
double sum = 0;
for (int i = 0; i
测试环境:随机生成1000/10w个双精度浮点数。
测试结果:向量化执行比标量执行快了2倍
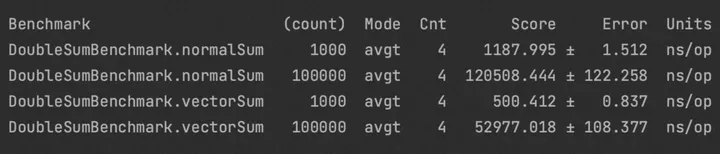
结果分析:
- Vector API的执行结果:只有一条指令
vfmadd231pd %ymm0,%ymm2,%ymm3: 将ymm2和ymm3中的双精度浮点数相乘,和ymm1中的数据相加,并把结果放到ymm1中
0x00007f764d363902: vfmadd231pd %ymm0,%ymm2,%ymm3
- 标量执行的结果:将乘法和加法拆成了两条指令vmulsd和vaddsd
0x00007f000133050d: vmulsd 0x10(%rax,%r13,8),%xmm0,%xmm0
0x00007f0001330514: vaddsd %xmm0,%xmm1,%xmm1
由测试结果可以看出,对于FMA计算场景,Vector API将原本需要两条指令的vmulsd和vaddsd合并为了一条指令vfmadd。
但需要注意:FMA计算的优化无法用在数据库中,因为PolarDB-X是将乘法和加法拆为两个算子来执行的
使用Vector API实现基础SIMD操作
在这里我们将演示如何使用Vector API实现《Rethinking SIMD Vectorization for In-Memory Databases》论文中的Gather和Scatter运算
1.Gather:Vector API的fromArray操作提供了对Gather操作的封装,我们只需要传入对应的参数即可
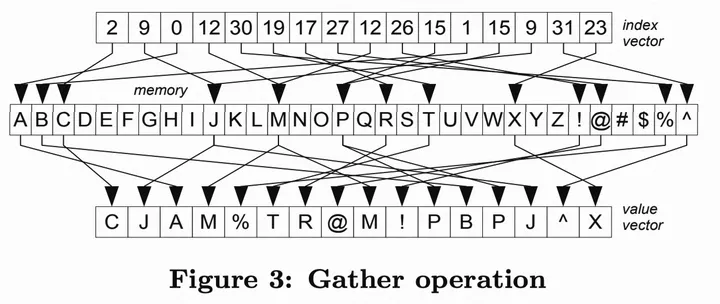
a.标量实现
public void gather(int[] source, int[] indexes, int count, int[] target) {
for (int i = 0; i
b.SIMD实现
public void gather(int[] source, int[] indexes, int count, int[] target) {
final int laneSize = INTEGER_VECTOR_SPECIES.length();
final int indexVectorLimit = count / laneSize * laneSize;
int indexPos = 0
for (; indexPos
2.Scatter实现:与Gather同理,Vector的intoArray运算提供了对Scatter运算的封装。
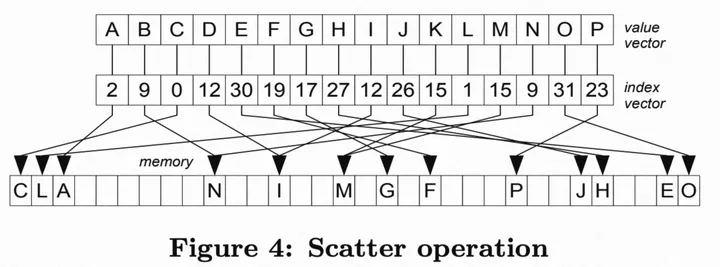
a.标量实现
public void scatter(long[] source, long[] target, int[] scatterMap, int copySize) {
for (int i = 0; i
b.SIMD实现
public void scatter(int[] source, int[] target, int[] scatterMap, int copySize) {
int laneSize = SIMDHandles.INT_VECTOR_LANE_SIZE; //每次SIMD能处理的位数
final int indexVectorLimit = copySize / laneSize * laneSize;
int index = 0;
for (; index
Vector API实现原理
以下面的向量化相加为例,我们探索一下add函数的实现
LongVector va = LongVector.fromArray(SPECIES, longArr, i);
LongVector vb = LongVector.fromArray(SPECIES, longArr2, i);
LongVector vc = va.add(vb);
JDK层面
在JDK层面Java并没有做任何的优化,其底层实现就是对Vector中的每个元素调用了apply函数,而apply函数指向了一个绑定的函数,该函数的实现为标量加法。
显然,这么做甚至会增加执行的开销,那Vector API的高性能从何谈起呢?
1.add函数的实现
@Override
@ForceInline
public final LongVector add(Vector v) {
return lanewise(ADD, v);
}
2.最终调用b0pTemplate函数进行计算
@ForceInline
final
LongVector bOpTemplate(Vector o,
FBinOp f) {
long[] res = new long[length()];
long[] vec1 = this.vec();
long[] vec2 = ((LongVector)o).vec();
for (int i = 0; i
3.apply绑定了标量执行的函数实现
LongVector lanewiseTemplate(VectorOperators.Binary op,
Vector v) {
LongVector that = (LongVector) v;
that.check(this);
....
int opc = opCode(op);
return VectorSupport.binaryOp(
opc, getClass(), long.class, length(),
this, that,
BIN_IMPL.find(op, opc, (opc_) -> {
switch (opc_) {
case VECTOR_OP_ADD: return (v0, v1) ->
v0.bOp(v1, (i, a, b) -> (long)(a + b));
case VECTOR_OP_SUB: return (v0, v1) ->
v0.bOp(v1, (i, a, b) -> (long)(a - b));
case VECTOR_OP_MUL: return (v0, v1) ->
v0.bOp(v1, (i, a, b) -> (long)(a * b));
case VECTOR_OP_DIV: return (v0, v1) ->
v0.bOp(v1, (i, a, b) -> (long)(a / b));
....
}}));
}
JVM层面
1.前置知识:JIT与C2编译器
这里需要简单讲一下Java的即时编译(JIT)。Java的执行过程整体可以分为解释执行和编译执行(JIT),第一步由javac将源码编译成字节码并进行解释执行,在解释执行的过程中,JVM会对程序的运行信息进行收集,对于其中的热点代码通过编译器(默认为C2)进行编译,将字节码直接转化为机器码,然后进行编译执行。
怎么样才会被认为是热点代码呢?JVM中会设置一个阈值,当方法或者代码块的在一定时间内的调用次数超过这个阈值时就会被认为是热点代码。
JIT的执行流程如下

2.Vector API在JVM层面的实现
通过查找,我们找到了Vector API的first commit,从该commit中我们发现Vector API的实现中有大量对JVM内核的修改。
首先,其在c2compiler中增加了Vector API相关的intrinsic(src/hotspot/share/opto/c2compiler.cpp)

当触发JIT时,Vector API相关的代码会替换为JVM层面的intrinsic,并使用SIMD指令优化。具体来说,当Vector API的代码被JIT后,其会将语法树中原本的IR节点替换为intrinsic的实现,即将method替换为intrinsic的方法。
//---------------------------make_vm_intrinsic----------------------------
CallGenerator* Compile::make_vm_intrinsic(ciMethod* m, bool is_virtual) {
vmIntrinsicID id = m->intrinsic_id();
C2Compiler* compiler = (C2Compiler*)CompileBroker::compiler(CompLevel_full_optimization);
bool is_available = false;
methodHandle mh(THREAD, m->get_Method());
is_available = compiler != NULL && compiler->is_intrinsic_supported(mh, is_virtual) &&
!C->directive()->is_intrinsic_disabled(mh) &&
!vmIntrinsics::is_disabled_by_flags(mh);
if (is_available) {
return new LibraryIntrinsic(m, is_virtual,
vmIntrinsics::predicates_needed(id),
vmIntrinsics::does_virtual_dispatch(id),
id);
} else {
return NULL;
}
}
最终的SIMD指令在C2的汇编器中生成实现
void Assembler::addpd(XMMRegister dst, XMMRegister src) {
NOT_LP64(assert(VM_Version::supports_sse2(), ""));
InstructionAttr attributes(AVX_128bit, /* rex_w */ VM_Version::supports_evex(), /* legacy_mode */ false, /* no_mask_reg */ true, /* uses_vl */ true);
attributes.set_rex_vex_w_reverted();
int encode = simd_prefix_and_encode(dst, dst, src, VEX_SIMD_66, VEX_OPCODE_0F, &attributes);
emit_int16(0x58, (0xC0 | encode));
}
表达式计算
Long数组相加
Vector API的最大优势就是加速计算,因此接下来我们会探索其可能能够带来性能提升的场景。
首先我们对前文中给出的Long数组相加的场景进行了Benchmark,可以看到在数组相加场景下标量执行和SIMD执行相差不大,通过对汇编指令的追踪,我们发现不论是SIMD执行还是标量执行最终都会生成vpaddq这条指令

1.SIMD执行
0x00007f3eb13602ae: vpaddq 0x10(%r11,%rbx,8),%ymm3,%ymm3;
2.标量执行
0x00007fa6fd33259a: vpaddq 0x10(%r8,%rbp,8),%ymm4,%ymm4
vpaddq:AVX512指令集。将(%r11 + %rbx * 8)开始的16个字节的数据和ymm3寄存器中的数据相加,写到ymm3寄存器中
自动向量化(auto-vectorization)
我们发现,哪怕没有显示的使用Vector API,向量化加法的代码也会被进行向量化,这源于Java的自动向量化(auto-vectorization)机制。
Java自动向量化的实现与Vector API类似,其会在JIT编译的时候检查代码能否使用SIMD指令进行运算,如果可以即替换为SIMD实现。
但是自动向量化仅能处理比较简单的计算,对于复杂计算仍然需要手动SIMD(使用Vector API)。
例如自动向量化已知的限制有:
- 只支持自增的for循环
- 只支持Int/Long类型(Short/Byte/Char 通过int间接支持)
- 循环的上限必须是常量
通过对一些成熟OLAP系统(例如ClickHouse)的调研,以及我们线上实际场景的探索,我们使用Vector API重新实现了一批算子,这里我们将会展示4种比较有代表性的场景。
大小写转化
使用SIMD实现大小写转化的思路比较简单,我们只需要调用compare方法进行比较,使用lanewise方法进行异或即可。这里引入了VectorMask,可以理解为一个boolean类型的寄存器,里面含有n个0/1。
@Benchmark
public void normal() {
final long Mask = 'A' ^ 'a';
for (int i = 0; i = 'A' && charArr[i] = 'A' && charArr[i]
Benchmark
测试环境:随机生成1000和10w个byte类型的字母来进行Benchmark
测试结果:在count=10w的场景下快了50x,原因在于ByteSpecies的长度为32,同时SIMD的执行方式没有分支预测失败flush流水线的开销。

SIMD Filter
使用SIMD指令实现Filter可以使用Gather运算读取数组中的元素,并使用compare方法进行比较,最后采用位运算的方式记录下满足条件的下标。
@Benchmark
public void normal() {
newSize = 0;
for (int i = 0; i vc = va.compare(VectorOperators.LE, vb);
if(!vc.anyTrue()) {
continue;
}
int res = (int) vc.toLong();
while(res != 0) {
int last = res & -res; //找到二进制中最后一个1对应的幂次, 例如12 = 1100, 12 & (-12) = 4
sel[newSize++] = i + Integer.numberOfTrailingZeros(last); //numberOfTrailingZeros(2^i) = i
res ^= last;
}
}
for(; i
Benchmark
测试环境:随机生成1000和10w个int类型的整数来进行Benchmark
结果分析:在count=1000时SIMD的性能反而下降,这是因为此时函数并没有JIT,而是采用了JDK层面的标量执行。在count=10w时方法已经被JIT,因此性能会有25%的提升。

Local Exchange
什么是Local Exchange算子
Exchange算子是PolarDB-X MPP执行模式中进行数据shuffle的重要组件,关于其背景可以参考文章PolarDB-X 并行计算框架 – 知乎这里不再赘述。在这里,我们主要来优化Local Exchange算子中的LocalPartitionExchanger执行模式。本次实践中,我们通过向量化算子 + SIMD Scatter指令的方式实现了35%的性能提升。
LocalPartitionExchanger算子可以简单理解为: 对于某个下游pipline中的driver,其会对Chunk中的每行数据计算对应的partition分区,并将相同partition分区的数据重新组装为一个新的Chunk喂给上游driver。
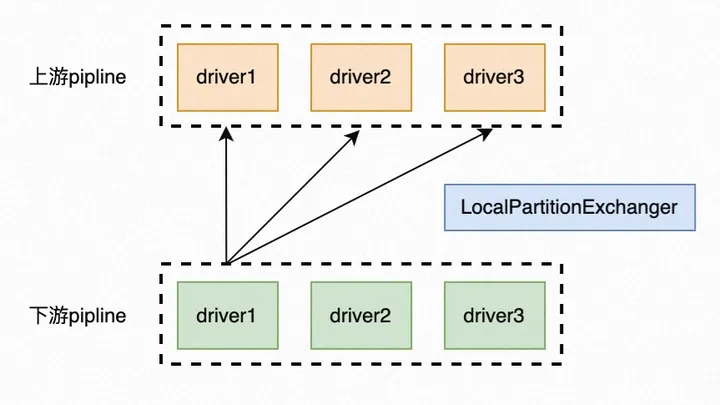
对于这一段表述不理解的话也没关系,本文的重点在于介绍使用SIMD指令优化代码逻辑的方式,因此可以放心继续阅读下文。
非向量化版本(PolarDB-X现有版本)
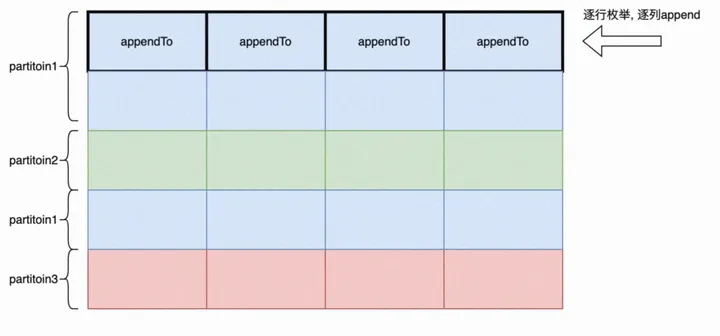
PolarDB-X现有版本沿用了行存执行模型下的Local Exchange算子,其基本思想是row by row的逐行枚举、逐行计算partition并写入对应的Chunk,这一执行模式的缺点在于其既不能有效的利用列式内存布局,同时appe服务器托管网ndTo操作会带来大量的时间开销。
旧版本的详细执行流程为:
1.计算position(行号)对应的partition:使用了n个链表来保存每个partition对应的position list
a.(partitionGenerator.getPartition可以简单的理解为对position对应的数据进行hash运算得到目标partition的位置)
for (int position = 0; position
2.buildChunk:生成对应partition的Chunk
a.先枚举partition
-
-
- 枚举partition对应的position(position表示行)
- 枚举该行对应的列block
- 调用builder的appendTo来为ChunkBuilder添加元素
- appendTo有一次虚函数调用,性能开销极大!
- 枚举该行对应的列block
- 枚举partition对应的position(position表示行)
-
Map partitionChunks = new HashMap();
for (int partition = 0; partition positions = partitionAssignments[partition]; //获取到对应的positions = partitionAssignments[partition]
ChunkBuilder builder = new ChunkBuilder(types, positions.size(), context);
Chunk partitionedChunk;
for (Integer pos : positions) { //枚举对应的position(行)
for (int i = 0; i
Local Exchange SIMD优化
思路:
1.对appendTo的优化: appendTo操作开销极大,尝试用更高效的方法拷贝数据, 例如system.arrayCopy
2.对行式枚举模式的优化:逐行枚举的方式受限,因为每一列的数据在不同的Block内,不可能攒批copy。同时逐行枚举的方式对访存不友好。那么考虑先枚举列。
-
- 问题: 每一个partition对应的行并不连续
- 解决方案:如下图所示,我们希望求出positionMapping数组使得相同partition的行能够被迁移到连续的行中,这样以来就可以使用Scatter运算进行加速。
afterValue[positionMapping[i]] = preValue[i]

3.问题:如何知道positionMapping?
-
- 其实很简单,线性扫描一遍,记录下每个partition的size, 记为partitoinSize[]
- 知道了size,就可以求出每个partition在最终数组中的偏移量paritionOffset[]
- 已知offset就可以边遍历边求出positionMapping:只需要记录出该行对应的partition的offset,然后让offset自增即可。这一过程看代码会更直观。
具体步骤
- 计算positionMapping[]
a.计算每个位置对应的partition以及每个partition的size
private void scatterAssignmentNoneBucketPageInBatch(Chunk keyChunk, int positionStart, int batchSize) {
int[] partitions = scatterMemoryContext.getPartitionsBuffer();
for (int i = 0; i
b.计算每个partition对应的offset
private void prepareDestScatterMapStartOffset() {
int startOffset = 0;
for (int i = 0; i
c.计算positionMapping
protected void prepareLengthsPerPartitionInBatch(int batchSize, int[] partitions, int[] destScatterMap) {
for (int i = 0; i
2.使用scatter运算
a.vectorizedSIMDScatterAppendTo中会判断该Block是否支持SIMD执行,并调用Block的copyPositions_scatter_simd方法,这里以IntBlock为例
protected void scatterCopyNoneBucketPageInBatch(Chunk keyChunk, int positionStart, int batchSize) {
Block[] sourceBlocks = keyChunk.getBlocksDirectly(); //获取到所有的block
for (int col = 0; col
public void copyPositions_scatter_simd(ScatterMemoryContext scatterMemoryContext, BlockBuilder[] blockBuilders) {
//存放目的数据的buffer
int[] afterValue = scatterMemoryContext.getafterValue();
//存放原始数据的buffer
int[] preValue = scatterMemoryContext.getpreValue();
//positionMapping
int[] positionMapping = scatterMemoryContext.getpositionMapping();
//每个partition的size
int[] partitionSize = scatterMemoryContext.getpartitionSize();
//使用scatter的操作
VectorizedPrimitives.SIMD_PRIMITIVES_HANDLER.scatter(preValue, afterValue, positionMapping, 0, batchSize);
int start = 0;
for (int partition = 0; partition
3.使用writeBatchInts来实现内存拷贝
public IntegerBlockBuilder writeBatchInts(int[] ints, boolean[] nulls, int sourceIndex, int count) {
values.addElements(getPositionCount(), ints, sourceIndex, count);
valueIsNull.addElements(getPositionCount(), nulls, sourceIndex, count);
return this;
}
addElements的底层使用了System.arraycopy命令来批量的进行内存复制
System.arraycopy是JVM的内置函数,其实现效率远远快于调用append接口来逐个添加数据
@IntrinsicCandidate
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
Benchmark
测试环境:我们设置parition的数量为3,并向Local Exchange算子输入100个大小为1024,包含4列int的Chunk来进行Benchmark
结果分析:

我们发现单纯的向量化算法并不会有性能提升,原因在于Local Exchange算子的瓶颈在于appendTo操作
而SIMD Scatter + System.arrayCopy的方式实现了35%的性能提升。
SIMD Hash Join
SIMD思路
在CMU 15-721中提到了SIMD Hash Probe的实现,我们将用Vector API来复现这一过程。
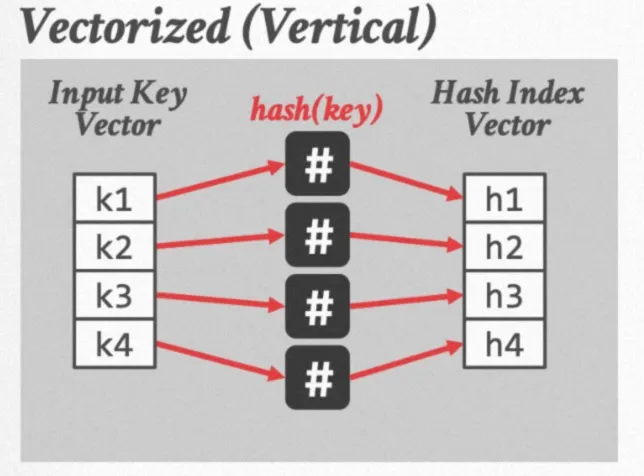
首先来回顾开放地址法的SIMD Hash Probe过程,其基本思路是一次性对4个位置的元素进行probe。
1.计算出4个位置的hash值
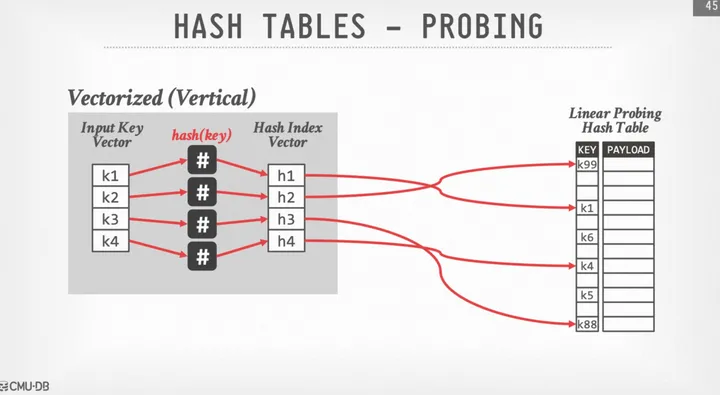
2.通过Gather运算读取到hash表中对应位置的元素
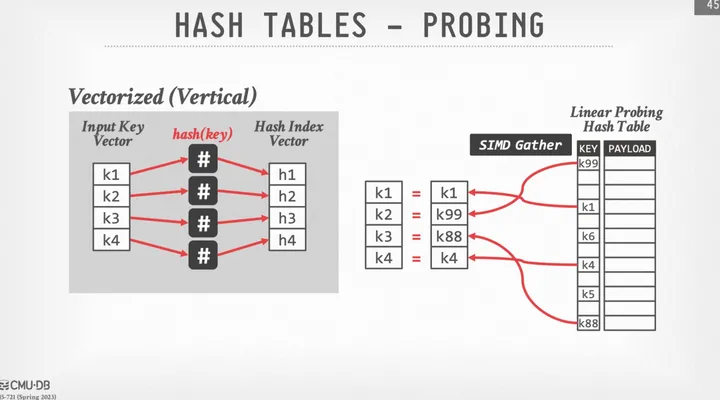
3.通过SIMD的compare运算比较有无hash冲突
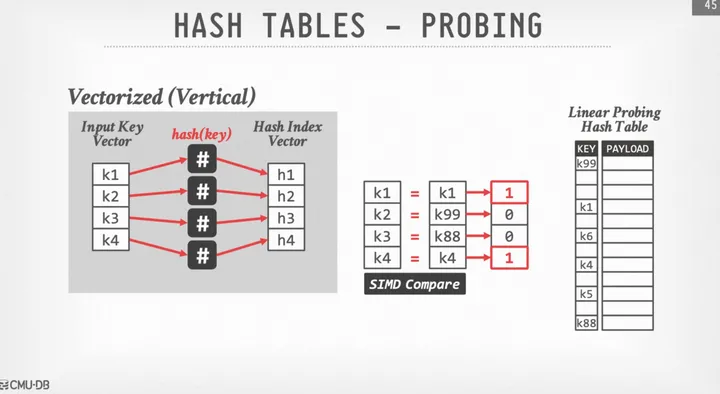
4.前3步都比较好理解,接下来我们需要让有hash冲突的元素寻址到下一个位置继续解hash冲突,这一步可以由SIMD加法来实现。重点在于如何让没有冲突的元素移走,把数组中后面的元素放进来继续匹配呢?(例如我们希望把下图中的k1, k4分别替换为k5, k6)
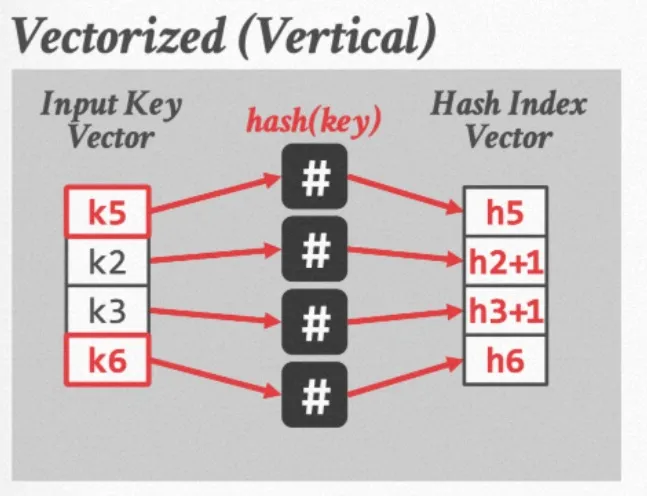
解决方案:
a.使用expand运算来进行selective load运算
buildPositionVec = buildPositionVec.expand(probePosition, probeOffset, probeMask);
b.expand运算可以将probeMask当中为1的n个位置元素替换为hashPosition数组从probeOffset位置开始的n个元素。
-
-
- 例如在上面的例子中数据的变化为
- hashPosition = [h1, h2, h3, h4, h5, h6, h7, h8…..]
- probeOffset = 4
- probeMask = [1, 0, 0, 1]
- 入参: [h1, h2, h3, h4]
- 出参: [h5, h2, h3, h6]
-
小插曲: 如何实现更强大的expand
在上述代码中,我们的expand运算传入了3个参数,但是openJDK官方的expand函数最多有一个入参(openJDK的expand用法不能传入数组,只能在Vector之间做expand)


这得益于阿里云强大的自研能力,我们与阿里云JVM团队进行了积极的沟通,JVM团队的同学帮助我们实现了更丰富的expand的运算。
验证
PolarDB-X的Hash方式并不是开放寻址法,而是布谷鸟Hash,但其SIMD的原理类似,这里给出对布谷鸟Hash的SIMD Hash Probe改造过程。
@Benchmark
public void normal() {
for(int i = 0; i probeMask;
VectorMask intProbeMask;
LongVector probeValueVec = LongVector.fromArray(LongVector.SPECIES_512, probeKey, probeOffset);
// step 1: 使用Gather运算从hashTable的keys中读取数据. int matchedPosition = hashTable.keys[hashedProbeKey[i]];
LongVector buildPositionVec = LongVector.fromArray(LongVector.SPECIES_512, hashTable.keys, 0, hashedProbeKey, probeOffset);
IntVector probeIndexVec = IntVector.fromArray(IntVector.SPECIES_256, index, probeOffset);
probeOffset += 8;
while(probeOffset + LongVector.SPECIES_512.length() emptyMask = buildPositionVec.compare(VectorOperators.EQ, 0);
// step 3: 使用Gather运算计算出buildKey[matchedPosition[i]]的值
IntVector intbuildPositionVec = buildPositionVec.castShape(IntVector.SPECIES_256, 0).reinterpretAsInts();
LongVector buildValueVec = LongVector.fromArray(LongVector.SPECIES_512, intbuildPositionVec, buildKey);
// step 4: 使用SIMD compare来进行比较. if (buildKey[matchedPosition] == probeKey[i])
VectorMask valueEQMask = probeValueVec.compare(VectorOperators.EQ, buildValueVec, emptyMask.not());
// step 5: 计算出probe过程成功找到目标位置的Mask
probeMask = valueEQMask.or(emptyMask);
intProbeMask = probeMask.cast(IntVector.SPECIES_256);
// step 6: 使用scatter运算将匹配的position写入joinedPosition. joinedPositions[i] = matchedPosition;
buildPositionVec.intoArray(joinedPositions, probeIndexVec, valueEQMask);
// step 7: 处理hash冲突. matchedPosition = positionLinks[matchedPosition];
buildPositionVec = LongVector.fromArray(LongVector.SPECIES_512, intbuildPositionVec, positionLinks);
// step 8: 使用expand运算获取到下一个probe vector
buildPositionVec = buildPositionVec.expand(probePosition, probeOffset, probeMask);
probeValueVec = probeValueVec.expand(probeKey, probeOffset, probeMask);
probeIndexVec = probeIndexVec.expand(index, probeOffset, intProbeMask);
// step 9: 更新probeOffset
probeOffset += probeMask.trueCount();
}
scalarProcessVector(probeValueVec, buildPositionVec, probeIndexVec, joinedPositions); //处理最后一个Vector
if (probeOffset
Benchmark
测试环境:在Build端我们向Hash表中插入了100w个大小在0-1000范围的元素来模拟Hash冲突,Probe时计算探测100w个元素所需要的时间
测试结果:虽然我们实现了SIMD Hash Probe,但由于现有的Vector API对类型的支持并不充分(代码中含有大量的类型转化),因此实测结果并不优秀,甚至有2倍多的性能下降。

但抛开Java Vector API本身带来的性能下降,使用SIMD指令来优化Ha服务器托管网sh Probe也许并不是明智之举,这是因为Hash Join的瓶颈不在于计算,而在于访存。《Improving hash join performance through prefetching》写到数据库的Hash Join算法有73%的开销在CPU cache miss上,这也解释了SIMD指令没有优化的原因。
在PolarDB-X内部对TPC-H Q9的测试中发现浪费在cache miss上的CPU Cycle达到了计算的10倍之多,因此我们将对Hash Join的优化转移到了cache miss。PolarDB-X已经尝试使用prefetch指令预取(由阿里云JVM团队提供对Java的增强),向量化Hash Probe等方式优化cache miss,相关的优化成果会在后续的文章中展示。
总结
本篇文章我们首先介绍了Vector API的用法与实现原理,并着重探索了其在数据库场景下的应用,在以计算为瓶颈的大小写转化中实现了50倍的性能提升,在Filter算子中实现了25%的性能提升,在Local Exchange算子中实现了35%的性能提升。同时我们也讨论了Vector API在Hash Probe这种以cache miss为瓶颈的算子中的局限性。
PolarDB-X作为一款分布式HTAP数据库,AP引擎的性能优化一直是我们的重点工作内容。我们不仅仅着眼于业内的常见优化,对于行列混存架构、向量化SIMD指令等无人涉及的“深水区”也在积极的探索当中。敬请大家期待后续 PolarDB-X 列存引擎在公有云和开源的正式发布。
作者:鸿为
点击立即免费试用云产品 开启云上实践之旅!
原文链接
本文为阿里云原创内容,未经允许不得转载。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
