
Detection of transcription factors binding to methylated DNA by deep recurrent neural network
关键词:deep recurrent neural network; methylated DNA; transcription factors; tripeptide; tripeptide word vector
作者:Hongfei Li , Yue Gong , Yifeng Liu , Hao Lin , Guohua Wang
期刊:Briefings in Bioinformatics
年份:2022
论文原文:
●10.1093/bib/bb服务器托管网ab533
补充材料:
网站链接:https://bioinfor.nefu.edu.cn/TFPM
主要内容
问题
转录因子(TFs)是一种特异性参与基因表达调控的蛋白质。在表观遗传学中,人们普遍认为甲基化的核苷酸可以阻止TFs与DNA片段的结合。然而,最近的研究证实,一些转录因子有能力与甲基化的DNA片段相互作用,从而进一步调控基因表达。虽然生化实验可以识别与甲基化DNA序列结合的TFs,但这些实验方法是耗时和昂贵的。机器学习方法为在不使用实验材料的情况下快速识别这些TFs提供了一个很好的选择。
方法
本研究旨在设计一个稳健的预测因子来检测甲基化DNA结合的转录因子。我们首先提出了使用三肽词向量 特 征来构建蛋白质样本。随后,基于具有长短期记忆的递归神经网络,设计了一个两步计算模型。第一步预测 因子区分转录因子和非转录因子。一旦蛋白质被预测为TFs,就使用第二步预测因子来判断转录因子是否能与甲基化的DNA结合。
模型流程框架图AGAPAA>109ET641MKHNFSLRLRVFNLNCW*’DIPYLSKHRTLPCSAHGSAERSALISADRMKRLALREARTELGRGIAQARWWAALFGYVMILGDAAFAAPSVV1945 PROTEIN SEQUENCESIN FASTA FORMATPROJECTIONTRIPEPTIDE WORD VECTORTE VS NTE:100-DTFPNM VS TFPM:200-DSKIP-GRAMPEIF THE SEQUENCE IS IDENTIFIED AS TFSNTFSTFS0.85>0.5 OR 0.15
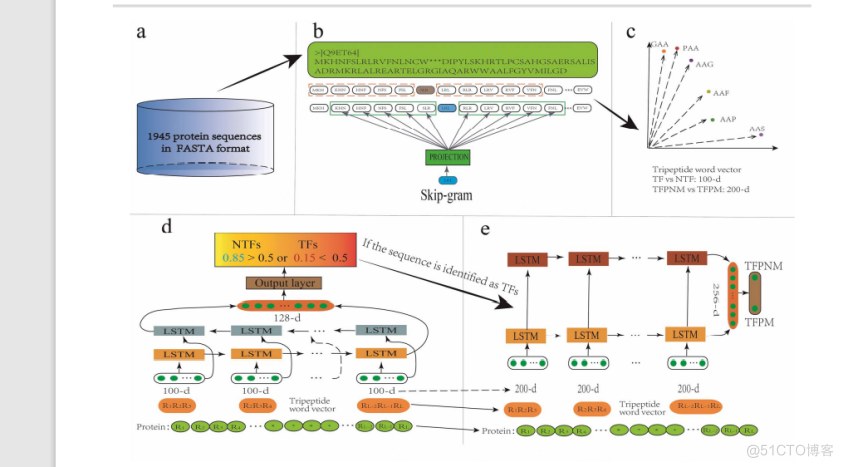
数据集
本文使用的训练数据和测试数据来自刘的工作。这些数据具有以下特征::(I)样品的长度不小于50个氨基酸残基;(II)这些序列不含模糊的氨基酸,如“B”、“X”或“Z”;(III)同一类别的序列同一性小于25%。有关数据的细节可以参考刘的作品。需要提到的是,TFs与甲基化DNA结合的原始数据是从MeDReaders 数据库中下载的。在基准数据集中,使用416个TFs和416个NTFs来训练已识别的TFs模型。将106个TFs和106个NTFs视为独立的数据集来验证模型的性能。此外,为了建立一个判断TFs是否有能力与甲基化DNA结合的模型,我们总共使用了106个TFPM和106个TFPNM作为训练数据。然后,在独立数据中分别包含69个TFPM和37个TFPNM,以进一步评价模型的性能。
数据来源:https://bioinfor.nefu.edu.cn/TFPM/
主要实验及结果
从蛋白质中预测转录因子
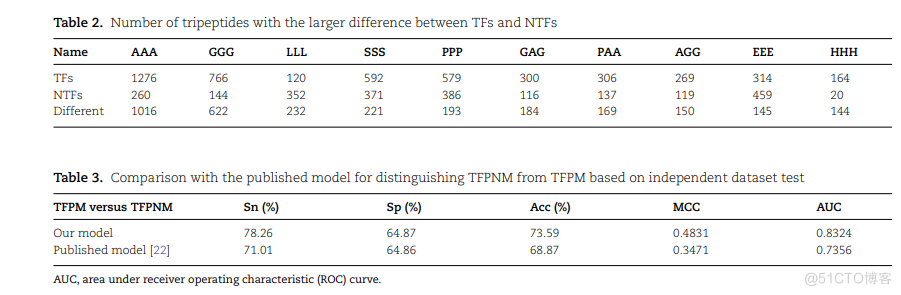
实验的第一步是建立一个预测模型来区分转录因子和NTFs。我们通过独立集测试验证了所提出的模型的性能,并将结果列在表1中。与已发表的模型的比较也记录在表中。总的来说,我们的模型比Liu的模型表现得更好。Acc和MCC分别增长了3.61%和0.0658,分别为86.36%和0.7275。
TABLE I, COMPARISON WITH THE PUBISHED RESUIS FOR DISCTIMINATING IFS FROM NTESED ON INDENDENT DATASETSN(%)SP(%)ACC(%)TFS VERSUS NTFSAUCMCC88.680.72720.9130OUR MODEL83.9686.63PUBLISHED MODEL[22]85.8580.1983.020.66140.9116AUC, AREA UNDER RECEIVER OPERATING CHARACTERISTIC (ROC) CURVE

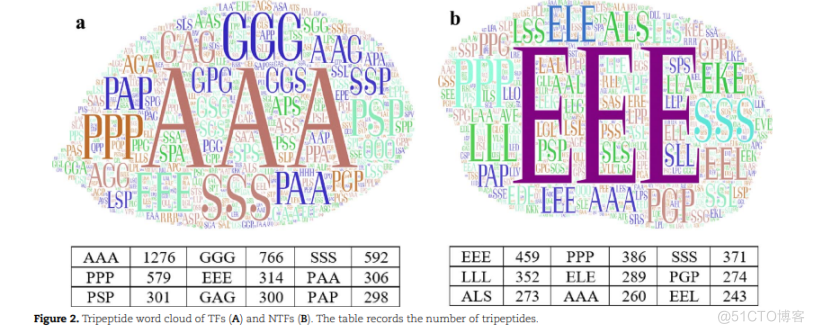
为了明确TFs和NTFs在一级结构上的差异,我们计算了416个TFs和416个NTFs之间不同三肽的数量,并通过单词云显示。显然,TF中最常见的三肽是AAA、GGG、SSS和PPP,其数量大于500,如图2A所示,这推断每个TF可能包含这些三肽。特别是在同一TF中,三肽AAA可能比其他三肽出现得更多。然而,在NTFs中,只有三肽EEE的数量大于样本服务器托管网的数量,以及其他三肽的数量,包括PPP、LLL、SSS等的值较低,差异较小。
LAA EDE ASASAALSGGGAAGISASCPPBKESPSAGAEKESSPGPGTSSGCSPAPEPEGSGAPSGAPSUSTMASSAAPSSDOPPPGG1000SILSLPGPPGGAGGYPAPGPGPLSLAAUBDADSSLSPEESRS TE WE SSCERLATTISGCP.TAA0P459PPP371SSS1276386EEEGGG766AAASSS592PGP352289LLL274579ELEPPPEEE314PAA306273ALS260EEL243301298AAAPSPPAPGAG300AND NTFS (B).THE TABLE RECORDS THE NUMBER OF TRIPEPTIDES.FIGURE 2. THIPEPTIDE WORD CLOUD OF TFS (A) AN
本文研究了出现在不同位置的三肽。由于序列长度不均匀,每个序列被分为起始、中间和结束三个片段,其中计算前30个位点的三肽数。如图3所示,TFs和NTFs之间差异最大的前10个三肽用白色字体染色,列在表2中。在NTFs中,三肽题词的数量和类型(AAA、LLL、EEE、GGA、AAG等)。更多的是在序列的开始位置,而不是在中间位置(PPP、LLL等)。和末端(EEE、SSS等)的序列。在TFs中,以AAA为主的三肽分布在序列的起始位置和中间位置。一般来说,三肽AAA的比例最大,这可能对TFs的功能有更重要的影响。
NTFNTFNTF14TOP1TOP3TOP5TOP5TOP1TOP3TOP5TOPTOP3TOP2TOPTOP2121010COUNTCOUNTCOUNT10MIDDLE OF SEQUENCESEND OF SEQUENCESTFTFTOPTOP3TOP5TOP5TOP3TOPZTOP5TOP3TOP2TOP420.0TOP417.51515COUNT10.01010MIDDLE OF SEQUENCESEND OF SEGUENCESSTART OF SEQUENCESREPRESENT A LARGE DIFFERENCE IN THE NUMBER OF TF AND NTF. THE TRIPEPTIDES WITH BLACK INSCRIPTIONCURRENT POSITION. THE TRIPEPTIDES WITH WHITE INSCNPTION REPRMEAN LITTLE DIFFERENCE.
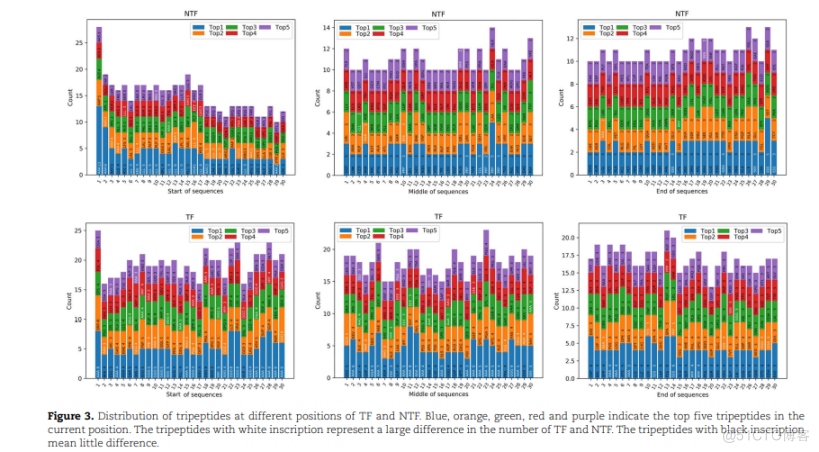
TABLE 2. NUMBER OF TRIPEPTIDES WITH THE LARGER DIFFERENCE BETWEEN TFS AND NTFSGGGGAGSSSLLLPAAAGGEEEAAAPPPNAMEHHH2695921276766314306579120164300TFS386NTFS37135214411611945913720260193DIFFERENT1452212321841501441696221016TABLE 3, COMPARISON VITH THE PUBISHED NODEL FOR DISTINGUISHING IPPNM FON TEPM BASED ON INDENT DATASEAUCSP (%)SN(%)ACC(%)TFPM VERSUS TFPNMMCCOUR MODEL0.83240.483164.8773.5978.260.735664.8668.870.347171.01PUBLISHED MODEL[22]AUC, AREA UNDER RECEIVER OPERATING CHARACTERISTIC (ROC) CURVE.
TFs是否与甲基化DNA结合的预测
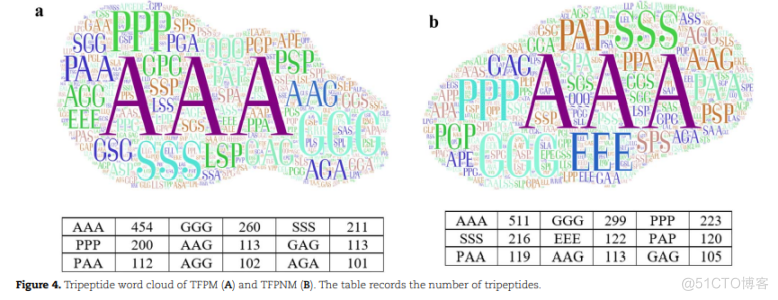
一旦一个蛋白质通过第一个模型被确定为TF,就有必要探索该TF是否能够与甲基化的DNA结合。我们训练了一个模型,根据方法中的描述来识别这些TFs。从表3可以看出,我们的模型的性能指标都高于之前发表的模型,特别是ACC、MCC和AUC分别从68.87%、0.3471和0.735提高到73.59%、0.4831和0.832。如Liu等人所述,不同类型的TFs与甲基化或非甲基化DNA相互作用,在功能和一级结构上是相似的。准确获取TF的序列信息以参考它们的差异是非常必要的。我们的模型不仅考虑了残留物的组成,还考虑了位置信息,因此,我们的模型的预测精度被大大提高了。从图4中的单词云,可以发现大多数三肽出现在TFPM TFPNM,包括AAA, GGG, SSS,PPP,进一步说明了TFPM和TFPNM之间的相似性,但相同的数量和位置的差异的三肽序列可能是关键决定TF结合甲基化DNA。
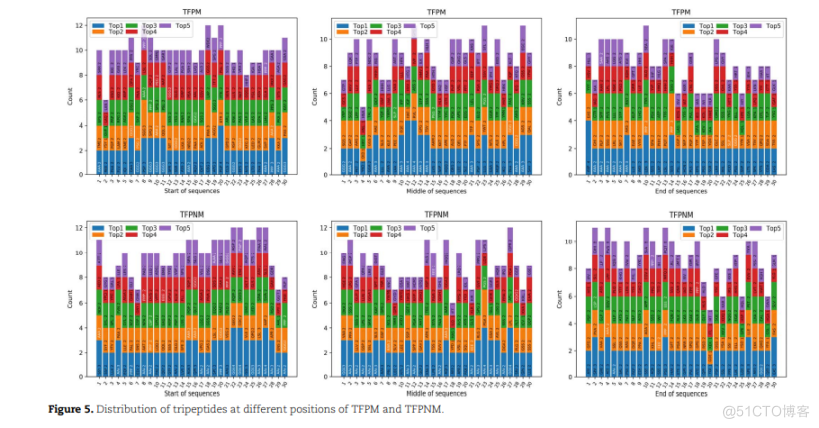
根据TFPM和TFPNM不同位置的三肽类型,我们在图5中列出了序列起始、中间和末端每30个位置排列的5个三肽。所有TFPM和TFPNM中带有白色题词的三肽数量均有显著差异,记录见表4。在TFPM序列开始时,GGG是分布最多的三肽,其次是AAA。相反,AAA是最常见的,GGG在TFPNM中排名第二。三肽PGP出现在TFPM中而不是TFPNM中,位于序列开始时的第20位,表明特定位置的三肽可能影响TF是否与甲基化DNA结合。在序列的中间位置,AAA在TFPM和TFPNM中最为常见。在序列结束时,TFPM和TFPNM中带有白色题词的三肽数量显著减少,TFPNM中的AAA数量小于TFPNM中。总的来说,三肽AAA的数量和位置可能会发生确定TF是否与甲基化的DNA结合,以及其他特殊的三肽也会影响它。此外,丙氨酸的疏水性证实了Shen的结论,即疏水性影响TFs与甲基化位点的结合。
PCEDE:GPPSASSOPPSANPAPSSSSPSGAAGSCDACGSISSGGPGAQUEPCPAPEPSPAAGPPAAASCACPAASSPAACLIGSAGGSSTPSPAAS,GPELPPSGSPEPFIAGA SAAGSGAGAGGACPASPASCOP GAGLISTWASA-ASAAKECAALSSSIPGPAUL BRITE511PPP299223AAAGGG454SSSGGGAAA211260PAP122SSSEEE216120PPP113200AAG113GAG113GAGPAA105119AAG112PAA102AGG101AGA(A) AND TFPNM(B). THE TABLE RECORDS THE NUMBER OF TRIPEPTIDES.FIGURE 4.TRIPEPTIDE WORD CLOUD OF TFPM (A) A
TFPMTFPMTFPMTOPLTOPTOP1TOP3TOP3TOP3TOP5TOP5TOP2TOP2TOP410COUNTCOUNTCOUNT6MIDDLE OF SEQUENCESSTART OF SEQUENCESEND OF SEQUENCESTEPNMTFPNMTEPNMTOP5TOP1TOP1TOP5TOP3T0P3TOP3TOP5TOP2TOP2TOP41010COUNTCOUNT自由印刷和医院政综合学院的街道的街道自由44201440000400010年START OF SEGUENCESMIDDLE OF SEGUENCESEND OF SEQUENCESFIGURE S. DISTRIBUTION OF TRIPEPTIDES AT DIFFERENT POSITIONS OF TFPM AND TFPNM.
结论
转录因子与DNA的结合对靶基因有消极(抑制转录)或积极(激活转录)的影响。最近,一种新的相互作用机制被证实,TFs可以与甲基化DNA结合。由于这种关系的功能和原理仍然很神秘,因此判断TFs是否能与甲基化DNA结合是遗传表观遗传学的一个里程碑。因此,我们引入了一种基于检测转录因子的三肽词载体,并进一步区分转录因子是否能与甲基化DNA结合。实验结果证实,特异性三肽的位置和数量可能限制了TFs与甲基化DNA的结合。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
在数据分析和机器学习领域,数据可视化是一项非常重要的技能。通过数据可视化,我们可以更加直观地了解数据的特征、趋势和分布等信息。Python作为一种强大的编程语言,提供了丰富的数据可视化库和工具,本文将介绍如何使用Python进行数据可视化。 一、Matplot…
