
1 导引
在机器学习,尤其是涉及异构数据的迁移学习/联邦学习中,我们常常会涉及互信息相关的优化项,我上半年的第一份工作也是致力于此(ArXiv链接:FedDCSR)。其思想虽然简单,但其具体的估计与优化手段而言却大有门道,我们今天来好好总结一下,也算是对我研一下学期一个收尾。
我们知道,随机变量(X)和(Y)的互信息定义为其联合分布(joint)(p(x, y))和其边缘分布(marginal)的乘积(p(x)p(y))之间的KL散度(相对熵)[1]:
I(X ; Y) &= D_{text{KL}}left(p(x, y) parallel p(x)p(y)right)
&=mathbb{E}_{p(x, y)}left[log frac{p(x, y)}{p(x)p(y)}right]
end{aligned}
tag{1}
]
直观地理解,互信息表示一个随机变量包含另一个随机变量信息量(即统计依赖性)的度量;同时,互信息也是在给定另一随机变量知识的条件下,原随机变量不确定度的缩减量,即(I(X; Y) = H(X) – H(X mid Y) = H(Y) – H(Ymid X))。当(X)和(Y)一一对应时,(I(X; Y) = H(X) = H(Y));当(X)和(Y)相互独立时(I(X; Y)=0)。
在机器学习的情境下,联合分布(p(x, y))一般是未知的,因此我们需要用贝叶斯公式将其继续转换为如下形式:
I(X ; Y)
&服务器托管网;overset{(1)}{=}mathbb{E}_{p(x, y)}left[log frac{p(x mid y)}{p(x)}right] overset{(2)}{=}mathbb{E}_{p(x, y)}left[log frac{p(y mid x)}{p(y)}right]
end{aligned}
tag{2}
]
那么转换为这种形式之后,我们是否就可以开始对其进行估计了呢?答案是否定的。我们假设现在是深度表征学习场景,(X)是数据,(Y)是数据的随机表征,则对于第((1))种形式来说,条件概率分布(p(x|y)=frac{p (y|x)p(x)}{int p(y|x)p(x)dx})是难解(intractable)的(由于(p(x))未知);而对于第((2))种形式而言,边缘分布(p(y))也需要通过积分(p(y)=int p(y mid x)p(x)d x)来进行计算,而这也是难解的(由于(p(x))未知)。为了解决互信息估计的的难解性,我们的方法是不直接对互信息进行估计,而是采用变分近似的手段,来得出互信息的下界/上界做为近似,转而对互信息的下界/上界进行最大化/最小化[2]。
2 互信息的变分下界(对应最大化)
我们先来看互信息的变分下界。我们常常通过最大化互信息的下界来近似地对其进行最大化。具体而言,按照是否需要解码器,我们可以将互信息的下界分为两类,分别对应变分信息瓶颈(解码项)[3][4]和Deep InfoMax[5][6]这两种方法。
2.1 数据VS表征:变分信息瓶颈(解码项)
对于互信息的第((1))种表示法即(I(X ; Y){=}mathbb{E}_{p(x, y)}left[log frac{p(x mid y)}{p(x)}right]),我们已经知道条件分布(p(x|y))是难解的,那么我们就采用变分分布(q(x|y))将其转变为可解(tractable)的优化问题。这样就可以导出互信息的Barber & Agakov下界(由于KL散度的非负性):
I(X ; Y)= & mathbb{E}_{p(x, y)}left[log frac{q(x mid y)}{p(x)}right]+mathbb{E}_{p(y)}left[D_{text{K L}}(p(x mid y) mid q(x mid y))right]
geq & mathbb{E}_{p(x, y)}[log q(x mid y)]+H(X) triangleq I_{mathrm{BA}},
end{aligned}
tag{3}
]
这里(H(X))是(X)的微分熵,BA是论文[7]两位作者名字的缩写。当(q(x|y)=p(x|y))时,该下界是紧的,此时上式的第一项就等于条件熵(H(X|Y))。
上式可不可解取决于微分熵(H(X))是否已知。幸运的是,限定在 (X)是数据,(Y)是表征 的场景下,(H(X)=mathbb{E}_{xsim p(x)} log p(x))仅涉及数据生成过程,和模型无关。这意味着我们只需要最大化(I_{text{BA}})的第一项,而这可以理解为最小化VAE中的重构误差(失真,distortion)。此时,(I_{text{BA}})的梯度就与“编码器”(p(y|x))和变分“解码器”(q(x|y))相关,而这是易于计算的。因此,我们就可以使用该目标函数来学习一个最大化(I(X; Y))的编码器(p(y|x)),这就是大名鼎鼎的变分信息瓶颈(variational information bottleneck) 的思想(对应其中的解码项部分)。
2.2 表征VS表征:Deep Infomax
我们在 2.1 中介绍的方法虽然简单好用,但是需要构建一个易于计算的解码器(q(x|y)),这在(X)是数据,(Y)是表征的时候非常容易,然而当 (X)和(Y)都是表征 的时候就直接寄了,首先是因为解码器(q(x|y))是难以计算的,其次微分熵(H(X))也是未知的。为了导出不需要解码器的可解下界,我们转向去思考(q(x|y))变分族的的非标准化分布(unnormalized distributions)。
我们选择一个基于能量的变分族,它使用一个判别函数/网络(critic)(f(x, y): mathcal{X} times mathcal{Y}rightarrow mathbb{R}),并经由数据密度(p(x))缩放:
]
我们将该分布代入公式((3))中的(I_{text{BA}})中,就导出了另一个互信息的下界,我们将其称为UBA下界(记作(I_{text{UBA}})),可视为Barber & Agakov下界的非标准化版本(Unnormalized version):
tag{5}
]
当(f(x, y)=log p(y|x) + c(y))时,该上界是紧的,这里(c(y))仅仅是关于(y)的函数(而非(x))。注意在代入过程中难解的微分熵(H(X))被消掉了,但我们仍然剩下一个难解的(log)配分函数(log Z(y)),它妨碍了我们计算梯度与评估。如果我们对(mathbb{E}_{p(y)}[log Z(y)])这个整体应用Jensen不等式((log)为凹函数),我们能进一步导出式((5))的下界,即大名鼎鼎的Donsker & Varadhan下界[7]:
tag{6}
]
然而,该目标函数仍然是难解的。接下来我们换个角度,我们不对(mathbb{E}_{p(y)}[log Z(y)])这个整体应用Jensen不等式,而考虑对里面的(log Z(y))应用Jensen不等式即(log Z(y)=log mathbb{E}_{p(x)}left[e^{f(x, y)}right]geqmathbb{E}_{p(x)}left[log e^{f(x, y)}right]=mathbb{E}_{p(x)}left[f(x, y)right]),那么我们就可以导出式((5))的上界来对其进行近似:
tag{7}
]
然而式((5))本身做为互信息的下界而存在,因此(I_{text{MINE}})严格意义上讲既不是互信息的上界也不是互信息的下界。不过这种方法可视为采用期望的蒙特卡洛近似来评估(I_{text{DV}}),也就是作为互信息下界的无偏估计。已经有工作证明了这种嵌套蒙特卡洛估计器的收敛性和渐进一致性,但并没有给出在有限样本下的成立的界[8][9]。
在(I_{text{MINE}})思想的基础之上,论文Deep Infomax[6]又向前推进了一步,认为我们无需死抱着信息的KL散度形式不放,可以大胆采用非KL散度的形式。事实上,我们主要感兴趣的是最大化互信息,而不关心它的精确值,于是采用非KL散度形式可以为我们提供有利的trade-off。比如我们就可以基于(p(x, y))与(p(x)p(y))的Jensen-Shannon散度(JSD),来定义如下的JS互信息估计器:
tag{8}
]
这里(x)是输入样本,(xprime)是采自(p(x^{prime}) = p(x))的负样本,(text{sp}(z) = log (1+e^x))是(text{softplus})函数。这里判别网络(f)被优化来能够区分来自联合分布的样本对(正样本对)和来自边缘乘积分布的样本对(负样本对)。
此外,噪声对比估计(NCE)[10]做为最先被采用的互信息下界(被称为“InfoNCE”),也可以用于互信息最大化:
tag{9}
]
对于Deep Infomax而言,(I_{text{JSD}})和(I_{text{InfoNCE}})形式的之间差别在于负样本分布(p(x^{prime}))的期望是套在正样本分布(p(x, y))期望的里面还是外面,而这个差别就意味着对于(text{DV})和(text{JSD})而言一个正样本只需要一个负样本,但对于(text{InfoNCE})而言就是一个正样本就需要(N)个负样本((N)为batch size)。此外,也有论文[6]分析证明了(I_{text{JSD}})对负样本的数量不敏感,而(I_{text{InfoNCE}})的表现会随着负样本的减少而下降。
3 互信息的变分上界(对应最小化)
我们接下来来看互信息的变分上界。我们常常通过最小化互信息的上界来近似地对互信息进行最小化。具体而言,按照是否需要编码器,我们可以将互信息的下界分为两类,而这两个类别分别就对应了变分信息瓶颈的编码项[4]和解耦表征学习[11]。
3.1 数据VS表征:变分信息瓶颈(编码项)
对于互信息的第((2))种表示法即(I(X ; Y){=}mathbb{E}_{p(x, y)}left[log frac{p(y mid x)}{p(y)}right]),我们已经知道边缘分布(p(y)=int p(y mid x)p(x)d x)是难解的。但是限定在 (X)是数据,(Y)是表征 的场景下,我们能够通过引入一个变分近似(q(y))来构建一个可解的变分下界:
I(X ; Y) & equiv mathbb{E}_{p(x, y)}left[log frac{p(y mid x)}{p(y)}right]
& overset{(1)}{=}mathbb{E}_{p(x, y)}left[log frac{p(y mid x) q(y)}{q(y) p(y)}right]
& overset{(2)}{=}mathbb{E}_{p(x, y)}left[log frac{p(y mid x)}{q(y)}right]-D_{text{K L}}(p(y) | q(y))
& overset{(3)}{leq} mathbb{E}_{p(x)}left[D_{text{K L}}(p(y mid x) | q(y))right] triangleq R,
end{aligned}
tag{10}
]
注意上面的((1))是分子分母同时乘以(q(y));((2))是单独配凑出KL散度;((3))是利用KL散度的非负性(证明变分上下界的常用技巧)。最后得到的这个上界我们在生成模型在常常被称为Rate[12](也就是率失真理论里的那个率),故这里记为(R)。当(q(y)=p(y))时该上界是紧的,且该上界要求(log q(y))是易于计算的。该变分上界经常在深度生成模型(如VAE)[13][14] 被用来限制随机表征的容量。在变分信息瓶颈[4]这篇论文中,该上界被用于防止表征携带更多与输入有关,但却和下游分类任务无关的信息(即对应其中的编码项部分)。
3.2 表征VS表征:解耦表征学习
上面介绍的方法需要构建一个易于计算的编码器(p(y|x)),但应用场景也仅限于在(X)是数据,(Y)是表征的情况下,当 (X)和(Y)都是表征 的时候(即对应解耦表征学习的场景)也会遇到我们在2.2中所面临的问题,从而不能够使用了。那么我们能不能效仿2.2中的做法,对导出的(I_{text{JSD}})和(I_{text{InfoNCE}})加个负号,从而将互信息最大化转换为互信息最小化呢?当然可以但是效果不会太好。因为对于两个分布而言,拉近它们距离的结果是确定可控的,但直接推远它们距离的结果就是不可控的了——我们无法掌控这两个分布推远之后的具体形态,导致任务的整体表现受到负面影响。那么有没有更好的办法呢?
我们退一步思考:最小化互信息(I(X, Y))的难点在于(X)和(Y)都是随机表征,那么我们可以尝试引入数据随机变量(D),使得互信息(I(X, Y))可以进一步拆分为(D)和(X)、(Y)之间的互信息(如(I(D; X))以及(I(D; Y))。已知三个随机变量的互信息(称之为Interation information[1])的定义如下:
I(X ; Y ; D)&overset{(1)}{=}I(X ; Y)-I(X ; Y mid D)
&overset{(2)}{=}I(X ; D)-I(X ; D mid Y)
&overset{(3)}{=}I(Y ; D)-I(Y ; D mid X)
end{aligned}
tag{11}
]
联立上述的等式((1))和等式((2)),我们有:
tag{12}
]
在解耦表征学习中,由于关于表征后验分布(q)满足结构化假设(qleft(X mid Dright)=qleft(X mid D, Yright)),因此上述等式的最后一项就消失了:
Ileft(X ; Y mid Dright) &= Hleft(X mid Dright)-Hleft(X mid D, Yright)
&=Hleft(X mid Dright)-Hleft(X mid Dright)=0
end{aligned}
tag{13}
]
这样我们就有:
Ileft(X ; Yright) &overset{(1)}{=}Ileft(D; Xright)-Ileft(D ; X mid Yright)
& overset{(2)}{=}Ileft(D ; Xright)+Ileft(D ; Yright)-Ileft(D ; X, Yright)
end{aligned}
tag{14}
]
上述的((1))是由于(I(X; Y mid D)=0),((2))是由于互信息的链式法则即(I(D; X, Y)=I(D; Y) + I(D; X mid Y))。
对(I(X, Y))等价变换至此,真相已经逐渐浮出水面:我们可以可以通过最小化(Ileft(D ; Xright))、(Ileft(D ; Yright)),最大化(Ileft(D ; X, Yright))来完成对(I(X, Y))的最小化。其直观的物理意义也就是惩罚表征(X)和(Y)中涵盖的总信息,并使得(X)和(Y)共同和数据(D)相关联。
基于我们在(3.1)、(2.1)中所推导的(I(D; X))、(I(D, Y))的变分上界与(I(D; X, Y))的变分下界,我们就得到了(I(X, Y))的变分上界:
Ileft(X ; Yright) &leq mathbb{E}_{p(D)}left[D_{text{K L}}(q(x mid D) | p(x)) + D_{text{K L}}(q(y mid D) | p(y))right]
&+ mathbb{E}_{p(D)}left[mathbb{E}_{q(x | D)q(y|D)}[log p(D mid x, y)]right]
end{aligned}
tag{15}
]
直观地看,上式地物理意义为使后验(q(xmid D))、(q(ymid D))都趋近于各自的先验分布(一般取高斯分布),并减小(X)和(Y)对(D)的重构误差,直觉上确实符合表征解耦的目标。
4 总结
总结起来,互信息的所有上下界可以表示为下图[2](包括我们前面提到的(I_{text{BA}})、(I_{text{UBA}})、(I_{text{DV}})、(I_{text{MINE}})、(I_{text{InfoNCE}})等):
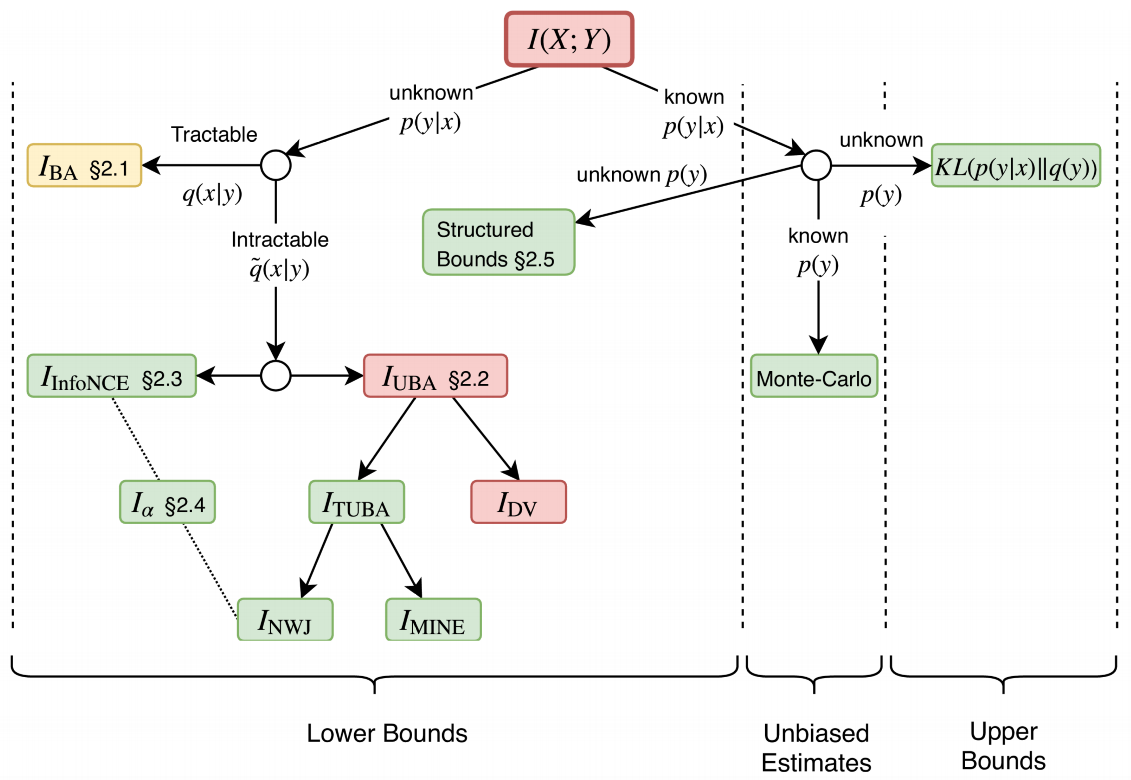
图中节点的代表了它们估计与优化的易处理性:绿色的界表示易估计也易于优化,黄色的界表示易于优化但不易于估计,红色的界表示既不易于优化也不易于估计。孩子节点通过引入新的近似或假设来从父亲节点导出。
参考
- [1] Cover T M. Elements of information theory[M]. John Wiley & Sons, 1999.
- [2] Poole B, Ozair S, Van Den Oord A, et al. On variational bounds of mutual information[C]//International Conference on Machine Learning. PMLR, 2019: 5171-5180.
- [3] Tishby N, Pereira F C, Bialek W. The information bottleneck method[J]. arXiv preprint physics/0004057, 2000.
- [4] Alemi A A, Fischer I, Dillon J V, et al. Deep variational information bottleneck[J]. arXiv preprint arXiv:1612.00410, 2016.
- [5] Belghazi M I, Baratin A, Rajeshwar S, et al. Mutual information neural estimation[C]//International conference on machine learning. PMLR, 2018: 531-540.
- [6] Hjelm R D, Fedorov A, Lavoie-Marchildon S, et al. Learning deep representations by mutual information estimation and maximization[J]. arXiv preprint arXiv:1808.06670, 2018.
- [7] Barber D, Agakov F. The im algorithm: a variational approach to information maximization[J]. Advances in neural information processing systems, 2004, 16(320): 201.
- [8] Rainforth T, Cornish R, Yang H, et al. On nesting monte carlo estimators[C]//International Conference on Machine Learning. PMLR, 2018: 4267-4276.
- [9] Mathieu E, Rainforth T, Siddharth N, et al. Disentangling disentanglement in variational autoencoders[C]//International conference on machine learning. PMLR, 2019: 4402-4412.
- [10] Oord A, Li Y, Vinyals O. Representation learning with contrastive predictive coding[J]. arXiv preprint arXiv:1807.03748, 2018.
- [11] Variational Interaction Information Maximization for Cross-domain Disentanglement
- [12] Alemi A, Poole B, Fischer I, et al. Fixing a broken ELBO[C]//International conference on machine learning. PMLR, 2018: 159-168.
- [13] Rezende D J, Mohamed S, Wierstra D. Stochastic backpropagation and approximate inference in deep generative models[C]//International conference on machine learning. PMLR, 2014: 1278-1286.
- [14] Kingma D P, Welling M. Auto-encoding variational bayes[J]. arXiv preprint arXiv:1312.6114, 2013.
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
大促备战,最大的隐患项之一就是慢SQL,对于服务平稳运行带来的破坏性最大,也是日常工作中经常带来整个应用抖动的最大隐患,在日常开发中如何避免出现慢SQL,出现了慢SQL应该按照什么思路去解决是我们必须要知道的。本文主要介绍对于慢SQL的排查、解决思路,通过一个…
