
开发者趋向于将关注点放在数据上,而不是领域上。这对于DDD新手来说也是如此,因为在软件开发中,数据库依然占据着主导地位。我们首先考虑的是数据的属性(对应数据库的列)和关联关系(外键关联),而不是富有行为的领域概念。这样做的结果是将数据模型直接反映在对象模型上,导致那些表示领域模型的实体包含了大量的getter和setter方法。另外,还存在大量的工具可以帮助我们生成这样的实体模型。虽然在实体模型中加入getter和setter并不是什么大错,但这却不是DDD的做法。
为什么使用实体
当我们需要考虑一个对象的个性特征,或者需要区分不同的对象时,我们引入实体这个领域概念。一个实体是一个唯一的东西,并且可以在相当长的一段时间内持续地变化。我们可以对实体做多次修改,故一个实体对象可能和它先前的状态大不相同。但是,由于它们拥有相同的身份标识,它们依然是同一个实体。
随着对象的改变,我们可能会跟踪这样的改变过程,比如什么时候发生了改变,发生了什么改变,是谁做出的改变等。也或者,当前对象已经包含了足够的先前状态的改变信息,此时我们便没必要显式地对对象状态进行跟踪。即便我们并不打算跟踪对象的每一个变化细节,我们也应该慎重对待在对象整个生命周期中所发生的合法改变。唯一的身份标识和可变性(mutability)特征将实体对象和值对象区分开来。
实体的具体定义可以参考《领域驱动设计》。
唯一标识
在实体设计早期,我们将刻意地把关注点放在能体现实体身份唯一性的主要属性和行为上,同时还将关注如何对实体进行查询。另外,我们还会刻意地忽略掉那些次要的属性和行为。
在设计实体时,我们首先需要考虑实体的本质特征,特别是实体的唯一标识和对实体的查找,而不是一开始便关注实体的属性和行为。只有在对实体的本质特征有用的情况下,才加入相应的属性和行为。
那么,首先我们应该怎么做呢?找到多种能够实现唯一标识性的方法是非常重要的,同时我们还应该考虑如何在实体的生命周期内维持它的唯一性。
值对象可以用于存放实体的唯一标识。值对象是不变的,这可以保证实体身份的稳定性,并且与身份相关的行为也可以得到集中处理。这样,我们便可以避免将身份标识相关的行为泄漏到模型的其他部分或者客户端中。
实体的唯一标识并不见得一定有助于对实体的查找和匹配。将唯一标识用于实体匹配通常取决于标识的可读性。比如,如果系统提供根据人名查找功能,但此时一个Person实体的唯一标识极有可能不是人名,因为存在大量重名的情况。另一方面,如果一个系统提供根据公司税号的查找功能,此时税号便可以作为Company实体的唯一标识,因为政府为每个公司分配了唯一的税号。
以下是一些常用的创建实体身份标识的策略,从简单到复杂依次为:
- 用户提供一个或多个初始唯一值作为程序输入,程序应该保证这些初始值是唯一的。
- 程序内部通过某种算法自动生成身份标识,此时可以使用一些类库或框架,当然程序自身也可以完成这样的功能。
- 程序依赖于持久化存储,比如数据库,来生成唯一标识。
- 另一个限界上下文已经决定出唯一标识,这作为程序的输入,用户可以在一组标识中进行选择。
委派标识
有些ORM工具,比如Hibernate,通过自己的方式来处理对象的身份标识。Hibernate更倾向于使用数据库提供的机制,比如使用一个数值序列来生成实体标识。如果我们自己的领域需要另外一种实体标识,此时这两者将产生冲突。为了解决这个问题,我们需要使用两种标识,一种为领域所使用,一种为ORM所使用,在Hibernate中,这被称为委托标识(Surrogate Identity)。
通常来说,委派标识采用long和int类型。同时,我们还需要相应地在数据库中创建一个列来保存该委派标识,并加上逐渐约束。
对外界来说,我们最好将委派标识隐藏起来,因为委派标识并不是领域模型的一部分,而将委派标识暴露给外界可能造成持久化漏洞。
此时,我们可以使用层超类型(Layer Supertype):
public abstract class IdentifiedDomainObject implements Serializable { private long id = -1; public IdentifiedDomainObject() { super (); } protected long id() { return this.id; } protected void setId(long anId) { this.id = anId; } }
这里的 IdentifiedDomainObject 便是层超类型,这是一个抽象基类,通过 protected 关键字,它向客户端隐藏了委派主键。所有实体都扩展自该抽象基类。在实体所处的模块之外,客户端根本不关心 id 这个委派标识。我们甚至可以将protected 换为 private 。Hibernate 既可以通过 getter 和 setter 方法来访问属性,也可以通过反射机制直接访问属性,故无论是使用protected 还是 private 都是无关紧要的。另外,层超类型还有其他好处,比如支持乐观锁,在聚合部分将会讲到。
标识稳定性
在多数情况下,我们都不应该修改实体的唯一标识,这样可以在实体的整个生命周期中保持标识的稳定性。
我们可以通过一些简单的措施来确保实体标识不被修改。此时,我们可以将标识的setter方法向客户端隐藏起来。我们也可以在setter方法中添加逻辑以确保标识在已经存在的情况下不会再被更新,比如可以使用一些断言语句:
public class User extends Entity { ... protected void setUsername (String aUsername){ if(this.username != null) { throw new IllegalStateException("The username may not be changed."); } if (aUsername == null) { throw new IllegalArgumentException( "The username may not be set to null."); } this.username = aUsername; } ... }
以上这个setter方法并不会阻碍Hibernate对对象的重建,因为对象在创建时,它的属性都是使用默认值,并且采用无参数构造函数,因此username属性的初始值为null。
发现实体及其本质特征
在通用语言的术语中,名词用于给概念命名,形容词用于描述这些概念,而动词则表示可以完成的操作。但是,如果我们认为对象就是一组命名的类和在类上定义的操作,除此之外并不包含其他内容,那么,我们就错了。在领域模型中还可以包含很多其他内容。团队讨论和规范文档可以帮助我们创建更有意义的通用语言。到最后,团队可以直接使用通用语言来进行对话,而此时的模型也能够非常准确地反映通用语言。
如果一些特定的领域场景会在今后继续使用,这时可以用一个轻量的文档将它们记录下来。简单形式的通用语言可以是一组术语和一些简单的用例场景。但是,如果我们就此认为通用语言只包含术语和用例场景,那么我们又错了。在最后,通用语言应该直接反映在代码中,而要保持设计文档的实时更新是非常困难的。
揭开实体及其本质特征的面纱
挖掘实体的关键行为
角色和职责
建模的一个方面便是发现对象的角色和职责。通常来说,对角色和职责分析是可以应用在领域对象上的。这里我们特别关注的是实体的角色和职责。
领域对象扮演多种角色
在面向对象编程中,通常由接口来定义实现类的角色。在正确设计的情况下,一个类对于每一个它所实现的接口来说,都存在一种角色。如果一个类没有显式的角色—即该类没有实现任何显式的接口,那么在默认情况下它扮演的即是本类的角色。也即,该类的公有方法表示该类的隐式接口。比如,上面的User类并没有实现任何接口,但是它依然扮演了一种角色,即User角色。由于User实体中有一些“人”的属性,所以定义一个Person值对象。
我们可以使用一个对象同时扮演User和Person的角色,虽然这并不是我所建议的,但就目前而言,让我们假设这是一个好主意。这样一来,我们便没有必要在User中引用一个Person了,而是只需要创建一个对象来同时扮演这两种角色即可。
那我们为什么要这么做呢?通常是因为两个或对象既有相似之处,又有不同之处。此时,这些对象上重叠的属性可以通过一个实现了多个接口的对象来表示。比如,我们可以创建一个HumanUser对象,该对象既是一个User,又是一个Person:
public interface User { ... } public interface Person { ... } public class HumanUser implements User,Person{ ... }
以上代码看似合乎情理的,但是它也可能使事情变得复杂。如果两个接口都是复杂的,那么HumanUser对象实现起来将是困难的。另外,如果User不是一个人,而是一个系统又该怎么办呢?此时我们可能需要3个接口,而要设计一个实现了这3个接口的对象将变得更加困难。我们可能需要创建一个通用的Principal(委托)来简化这个问题:
public interface User{ ... } public interface Principal { ... } public class UserPrincipal implements User, Priincipal{ ... }
有了以上代码,我们可以直到运行时才决定一个Principal的类型。一个人对应的Principal和一个系统对应的Principal在实现上是不同的。一个系统不需要拥有像人一样的联系信息。另外,我们还可以通过委派的方式来实现以上两个接口,此时我们需要在运行时检查存在哪种类型的Principal,再将逻辑委派给这个实际的Principal对象:
public interface User {
...
} public interface Principal{ public Name principalName();
...
} public class PersonPrincipal implements Principal (
...
} public class SystemPrincipal implements Principal{
...
} public class UserPrincipal implements User, Principal{ private Principal personPrincipal; private Principal systemPrincipal; public Name principalName(){ if (personPrincipal != null) { return personPrincipal.principalName();
} else if(systemPrincipal!=null){
return systemPrincipal.principalName();
}else {
throw new IllegalStateException("The principal is unknown.");
}
}
以上代码设计存在多个问题,其中之一便是对象分裂症(Object Schizophrenia)(即表示一个具有多重身份的对象)。对象的行为通过技术上的转向和分发来进行委派。无论是personPrincipal 还是systemPrincipal 它们都不具有 UserPrincipal 实体的身份标识,而UserPrincipal 才是行为的最初执行对象。
对象分裂症的描述是:委派对象根本不知道原来被委派对象的身份标识,因此我们无法知道委派对象的真正身份。虽然并不是所有的委派对象都需要知道被委派对象的身份标识,但是在有些情况下的确是有必要的。我们可以向 principalName() 传入一个 UserPrincipal 对象的引用,但这使设计变得更加复杂,并且需要改变 Principal 接口,因此显然是不好的。“委派只有在使问题简化而不是复杂时,才是好的。”
以下两项需求有助于我们设计出好的接口:
- 向一个客户添加订单。
- 使客户成为优先(Preferred)客户。
Customer类实现了两个细粒度的角色接口:IAddOrdersToCustomer 和 IMakeCustomerPreferred。每一个接口都制定一个了单个操作,如图。我们甚至还可以使Customer实现另外的接口,比如IValidator。
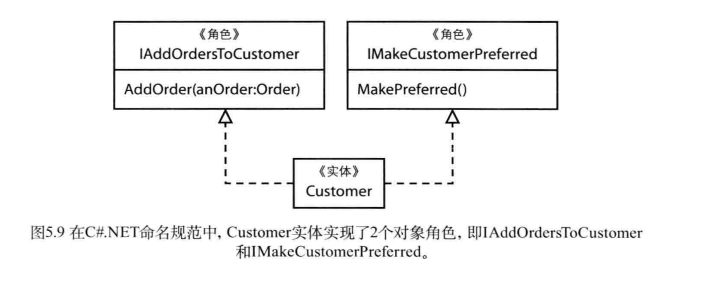
在聚合中会提到,我们并不希望创建一个拥有大量对象的集合,比如向Customer中添加大量的订单。但是,这并不是我们当前的重点,这里的重点是演示对象角色的使用。
这种风格能给我们带来哪些好处?实体的角色可以在不同的用例之间发生转变。将一个新的Order实例添加到Customer,或者使用Customer变成优先客户,在这两种情况下一个Customer所扮演的角色是不同的。同时,这种风格还有技术上的好处,不同的用例所使用的Customer获取策略可能是不同的:
IMakeCustomer Preferred customer = session. Get(customerid); customer.MakePreferred(); ... IAddOrdersToCustomer customer = session.Get(customerId) customer.AddOrder(order);
通过使用泛型,持久化机制从基础设施中查找不同的获取策略。如果某个接口没有特殊的获取策略,那么将使用默认的获取策略。在使用特定的获取策略时,所获取的Customer能够满足特定的用例。
当然,还存在其他的特定于某个用例的行为可以与角色联系起来,比如验证功能,在实体被持久化时,它可以充当验证器的角色对自身进行数据验证。
好的接口设计也有助于实现类,比如Customer,将功能实现在其自身上,而没有必要将实现委派给其他类,对象分裂症也由此得到避免。
将Customer的行为通过角色进行划分是否能给领域建模带来好处?我们可以将前面的Customer和下图中的Customer做个对比,哪个更好?当需要调用MakePreferred() 方法时,下图中的Customer是否更容易引导客户端错误地调用成AddOrder() 方法?但这并不是唯一的评判标准。
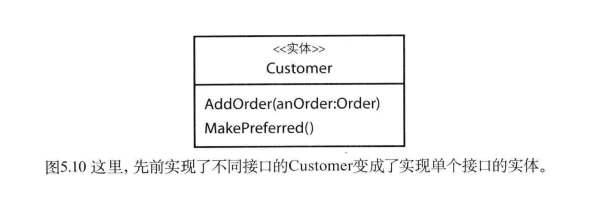
角色接口最实用之处可能也是其最简单之处。通过接口,我们可以将实现细节隐藏起来,从而不至于将实现细节泄漏到客户端中。我们所设计的接口应该刚好能够满足客户端的需求,不多也不少。实现类可以比接口复杂得多,它可以拥有大量支撑属性,外加这些属性的getter和setter方法。但是,客户端是看不到这些实现细节的。
不管采用哪种设计方式,我们都应该确保领域语言优先于技术实现。在DDD中,业务领域的模型才是最重要的。
创建实体
当我们新建一个实体时,我们希望通过构造函数来初始化足够多的实体状态,这一方面有助于表明该实体的身份,另一方面可以帮助客户端更容易地查找该实体。在使用及早生成唯一标识的策略时,构造函数至少需要接受一个唯一标识作为参数。如果我们还有可能通过其他方式对实体进行查找,比如名字或描述信息,那么应该将这些参数也一并传给构造函数。
有时一个实体维护了一个或多个不变条件。不变条件即是整个生命周期中都必须保持事务一致性的一种状态。不变条件主要是聚合所关注的,但是由于聚合根通常也是实体,故这里我们也稍作提及。如果实体的不变条件要求该实体所包含的对象都不能为null状态,或者由其他状态计算所得,那么这些状态需要作为参数传递给构造函数。
每一个User对象都必须包含tenantId、username、password和person属性。换句话说,在User对象得到正确实例化之后,这些属性绝对不能为null。User对象的构造函数和实例变量对象的setter方法保证了这一点:
public class User extends Entity { protected User(TenantId aTenantId, String aaUsername String aPassword, Person aPerson){ this (); this.setPassword(aPassword); this.setPerson(aPerson); this.setTenantId (aTenantId); this.setUsername (aUsername); this.initialize(); } protected void setPassword(String aPasswordd){ if (aPassword == null) { throw new IllegalArgumentException ( "The passwordmay not be set to null."); } this.password = aPassword; } protected void setPerson (Person aPerson) { if (aPerson == null) { throw new IllegalArgumentException( "The person may not be set to null."); } this.person = aPerson; } protected void setTenantid(Ten服务器托管网antId aTenantid){ if(aTenantId== null) { throw new IllegalArgumentException( "The tenantId may not be set to null."); } this.tenantId = aTenantId; } protected void setUsername(String aUsername) { if(this.username != null){ throw new IllegalStateException ( "The username may not be changed."); } if(aUsername == null){ throw new IllegalArgumentException( "The username may not be set to null."); } this.username = aUsername; }
}
User对象展示了一种自封装性。在构造函数对实例变量赋值时,它把操作委派给了实例变量所对应的setter方法,这样便保证了实例变量的自封装性。实例变量的自封装性使用setter方法来决定何时给实例变量赋值。每一个setter方法都“代表着实体”对所传进参数做非null检查,这里的断言称为守卫。在“标识稳定性”一节中我们讲到,setter方法的自封装性技术可能会变的非常复杂。
对于那些非常复杂的创建实体的情况,我们可以使用工厂,后面“工厂”部分会讲到。
验证
验证的主要目的在于检查模型的正确性,检查的对象可以是某个属性,也可以是整个对象,甚至是多个对象的组合。我们将对模型进行三个级别的验证。虽然有很多种验证方式,包括专门用于验证的框架和类库等,但这里主要讨论的是一些通用的验证方法。
验证可以达到不同的目的。即便领域对象的各个属性都是合法的,这也并不表示该对象作为一个整体是合法的。两个合法属性组合起来有可能使整个对象不合法。同样的道理,单个对象的合法性并不能保证对象组合的合法性。两个合法实体对象的组合有可能是不合法的。因此我们需要采用不同级别的验证来处理这些情况。
验证属性
我们如何确保属性处于合法状态呢?建议使用自封装性来验证属性。
Martin Fowler曾说:“自封装性要求无论以哪种方式访问数据,即使从对象内部访问数据,都必须通过getter和setter方法”。这种方式有诸多优点。首先它为对象的实例变量和类变量提供了一层抽象。其次,我们可以方便地在对象中访问其所引用对象的属性。重要的是,自封装性使验证变得非常简单。


在上面的代码中,setAddress() 方法中存在4个前置条件,所有的前置条件都对 anAddress 参数进行断言。
EmailAddress 类并不是一个实体,而是值对象。这里我们使用值对象是有原因的。首先它向我们展示了一个很好的前置条件验证的例子,从null检查到格式检查。其次,EmailAddress 是Person实体的属性,因此EmailAddress 和其他直接声明在Person中的简单属性一样。在为其他简单属性创建setter方法时,我们可以采用完全相同的方式对它们进行验证。在将一个整体值对象赋值给实体时,只有当值对象中的所有较小属性得到验证时,我们才能保证整体值对象的验证。
验证整体对象
虽然有时实体中的所有单个属性都是合法的,但是这并不意味着整个实体就是合法的。要验证整个实体,我们需要访问整个对象的状态——所有对象属性。此时我们可能还需要使用规范(Specification)或者策略(Strategy)来进行验证。
由于验证逻辑需要访问实体的所有状态,有人可能会直接将验证逻辑嵌入到实体对象中。这里我们需要注意,更多的时候验证逻辑比领域对象本身变化还快,而将验证逻辑嵌入在领域对象中也使领域对象承担了太多的职责。
此时我们可以创建一个单独的验证类来完成模型验证。
验证类可以实现规范模式或策略模式。当发现非法状态时,验证类将通知客户方或者记录下验证结果以便后用(比如,在批量处理完成之后)。验证过程应该收集到所有的验证结果,而不是一开始遇到非法状态时就抛出一场。考虑以下的例子:
////// 验证器抽象类 /// public abstract class Validator { //验证通知处理器程序 private ValidationNotificationHandler notificationHandler; public Validator(ValidationNotificationHandler aHandler) { this.SetNotificationHandler(aHandler); } /// /// 验证 /// public abstract void Validate(); /// /// 当前验证类的通知处理程序 /// /// protected ValidationNotificationHandler NotificationHandler() { return notificationHandler; } private void SetNotificationHandler(ValidationNotificationHandler aHandler) { notificationHandler = aHandler; } }
////// 通用验证通知处理器 /// public class ValidationNotificationHandler { private Liststring> errorList = new Liststring>(); //private public ValidationNotificationHandler() { } public void HandleError(string msg) { errorList.Add(msg); } public IReadOnlyCollectionstring> GetErrors() { return errorList; } }
public class WarbleValidator: Validator { private Warble warble; public WarbleValidator(Warble aWarble, ValidationNotificationHandler aHandler) :base(aHandler) { SetWarble(aWarble); } public override void Validate() { if (this.HasWarpedWarbleCondition(this.warble)) { this.NotificationHandler().HandleError("the warble is warped."); } if (this.HasWackyWarbleState(this.warble)) { this.NotificationHandler().HandleError("the warble has a wacky state."); } } private void SetWarble(Warble aWarble) { warble = aWarble; } }
在上面例子中,WarbleValidator 在初始化时传入了一个ValidationNotificationHandler 。任何时候,当发现非法状态时,WarbleValidator 都会调用ValidationNotificationHandler 来处理。ValidationNotificationHandler 是一个通用实现,它拥有一个HandleError 方法,该方法接收一个 String 类型的验证通知消息。我们可以将验证通知封装在方法中,这样一来,我们便将错误消息、消息通知与验证过程进行了解耦:
public class WarbleValidator: Validator { private Warble warble; public WarbleValidator(Warble aWarble, ValidationNotificationHandler aHandler) :base(aHandler) { SetWarble(aWarble); } private void SetWarble(Warble aWarble) { warble = aWarble; } public override void Validate() { CheckForWarpedWarbleCondition(); CHeckForWackyWarbleState(); } private void CheckForWarpedWarbleCondition() { if (this.HasWarpedWarbleCondition(this.warble)) { this.NotificationHandler().HandleError("the warble is warped."); } } private void CHeckForWackyWarbleState() { if (this.HasWackyWarbleState(this.warble)) { this.NotificationHandler().HandleError("the warble has a wacky state."); } } }
在这个例子中,我们使用了一个特定的ValidationNotificationHandler 。我们可以定义一个子类WarbleValidationNotificationHandler 继承自ValidationNotificationHandler,然后在WarbleValidator 使用子类。同时可以将各个消息通知方法封装在WarbleValidationNotificationHandler :
public class WarbleValidationNotificationHandler: ValidationNotificationHandler { public WarbleValidationNotificationHandler() { } public void HandleWarpedWarble() { this.HandleError("the warble is warped."); } public void HandleWackydWarbleState() { this.HandleError("the w服务器托管网arble has a wacky state."); } }
public class WarbleValidator: Validator { private Warble warble; public WarbleValidator(Warble aWarble, WarbleValidationNotificationHandler aHandler) :base(aHandler) { SetWarble(aWarble); } private void SetWarble(Warble aWarble) { warble = aWarble; } public override void Validate() { var handler = (WarbleValidationNotificationHandler)this.NotificationHandler(); CheckForWarpedWarbleCondition(handler); CHeckForWackyWarbleState(handler); } private void CheckForWarpedWarbleCondition(WarbleValidationNotificationHandler handler) { if (this.HasWarpedWarbleCondition(this.warble)) { handler.HandleWarpedWarble(); } } private void CHeckForWackyWarbleState(WarbleValidationNotificationHandler handler) { if (this.HasWackyWarbleState(this.warble)) { handler.HandleWackydWarbleState(); } } }
对于使用什么样的ValidationNotificationHandler 类型,验证类和客户端应该达成一致。
客户端如何保证对实体的验证确实发生了?验证过程又从何处开始?
要将Validate() 方法应用在所有需要验证的实体上,我们可以使用层超类型:
public abstract class Entity { public Entity() { Validate(); } public virtual void Validate() { } }
任何继承自Entity 的类都可以安全地调用Validate 方法。如果具体的实体类拥有自身的验证逻辑,该验证逻辑将被执行,否则Validate 方法不做任何事情。同时,我们应该只在需要进行验证的实体中才重写 Validate 方法。
然而,实体应该进行自我验证吗?拥有Validate 方法并不表示需要实体自行执行验证过程。此时实体可以将验证过程交给单独的验证类:
public class Warble: Entity { public Warble() { } public override void Validate() { var notificationHandler = new WarbleValidationNotificationHandler(); new WarbleValidator(this, notificationHandler) .Validate(); if (notificationHandler.HasError()) { throw new Exception("这里可以发送报错信息"); } } }
每一个专有的Validator 都会执行特定的验证过程。实体类不用知道验证过程是如何发生的。单独的Validator 也将验证逻辑的变化与实体对象本身的变化分离开来,并且有助于对复杂验证过程的测试。
验证对象组合
在需要对复杂对象进行验证时,我们可以使用延迟验证。这里我们关注的并不只是某个单独的实体是否合法,而是多个实体的组合是否全部合法,包括一个或多个聚合实例。要达到这样的目的,我们需要创建继承自Validator 的不同验证类的实例。但是,最好的方式是把验证过程创建成一个领域服务。该领域服务可以通过资源库读取那些需要验证的聚合实例,然后对每个实例进行验证,可以是单独验证,也可以和其他聚合实例组合起来验证。
在任何时候,我们都需要决定是否可以展开验证。有时某个聚合或一组聚合可能处于临时的、中间的状态。此时我们可以在聚合上创建一个状态标识来避免这些状态的验证。当验证条件成熟时,模型通过发送领域事件的方式通知客户方。
在领域驱动设计(DDD)中,延迟验证可以通过以下步骤实现:
1. 定义聚合根和聚合实体:首先,你需要明确聚合根和聚合实体的概念。聚合根是聚合的起始点,负责维护聚合的状态。聚合实体是与聚合根相关联的其他对象。
2. 确定验证时机:确定何时进行验证。在DDD中,验证通常在聚合根上执行,而不是在实体上执行。这意味着验证逻辑应该集中在聚合根上,而不是分散在整个聚合中。
3. 实现验证逻辑:在聚合根中实现验证逻辑。你可以使用领域服务或工厂来获取对其他聚合根的引用,并在聚合根上调用适当的方法来执行验证。
4. 延迟验证:将验证逻辑推迟到真正需要验证的时间点上执行。这可以通过在聚合根上定义方法来实现,该方法将在适当的时机调用验证逻辑。例如,你可以在保存聚合根或执行某些关键操作时调用该方法。
5. 处理无效状态:如果验证失败,即验证逻辑发现聚合处于无效状态,你需要处理这种情况。你可以抛出异常或返回错误信息,以便调用者能够采取适当的措施。
通过以上步骤,你可以在DDD中实现延迟验证,将验证逻辑集中在聚合根上,并在适当的时间点上推迟验证操作。这样可以提高代码的可维护性和可读性,同时减少不必要的验证和资源消耗。
跟踪变化
根据实体的定义,我们没必要在整个生命周期中对状态的变化进行跟踪,而是只需要跟踪那些持续改变的状态。然而,有时领域专家可能会关心发生在模型中的一些重要事件,此时我们便应该对实体的一些特殊变化进行跟踪了。
跟踪变化最实用的方法是领域事件和事件存储。我们为领域专家所关心的所有状态改变都创建单独的事件类型,事件的名字和属性表明发生了什么样的事件。当命令操作执行完后,系统发出这些领域事件。事件的订阅方可以接收发生在模型上的所有事件。在接收到事件后,订阅方将事件保存在事件存储中。
领域专家并不会关心发生在模型中的所有变化,但这却是技术团队所应该关心的。可以参考事件源模式。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
微附件是一款设计用于管理公众号附件的便捷工具。它让运营者能简单地上传和管理各种格式的文件,如Word、Excel、PPT、PDF、TXT等,并允许用户直接下载这些文件。由于公众号本身不提供这种功能,因此微附件就发挥了很大的作用。 1、首先,只需在浏览器中输入下…
