
①索引的类型:
— B-Tree索引:
加快访问数据的速度,因为存储引擎不再需要全表扫描而是
从索引根节点开始搜索
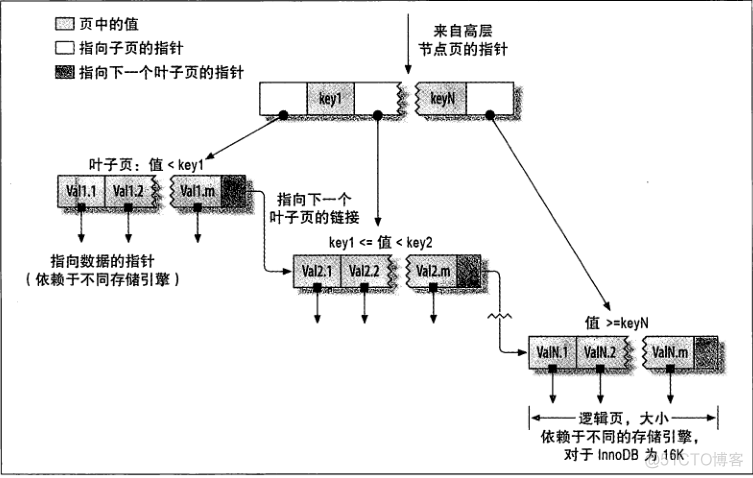
使用范围: 全值匹配、最左前缀、列前缀、范围值、精确匹配某一列并范围匹配另一列、只访问索引查询
注:索引列的 顺序
很重要!!! 比如:先用索引过滤然后 and一个like,因为like使索引
失效,如果放前面就会首先全部顺序检索。
— 哈希索引:
自动哈希索引(当注意到 某些索引用的频繁时开启)
对于不支持哈希的,可模拟创建如下:
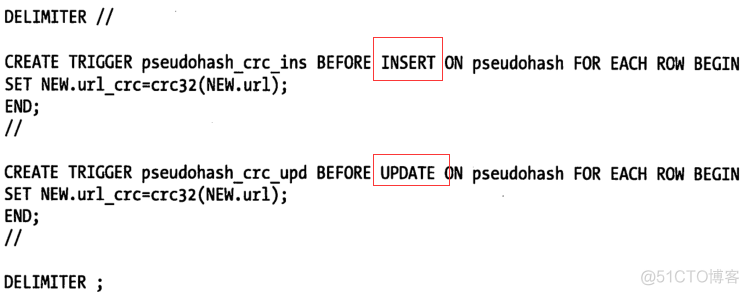
假如本身以URL为索引如下:
SELECT id FROM url WHERE url=’http://www.mysql.com’;
以上做法存储大,查询性能慢,对此可额外添加一索引列(url_crc)用于伪哈希,并删除url上索引

注:以上做法能提高性能但需要 触发器 维护索引
注:索引并不是最优解决方案,对于TB级数据应用块级别 元数据技术替代。
②高性能索引策略:
— 独立的列:索引列单独放在比较符号一侧
SELECT id FROM test WHERE id+1=5; X
— 前缀索引:对于过大数据,模拟哈希支持不好,此时用前缀索引替代(如对 BLOB、TEXT或过长VARCHAR必须用前缀索引)
首先判断索引建到多少合适:
select count(distinct left(time,5))/count(*) as no1, count(distinct left(time,6))/count(*) as no2, count(distinct left(time,7))/count(*) as no3, count(distinct left(time,8))/count(*) as no4,
count(distinct left(time,9))/count(*) as no5,
count(distinct left(time,10))/count(*) as no6,
count(distinct time)/count(*) as no
from test.demo;
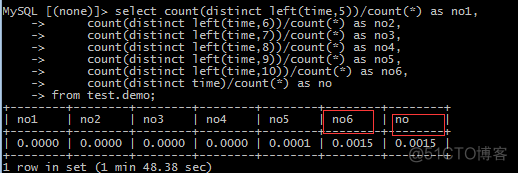
结果如下:从中找出 与no最相近的,这里是10,然后就可以建索引为–> ALTER TABLE test.demo ADD KEY (time(10));
— 多列索引:不少人会为每一个列建索引,这样联合查找时性能不佳(尽管mysql5.0以上会 自动将独立索引合并为 联合索引)
OR时可用 UNION ALL优化:

注:优化器不会吧独立索引自动合并计算到查询成本,导致成本低估。
— 选择合适索引列顺序:
where中将选择性最高的列放在最前列(趁早过滤完),选择方法如下:
select count(distinct id)/count(*) as no1, count(distinct uid)/count(*) as nofrom test.demo;
注:上面如果需要两个一起 做条件,则 选择较大值放前面(如no>no1,选no)
— 聚簇索引:暂不记录
— 覆盖索引:select的数据列只用从索引中就能够取得,不必从数据表中读取,如下列子:
EXPLAIN SELECTid,name
有时覆盖索引很难达到,这时候就部分覆盖(延迟关联):

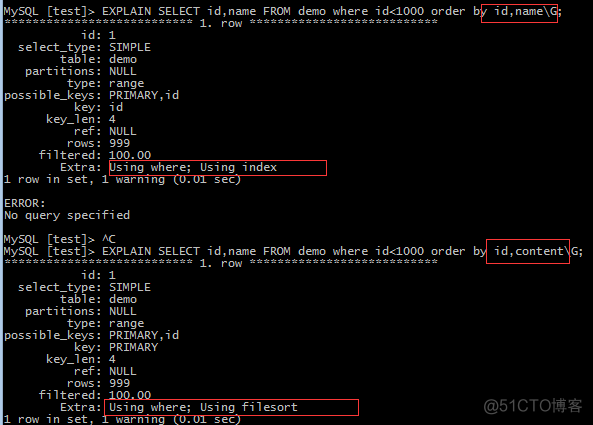
— 扫面索引排序:order by排序中的字段应全为索引列,如下:
EXPLAIN SELECT id,name FROM demo where id
EXPLAIN SELECT id,name FROM demo where id
— 前缀索引压缩:不多说,具体在CREATE TABLE中指定pack_keys控制
— 冗余和重复索引:有时候需要同时 多条件查询或独立查询,为了快速,可在同一列上 建立多种索引,如联合索引与独立索引(创建多种索引会是性能比单个 稍低)
例:创建(A, B),就不必创建(A),但如果要单独搜B,则要创建(B),因为 Innodb仅支持前缀(A是前缀,B不是)
注:where尽可能将 范围查询置于索引后面,如in、between.
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
