
代码
原文地址
预备知识:
1.什么是K-L散度(Kullback-Leibler Divergence)?
K-L散度,是一种量化两种概率分布P和Q之间差异的方式,又叫相对熵。在概率学和统计学上,我们经常会使用一种更简单的、近似的分布来替代观察数据或太复杂的分布。K-L散度能帮助我们度量使用一个分布来近似另一个分布时所损失的信息量。
2.什么是自训练(self-training)?
自训练算法是一种半监督学习算法,在这种算法中,学习者不断标记未标记的样本,并在一个扩大的标记训练集上对自己进行再训练。由于自训练过程可能会错误地标记一些未标记的示例,因此有时学习到的假设不能很好地执行。
摘要
文档级关系抽取(DocRE)的目标是从文档中找出所有实体之间的关系。为了提高DocRE的效果,需要利用证据,也就是包含实体关系线索的句子,来筛选出相关的文本。但是,DocRE中的证据检索(evidence retrieval,ER)存在两个主要挑战:内存消耗过大和缺乏标注数据。本文针对这些问题,提出了一种提升ER在DocRE中应用的方法。首先,本文设计了DREEAM,这是一种节省内存的模型,它利用证据信息作为监督信号,指导DocRE模型的注意力机制更加关注证据。其次,采用了一种自训练的策略,让DREEAM能够从大量无标注的数据中自动学习ER,而不需要人工标注证据。实验结果显示,DREEAM在DocRED数据集上,在DocRE和ER两个任务上都达到了最优的性能。
1 Introduction
证据句:包含实体对之间关系线索的一组句子。

如图1所示,确定Prince Edmund和Blackadder之间的关系,只需阅读第1句和第2句,它们就是证据句。第5句和第6句虽然也提到了Edmund,但与它们二者的关系无关。
提取证据句面临的两个问题:
(1)现有的ER方法都占用太多内存
以前的系统把ER和DocRE当作两个独立的任务,需要额外的神经网络层来同时学习ER和DocRE(Huang等人, 2021a;Xie等人, 2022; Xiao等人, 2022)。ER模块一般用一个双线性分类器,输入是实体对的嵌入和句子的嵌入。为了得到每个句子对每个实体对的证据分数,该模块要遍历所有的(实体对,句子)组合。这样的计算大大增加了内存的消耗,尤其是在句子和实体很多的文档中。
(2)人工标注证据的资源很少
DocRE的金标准数据比句子级的数据更难获得。人工标注的成本很高,而低成本的证据标注方法还缺乏研究。即使利用远程监督自动生成RE的银标准数据,从文档中筛选出与RE实例相关的证据也是一项挑战。
为了节省内存,本文提出了一种结合DocRE和ER的高效方法,即基于证据引导的注意机制的文档级关系抽取(DREEAM)。本文基于ATLOP(Zhou等人, 2021),这是一种广泛应用于前人研究的基于Transformer的DocRE系统。本文不需要外部的ER模块,而是直接让DocRE系统专注于证据。具体来说,本文对实体对的局部上下文嵌入进行监督学习。局部上下文嵌入是根据编码器的注意力机制,对所有词嵌入进行加权平均得到的,它被训练为对证据赋予更高的权重,对其他部分赋予更低的权重。
为了解决证据标注的不足,本文提出了一种弱监督的ER方法,它基于DREEAM在大量的无标注数据上进行自训练。这些无标注数据是通过远程监督自动添加关系标签的,但没有证据标签。目标是利用人工标注数据的指导,让ER知识在无标注数据上逐渐积累和扩展。具体来说,先用一个在人工标注数据上预训练的教师模型,从无标注数据中筛选出可靠的证据作为银色证据。然后,用这些银色证据来训练一个学生模型,同时实现RE和ER的目标。最后,在人工标注数据上对学生模型进行微调,以优化其效果。在DocRED数据集上的实验表明,本文的方法在RE和ER方面都取得了最佳的性能。
2 Preliminary
2.1 Problem Formulation
给定一个文档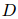 ,它由一组句子
,它由一组句子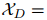
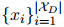 和一组实体
和一组实体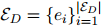 组成。DocRE的目标是预测文档中每一对实体之间的所有可能的关系。文档中的每一个实体
组成。DocRE的目标是预测文档中每一对实体之间的所有可能的关系。文档中的每一个实体 至少有一个专有名词指称,用
至少有一个专有名词指称,用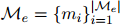 表示。文档中的每一对实体
表示。文档中的每一对实体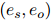 可以有多种关系,构成一个关系子集
可以有多种关系,构成一个关系子集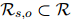 ,其中
,其中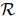 是一个预定义的关系集合。用
是一个预定义的关系集合。用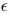 表示两个实体之间没有关系,也属于。另外,如果两个实体
表示两个实体之间没有关系,也属于。另外,如果两个实体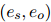 之间有一个有效的关系
之间有一个有效的关系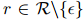 ,ER的目标是从文档中找出能够支持预测三元组
,ER的目标是从文档中找出能够支持预测三元组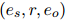 的证据句子集合
的证据句子集合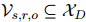 。
。
,它由一组句子和一组实体组成。DocRE的目标是预测文档中每一对实体之间的所有可能的关系。文档中的每一个实体至少有一个专有名词指称,用表示。文档中的每一对实体可以有多种关系,构成一个关系子集,其中是一个预定义的关系集合。用表示两个实体之间没有关系,也属于。另外,如果两个实体之间有一个有效的关系,ER的目标是从文档中找出能够支持预测三元组的证据句子集合。2.2 ATLOP
Text Encoding
编码前,在每个实体提及的首尾加上一个特殊的标记“*” 。然后,用一个基于Transformer的预训练语言模型对文档中的词元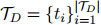 进行编码,得到每个词元的嵌入和跨词元的依赖。虽然原始的ATLOP只使用了最后一层的输出,但本文采用了最后三层的平均值(试点实验表明,使用最后3层比只使用最后一层的性能更好)。具体来说,对于每个Transformer层有d个隐藏维度的预训练语言模型,词元嵌入
进行编码,得到每个词元的嵌入和跨词元的依赖。虽然原始的ATLOP只使用了最后一层的输出,但本文采用了最后三层的平均值(试点实验表明,使用最后3层比只使用最后一层的性能更好)。具体来说,对于每个Transformer层有d个隐藏维度的预训练语言模型,词元嵌入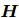 和跨词元依赖
和跨词元依赖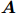 的计算公式如下:
的计算公式如下:
中的词元进行编码,得到每个词元的嵌入和跨词元的依赖。虽然原始的ATLOP只使用了最后一层的输出,但本文采用了最后三层的平均值(试点实验表明,使用最后3层比只使用最后一层的性能更好)。具体来说,对于每个Transformer层有d个隐藏维度的预训练语言模型,词元嵌入和跨词元依赖的计算公式如下: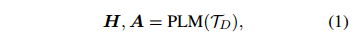
其中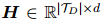 是每个词元在最后三层的隐藏状态的平均值,
是每个词元在最后三层的隐藏状态的平均值,
 是最后三层所有注意力头的注意力权重的平均值。
是最后三层所有注意力头的注意力权重的平均值。
是每个词元在最后三层的隐藏状态的平均值,是最后三层所有注意力头的注意力权重的平均值。Entity Embedding
ATLOP用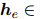
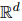 表示每个实体
表示每个实体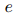 的嵌入,它是由它的所有提及的信息汇总而来的。具体而言,ATLOP采用了logsumexp池化方法。logsumexp池化的公式是:
的嵌入,它是由它的所有提及的信息汇总而来的。具体而言,ATLOP采用了logsumexp池化方法。logsumexp池化的公式是:
表示每个实体的嵌入,它是由它的所有提及的信息汇总而来的。具体而言,ATLOP采用了logsumexp池化方法。logsumexp池化的公式是: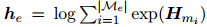
其中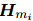 是提及
是提及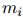 开始位置的特殊标记“*”的嵌入。
开始位置的特殊标记“*”的嵌入。
是提及开始位置的特殊标记“*”的嵌入。Localized Context Embedding
ATLOP提出了一种利用长文本信息的局部上下文嵌入方法,它根据实体对的重要性来选择词语。直观地说,对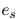 和
和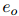 都有贡献的词语应该被更多地考虑。每个词语的重要性由公式1得到的词语之间的依赖关系决定。对于实体,它的所有提及
都有贡献的词语应该被更多地考虑。每个词语的重要性由公式1得到的词语之间的依赖关系决定。对于实体,它的所有提及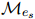 的词语依赖关系被收集并平均,得到每个词语对的重要性
的词语依赖关系被收集并平均,得到每个词语对的重要性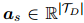 。然后,每个词语对实体对的重要性
。然后,每个词语对实体对的重要性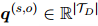 ,由
,由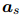 和
和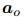 计算得到:
计算得到:
的重要性来选择词语。直观地说,对和都有贡献的词语应该被更多地考虑。每个词语的重要性由公式1得到的词语之间的依赖关系决定。对于实体,它的所有提及的词语依赖关系被收集并平均,得到每个词语对的重要性。然后,每个词语对实体对的重要性,由和计算得到: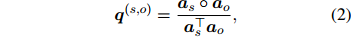
其中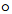 表示哈达玛积。
表示哈达玛积。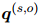 是一个分布,反映了每个词语对实体对的重要性。接下来,ATLOP执行一个局部上下文池化:
是一个分布,反映了每个词语对实体对的重要性。接下来,ATLOP执行一个局部上下文池化:
表示哈达玛积。是一个分布,反映了每个词语对实体对的重要性。接下来,ATLOP执行一个局部上下文池化: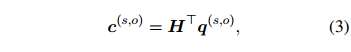
其中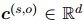 是所有词语嵌入的加权平均,权重由决定。
是所有词语嵌入的加权平均,权重由决定。
是所有词语嵌入的加权平均,权重由决定。Relation Classification
为了预测实体对之间的关系,ATLOP 首先生成了考虑上下文的头实体和尾实体表示:
之间的关系,ATLOP 首先生成了考虑上下文的头实体和尾实体表示: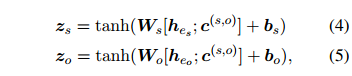
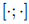 表示两个向量的拼接,其中
表示两个向量的拼接,其中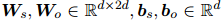 为可训练参数。然后,在上下文感知表示上应用双线性分类器来计算关系分数
为可训练参数。然后,在上下文感知表示上应用双线性分类器来计算关系分数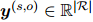 :
: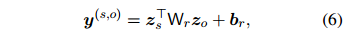
其中,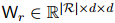 和
和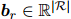 是可训练参数。因此,实体与之间关系
是可训练参数。因此,实体与之间关系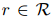 成立的概率为
成立的概率为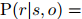
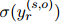 ,其中
,其中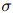 为sigmoid函数。
为sigmoid函数。
和是可训练参数。因此,实体与之间关系成立的概率为,其中为sigmoid函数。Loss Function
ATLOP 提出了一种自适应阈值损失(ATL),它在训练过程中学习一个虚拟的阈值类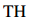 ,作为每个关系类的动态阈值。对于每一对实体,ATL 强制模型对正向关系类
,作为每个关系类的动态阈值。对于每一对实体,ATL 强制模型对正向关系类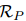 产生高于的分数,对负向关系类
产生高于的分数,对负向关系类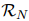 产生低于的分数,如下式所示:
产生低于的分数,如下式所示:
,作为每个关系类的动态阈值。对于每一对实体,ATL 强制模型对正向关系类产生高于的分数,对负向关系类产生低于的分数,如下式所示:
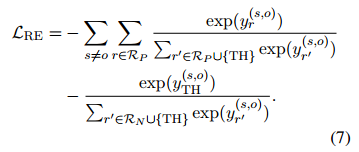
设置阈值类的想法类似于Flexible threshold (Chen等人, 2020)。
3 Proposed Method: DREEAM
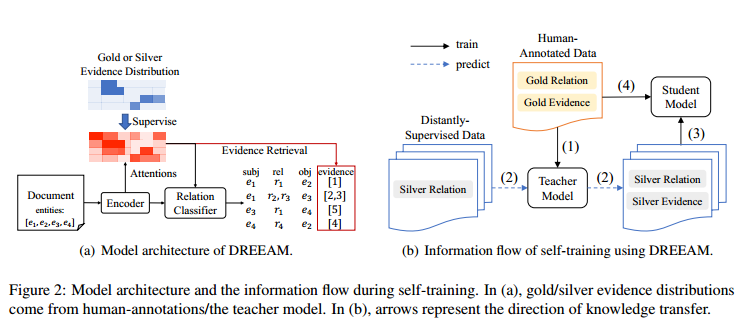
为了进行信息过滤,ATLOP利用基于Transformer的编码器计算了一个基于注意力权重的局部上下文嵌入。这是基于这样一个基本原理:Transformer层中的注意力权重能够编码跨词依赖关系。本文提出的DREEAM通过引入证据信息来增强ATLOP的效果。具体来说,它对注意力模块进行了监督,使其在确定关系时,更多地关注有用的证据句子,而不是其他无关的句子。DREEAM可以用于有监督和自监督的训练,它们的架构相同,但使用了不同的监督信号,如图2(a)所示。另外,本文还参考了Tan等人(2022a)的工作,提出了一个实现ER自监督的流程,其数据流如图2(b)所示。该流程包括以下几个步骤:首先,在人工标注的数据上训练一服务器托管网个带有金标准关系和证据标签的教师模型;然后,用教师模型预测远程监督的数据的银标准证据;接着,在远程监督的数据上训练一个学生模型,用银标准证据来监督ER;最后,在人工标注的数据上对学生模型进行微调,以优化其知识。
3.1 Teacher Model
本文用一个证据分布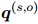 来为每一对实体
来为每一对实体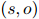 生成一个基于证据的局部上下文嵌入。可以给出和的词级别的重要性,但句级别的证据只能从人工标注中得到,如图1所示。为了弥补这个差距,本文对每个句子中的每个词的权重求和。具体来说,对于一个由词
生成一个基于证据的局部上下文嵌入。可以给出和的词级别的重要性,但句级别的证据只能从人工标注中得到,如图1所示。为了弥补这个差距,本文对每个句子中的每个词的权重求和。具体来说,对于一个由词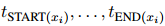 组成的句子
组成的句子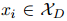 ,计算句子级别的重要性为:
,计算句子级别的重要性为:
来为每一对实体生成一个基于证据的局部上下文嵌入。可以给出和的词级别的重要性,但句级别的证据只能从人工标注中得到,如图1所示。为了弥补这个差距,本文对每个句子中的每个词的权重求和。具体来说,对于一个由词组成的句子,计算句子级别的重要性为:
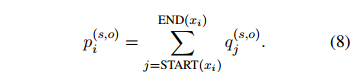
然后把所有句子的重要性汇总成一个分布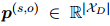 ,它反映了文档中每个句子对实体对的重要性。本文还用人工标注的证据分布来指导
,它反映了文档中每个句子对实体对的重要性。本文还用人工标注的证据分布来指导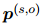 。首先,对于每个有效的关系标签
。首先,对于每个有效的关系标签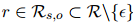 ,定义一个二值向量
,定义一个二值向量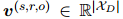 ,它标记了文档中的每个句子
,它标记了文档中的每个句子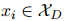 是否是关系三元组
是否是关系三元组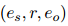 的证据。如果是,就设为1,否则为0。例如,如果
的证据。如果是,就设为1,否则为0。例如,如果 是的证据,那么
是的证据,那么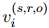 就设为1,否则为0。
就设为1,否则为0。
,它反映了文档中每个句子对实体对的重要性。本文还用人工标注的证据分布来指导。首先,对于每个有效的关系标签,定义一个二值向量,它标记了文档中的每个句子是否是关系三元组的证据。如果是,就设为1,否则为0。例如,如果是的证据,那么就设为1,否则为0。然后,对所有有效的关系求和,并归一化,得到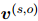 :
:
: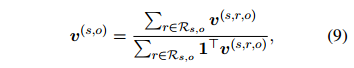
其中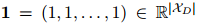 是一个全1向量。公式9的原理是,在关系分类器之前的模块并不显式地知道具体的关系类型。因此,引导编码器中的注意力模块产生与关系无关的词依赖。
是一个全1向量。公式9的原理是,在关系分类器之前的模块并不显式地知道具体的关系类型。因此,引导编码器中的注意力模块产生与关系无关的词依赖。
是一个全1向量。公式9的原理是,在关系分类器之前的模块并不显式地知道具体的关系类型。因此,引导编码器中的注意力模块产生与关系无关的词依赖。Loss Function
为了生成一个能够反映实体对之间关系的局部上下文嵌入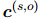 ,本文利用人工标注的证据
,本文利用人工标注的证据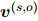 来指导每个实体对的证据分布。用K-L散度损失来训练模型,使
来指导每个实体对的证据分布。用K-L散度损失来训练模型,使
之间关系的局部上下文嵌入,本文利用人工标注的证据来指导每个实体对的证据分布。用K-L散度损失来训练模型,使尽可能地接近,从而减少两者之间的统计差异:
,从而减少两者之间的统计差异: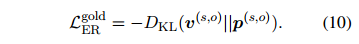
同时,用一个超参数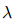 来调节ER损失和RE损失的权重,使模型能够同时优化两个目标:
来调节ER损失和RE损失的权重,使模型能够同时优化两个目标:
来调节ER损失和RE损失的权重,使模型能够同时优化两个目标: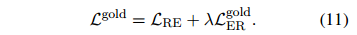
3.2 Student Model
为了在大规模数据上进行ER自训练,本文使用在人工标注数据上训练的系统作为教师模型。这些大规模数据是通过关系远程监督得到的,它们只有RE的噪声标签,没有ER的信息。本文在这些数据上训练一个学生模型,它的监督由两部分组成:一个是RE的二元交叉熵损失,另一个是ER的自训练损失。本文用教师模型的预测作为ER训练的监督信号。具体来说,先让教师模型在远程监督数据上进行推理,得到每个实体对的证据分布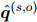 。然后,让学生模型学习复现每个实体对的证据分布。
。然后,让学生模型学习复现每个实体对的证据分布。
的证据分布。然后,让学生模型学习复现每个实体对的证据分布。Loss Function
自训练目标是和有监督训练一样的。用KL散度损失来训练学生模型的ER,公式如下:
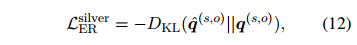
其中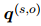 是学生模型对实体对的证据分布,由公式2得出。
是学生模型对实体对的证据分布,由公式2得出。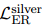 和
和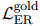 有两点不同。第一,是用句子级别的监督信号,而是用词级别的监督信号。这是因为词级别的证据分布更容易获得。在人工标注的数据上,要从句子级别的标注中得到词级别的证据分布很困难。在远程监督的数据上,词级别的证据分布可以从教师模型的预测中直接得到。所以,本文用词级别的证据分布来给ER自训练提供微观的监督。第二,只在有有效关系的实体对上计算,而在文档中的所有实体对上计算。这是因为远程监督数据上的关系标签不太可靠。这些关系标签是自动收集的,可能有些标注的关系和文档无关。所以,从自动标注中很难分辨哪些关系是有效的,哪些是无效的。为了避免漏掉重要的实例,本文对所有实体对计算损失。总的损失是由公式11中的超参数
有两点不同。第一,是用句子级别的监督信号,而是用词级别的监督信号。这是因为词级别的证据分布更容易获得。在人工标注的数据上,要从句子级别的标注中得到词级别的证据分布很困难。在远程监督的数据上,词级别的证据分布可以从教师模型的预测中直接得到。所以,本文用词级别的证据分布来给ER自训练提供微观的监督。第二,只在有有效关系的实体对上计算,而在文档中的所有实体对上计算。这是因为远程监督数据上的关系标签不太可靠。这些关系标签是自动收集的,可能有些标注的关系和文档无关。所以,从自动标注中很难分辨哪些关系是有效的,哪些是无效的。为了避免漏掉重要的实例,本文对所有实体对计算损失。总的损失是由公式11中的超参数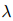 来平衡的,公式如下:
来平衡的,公式如下:
是学生模型对实体对的证据分布,由公式2得出。和有两点不同。第一,是用句子级别的监督信号,而是用词级别的监督信号。这是因为词级别的证据分布更容易获得。在人工标注的数据上,要从句子级别的标注中得到词级别的证据分布很困难。在远程监督的数据上,词级别的证据分布可以从教师模型的预测中直接得到。所以,本文用词级别的证据分布来给ER自训练提供微观的监督。第二,只在有有效关系的实体对上计算,而在文档中的所有实体对上计算。这是因为远程监督数据上的关系标签不太可靠。这些关系标签是自动收集的,可能有些标注的关系和文档无关。所以,从自动标注中很难分辨哪些关系是有效的,哪些是无效的。为了避免漏掉重要的实例,本文对所有实体对计算损失。总的损失是由公式11中的超参数来平衡的,公式如下: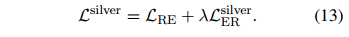
在远程监督的数据上训练后,学生模型再用人工标注的数据进行微调,用可靠的监督信号来改进它对DocRE和ER的知识。
3.3 Inference
本文根据Zhou等人(2021)的方法,用自适应阈值法得到RE的预测,选出得分超过阈值的关系类别。对于ER,用静态阈值法,选出重要性超过阈值的句子作为证据。本文还采用了Xie等人(2022)提出的推理阶段融合策略。具体来说,对于每个预测的关系三元组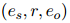 和它的证据预测
和它的证据预测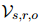 ,从中收集证据句子
,从中收集证据句子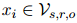 ,构建一个伪文档
,构建一个伪文档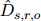 。然后,把伪文档输入训练好的模型,重新给关系三元组评分。为了把伪文档和整个文档的预测结合起来,用一个只有一个参数
。然后,把伪文档输入训练好的模型,重新给关系三元组评分。为了把伪文档和整个文档的预测结合起来,用一个只有一个参数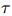 的混合层,是一个阈值。只有当一个三元组在整个文档和伪文档上的得分之和大于时,才把它作为最终的预测结果。调整,让RE在开发集上的二元交叉熵损失最小。
的混合层,是一个阈值。只有当一个三元组在整个文档和伪文档上的得分之和大于时,才把它作为最终的预测结果。调整,让RE在开发集上的二元交叉熵损失最小。
和它的证据预测,从中收集证据句子,构建一个伪文档。然后,把伪文档输入训练好的模型,重新给关系三元组评分。为了把伪文档和整个文档的预测结合起来,用一个只有一个参数的混合层,是一个阈值。只有当一个三元组在整个文档和伪文档上的得分之和大于时,才把它作为最终的预测结果。调整,让RE在开发集上的二元交叉熵损失最小。4 Experiments
4.1 Setting
Dataset
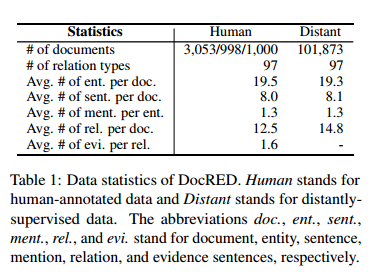
本文实验是在DocRED这个具有人工标注的DocRE数据集上进行的。表1显示,DocRED包含了一小部分人工标注的数据和一大部分远程监督的数据。这些远程监督的数据是通过把维基百科文章和Wikidata知识库对齐而得到的。本文直接使用了DocRED提供的远程监督的数据。
Configuration
为了实现DREEAM,本文基于Hugging Face的Transformers框架,使用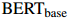 和
和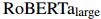 作为预训练语言模型(PLM)编码器。参考前人的工作,通过网格搜索从
作为预训练语言模型(PLM)编码器。参考前人的工作,通过网格搜索从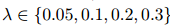 中选取了合适的参数,分别为的0.1和的0.05,来平衡ER损失和RE损失。在训练和评估DREEAM时,使用单个Tesla V100 16GB GPU来运行,使用单个NVIDIA A100 40GB GPU来运行。超参数和运行时间的细节见附录A。
中选取了合适的参数,分别为的0.1和的0.05,来平衡ER损失和RE损失。在训练和评估DREEAM时,使用单个Tesla V100 16GB GPU来运行,使用单个NVIDIA A100 40GB GPU来运行。超参数和运行时间的细节见附录A。
和作为预训练语言模型(PLM)编码器。参考前人的工作,通过网格搜索从中选取了合适的参数,分别为的0.1和的0.05,来平衡ER损失和RE损失。在训练和评估DREEAM时,使用单个Tesla V100 16GB GPU来运行,使用单个NVIDIA A100 40GB GPU来运行。超参数和运行时间的细节见附录A。
Evaluation
本文在推理阶段,根据公式8得到的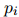 值,筛选出大于0.2的句子
值,筛选出大于0.2的句子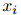 ,作为证据的来源。在评估阶段,使用DocRED的官方评估指标,分别对RE和ER进行Ign F1和F1、Evi F1的评估。Ign F1是在去除了训练集中已有的关系后,对开发集和测试集进行的评估,以消除训练集的影响。用不同的随机种子,对系统进行了五次训练,并给出了这些训练的平均分数和标准误差。
,作为证据的来源。在评估阶段,使用DocRED的官方评估指标,分别对RE和ER进行Ign F1和F1、Evi F1的评估。Ign F1是在去除了训练集中已有的关系后,对开发集和测试集进行的评估,以消除训练集的影响。用不同的随机种子,对系统进行了五次训练,并给出了这些训练的平均分数和标准误差。
值,筛选出大于0.2的句子,作为证据的来源。在评估阶段,使用DocRED的官方评估指标,分别对RE和ER进行Ign F1和F1、Evi F1的评估。Ign F1是在去除了训练集中已有的关系后,对开发集和测试集进行的评估,以消除训练集的影响。用不同的随机种子,对系统进行了五次训练,并给出了这些训练的平均分数和标准误差。4.2 Main Results
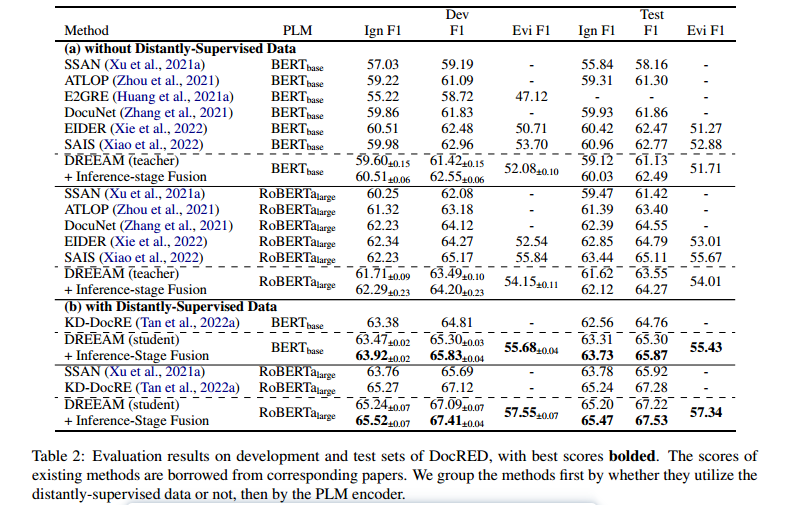
Performance of the Student Model
表2显示,利用远程监督数据的学生模型在RE上优于现有系统。尤其是,当使用BERTbase作为PLM编码器时,DREEAM在开发集上的Ign F1/F1比先前的最先进系统KD-DocRE高出0.6/1.0个百分点。在测试集上,Ign F1和F1都提高了1.1个百分点。值得注意的是,DREEAM使用甚至能够与在弱监督设置下使用的SSAN (Xu等人, 2021a)相比肩。当使用作为PLM编码器时,DREEAM在开发集和测试集上仍然保持优势。这些结果证明了本文的假设,即ER自训练能够改善RE,这是之前的工作未能展示的。
甚至能够与在弱监督设置下使用的SSAN (Xu等人, 2021a)相比肩。当使用作为PLM编码器时,DREEAM在开发集和测试集上仍然保持优势。这些结果证明了本文的假设,即ER自训练能够改善RE,这是之前的工作未能展示的。Performance of the Teacher Model
表2的上半部分显示,用人工标注数据训练的教师模型在RE和ER两个任务上与EIDER相媲美。尽管DREEAM和SAIS在性能上有一定差距,但本文认为这主要是由于监督信号的不同造成的。DREEAM只是将RE和无关联的ER结合在一起,而SAIS则在此之上增加了三个额外的任务:共指消解、实体类型和关联特定的ER (Xiao等人, 2022)。这些附加的监督信号可能有助于提升SAIS的性能。除了性能外,DREEAM还在内存效率方面优于以前的ER-incorporated DocRE系统。在第4.4节中对此进行了详细的讨论。
Effectiveness of ER Self-Training
学生模型在ER任务上远远超过了其他现有的系统。DREEAM是第一个采用弱监督ER训练的方法,它通过自我训练有效地利用了大量无需证据标注的数据。实验结果显示,DREEAM在Evi F1指标上比目前最好的监督方法高出了约2.0个百分点。因此,本文认为,ER自我训练方法能够成功地从无需证据标注的关系远程监督数据中学习到证据知识。
4.3 Ablation Studies
Teacher Model
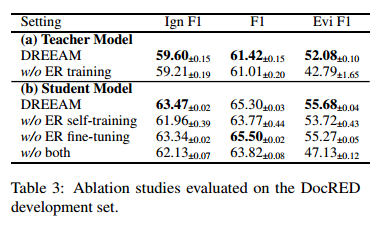
本文探索了如何利用证据指导注意力来提升人工标注数据的RE训练效果,训练了一个不包含ER训练的教师模型,并在DocRED开发集上进行了评估。结果显示,如果关闭ER训练,教师模型的RE性能会降到与ATLOP相似的基线水平。如表3(a)所示,没有ER训练的情况下,DREEAM的RE性能有所下降。这一观察验证了利用证据指导注意力可以提高RE性能的假设。本文还进一步可视化了一些实例的词元重要性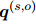 ,以分析证据指导训练的影响,发现本文的方法能够有效地将注意力集中在相关的上下文上。更多细节可以参见附录B。此外,本文还从关闭ER训练的教师模型中检索出证据,作为重要性超过预设阈值的句子。通过这种方式,发现Evi F1与开启ER训练的教师模型相差无几。这一观察说明,ER是一个与RE紧密相关的任务。
,以分析证据指导训练的影响,发现本文的方法能够有效地将注意力集中在相关的上下文上。更多细节可以参见附录B。此外,本文还从关闭ER训练的教师模型中检索出证据,作为重要性超过预设阈值的句子。通过这种方式,发现Evi F1与开启ER训练的教师模型相差无几。这一观察说明,ER是一个与RE紧密相关的任务。
,以分析证据指导训练的影响,发现本文的方法能够有效地将注意力集中在相关的上下文上。更多细节可以参见附录B。此外,本文还从关闭ER训练的教师模型中检索出证据,作为重要性超过预设阈值的句子。通过这种方式,发现Evi F1与开启ER训练的教师模型相差无几。这一观察说明,ER是一个与RE紧密相关的任务。Student Model
本文研究了在远程监督数据上训练并在人工标注数据上微调的学生模型。目的是检验在不同训练阶段用证据指导注意力的效果。为了实现这一目的,本文去掉了学生模型在远程监督和人工标注数据上的训练过程中的ER监督信号。基线模型也同样排除了ER监督,它只在远程监督数据上预训练,然后在人工标注数据上仅为RE微调。如表3(b)所示,没有ER自训练的DREEAM与基线模型表现相当,而没有ER微调的DREEAM与没有任何消融的原始模型表现相当。这些结果表明,ER自训练对于学生模型的效果比ER微调更重要。一方面,可以观察到,在大量数据上禁用ER自训练会导致证据知识的巨大损失,而这种损失无法通过在更小的证据标注数据集上的微调来恢复。另一方面,可以得出结论,DREEAM能够成功地从没有任何证据标注的数据中检索出证据知识,证明了ER自训练策略的有效性。
4.4 Memory Efficiency
这一小节分析了之前的ER方法存在的内存效率问题,以及DREEAM如何克服它。之前的方法把ER当作一个与RE相独立的任务,需要额外的神经网络层来完成。为了进行ER,它们都采用了一个双线性证据分类器,它的输入是一个实体对相关的嵌入和一个句子嵌入。例如,EIDER用以下公式计算句子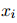 对于实体对
对于实体对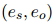 的证据分数:
的证据分数:
对于实体对的证据分数: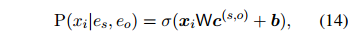
其中是一个句子嵌入,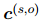 是根据公式3得到的局部上下文嵌入,
是根据公式3得到的局部上下文嵌入, 和
和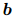 是可训练的参数。EIDER和其他现有的系统因此需要对所有的(句子,实体对)组合进行计算。具体来说,假设一个文档
是可训练的参数。EIDER和其他现有的系统因此需要对所有的(句子,实体对)组合进行计算。具体来说,假设一个文档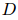 有
有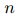 个句子
个句子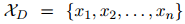 ,和
,和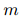 个实体
个实体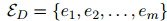 ,则有
,则有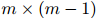 个实体对。为了得到证据分数,EIDER必须通过公式14进行
个实体对。为了得到证据分数,EIDER必须通过公式14进行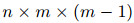 次双线性分类,导致巨大的内存消耗。相比之下,DREEAM直接用注意力权重在词上的求和作为证据分数,因此无需引入新的可训练参数,也无需进行昂贵的矩阵计算。因此,可以看到,DREEAM比它的竞争对手更节省内存。
次双线性分类,导致巨大的内存消耗。相比之下,DREEAM直接用注意力权重在词上的求和作为证据分数,因此无需引入新的可训练参数,也无需进行昂贵的矩阵计算。因此,可以看到,DREEAM比它的竞争对手更节省内存。
是一个句子嵌入,是根据公式3得到的局部上下文嵌入,和是可训练的参数。EIDER和其他现有的系统因此需要对所有的(句子,实体对)组合进行计算。具体来说,假设一个文档有个句子,和个实体,则有个实体对。为了得到证据分数,EIDER必须通过公式14进行次双线性分类,导致巨大的内存消耗。相比之下,DREEAM直接用注意力权重在词上的求和作为证据分数,因此无需引入新的可训练参数,也无需进行昂贵的矩阵计算。因此,可以看到,DREEAM比它的竞争对手更节省内存。表4展示了当使用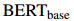 作为预训练语言模型(PLM)编码器时,现有方法和提出的方法的内存消耗和可训练参数的数量。数值是在使用相应的官方仓库和批量大小为四的情况下训练系统时测量的。本文发现,DREEAM的内存消耗只有EIDER的27.4%和SAIS的25.5%。值得注意的是,DREEAM的内存消耗也比KD-DocRE少,突出了本文提出的方法的内存效率。
作为预训练语言模型(PLM)编码器时,现有方法和提出的方法的内存消耗和可训练参数的数量。数值是在使用相应的官方仓库和批量大小为四的情况下训练系统时测量的。本文发现,DREEAM的内存消耗只有EIDER的27.4%和SAIS的25.5%。值得注意的是,DREEAM的内存消耗也比KD-DocRE少,突出了本文提出的方法的内存效率。
作为预训练语言模型(PLM)编码器时,现有方法和提出的方法的内存消耗和可训练参数的数量。数值是在使用相应的官方仓库和批量大小为四的情况下训练系统时测量的。本文发现,DREEAM的内存消耗只有EIDER的27.4%和SAIS的25.5%。值得注意的是,DREEAM的内存消耗也比KD-DocRE少,突出了本文提出的方法的内存效率。4.5 Performance on Re-DocRED
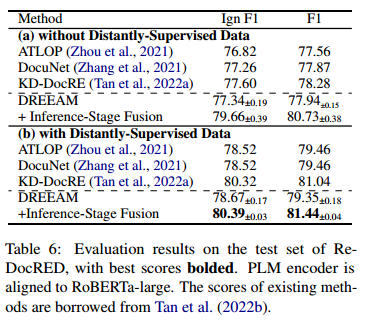
尽管DocRED是一个广泛使用的基准,但最近的一些工作指出,该数据集的标注存在不完整性。也就是说,DocRED中有很多关系三元组没有被人类标注出来,导致数据集有很多假负例的问题。为了解决这一问题,Tan等人(2服务器托管网022b)提出了ReDocRED,一个更可靠的DocRE的基准,对DocRED进行了修正和补充。本文在ReDocRED上评估了DREEAM,以验证其有效性。
与第4.2节类似,本文在两种不同的设置下进行了实验:(a)不使用远程监督数据的全监督设置和(b)使用远程监督数据的弱监督设置。需要注意的是,ReDocRED增加了一些新的关系三元组,但没有给出相应的证据句子。如表5所示,与DocRED相比,ReDocRED的训练集中有更多的关系三元组缺少证据句子。这可能导致基于ReDocRED训练的DREEAM在证据关系(ER)上不够准确,受到缺失证据的影响。因此,在学生模型的ER自训练过程中,本文使用了基于DocRED训练的教师模型预测的记号证据分布作为监督信号。然后,在ReDocRED上对学生模型进行了微调,以提高其关系抽取(RE)的能力。
表6展示了DREEAM与现有方法的性能比较。可以发现,DREEAM在全监督设置和弱监督设置下都超过了现有方法。这一结果证明了本文提出的方法的合理性。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
使用 IDEA 处理合并(merge) 使用IDEA处理git合并如果遇到冲突,对冲突文件的不冲突部分需要处理吗?会自动将双方不冲突的部分合并吗? 比如如下,使用 IDEA 合并 branch1 到 branch2 分支,出现了冲突,如下图: 如果处理好冲突,…
