

♂️ 个人主页: @AI_magician
主页地址: 作者简介:CSDN内容合伙人,全栈领域优质创作者。
景愿:旨在于能和更多的热爱计算机的伙伴一起成长!!
♂️声明:本人目前大学就读于大二,研究兴趣方向人工智能&硬件(虽然硬件还没开始玩,但一直很感兴趣!希望大佬带带)

【大数据 | 综合实践】大数据技术基础综合项目 – 基于GitHub API的数据采集与分析平台
摘要: 本文章详解了整个大数据技术综合项目全流程,以及源码、服务器托管网文档、元数据、等,大家在做大作业或者课设可以参考借鉴以下。 基于 hadoop hbase spark python mysql mapreduce 实现
该文章收录专栏
[✨— 《深入学习大数据与分布式系统》 —✨]
文件目录如下:
文件目录树如下
D:.
| file_tree.txt
| README.md
| 大数据技术基础综合项目 - 基于GitHub API的数据采集与分析平台.doc
| 大数据技术基础综合项目 - 基于GitHub API的数据采集与分析平台.pdf
|
+---Hbase导入代码
| HbaseImportTest.jar
| HBaseImportTest.java
|
+---mapreduce代码
| WordCount.jar
| WordCount.java
|
+---Python可视化代码
| 可视化代码.py
|
+---python数据分析代码
| analysis.py
|
+---数据爬取和处理代码
| collect data.py
| deal data.py
|
+---数据集
| github_table.csv
| pre_projects.csv
| projects.csv
| small_data.csv
|
---数据集文件上传hdfs代码
HdfsDownload.java以上文件获取地址见:
在线下载获取 (六折价格,截至到月底哦)
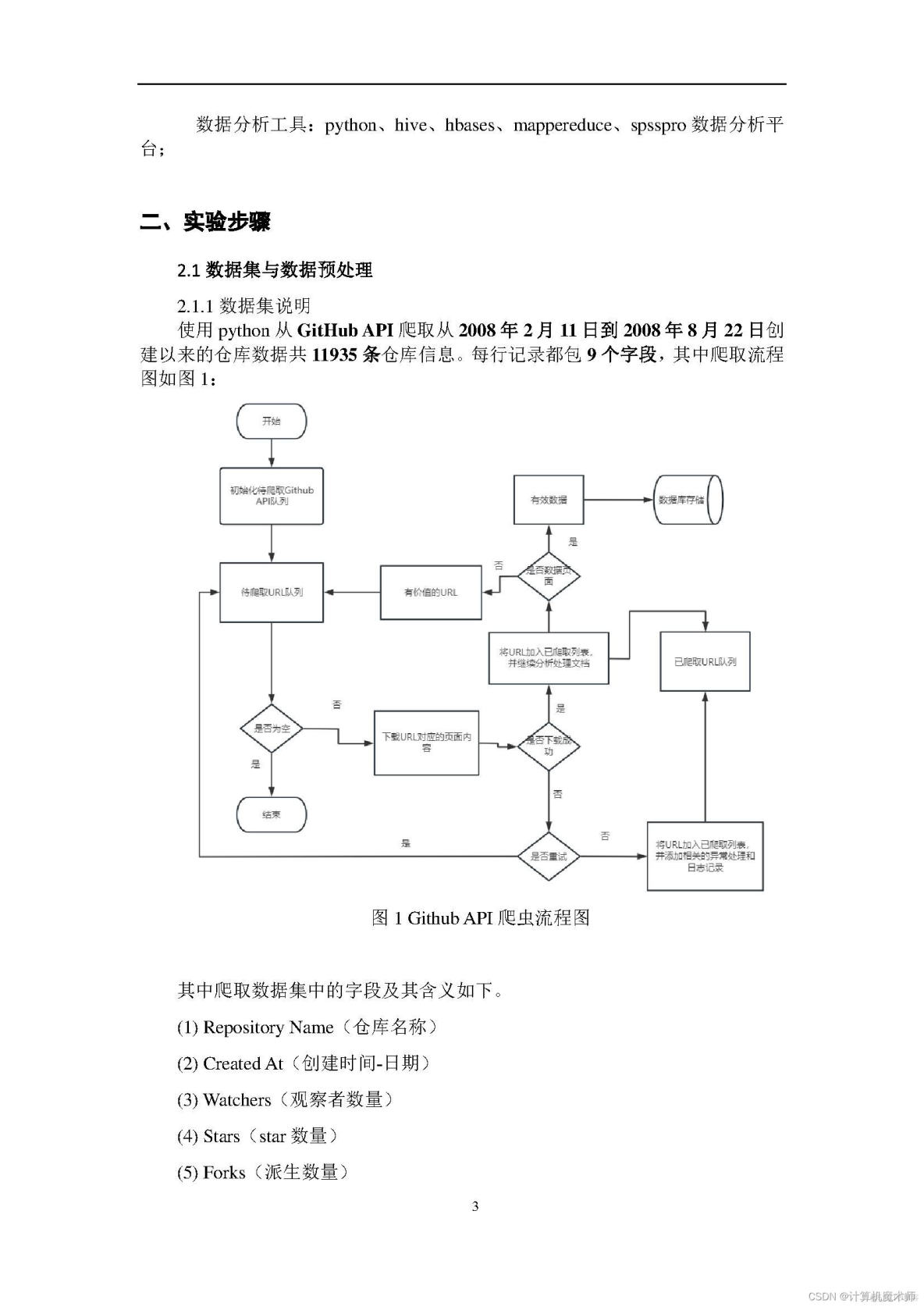
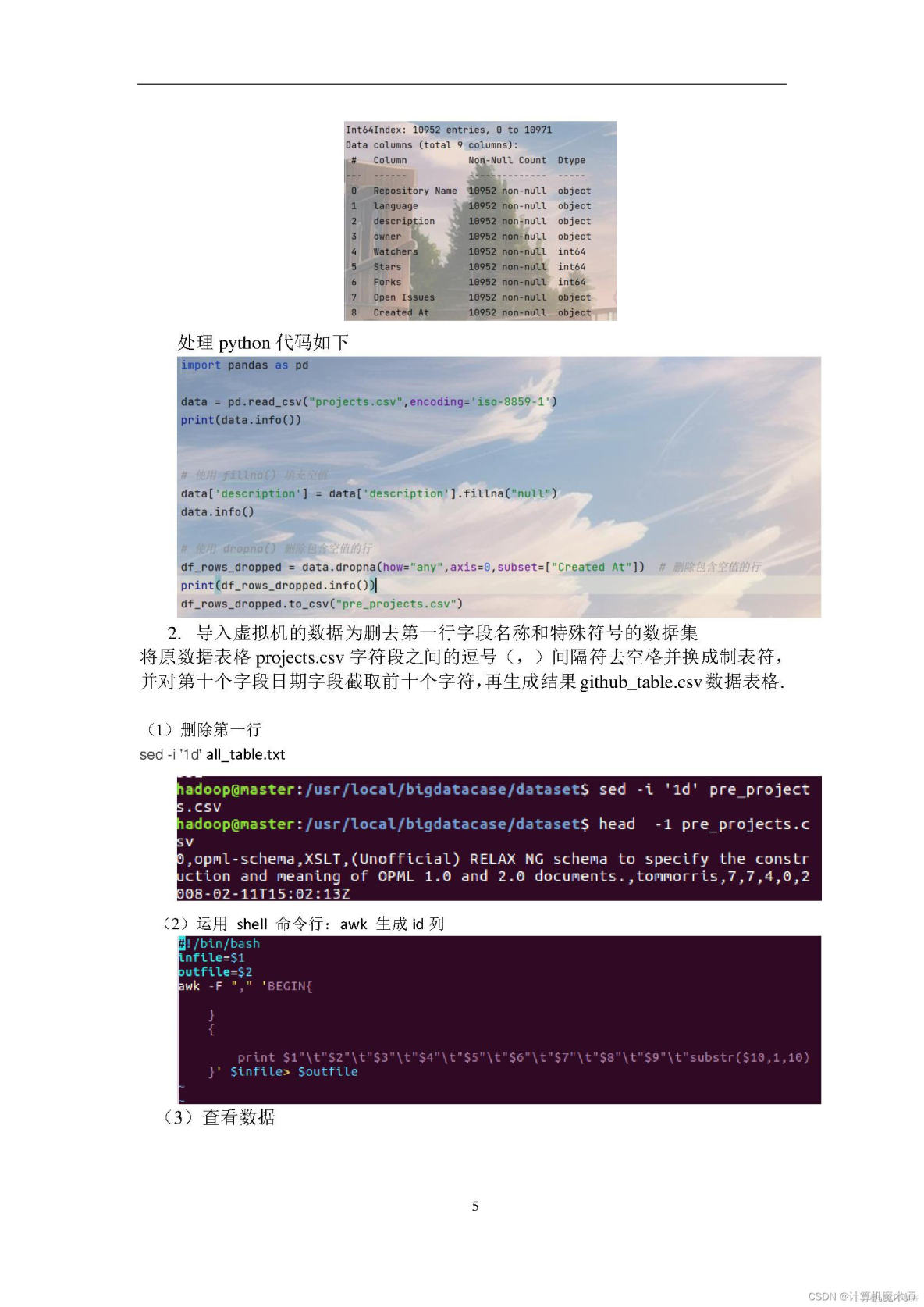
文档目录如下:

一、项目背景与功能
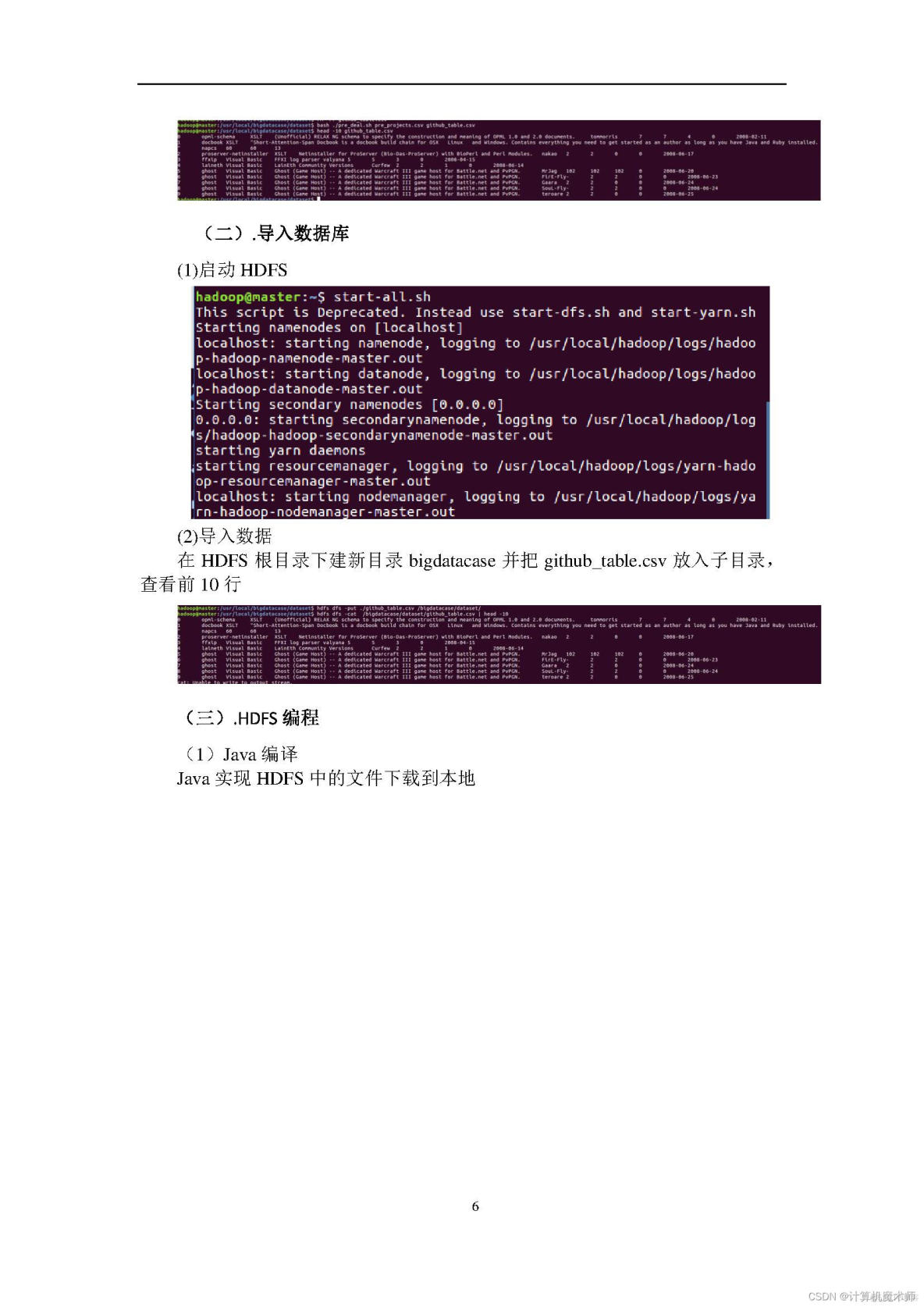
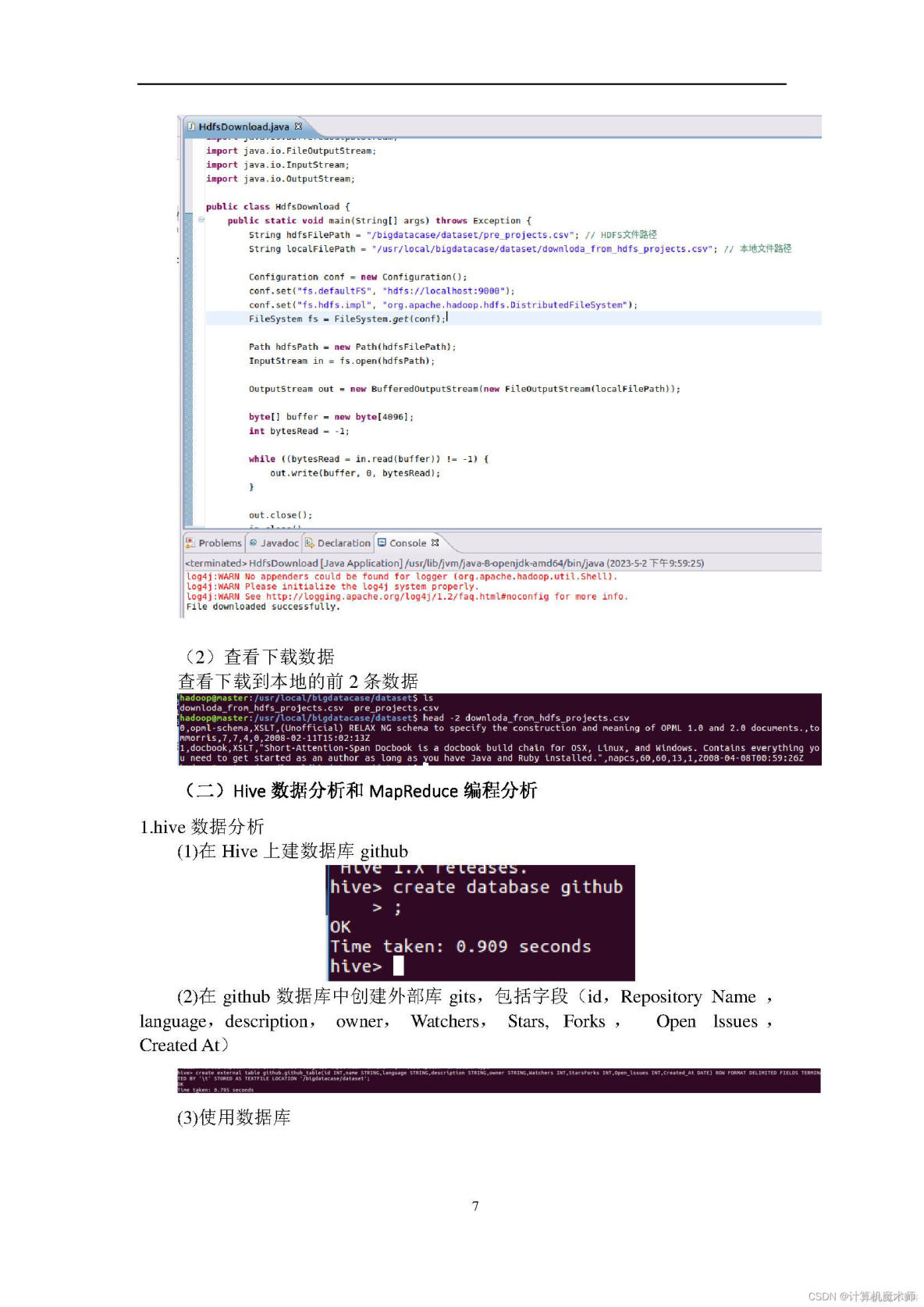
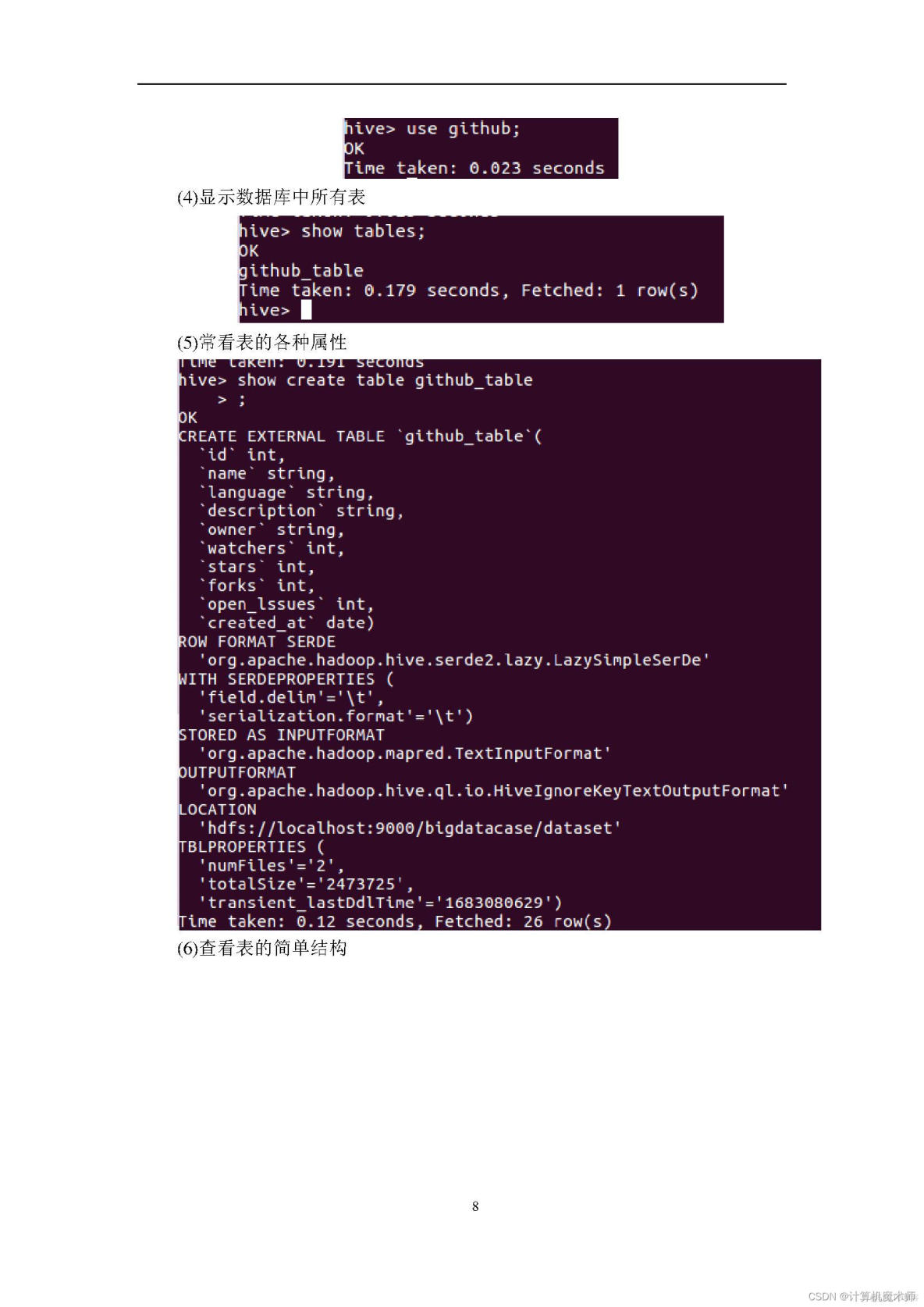
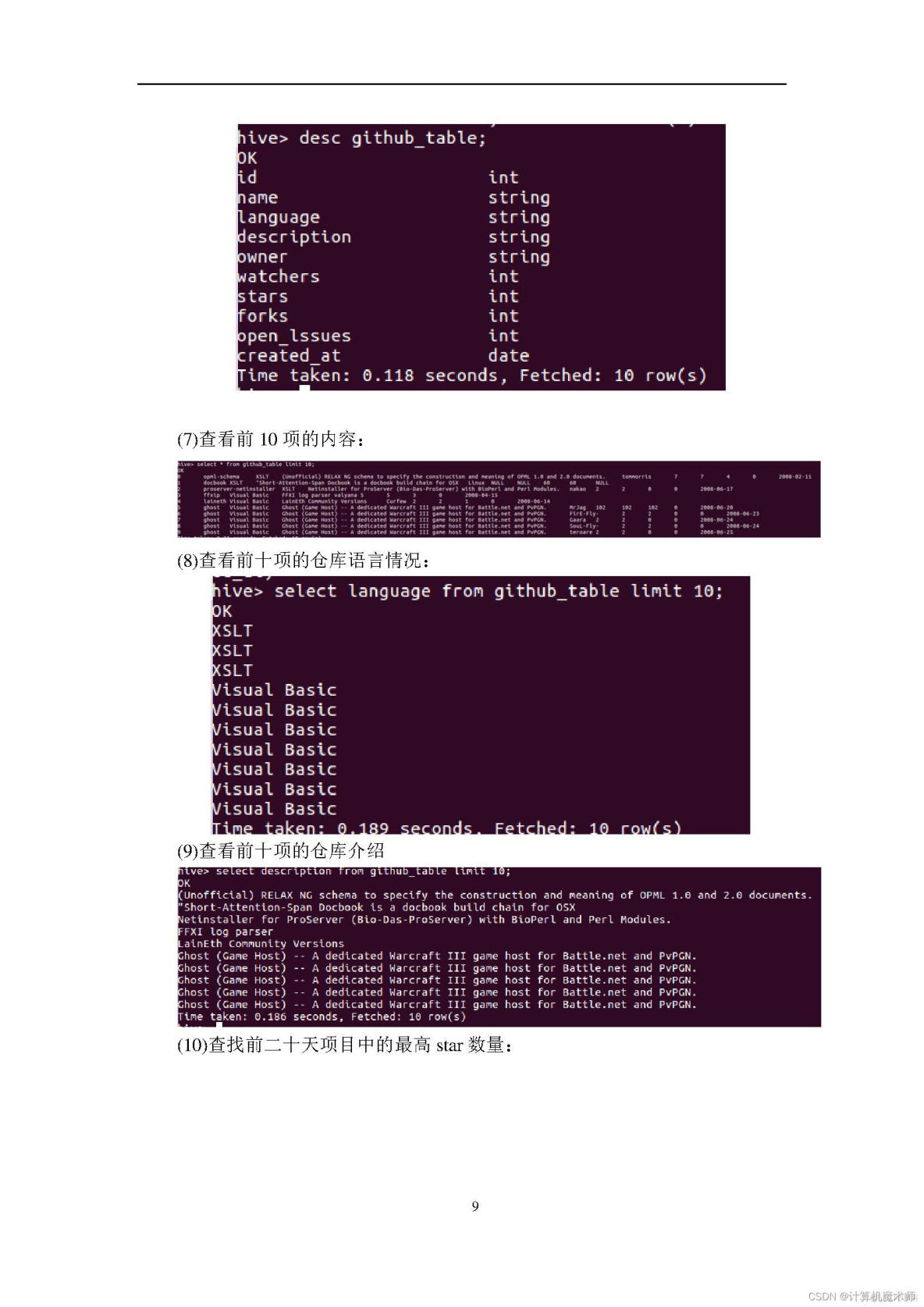
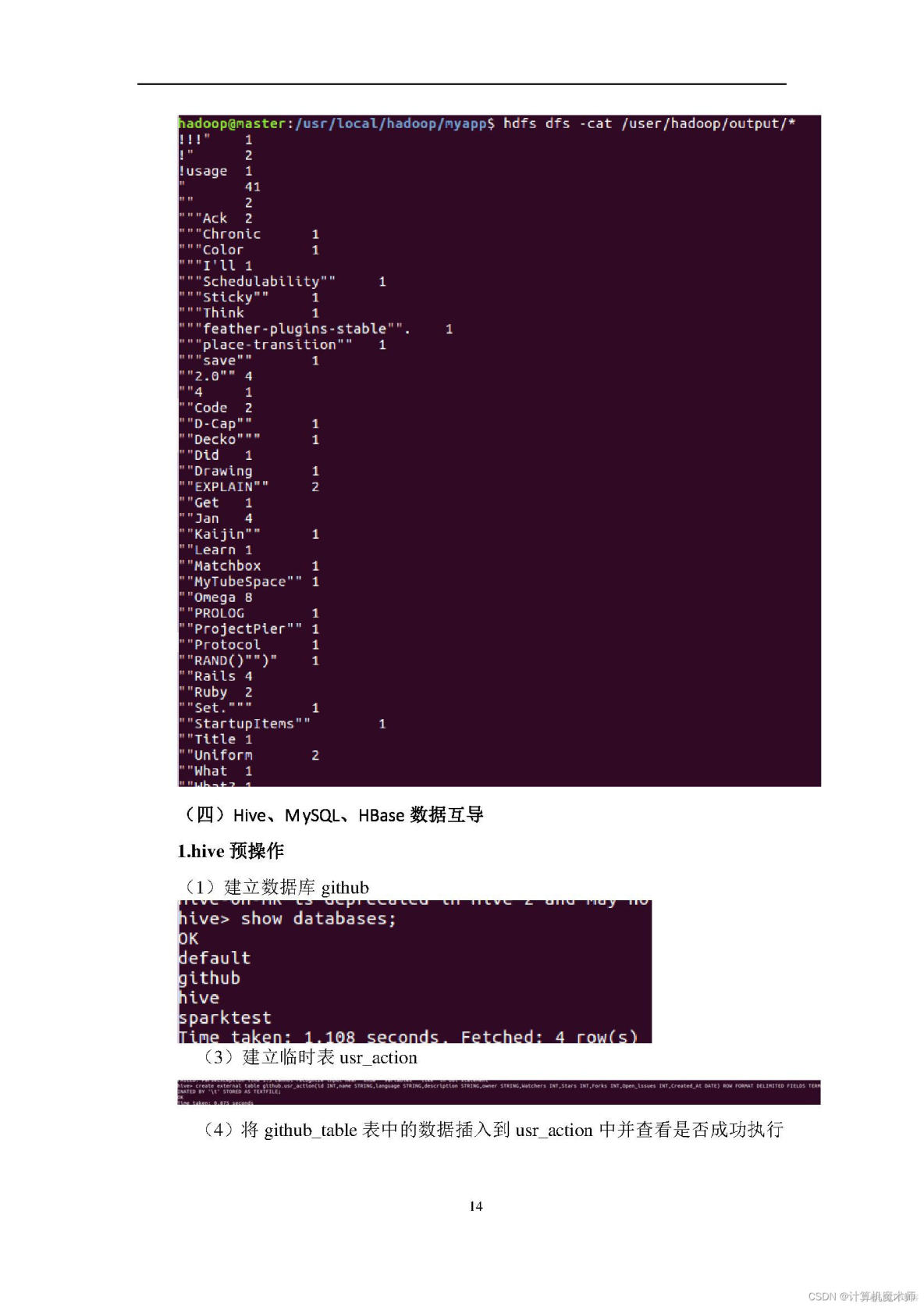
1、熟悉Linux系统、MySQL、Hadoop、Hbase、Hive、Sqoop、matplotlib、Eclipse等系统和软件的安装和使用。2、了解大数据处理的基本流程。
3、熟悉数据预处理方法。
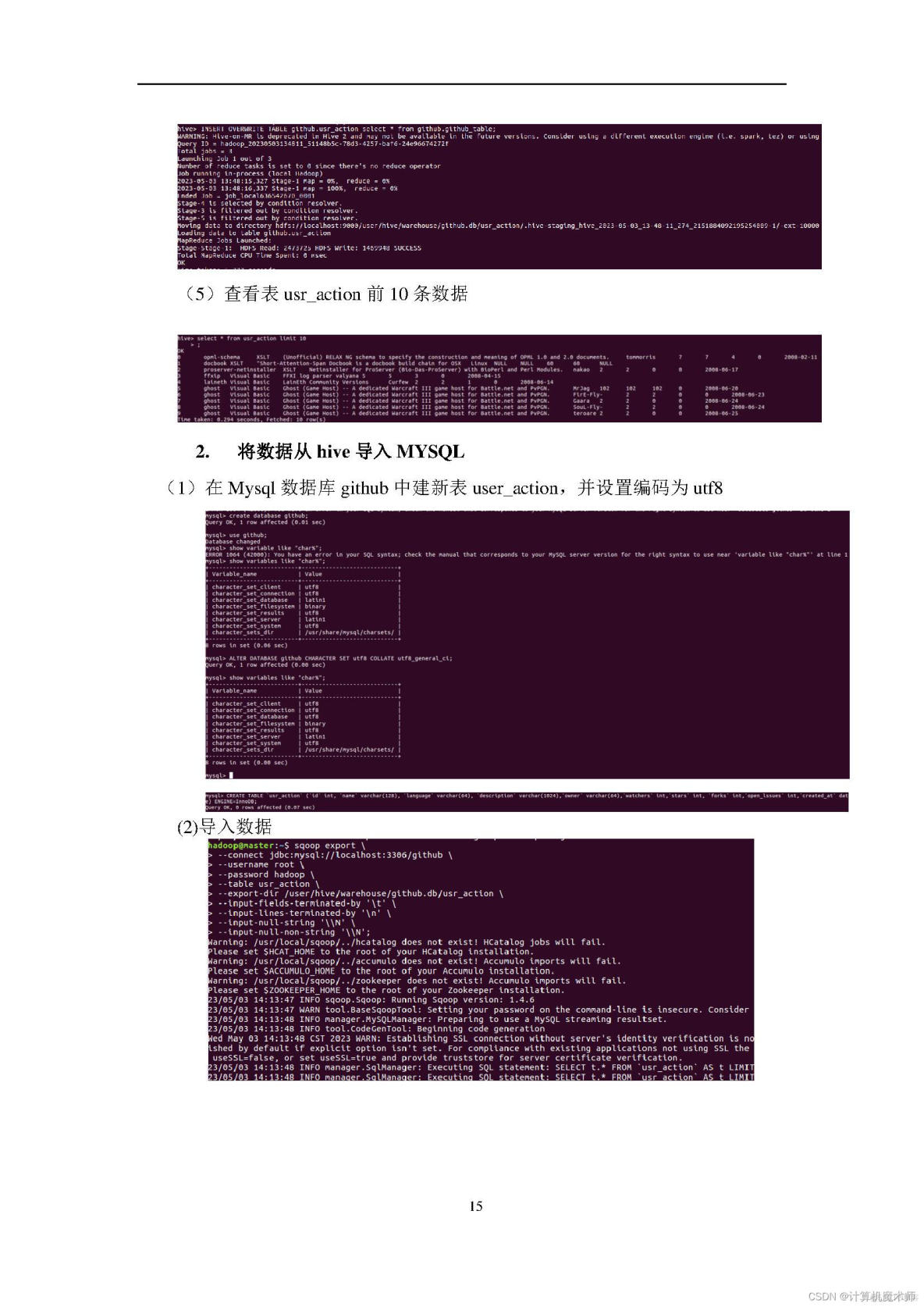
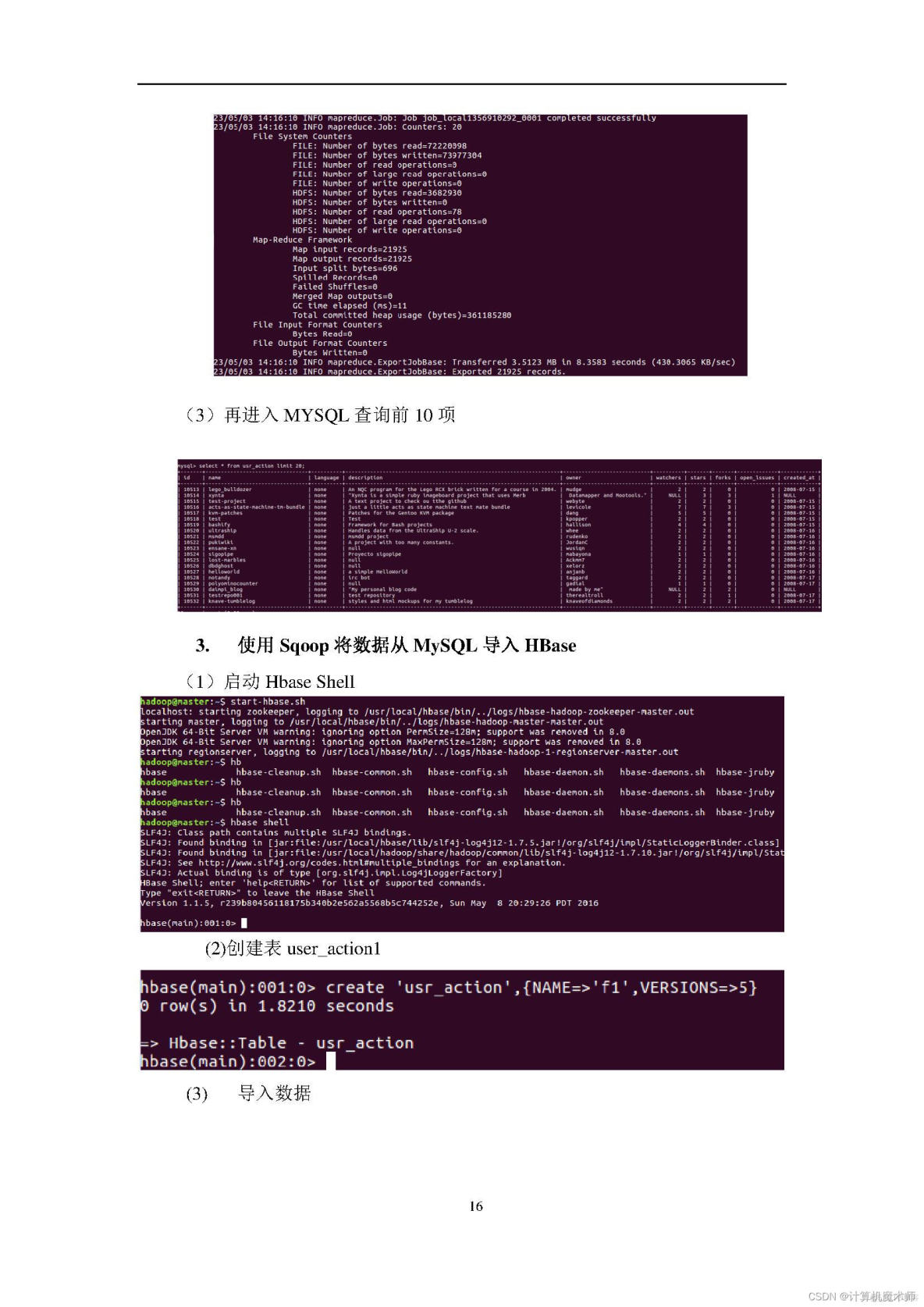
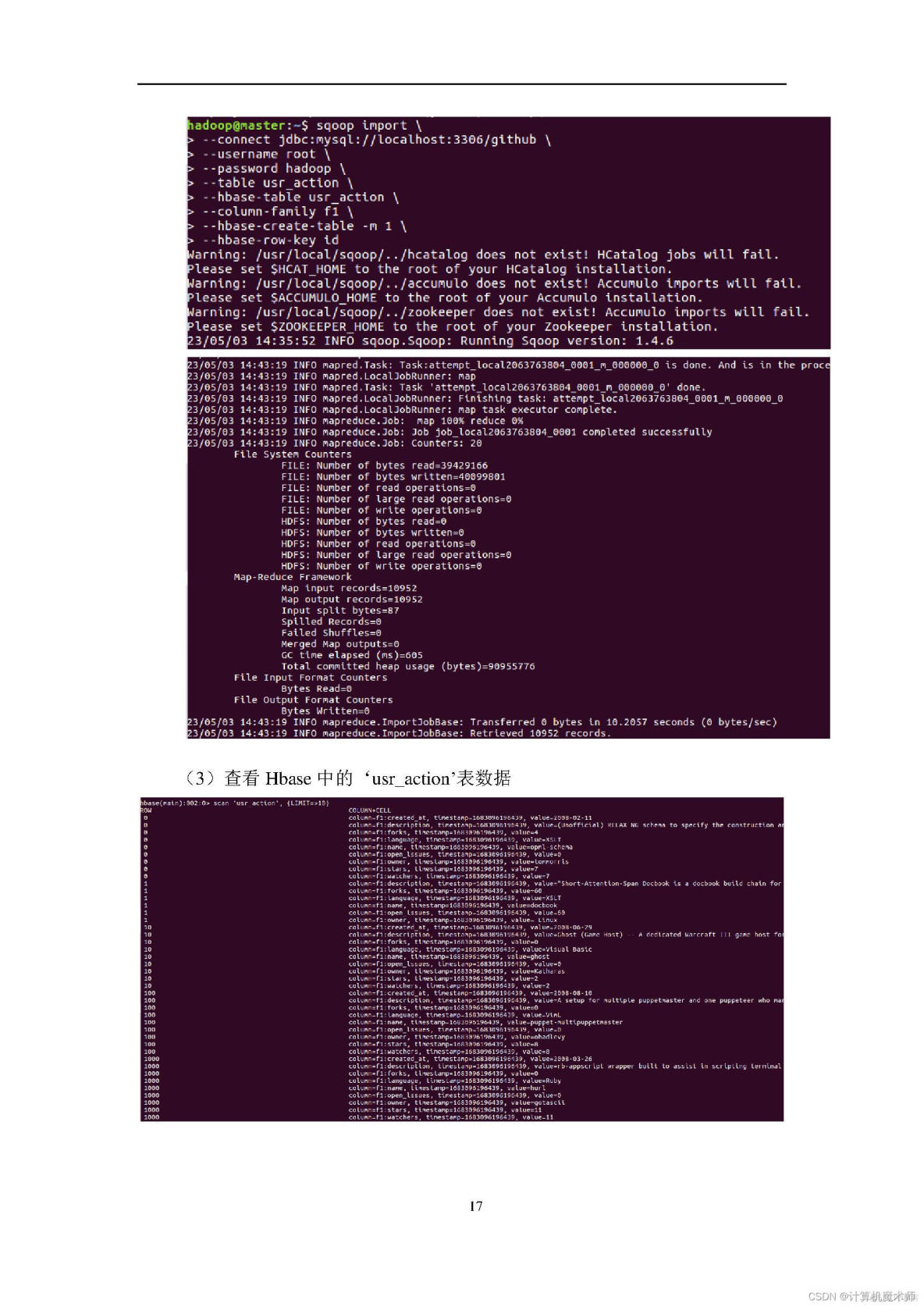
4、熟悉在不同类型数据库之间进行数据相互导入和导出。
5、熟悉使用R语言进行可视化分析。
6、熟悉使用Eclipse编写java程序操作HBase数据库。
实验环境:操作系统:Linux(建议U服务器托管网buntu16.04);
8、Hadoop版本:2.7.1。
1.1项目背景
在当今数字化社会中,数据是企业的重要资产之一。GitHub是全球最大的开源代码托管平台之一,拥有着海量的代码和开发者社区。因此,利用GitHub API爬取数据成为了一种重要的数据采集方法。GitHub API提供了大量的数据接口,包括代码、用户、组织等信息,可以满足不同场景下的数据需求。通过爬取GitHub API获取的数据可以用于分析行业趋势、评估开发者质量、挖掘优秀开源项目等。此外,数据还可以用于机器学习模型的训练和优化。
爬取GitHub API的项目背景和意义在于,通过数据采集和分析,为企业和个人提供全面的市场洞察和技术趋势分析,帮助他们做出更好的决策,并推动技术的发展和创新。
1.2 项目功能
这个项目的主要功能是利用GitHub API来爬取GitHub上的开源代码、用户、组织等信息,并将这些信息进行处理和分析。具体来说,项目可以实现以下功能:
- 爬取GitHub上的代码库信息,包括代码库名称、代码库描述、代码库语言、代码库Stars数等。
- 爬取GitHub上的用户信息,包括用户名、用户类型、用户Stars数、用户Followers数等。
- 对获取的数据进行分析和处理,例如统计各种数据的数量、计算平均值、挖掘数据中的关联规律等。
- 将处理后的数据可视化展示,例如生成图表、制作地图等。通过以上功能,该项目可以帮助用户快速获取GitHub上的数据,并进行分析和处理,从而为用户提供全面的技术趋势分析和市场洞察。
1.3 运行环境
操作系统:Linux(建议Ubuntu16.04),Windows;Hadoop版本:2.7.1。
数据分析工具:python、hive、hbases、mappereduce、spsspro数据分析平台;

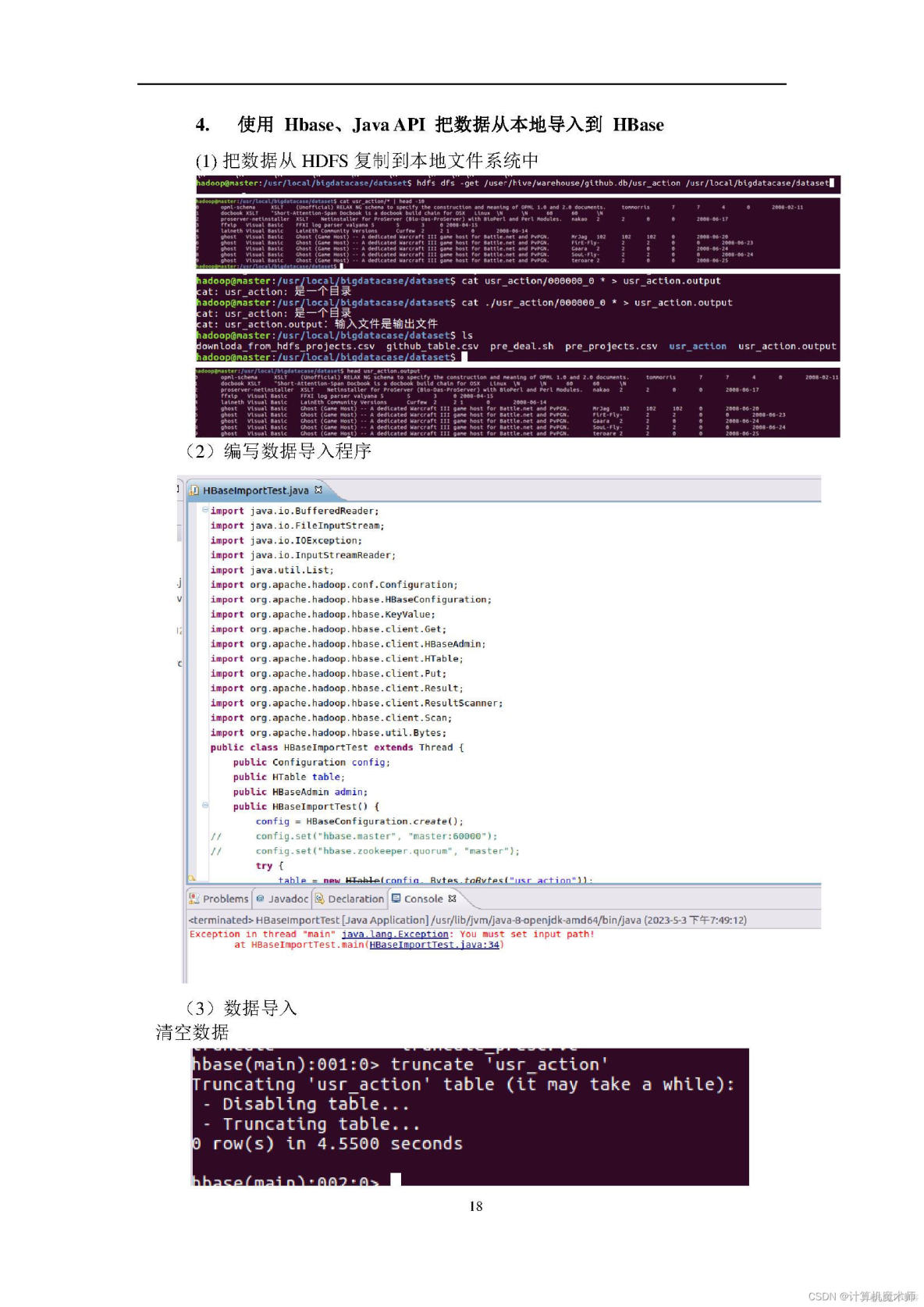
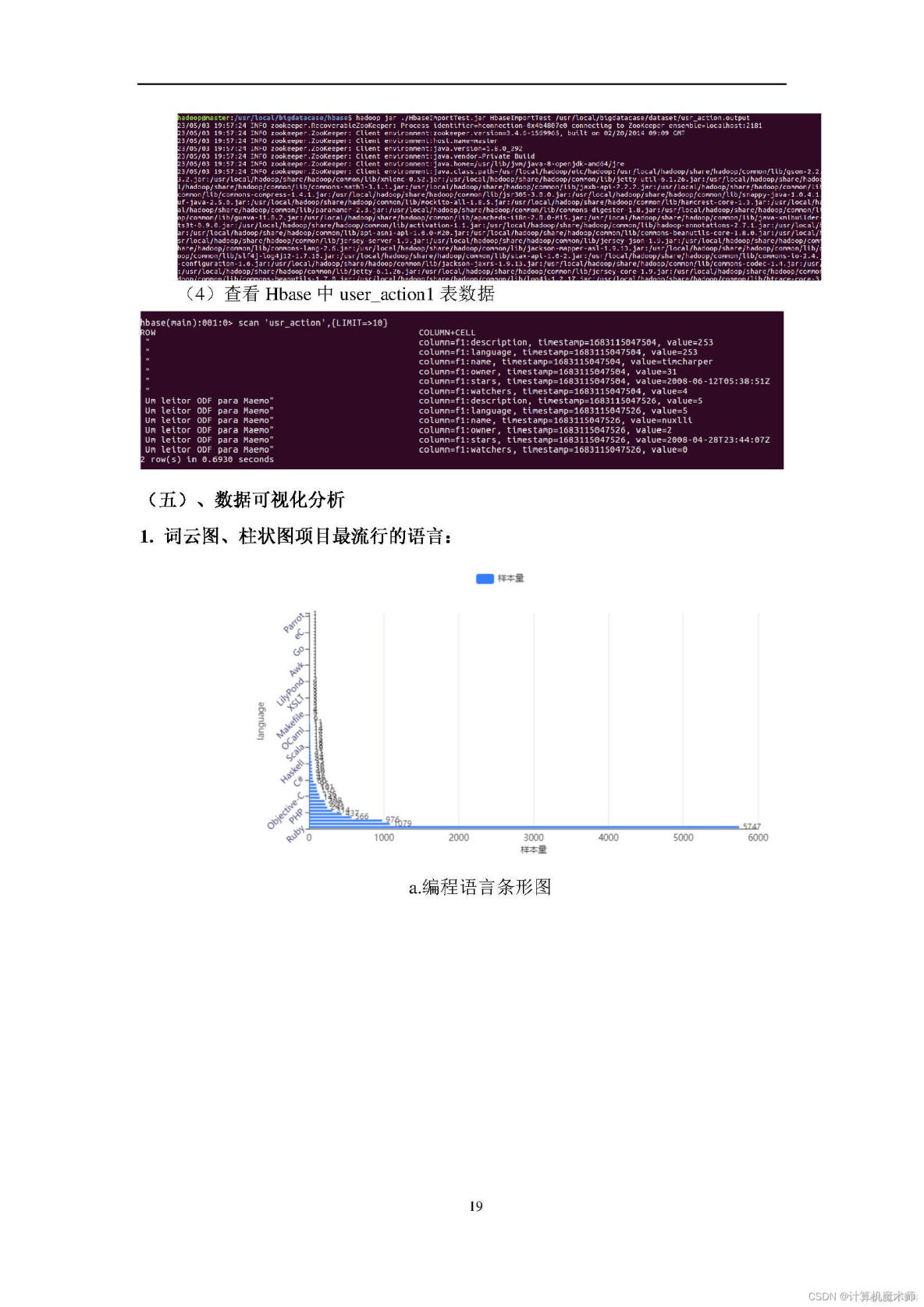
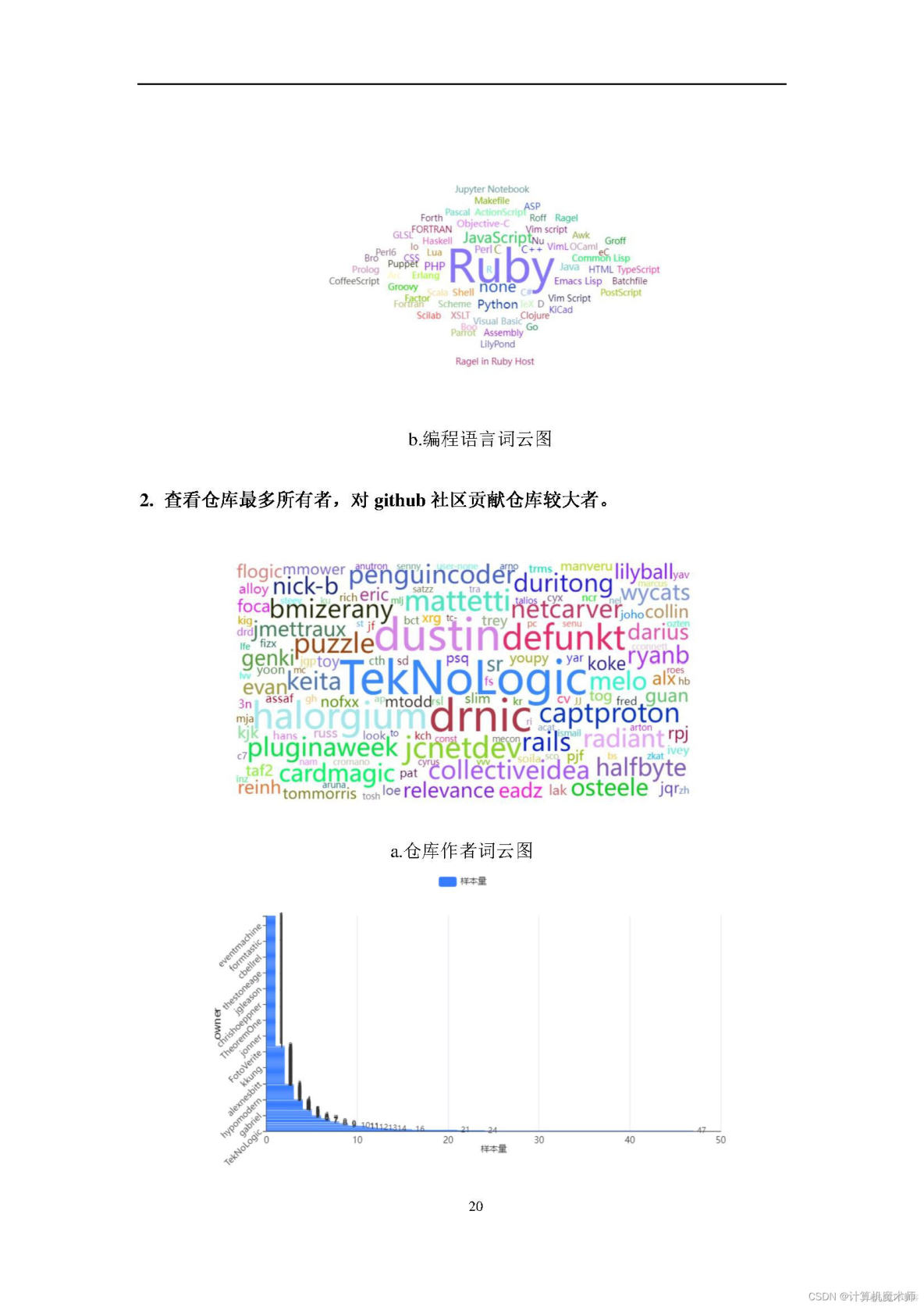

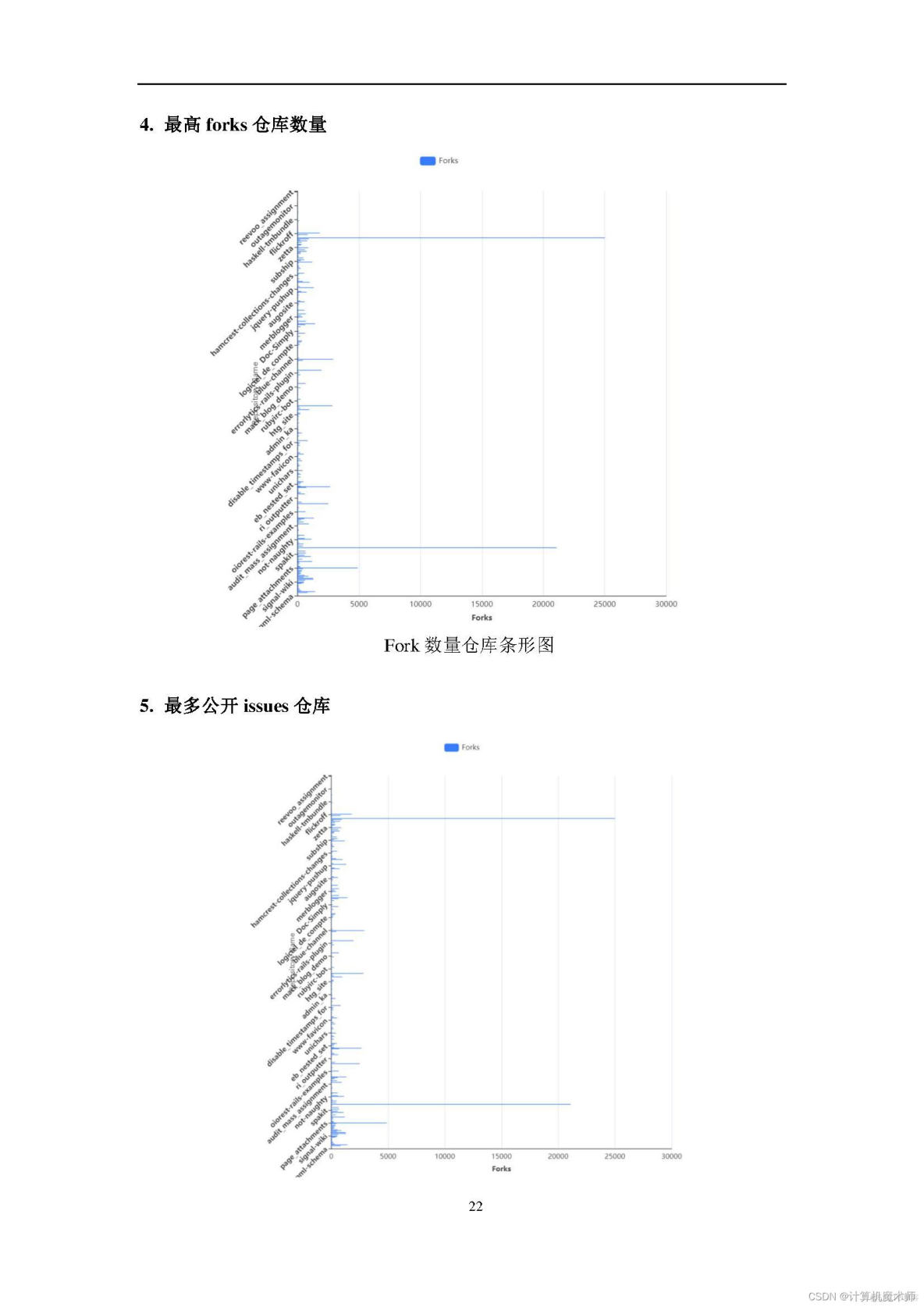

全家桶打包地址见;
在线下载获取 (六折价格,截至到月底哦)

到这里,如果还有什么疑问
欢迎私信博主问题哦,博主会尽自己能力为你解答疑惑的!
如果对你有帮助,你的赞是对博主最大的支持!!服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
