
泊松融合我自己写的第一版程序大概是2016年在某个小房间里折腾出来的,当时是用的迭代的方式,记得似乎效果不怎么样,没有达到论文的效果。前段时间又有网友问我有没有这方面的程序,我说Opencv已经有了,可以直接使用,他说opencv的框架太大,不想为了一个功能的需求而背上这么一座大山,看能否做个脱离那个环境的算法出来,当时,觉得工作量挺大,就没有去折腾,最近年底了,项目渐渐少了一点,公司上面又在搞办公室政治,我地位不高,没有参与权,所以乐的闲,就抽空把这个算法从opencv里给剥离开来,做到了完全不依赖其他库实现泊松融合乐,前前后后也折腾进半个月,这里还是做个开发记录和分享。
在翻译算法过程中,除了参考了opencv的代码,还看到了很多参考资料,主要有以下几篇:
1、http://takuti.me/dev/poisson/demo/ 这个似乎打不开了,早期的代码好像是主要参考了这里
2、http://blog.csdn.net/baimafujinji/article/details/46787837 图像的泊松(Poisson)编辑、泊松融合完全详解
3、http://blog.csdn.net/hjimce/article/details/45716603 图像处理(十二)图像融合(1)Seamless cloning泊松克隆-Siggraph 2004
4、https://www.baidu.com/link?url=GgbzGxsNBzdTewEEXY4lx7RH5hB4KWxODUF79-cdVnNT4siKaGx5JSqh-pR3l7N9rXufCnyXWj2Fl40KvfRuTq&wd=&eqid=d200bfec000c06300000000665a61134 从泊松方程的解法,聊到泊松图像融合
对应的论文为:Poisson Image Editing,可以从百度上下载到。
泊松融合的代码在opencv的目录如下:
opencv-4.9.0源代码modulesphotosrc,其中的seamless_cloning_impl.cpp以及seamless_cloning.cpp为主要算法代码。
我们总结下opencv的泊松融合主要是由以下几个步骤组成的:
1、计算前景和背景图像的梯度场;
2、根据一定的原则计算融合后的图像的梯度场(这一步是最灵活的,通过改变他可以实现各种效果);
3、对融合后的梯度偏导,获取对应的散度。
4、由散度及边界像素值求解泊松方程(最为复杂)。
那么我们就一步一步的进行扣取和讲解。
一、计算前景和背景图像的梯度场。
这一部分在CV中对应的函数名为:computeGradientX及computeGradientY,在CV中的调用代码为:
computeGradientX(destination, destinationGradientX);
computeGradientY(destination, destinationGradientY);
computeGradientX(patch, patchGradientX);
computeGradientY(patch, patchGradientY);
以X方向的梯度为例, 其相应的代码为:
void Cloning::computeGradientX( const Mat &img, Mat &gx) { Mat kernel = Mat::zeros(1, 3, CV_8S); kernel.atchar>(0,2) = 1; kernel.atchar>(0,1) = -1; if(img.channels() == 3) { filter2D(img, gx, CV_32F, kernel); } else if (img.channels() == 1) { filter2D(img, gx, CV_32F, kernel); cvtColor(gx, gx, COLOR_GRAY2BGR); } }
可以看到就是简单的一个卷积,卷积核心为[0, -1, 1],然后使用filter2D函数进行处理。在这里opencv为了减少代码量,把灰度版本的算法也直接用彩色的处理了。
这个要抛弃CV,其实是个很简单的过程,一个简单的代码如下:
// 边缘部分采用了反射101方式,这个要和Opencv的代码一致,支持单通道和3通道 void IM_ComputeGradientX_PureC(unsigned char *Src, short *Dest, int Width, int Height, int Stride) { int Channel = Stride / Width; if (Channel == 1) { for (int Y = 0; Y ) { unsigned char* LinePS = Src + Y * Stride; short* LinePD = Dest + Y * Width; for (int X = 0; X 1; X++) { LinePD[X] = LinePS[X + 1] - LinePS[X]; } // LinePD[Width - 2] = LinePS[Width - 1] - LinePS[Width - 2] // LinePD[Width - 1] = LinePS[Width - 2] - LinePS[Width - 1] 101方式的镜像就是这个结果 LinePD[Width - 1] = -LinePD[Width - 2]; // 最后一列 } } else { // 三通道代码 } }
我这里的Dest没有用float类型,而是用的short,我的原则是用最小的内存量+合适的数据类型来保存目标。
注意,opencv里默认的边缘采用的是101的镜像方式的,因此,对于[0, -1, 1]这种卷积和,最右侧一列的值就是右侧倒数第二列的负值。
2、根据一定的原则计算融合后的图像的梯度场
这部分算法opencv写的很分散,他把代码放置到了好几个函数里,这里把他们集中一下大概就是如下几行:
1 Mat Kernel(Size(3, 3), CV_8UC1);
2 Kernel.setTo(Scalar(1));
3 erode(binaryMask, binaryMask, Kernel, Point(-1,-1), 3);
4 binaryMask.convertTo(binaryMaskFloat, CV_32FC1, 1.0/255.0);
5 arrayProduct(patchGradientX, binaryMaskFloat, patchGradientX);
6 arrayProduct(patchGradientY, binaryMaskFloat, patchGradientY);
7 bitwise_not(wmask,wmask);
8 wmask.convertTo(binaryMaskFloatInverted,CV_32FC1,1.0/255.0);
9 arrayProduct(destinationGradientX, binaryMaskFloatInverted, destinationGradientX);
10 arrayProduct(destinationGradientY, binaryMaskFloatInverted, destinationGradientY);
11 Mat laplacianX = destinationGradientX + patchGradientX;
12 Mat laplacianY = destinationGradientY + patchGradientY;
这个代码里的前面是三行一开始我感觉很纳闷,这个是干啥呢,为什么要对mask进行一个收缩呢,后面想一想,如果是一个纯白的mask,那么下面的融合整个融合后的梯度场就完全是前景的梯度场了,和背景就毫无关系了,而进行erode后,则边缘部分使用的就是背景的梯度场,这样就有了有效的边界条件,不过erode(binaryMask, binaryMask, Kernel, Point(-1, -1), 3);最后一个参数要是3呢,这个3可是表示重复执行三次,如果配合上前面的Kernel参数,对于一个纯白的图,边缘就会出现3行和3列的纯黑的像素了(我测试默认参数下erode在处理边缘时,是用了0值代替超出边界的值),我个人感觉这里使用参数1就可以了。
从第四到第十二行其实就是很简单的一个线性融合过程,Opencv的代码呢写的很向量化,我们要自己实现其实就下面几句代码:
for (int Y = 0; Y ) { int Index = Y * Width * Channel; int Speed = Y * Width; for (int X = 0; X ) { float MaskF = MaskS[Speed + X] * IM_INV255; float InvMaskF = 1.0f - MaskF; if (Channel == 1) { LaplacianX[Index + X] = GradientX_B[Index + X] * InvMaskF + GradientX_F[Index + X] * MaskF; LaplacianY[Index + X] = GradientY_B[Index + X] * InvMaskF + GradientY_F[Index + X] * MaskF; } else { // 三通道 } } }
3、对融合后的梯度偏导,获取对应的散度。
这一部分对应的CV的代码为:
computeLaplacianX(laplacianX,laplacianX);
computeLaplacianY(laplacianY,laplacianY);
以X方向的散度计算为例,其代码如下:
void Cloning::computeLaplacianX( const Mat &img, Mat &laplacianX) { Mat kernel = Mat::zeros(1, 3, CV_8S); kernel.atchar>(0,0) = -1; kernel.atchar>(0,1) = 1; filter2D(img, laplacianX, CV_32F, kernel); }
也是个卷积,没有啥特别的,翻译成普通的C代码可以用如下方式:
void IM_ComputeLaplacianX_PureC(float* Src, float* Dest, int Width, int Height, int Channel) { if (Channel == 1) { for (int Y = 0; Y ) { float* LinePS = Src + Y * Width; float* LinePD = Dest + Y * Width; for (int X = Width - 1; X >= 1; X--) { LinePD[X] = LinePS[X] - LinePS[X - 1]; } LinePD[0] = -LinePD[1]; // 第一列 } } else { // 三通道 } }
注意到Opencv的这个函数是支持Inplace操作的,即Src=Dest时,也能得到正确的结果,为了实现这个结果,我们注意到这个卷积核是偏左的,即核中心偏左的元素有用,利用这个特性可以在X方向上从右向左循环,就可以避免数据被覆盖的,当然对于每行的第一个元素就要特别处理了,同时注意这里采用了101格式的边缘处理。
4、由散度及边界像素值求解泊松方程。
有了以上的散度的计算,后面就是求解一个很大的稀疏矩方程的过程了,如果直接求解,将会是一个非常耗时的过程,即使利用稀疏的特性,也将对编码者提出很高的技术要求。自己写个稀疏矩阵的求解过程也是需要很大的勇气的。
在opencv里,上面的求解是借助了傅里叶变换实现的,这个的原理我在某个论文中看到过,现在时间关系,我也没有找到那一片论文了,如果后续有机会看到,我在分享出来。
CV的求解过程涉及到了3个函数,分别是poissonSolver、solve、dst,也是一个调用另外一个的关系,具体的这个代码能实现求解泊松方程的原理,我们也不去追究吧,仅仅从代码层面说说大概得事情。
首先是poissonSolver函数,其具体代码如下:
1 void Cloning::poissonSolver(const Mat &img, Mat &laplacianX , Mat &laplacianY, Mat &result)
2 {
3 const int w = img.cols;
4 const int h = img.rows;
5 Mat lap = laplacianX + laplacianY;
6 Mat bound = img.clone();
7 rectangle(bound, Point(1, 1), Point(img.cols-2, img.rows-2), Scalar::all(0), -1);
8 Mat boundary_points;
9 Laplacian(bound, boundary_points, CV_32F);
10 boundary_points = lap - boundary_points;
11 Mat mod_diff = boundary_points(Rect(1, 1, w-2, h-2));
12 solve(img,mod_diff,result);
13 }
这里,Opencv有一次把他的代码艺术展现的活灵活现。从低6到第11行,我们看到了一个艺术家为了获取最后的结果所做的各种行为艺术。
首先是复制原图,然后把原图除了第一行、最后一行、第一列、最后一列填充为黑色(rectangle函数),然后对这个填充后的图进行拉普拉斯边缘检测,然后第10行做个减法,最后第11行呢,又直接裁剪了去掉周边一个像素宽范围内的结果。
行为艺术家。
如果只从结果考虑,我们完全没有必要有这么多的中间过程,我们把边缘用*表示,中间值都为0,则一个二维平面图如下所示:
// 拉普拉斯卷积核如下 对应标识如下
// 1 Q1
// 1 -4 1 Q3 Q4 Q5
// 1 Q7
//
// * * * * * * * * *
// * 0 0 0 0 0 0 0 *
// * 0 0 0 0 0 0 0 *
// * 0 0 0 0 0 0 0 *
// * 0 0 0 0 0 0 0 *
// * 0 0 0 0 0 0 0 *
// * * * * * * * * *
所有为0的部位的计算值为我们需要的结果,很明显,除了最外一圈0值的拉普拉斯边缘检测不为0,其他的都为0,不需要计算,而周边一圈的0值的拉普拉斯边缘检测涉及到的3*3又恰好在原图的有效范围内,不需要考虑边缘的值,因此,我们可以直接一步到位写出mod_diff的值的。
ModDiff[0] = Laplacian[Width + 1] - (Image[1] + Image[Stride]); // 对应的拉普拉斯有效值为: Q1 + Q3 for (int X = 2; X 2; X++) { ModDiff[X - 1] = Laplacian[Width + X] - Image[X]; // Q1 } ModDiff[Width - 3] = Laplacian[Width + Width - 2] - (Image[Width - 2] + Image[Stride + Width - 1]); // Q1 + Q5 for (int Y = 2; Y 2; Y++) { unsigned char* LinePI = Image + Y * Stride; float* LinePL = Laplacian + Y * Widt服务器托管网h; float* LinePD = ModDiff + (Y - 1) * (Width - 2); LinePD[0] = LinePL[1] - LinePI[0]; // Q3 for (int X = 2; X 2; X++) { LinePD[X - 1] = LinePL[X]; // 0 } LinePD[Width - 3] = LinePL[Width - 2] - LinePI[Width - 1]; // Q5 } // 最后一行 ModDiff[(Height - 3) * (Width - 2)] = Laplacian[(Height - 2) * Width + 1] - (Image[(Height - 2) * Stride] + Image[(Height - 1) * Stride + 1]); // Q3 + Q7 for (int X = 2; X 2; X++) { ModDiff[(Height - 3) * (Width - 2) + X - 1] = Laplacian[(Height - 2) * Width + X] - Image[(Height - 1) * Stride + X]; // Q7 } ModDiff[(Height - 3) * (Width - 2) + Width - 3] = Laplacian[(Height - 2) * Width + Width - 2] - (Image[(Height - 2) * Stride + Width - 1] + Image[(Height - 1) * Stride + Width - 2]); // Q5 + Q7
接下来是我们的solve函数,这个函数不是核心,所以稍微提及一下:


void Cloning::solve(const Mat &img, Mat& mod_diff, Mat &result) { const int w = img.cols; const int h = img.rows; Mat res; dst(mod_diff, res); for(int j = 0 ; j 2; j++) { float * resLinePtr = res.ptrfloat>(j); for(int i = 0 ; i 2; i++) { resLinePtr[i] /= (filter_X[i] + filter_Y[j] - 4); } } dst(res, mod_diff, true); unsigned char * resLinePtr = result.ptrchar>(0); const unsigned char * imgLinePtr = img.ptrchar>(0); const float * interpLinePtr = NULL; //first col for(int i = 0 ; i i) result.ptrchar>(0)[i] = img.ptrchar>(0)[i]; for(int j = 1 ; j 1 ; ++j) { resLinePtr = result.ptrchar>(j); imgLinePtr = img.ptrchar>(j); interpLinePtr = mod_diff.ptrfloat>(j-1); //first row resLinePtr[0] = imgLinePtr[0]; for(int i = 1 ; i 1 ; ++i) { //saturate cast is not used here, because it behaves differently from the previous implementation //most notable, saturate_cast rounds before truncating, here it's the opposite. float value = interpLinePtr[i-1]; if(value 0.) resLinePtr[i] = 0; else if (value > 255.0) resLinePtr[i] = 255; else resLinePtr[i] = static_castchar>(value); } //last row resLinePtr[w-1] = imgLinePtr[w-1]; } //last col resLinePtr = result.ptrchar>(h-1); imgLinePtr = img.ptrchar>(h-1); for(int i = 0 ; i i) resLinePtr[i] = imgLinePtr[i]; }
View Code
他主要调用dst函数,然后对dst函数处理的结果再进行滤波,然后再调用dst函数,最后得到的结果进行图像化。 不过第一次dst是使用FFT正变换,第二次使用了FFT逆变换。
从他的恢复图像的过程看,他也是对最周边的一圈像素不做处理,直接使用背景的图像值。
那么我们再看看dst函数,这个是解泊松方程的关键所在,opencv的代码如下:
void Cloning::dst(const Mat& src, Mat& dest, bool invert) { Mat temp = Mat::zeros(src.rows, 2 * src.cols + 2, CV_32F); int flag = invert ? DFT_ROWS + DFT_SCALE + DFT_INVERSE: DFT_ROWS; src.copyTo(temp(Rect(1,0, src.cols, src.rows))); for(int j = 0 ; j j) { float * tempLinePtr = temp.ptrfloat>(j); const float * srcLinePtr = src.ptrfloat>(j); for(int i = 0 ; i i) { tempLinePtr[src.cols + 2 + i] = - srcLinePtr[src.cols - 1 - i]; } } Mat planes[] = {temp, Mat::zeros(temp.size(), CV_32F)}; Mat complex; merge(planes, 2, complex); dft(complex, complex, flag); split(complex, planes); temp = Mat::zeros(src.cols, 2 * src.rows + 2, CV_32F); for(int j = 0 ; j j) { float * tempLinePtr = temp.ptrfloat>(j); for(int i = 0 ; i i) { float val = planes[1].ptrfloat>(i)[j + 1]; tempLinePtr[i + 1] = val; tempLinePtr[temp.cols - 1 - i] = - val; } } Mat planes2[] = {temp, Mat::zeros(temp.size(), CV_32F)}; merge(planes2, 2, complex); dft(complex, complex, flag); split(complex, planes2); temp = planes2[1].t(); temp(Rect( 0, 1, src.cols, src.rows)).copyTo(dest); }
对Temp的数据填充中,我们看到他临时创建了宽度2*Width + 2大小的数据,高度为Height,其中第0列,第Width + 1列的数据为都为0,第1列到第Width +1列之间的数据为原是数据,第Width + 2到2*Width + 1列的数据为原始数据镜像后的负值。
填充完之后,在构造一个复数,然后调用FFT变换,当invert为false时,使用的DFT_ROWS参数,为true时,使用的是DFT_ROWS + DFT_SCALE + DFT_INVERSE参数,那么其实这里就是一维的FFT正变换和逆变换,即对数据的每一行单独处理,行于行之间是无关的,是可以并行的。
再进行了第一次FFT变换后,我们有创建一副宽度为2*Height+ 2,高度为Width大小的数据,这个时候数据里的填充值依旧分为2块,也是用黑色的处置条分开,同样右侧值的为镜像负值分布。但是这个时候原始值是从前面进行FFT变换后的数据中获取,而且还需要转置获取,其获取的是FFT变换的虚部的值。
填充完这个数据后,再次进行FFT变换,变换完之后,我们取变换后的虚部的值的转置,并且舍弃第一列的值,作为我们处理后的结果。
整个OPENCV的代码从逻辑上是比较清晰的,他通过各种内嵌的函数组合,实现了清晰的思路。但是如果从代码效率角度来说,是非常不可取的,从内存占用上来说,也存在着过多的浪费。这也是opencv中非核心函数通用的问题,基本上就是只在意结果,不怎么在乎过程和内存占用。
谈到这里,核心的泊松融合基本就讲完了,其各种不同的应用也是基于上述过程。
那么我们再稍微谈谈算法的优化和加速。
整个算法流程不算特别长,前面三个步骤的计算都比较简单,计算量也不是很大,慢的还是在于泊松方程的求解,而求解中最耗时还是那个DFT变换,简单的测试表面,DFT占整个算法耗时的80%(单线程下)。前面说过,这个内部使用的是一维行方向的DFT变换,行于行之间的处理是无关的,而且,他的数据量也比较大,特别适合于并行处理,我们可以直接用简单的omp就可以实现加速。
另外,我们再进行FFT时,常用的一个加速手段就是GetOptimalDftSize获得一个和原始尺寸最为接近而又能更快实现FFT的大小,通常他们是3或者4或者5的倍数。有时候,这个加速也非常的明显,比如尺寸为1023的FFT和尺寸为1024的FFT,速度可以相差好几倍。这里我也尝试使用这个函数,但是经过多次尝试(包括适当的改变数据布局),都存在一个严重的问题,得到的结果图像有着不可忽视的误差,基本无法恢复。因此,这个优化的步骤不得已只能放弃。
前面说了很多,还忘记了一个最重要的函数的扣取,dft函数,这个函数在opencv的目录如下: opencv-4.9.0源代码modulescoresrcdxt.cpp,居然是用的dxt这个文件名,开始我怎么搜都搜不到他。
关于这个功能的扣取,我大概也花了半个月的时间,时间上OPENCV也有很多版本,比如CPU的、opencl的等等,我这里扣取的是纯CPU的,而且还是从早期的CV的代码中扣的,现在的版本的代码里有太多不相关的东西了,扣取的难度估计还要更大。而且在扣取中我还做了一些优化,这个就不在这里多说了,总之,opencv的FFT在各种开源版本的代码中算是一份非常不错的代码。
具体的应用:
1、无缝的图像合成,对应CV的seamlessClone函数,他支持背景图和前景图图不一样大小,也可以没有蒙版等等特性,其具体的代码如下:
void cv::seamlessClone(InputArray _src, InputArray _dst, InputArray _mask, Point p, OutputArray _blend, int flags)
{
CV_INSTRUMENT_REGION();
CV_Assert(!_src.empty());
const Mat src = _src.getMat();
const Mat dest = _dst.getMat();
Mat mask = checkMask(_mask, src.size());
dest.copyTo(_blend);
Mat blend = _blend.getMat();
Mat mask_inner = mask(Rect(1, 1, mask.cols - 2, mask.rows - 2));
copyMakeBorder(mask_inner, mask, 1, 1, 1, 1, BORDER_ISOLATED | BORDER_CONSTANT, Scalar(0));
Rect roi_s = boundingRect(mask);
if (roi_s.empty()) return;
Rect roi_d(p.x - roi_s.width / 2, p.y - roi_s.height / 2, roi_s.width, roi_s.height);
Mat destinationROI = dest(roi_d).clone();
Mat sourceROI = Mat::zeros(roi_s.height, roi_s.width, src.type());
src(roi_s).copyTo(sourceROI,mask(roi_s));
Mat maskROI = mask(roi_s);
Mat recoveredROI = blend(roi_d);
Cloning obj;
obj.normalClone(destinationROI,sourceROI,maskROI,recoveredROI,flags);
}
copyMakeBorder这个东西,呵呵,和前面讲的那个rectangle的作用正好想法,把周边一圈设置为黑色,然后再提取出实际有效的边界(不为0的区域),以便减少计算量,后续再根据边界裁剪出有效的区域,交给具体的融合的函数处理。
opencv的这个函数写的实在不怎么好,当我们不小心设置了错误的p参数时,就会出现内存错误,这个参数主要是指定前景图像在背景图像中的位置的, 我们必须保证前景图像不能有任何部分跑到背景图像的外部,在我自己写的版本中已经校正了这个小错误。
注意,这里有个Flag参数,当Flag为NORMAL_CLONE时,就是我们前面的标准过程,当为MIXED_CLONE时,则在第二步体现了不同:
用原文的公式表示即为:

翻译为我们能看懂的意思就是:Mixed的模式下,如果前景的梯度差异大于背景的差异,则直接进行线性混合,否则就直接用背景的梯度。这个模式下可以获得更为理想的融合效果。
我想办法把论文中的一些测试图像抠出来,然后进行了一系列测试,确实能获得一些不错的效果。

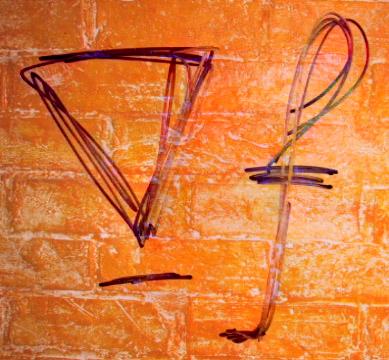
字符 背景纹理 服务器托管网 融合结果



海景 彩虹 融合后
上面为不带mask时全图进行融合,可以看到融合后前景基本完美的融合到了背景中,但是前景的颜色还是发生了一些改变。




背景图 前景图 蒙版图 合成图
上面这一幅测试图中,太阳以及太阳在水中的倒影也完美的融合到背景图中,相当的自然。
以下为多福图像和成到一幅中的效果。


前景1 前景1蒙版


前景2 前景2蒙版


背景图 融合后结果
上面所有的融合方式都是选择的MIXED_CLONE。
其实注意到MIXED_CLONE里梯度的混合原则,要达到上图这样较好的融合效果,对前景图实际上还是有一丝丝特别的要求的,那就是在前景图中,我们不希望保留的特征一定要是梯度变化比较小的区域,比如纯色范围,或者很类似的颜色这样的东西。
opencv里还有个MONOCHROME_TRANSFER这个Flag可以选,这个其实直接把前景图像变为彩色模式的灰度图就能得到一样的结果了。
对于任意的两幅图,进行这中无缝的泊松融合,也能出现一些奇葩的效果,比如下面这样的图。

不过这种图并没有什么实际意义。
2、图像的亮度的改变,对应illuminationChange函数,其具体代码为:
void Cloning::illuminationChange(Mat &I, Mat &mask, Mat &wmask, Mat &cloned, float alpha, float beta)
{
CV_INSTRUMENT_REGION();
computeDerivatives(I,mask,wmask);
arrayProduct(patchGradientX,binaryMaskFloat, patchGradientX);
arrayProduct(patchGradientY,binaryMaskFloat, patchGradientY);
Mat mag;
magnitude(patchGradientX,patchGradientY,mag);
Mat multX, multY, multx_temp, multy_temp;
multiply(patchGradientX,pow(alpha,beta),multX);
pow(mag,-1*beta, multx_temp);
multiply(multX,multx_temp, patchGradientX);
patchNaNs(patchGradientX);
multiply(patchGradientY,pow(alpha,beta),multY);
pow(mag,-1*beta, multy_temp);
multiply(multY,multy_temp,patchGradientY);
patchNaNs(patchGradientY);
Mat zeroMask = (patchGradientX != 0);
patchGradientX.copyTo(patchGradientX, zeroMask);
patchGradientY.copyTo(patchGradientY, zeroMask);
evaluate(I,wmask,cloned);
}
这个的基础是下面的公式:

通过调整Alpha和Beta值,改变原始的亮度,然后再将改变亮度后的图和原始的图进行泊松融合,所以这里的前景图是由背景图生成的。
这里的代码再一次体现opencv的艺术家的特性:pow(mag,-1*beta, multx_temp);这么耗时的操作居然执行了两次。
这里的核心其实还是在算法的第二步:根据一定的原则计算融合后的图像的梯度场,其他的过程和标准的无缝融合是一样的。
不过不可理解的是,为什么这个函数opencv不使用类似seamlessclone的boundingRect函数缩小需要计算的范围了,这样实际是可以提速很多的。
这个函数用论文提供的自带图像确实有较为不错的效果,比如下面这个橙子的高光部分从视觉上看确实去掉的比较完美,但是也不是所有的高光都能完美去掉。



原始图 蒙版 结果图(alpha = 0.2, beta = 0.3)
论文里还提到了可以对偏黑的图进行适度调亮,这个我倒是没有测试成功。
3、图像颜色调整,对应函数localColorChange,这个函数就更为简单了。
void Cloning::localColorChange(Mat &I, Mat &mask, Mat &wmask, Mat &cloned, float red_mul=1.0,
float green_mul=1.0, float blue_mul=1.0)
{
computeDerivatives(I,mask,wmask);
arrayProduct(patchGradientX,binaryMaskFloat, patchGradientX);
arrayProduct(patchGradientY,binaryMaskFloat, patchGradientY);
scalarProduct(patchGradientX,red_mul,green_mul,blue_mul);
scalarProduct(patchGradientY,red_mul,green_mul,blue_mul);
evaluate(I,wmask,cloned);
}
这个其实就在前景图上的梯度上乘上不同的系数,然后再和原图融合,这种调整可能比直接调整颜色要自然一些。



4、cv里还提供了一个纹理平整化的算法,叫textureFlatten,我没感觉到这个算法有多大的作用。所以就没有怎么去实现。
其实算法论文里还有个Seamless tilingg功能的,我自己尝试去实现,暂时没有获取正确的结果,如下图所示:

这个效果再有些场景下还是很有用的。
最后谈及下算法速度吧,因为整体都是翻译自opencv,而且核心最耗时的FFT部分也基本是直接翻译的,所以不会有本质的区别,在默认情况下,我用opencv 4.0版本去测试,同样大小的图,如果我不开openmp,耗时比大概是10:6,其中10是我的耗时,我估计这个于CV内部调用的DFT算法版本有关。此时我们观察到使用CV时,CPU的使用率在35%(4核),当在CV下加入setNumThreads(1)指令后,可以看到CPU使用在25%,此时耗时比大概是10:8。当我使用2个线程加速我的FFT1D时,CV也使用默认设置,耗时比约为5:6,此时我的CPU占用率约为40%,因此比cv版本的还是要快一些的。
以上对比仅限于seamlessclone,对于其他的函数,我做了boundRect,那就不是块一点点了。
为了方便测试,我做了一个可视化的UI,有兴趣的朋友可以自行测试看看效果。
总的来说,这个泊松融合要想获取自己需要的结果,还是要有针对性的针对第二步梯度的融合多做些考虑和调整,才能获取到自己需要的结果。
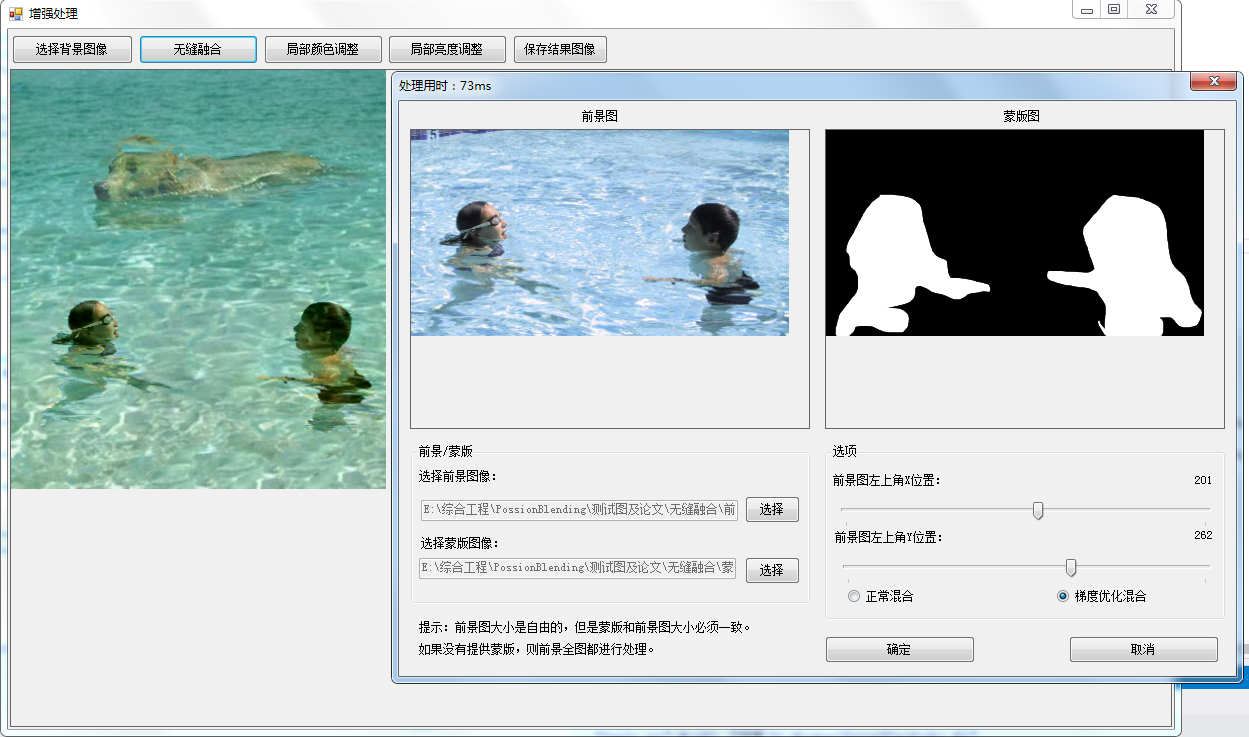
测试Demo及测试图片下载地址: https://files.cnblogs.com/files/Imageshop/PossionBlending.rar?t=1705395766&download=true
如果想时刻关注本人的最新文章,也可关注公众号或者添加本人微信: laviewpbt

翻译
搜索
复制
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
#include //kMP算法 char* my_strstr(const char* p1, c服务器托管网onst char* p2) { assert(p1 != NULL); assert(p2 != NULL); char *s1 = (char …
