
从零开始
在本文中,我们将详细介绍如何在Python / pyspark环境中使用graphx进行图计算。GraphX是Spark提供的图计算API,它提供了一套强大的工具,用于处理和分析大规模的图数据。通过结合Python / pyspark和graphx,您可以轻松地进行图分析和处理。
为了方便那些刚入门的新手,包括我自己在内,我们将从零开始逐步讲解。
安装Spark和pyspark
如果你只是想单独运行一下pyspark的演示示例,那么只需要拥有Python环境就可以了。你可以前往官方网站的快速开始页面查看详细的指南:https://spark.apache.org/docs/latest/api/python/getting_started/quickstart_df.html
安装pyspark包
pip install pyspark
由于官方省略的步骤还是相当多的,我简单写了一下我的成功演示示例。
from pyspark.sql import SparkSession,Row
from datetime import datetime, date
import pandas as pd
import os
os.environ['PYSPARK_PYTHON'] = "%你的Python包路径%//python.exe"
spark = SparkSession.builder.getOrCreate()
df = spark.createDataFrame([
Row(a=1, b=2., c='string1', d=date(2000, 1, 1), e=datetime(2000, 1, 1, 12, 0)),
Row(a=2, b=3., c='string2', d=date(2000, 2, 1), e=datetime(2000, 1, 2, 12, 0)),
Row(a=4, b=5., c='string3', d=date(2000, 3, 1), e=datetime(2000, 1, 3, 12, 0))
])
df.show()
然而,考虑到我们今天需要使用GraphX进行分析,因此我们仍然需要安装Spark。
安装Spark
请访问Spark官方网站(https://spark.服务器托管网apache.org/downloads.html)以获取适用于您操作系统的最新版本,并进行下载。如果您觉得下载速度较慢,您还可以选择使用国内阿里镜像进行下载。为了方便起见,我已经帮您找到了相应的镜像地址。
国内阿里镜像:https://mirrors.aliyun.com/apache/spark/spark-3.5.0/?spm=a2c6h.25603864.0.0.52d72104qIXCsH
请下载带有hadoop的版本:spark-3.5.0-bin-hadoop3.tgz。解压缩Spark压缩包即可
配置环境变量
在安装Spark之前,请务必记住需要Java环境。请确保提前配置好JAVA_HOME环境变量,这样才能正常运行Spark。
在windows上安装Java和Apache Spark后,设置SPARK_HOME、HADOOP_HOME和PATH环境变量。如果你知道如何在windows上设置环境变量,请添加以下内容:
SPARK_HOME = C:appsoptspark-3.5.0-bin-hadoop3
HADOOP_HOME = C:appsoptspark-3.5.0-bin-hadoop3

在Windows上使用winutils.exe的Spark
在Windows上运行Apache Spark时,确保你已经下载了适用于Spark版本的winutils.exe。winutils.exe是一个用于在Windows环境下模拟类似POSIX的文件访问操作的工具,它使得Spark能够在Windows上使用Windows特有的服务和运行shell命令。
你可以从以下链接下载适用于你所使用的Spark版本的winutils.exe:https://github.com/kontext-tech/winutils/tree/master/hadoop-3.3.0/bin
请确保将下载的winutils.exe文件放置在Spark安装目录的bin文件夹下,以便Spark能够正确地使用它来执行Windows特有的操作。
Apache Spark shell
spark-shell是Apache Spark发行版附带的命令行界面(CLI)工具,它可以通过直接双击或使用命令行窗口在Windows操作系统上运行。此外,Spark还提供了一个Web UI界面,用于在Windows上进行可视化监控和管理。
请尝试运行Apache Spark shell。当你成功运行后,你应该会看到一些内容输出(请忽略最后可能出现的警告信息)。
在启动Spark-shell时,它会自动创建一个Spark上下文的Web UI。您可以通过从浏览器中打开URL,访问Spark Web UI来监控您的工作。
GraphFrames
在前面的步骤中,我们已经完成了所有基础设施(环境变量)的配置。现在,我们需要进行一些配置来使Python脚本能够运行graphx。
要使用Python / pyspark运行graphx,你需要进行一些配置。接下来的示例将展示如何配置Python脚本来运行graphx。
GraphFrames的安装
如需获得更多关于GraphFrames的信息和快速入门指南,请访问官方网站:https://graphframes.github.io/graphframes/docs/_site/quick-start.html。
你也可以使用以下命令来安装GraphFrames。
pip install graphframes
在继续操作之前,请务必将graphframes对应的jar包安装到spark的jars目录中,以避免在使用graphframes时出现以下错误:
java.lang.ClassNotFoundException: org.graphframes.GraphFramePythonAPI

将下载好的jar包放入你的%SPARK_HOME%jars即可。

接下来,我们可以开始正常地使用graphx图计算框架了。现在,让我们简单地浏览一下一个示例demo。
from pyspark.sql.types import *
from pyspark.sql import SparkSession
from pyspark import SparkContext, SparkConf
import pandas as pd
from graphframes import GraphFrame
spark_conf = SparkConf().setAppName('Python_Spark_WordCount').setMaster('local[2]')
sc = SparkContext(conf=spark_conf)
spark=SparkSession.builder.appName("graph").getOrCreate()
v = spark.createDataFrame([
("a", "Alice", 34),
("b", "Bob", 36),
("c", "Charlie", 30),
], ["id", "name", "age"])
# Create an Edge DataFrame with "src" and "dst" columns
e = spark.createDataFrame([
("a", "b", "friend"),
("b", "c", "follow"),
("c", "b", "follow"),
], ["src", "dst", "relationship"])
# Create a GraphFrame
g = GraphFrame(v, e)
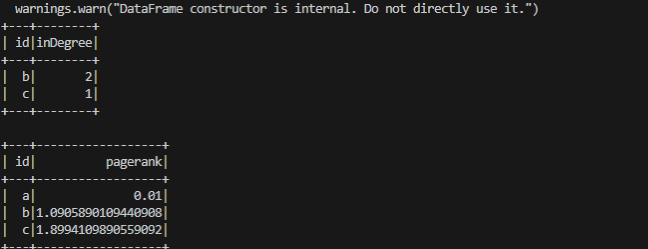
# Query: Get in-degree of each vertex.
g.inDegrees.show()
# Query: Count the number of "follow" connections in the graph.
g.edges.filter("relationship = 'follow'").count()
# Run PageRank algorithm, and show results.
results = g.pageRank(resetProbability=0.01, maxIter=20)
results.vertices.select("id", "pagerank").show()
如果运行还是报错:org.apache.spark.SparkException: Python worker failed to connect back
import os
os.environ['PYSPARK_PYTHON'] = "%你自己的Python路径%//Python//python.exe"
最后大功告成:
网络流量分析
接下来,我们将探讨一下是否能够对网络流量进行分析。对于初学者来说,很难获得一些有组织的日志文件或数据集,所以我们可以自己制造一些虚拟数据,以便进行演示。
首先,让我来详细介绍一下GraphFrame(v, e)的参数:
参数v:Class,这是一个保存顶点信息的DataFrame。DataFrame必须包含名为”id”的列,该列存储唯一的顶点ID。
参数e:Class,这是一个保存边缘信息的DataFrame。DataFrame必须包含两列,”src”和”dst”,分别用于存储边的源顶点ID和目标顶点ID。
edges=sc.textFile(r'/Users/xiaoyu/edges')
edges=edges.map(lambda x:x.split('t'))
edges_df=spark.createDataFrame(edges,['src','dst'])
nodes=sc.textFile(r'/Users/xiaoyu/nodes')
nodes=nodes.map(lambda x:[x])
nodes_df=spark.createDataFrame(nodes,['id'])
graph=GraphFrame(nodes_df, edges_df)
为了创建图数据结构并进行分析,可以简化流程,直接读取相关文件并进行处理。
# 计算每个节点的入度和出度
in_degrees = graph.inDegrees
out_degrees = graph.outDegrees
# 打印节点的入度和出度
in_degrees.show()
服务器托管网out_degrees.show()
查找具有最大入度和出度的节点:
# 找到具有最大入度的节点
max_in_degree = in_degrees.agg(F.max("inDegree")).head()[0]
node_with_max_in_degree = in_degrees.filter(in_degrees.inDegree == max_in_degree).select("id")
# 找到具有最大出度的节点
max_out_degree = out_degrees.agg(F.max("outDegree")).head()[0]
node_with_max_out_degree = out_degrees.filter(out_degrees.outDegree == max_out_degree).select("id")
# 打印结果
node_with_max_in_degree.show()
node_with_max_out_degree.show()
总结
本文介绍了如何在Python / pyspark环境中使用graphx进行图计算。通过结合Python / pyspark和graphx,可以轻松进行图分析和处理。首先需要安装Spark和pyspark包,然后配置环境变量。接着介绍了GraphFrames的安装和使用,包括创建图数据结构、计算节点的入度和出度,以及查找具有最大入度和出度的节点。最后,希望本文章对于新手来说有一些帮助~
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 详解十大经典排序算法(三):插入排序(Insertion Sort)
算法原理 每次从无序部分选择一个元素,将其插入到有序部分的正确位置,重复这个过程直至整个数组有序。 算法描述 插入排序是一种简单直观的排序算法,它的基本思想是将一个待排序的元素插入到已经排序好的序列中的适当位置,从而得到一个新的、长度加一的有序序列。插入排序的…
