
OPTICS是基于DBSCAN改进的一种密度聚类算法,对参数不敏感。当需要用到基于密度的聚类算法时,可以作为DBSCAN的一种替代的优化方案,以实现更优的效果。
原理
基于密度的聚类算法(1)——DBSCAN详解_dbscan聚类_root-cause的博客-CSDN博客
重点关照
DBSCAN的优缺点及应用场景:
(1)DBSCAN的优点:
1) 可以对任意形状的稠密数据集进行聚类,相对的,K-Means之类的聚类算法一般只适用于服务器托管网凸数据集。
2) 可以在聚类的同时发现异常点,对数据集中的异常点不敏感,和BIRCH聚类一样。
3) 聚类结果没有偏倚,相对的,K-Means之类的聚类算法初始值对聚类结果有很大影响。
(2)DBSCAN的缺点:
1)如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合。
2) 如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进。
3) 调参稍复杂,对参数比较敏感。主要需要对距离阈值,邻域样本数阈值MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响
python实现
原始数据
from sklearn.cluster import DBSCAN
#from sklearn import metrics
from sklearn.datasets import make_blobs
from sklearn.preprocessing import StandardScaler
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['STKaiTi'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
# 产生数据
centers = [[1, 1], [-1, -1], [1, -1]]
#make_blobs函数是为聚类产生数据集,产生服务器托管网一个数据集和相应的标签
X,ltrue=make_blobs(n_samples=750,centers=centers,cluster_std=0.4,random_state=0)
X = StandardScaler().fit_transform(X)
# 画出原始的数据点
plt.figure(0, figsize=(8, 6))
plt.scatter(X[:, 0], X[:, 1],c = ltrue)
plt.show()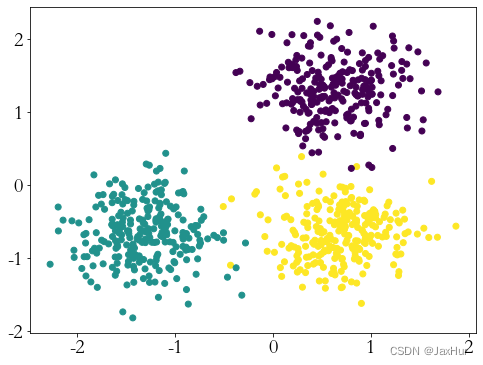
DBSCAN聚类
# 调用DBSCAN
model = DBSCAN(eps=0.3, min_samples=10)
db=model.fit(X)
labels = db.labels_
#-1表示那些噪声点
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
print(n_clusters_)
print(set(labels))
# 统计每一类的数量
import pandas as pd
counts = pd.value_counts(model.fit_predict(X),sort=True)
print(counts)
plt.figure(1, figsize=(8, 6))
plt.scatter( X[:, 0], X[:, 1],c=db.labels_)
plt.show()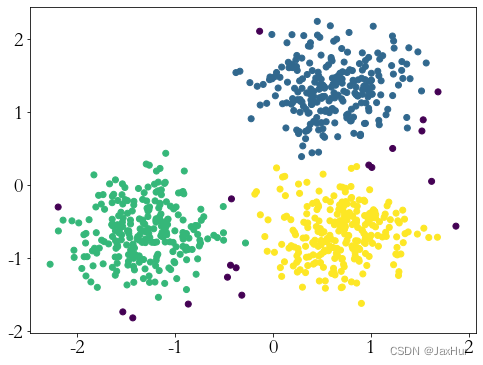
图中黑色的是异常点,在取参数的过程中发现对参数比较敏感,一不小心就不对了
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
C++ 模板 C++ 模板是一种强大的泛型编程工具,它允许我们编写通用的代码,可以用于处理多种不同的数据类型。模板允许我们在编写代码时将类型作为参数进行参数化,从而实现代码的重用性和灵活性。 在 C++ 中,模板由关键字 template 开始,并且后面跟着模…
