
- 前言
- 一、一次性全量
- 二、定时任务增量
- 三、强一致性问题
-
四、canal 框架
- 4.1基本原理
-
4.2安装使用(重点)
- 版本说明
- 4.3引入依赖(测试)
- 4.4代码示例(测试)
- 五、文章小结
前言
在日常项目开发中,可能会遇到使用 ES 做关键词搜索的场景,但是一般来说业务数据是不会直接通过 CRUD 写进 ES 的。
因为这可能违背了 ES 是用来查询的初衷,数据持久化的事情可以交给数据库来做。那么,这里就有一个显而易见的问题:ES 里的数据从哪里来?
本文介绍的就是如何将 MySQL 的表数据迁移到 ES 的全过程。
一、一次性全量
该方案的思路很简单直接:将数据库中的表数据一次性查出,放入内存,在转换 DB 与 ES 的实体结构,遍历循环将 DB 的数据 放入 ES 中。
但是对机器的性能考验非常大:本地 MySQL 10w 条数据,电脑内存16GB,仅30秒钟内存占用90%,CPU占用100%。太过于粗暴了,不推荐使用。
@Component05
@Slf4j
public class FullSyncArticleToES implements CommandLineRunner {
@Resource
private ArticleMapper articleMapper;
@Resource
private ArticleRepository articleRepository;
/**
* 执行一次即可全量迁移
*/
//todo: 弊端太明显了,数据量一大的话,对内存和 cpu 都是考验,不推荐这么简单粗暴的方式
public void fullSyncArt服务器托管网icleToES() {
LambdaQueryWrapper wrapper = new LambdaQueryWrapper();
List articleList = articleMapper.selectList(wrapper);
if (CollectionUtils.isNotEmpty(articleList)) {
List esArticleList = articleList.stream().map(ESArticle::dbToEs).collect(Collectors.toList());
final int pageSize = 500;
final int total = esArticleList.size();
log.info("------------FullSyncArticleToES start!-----------, total {}", total);
for (int i = 0; i 二、定时任务增量
这种方案的思想是按时间范围以增量的方式读取,比全量的一次性数据量要小很多。
也存在弊端:频繁的数据库连接 + 读写,对服务器资源消耗较大。且在极端短时间内大量数据写入的场景,可能会导致性能、数据不一致的问题(即来不及把所有数据都查到,同时还要写到 ES)。
但还是有一定的可操作性,毕竟可能没有那么极端的情况,高并发写入的场景不会时刻都有。
@Component
@Slf4j
public class IncSyncArticleToES {
@Resource
private ArticleMapper articleMapper;
@Resource
private ArticleRepository articleRepository;
/**
* 每分钟执行一次
*/
@Scheduled(fixedRate = 60 * 1000)
public void run() {
// 查询近 5 分钟内的数据,有 id 重复的数据 ES 会自动覆盖
Date fiveMinutesAgoDate = new Date(new Date().getTime() - 5 * 60 * 1000L);
List articleList = articleMapper.listArticleWithData(fiveMinutesAgoDate);
if (CollectionUtils.isNotEmpty(articleList)) {
List esArticleList = articleList.stream().map(ESArticle::dbToEs).collect(Collectors.toList());
final int pageSize = 500;
int total = esArticleList.size();
log.info("------------IncSyncArticleToES start!-----------, total {}", total);
for (int i = 0; i 三、强一致性问题
如果大家看完以上两个方案,可能会有一个问题:
无论是增量还是全量, MySQL 和 ES 进行连接/读写是需要耗费时间的,如果这个过程中如果有大量的数据插到 MySQL 里,那么有没有可能写入 ES 里的数据并不能和 MySQL 里的完全一致?
答案是:在数据量大和高并发的场景下,是很有可能会发生这种情况的。
如果需要我们自己写代码来保证一致性,可以怎么做才能较好地解决呢?
思路:由于 ES 查询做了分页,每次查只有10 条,那么每次调用查询的时候,就拿这10条数据的唯一标识 id 再去 MySQL 中查一下,MySQL 里有的就会被查出来,那么返回这些结果就好,就不直接返回 ES 的查询结果了;同时删除掉 ES 里那些在数据库中被删除的数据,做个”反向同步“。这个思路有几个明显的优点:
1、单次数据量很小,在内存中操作几乎就是毫秒级的;
2、返回的是 MySQL 的源数据,不再 ”信任“ ES 了,保证强一致性;
3、反向删除 ES 中的那些已经被 MySQL 删除了的数据。
以下是代码,注释很详细,应该很好理解:
@Override
public PageInfo testSearchFromES(ArticleSearchDTO articleSearchDTO){
// 获取查询对象的结果, searchQuery 这里忽略,就当查询条件已经写好了,可以查到数据
SearchHits searchHits = elasticTemplate.search(searchQuery, ESArticle.class);
//todo: 以下考虑使用 MySQL 的源数据,不再以 ES 的数据为准
List resultList = new ArrayList();
// 从 ES 查出结果后,再与 db 获的数据进行对比,确认后再组装返回
if (searchHits.hasSearchHits()) {
// 收集 ES 里业务对象的 Id 成 List
List articleIdList = searchHits.getSearchHits().stream()
.map(val -> val.getContent().getId())
.collect(Collectors.toList());
// 获取数据库的符合体条件的数据,由于是分页的,一次性的数据量小(10条而已),剩下的都是内存操作,性能可以保证
List articleList = baseMapper.selectBatchIds(articleIdList);
if (CollectionUtils.isNotEmpty(articleList)) {
//根据 db 里业务对象的 Id 进行分组
Map> idArticleMap = articleList.stream().collect(Collectors.groupingBy(Article::getId));
//对 ES 中的 Id 的集合进行 for 循环,经过对比后添加数据
articleIdList.forEach(articleId -> {
// 如果 ES 里的 Id 在数据库里有,说明数据已经同步到 ES 了,两边的数据是一致的
if (idArticleMap.containsKey(articleId)) {
// 则把符合的数据放入 page 对象中
resultList.add(idArticleMap.get(articleId).get(NumberUtils.INTEGER_ZERO));
} else {
// 删除 ES 中那些在数据库中被删除的数据;因为数据库都没有这条数据库了,那么 ES 里也不能有,算是一种反向同步吧
String delete = elasticTemplate.delete(String.valueOf(articleId), PostEsDTO.class);
log.info("delete post {}", delete);
}
});
}
}
// 初始化 page 对象
PageInfo pageInfo = new PageInfo();
pageInfo.setList(resultList);
pageInfo.setTotal(searchHits.getTotalHits());
System.out.println(pageInfo);
return pageInfo;
}
然而,以上的所有内容并不是今天文章的重点。只是为引入 canal 做的铺垫,引入、安装、配置好 canal 后可以解决以上的全部问题。对,就是全部。
四、canal 框架
4.1基本原理
canal 是 Alibaba 开源的一个用于 MySQL 数据库增量数据同步工具。它通过解析 MySQL 的 binlog 来获取增量数据,并将数据发送到指定位置。
canal 会模拟 MySQL slave 的交互协议,伪装自己为 MySQL 的 slave ,向 MySQL master 发送 dump 协议。MySQL master 收到 dump 请求,开始推送 bin-log 给 slave (即 canal )。
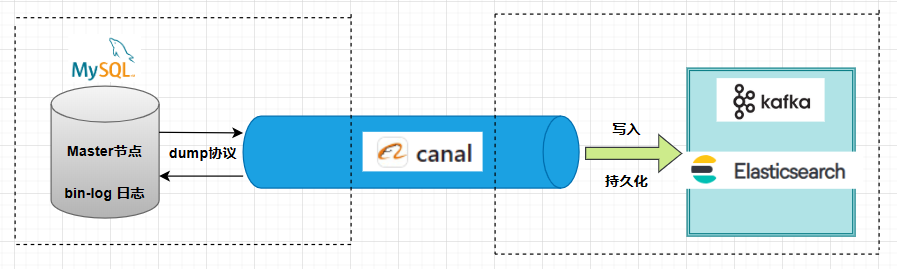
canal 简单原理
canal 的高可用分为两部分:canal server 和 canal client。
canal server 为了减少对 MySQL dump 的请求,不同 server 上的实例要求同一时间只能有一个处于 running 状态;
canal client 为了保证有序性,一份实例同一时间只能由一个 canal client 进行 get/ack/rollback 操作来保证顺序。
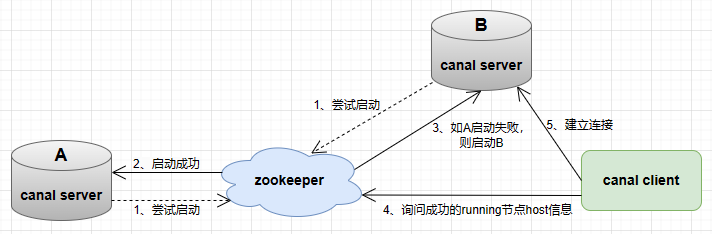
canal 高可用
4.2安装使用(重点)
-
版本说明
- Centos 7(这个关系不大)
- JDK 11(这个很关键)
- MySQL 5.7.36(只要5.7.x都可)
- Elasticsearch 7.16.x(不要太高,比较关键)
- cannal.server: 1.1.5(有官方镜像,放心拉取)
- canal.adapter: 1.1.5(无官方镜像,但问题不大)
注:我这里由于自己的个人服务器的一些中间件版本问题,始终无法成功安装上 canal-adapter,所以没有最终将数据迁移到 ES 里去。

主要原因在于两点:
- JDK 版本需要 JDK11及以上,我自己个人服务器现用的是 JDK 8,但 canal 并不兼容 JDK 8;
- 我的 ES 的版本太高用的是7.6.1,这可能导致 canal 版本与它不兼容,可能实际需要降低到7.16.x 左右。
但是本人在工作中是有过项目实践的,推荐使用 docker 安装 canal,步骤参考:https://zhuanlan.zhihu.com/p/465614745
4.3引入依赖(测试)
com.alibaba.otter
canal.client
1.1.4
4.4代码示例(测试)
以下代码 demo 来自官网,仅用于测试。
首先需要连接上4.2小节中的 canal-server 配置,然后启动该类中的 main 方法后会不断去监听对应的 MySQL 库-表数据是否有变化,有的话就打印出来。
public class CanalClientUtils {
public static void main(String[] args) {
// 创建连接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress
("你的公网ip地址", 11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*..*");
connector.rollback();
int totalEmptyCount = 1000;
while (emptyCount entries) {
for (CanalEntry.Entry entry : entries) {
if (entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONBEGIN || entry.getEntryType() == CanalEntry.EntryType.TRANSACTIONEND) {
continue;
}
CanalEntry.RowChange rowChage;
try {
rowChage = CanalEntry.RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of error-event has an error , data:" + entry, e);
}
CanalEntry.EventType eventType = rowChage.getEventType();
System.out.printf(
"-----------binlog[%s:%s] , name[%s,%s] , eventType:%s%n ------------",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType);
for (CanalEntry.RowData rowData : rowChage.getRowDatasList()) {
if (eventType == CanalEntry.EventType.DELETE) {
printColumn(rowData服务器托管网.getBeforeColumnsList());
} else if (eventType == CanalEntry.EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("---------before data----------");
printColumn(rowData.getBeforeColumnsList());
System.out.println("---------after data-----------");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List columns) {
for (CanalEntry.Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + ",update status:" + column.getUpdated());
}
}
}
预期的结果会表明涉及的库、表名称,以及操作的类型,同时还可以知道字段的状态:true 为有变化,false 为无变化。如下图所示:
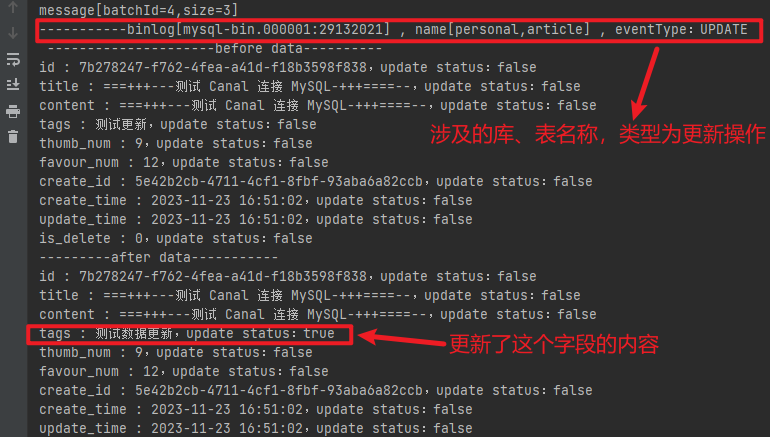
canal 监听示例
以上的4.3和4.4小节都是用来测试效果的,在服务器上安装配置好 canal 以后,实际无需在项目中写关于 canal 的操作代码。
每一步的 MySQL 操作 binlog 都会被 canal 获取到,然后将数据同步到 ES 中,这些操作都是在服务器上进行的,基本上对于开发人员来说是无感的。
阿里云上有专门的产品来支持数据从 MySQL 迁移到 ES 的场景,真正的商业项目开发,还是可以选择云厂商现有的方案(我不是打广告):
https://help.aliyun.com/zh/dts/user-guide/migrate-data-from-an-apsaradb-rds-for-mysql-instance-to-an-elasticsearch-cluster?spm=a2c4g.11186623.0.0.33626255Aql88M
五、文章小结
到这里我就和大家分享完了关于数据从 MySQL 迁移到 ES 全过程的思考,如有错误和不足,期待大家的指正和交流。
参考文档:
- 阿里巴巴 canal 的 GitHub 开源项目地址:https://github.com/alibaba/canal
- 安装以及配置步骤:https://zhuanlan.zhihu.com/p/465614745
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: Java之Date类以及SimpleDateFormal类的概述
Date类 1.1 Date概述 java.util.Date`类 表示特定的瞬间,精确到毫秒。 继续查阅Date类的描述,发现Date拥有多个构造函数,只是部分已经过时,我们重点看以下两个构造函数 public Date():从运行程序的此时此刻到时间原点经…
