
文章目录
- 【AI 实战】Text Processing and Word Embedding 文本处理以及词嵌入原理和代码实例讲解
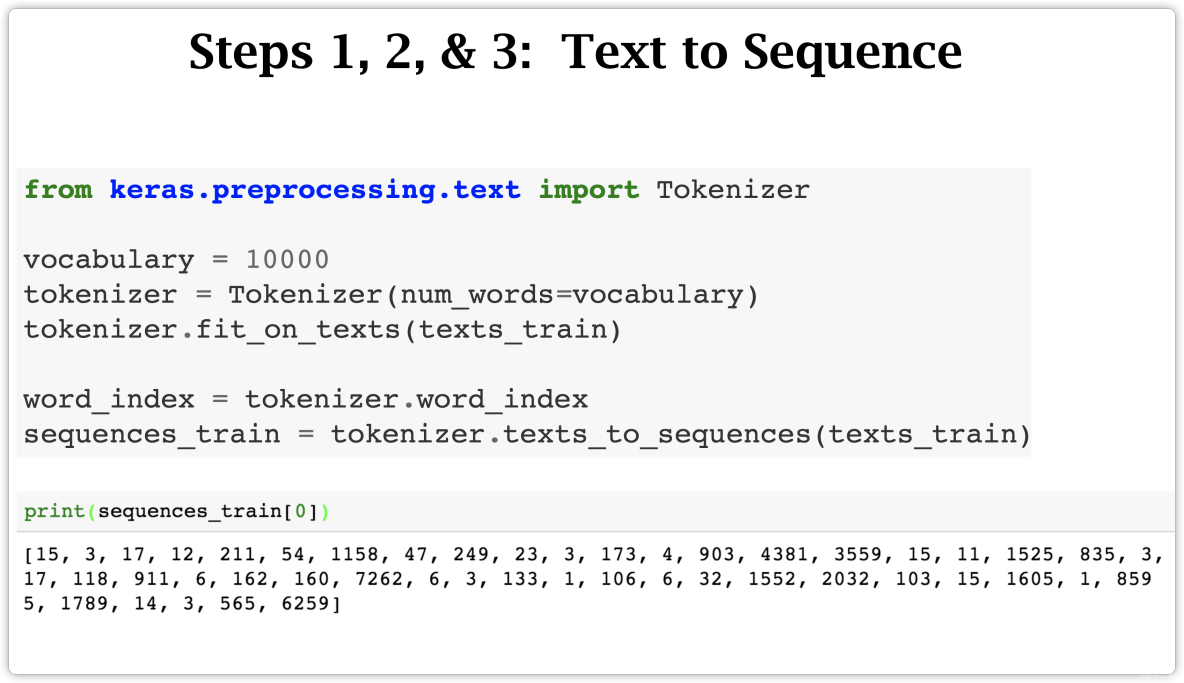
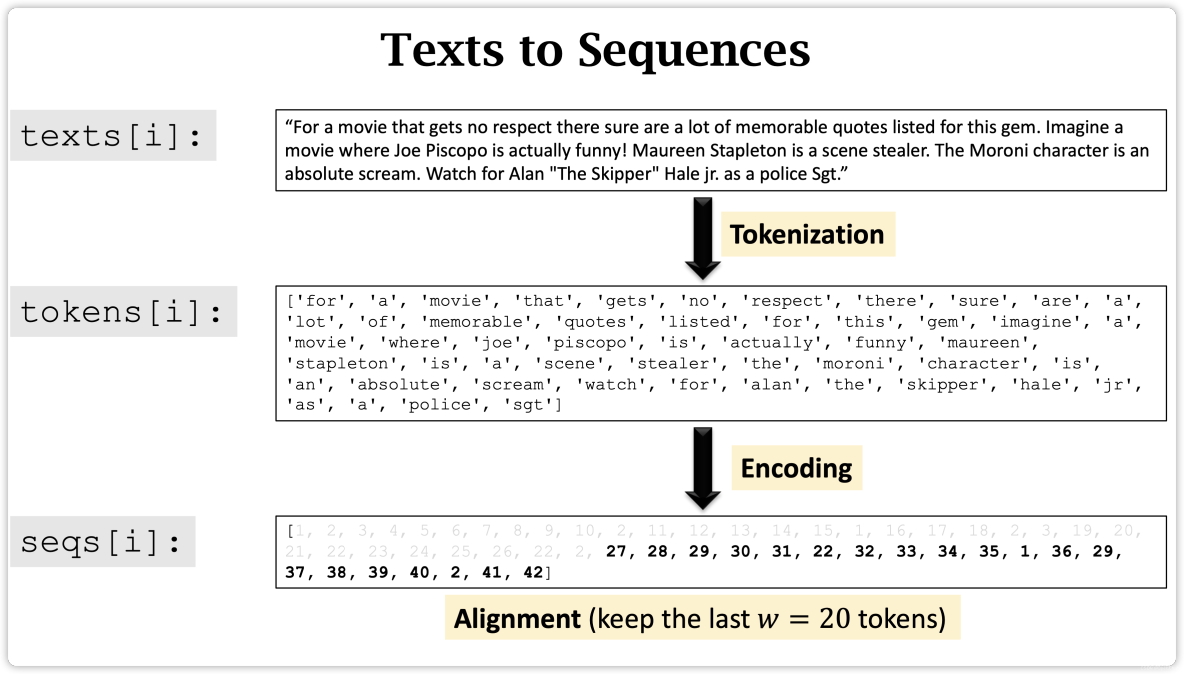
- Text to Sequence
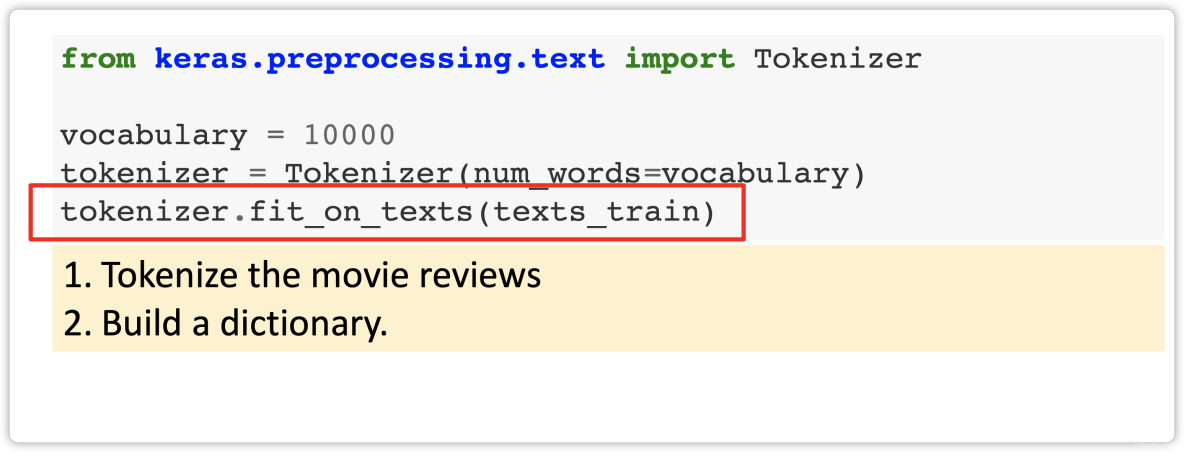
- Step 1: Tokenization
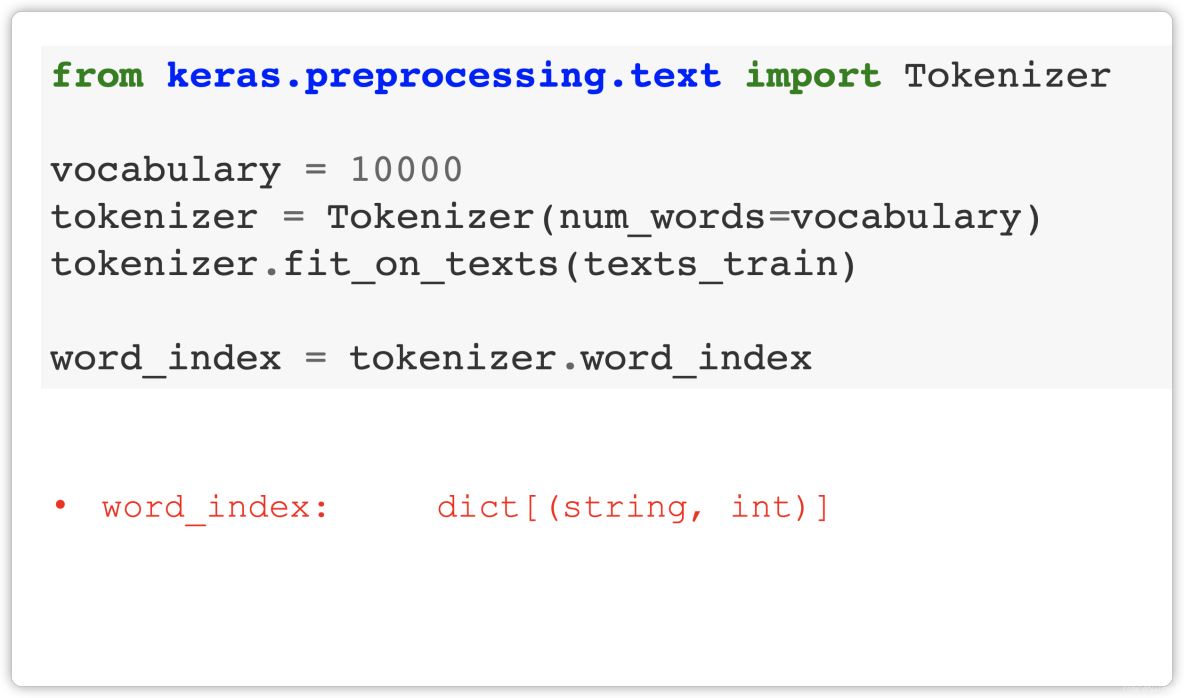
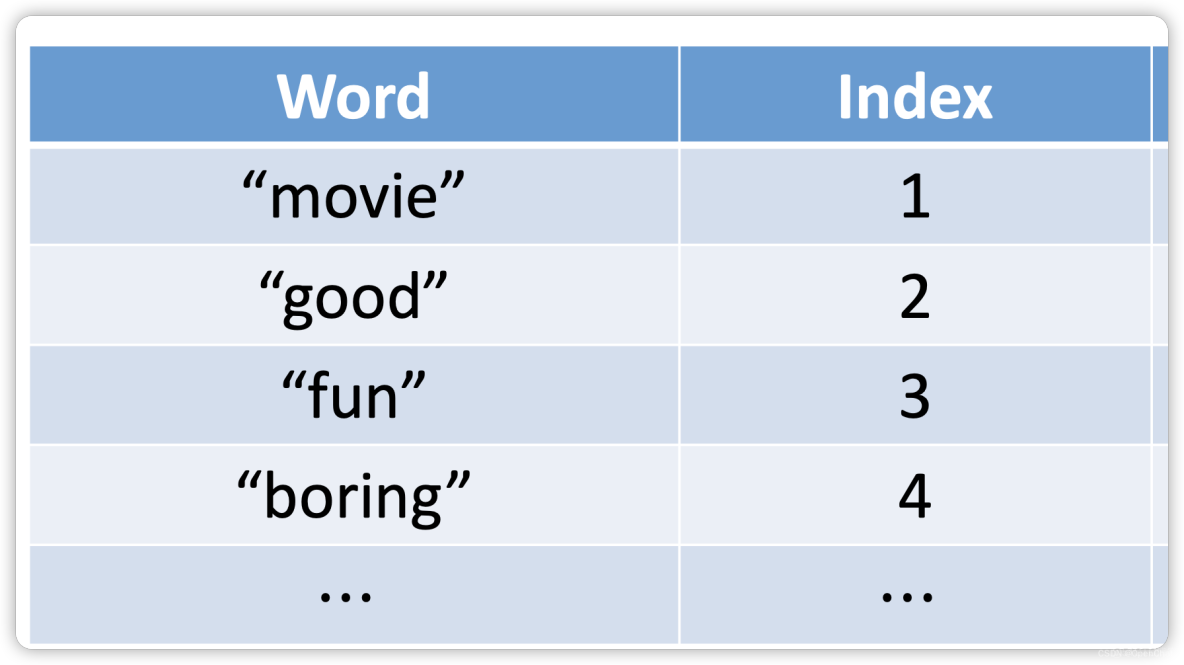
- Step 2: Build Dictionary
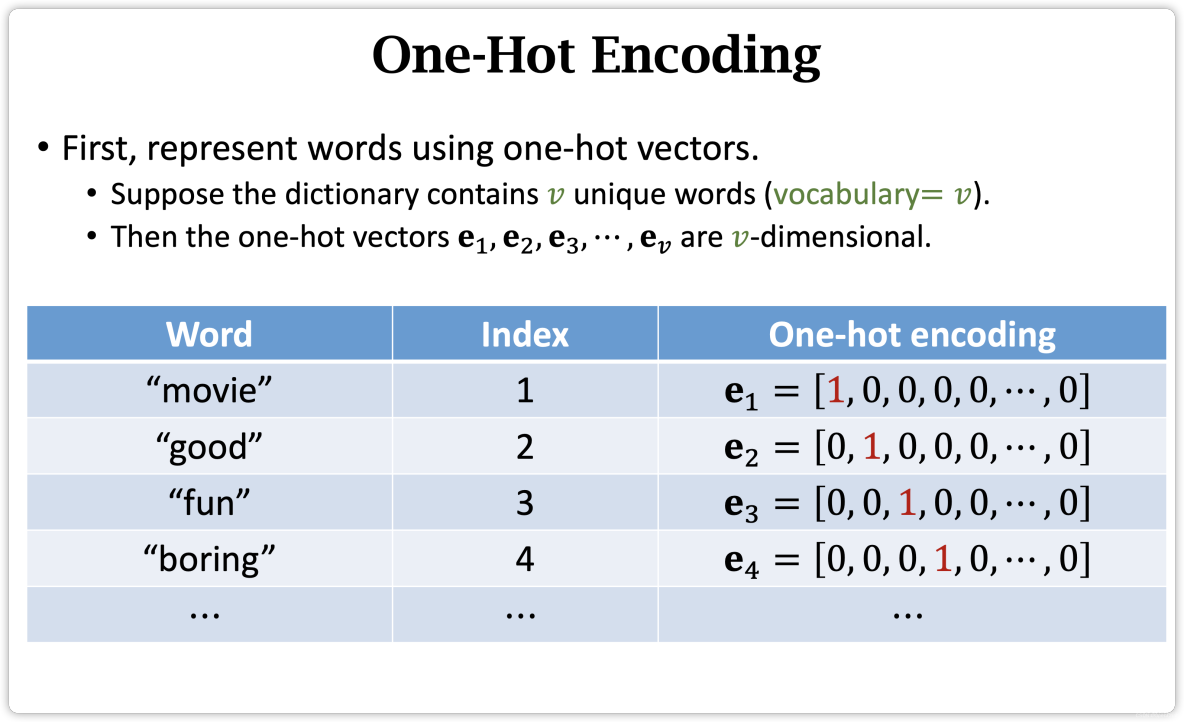
- Step 3: One-Hot Encoding
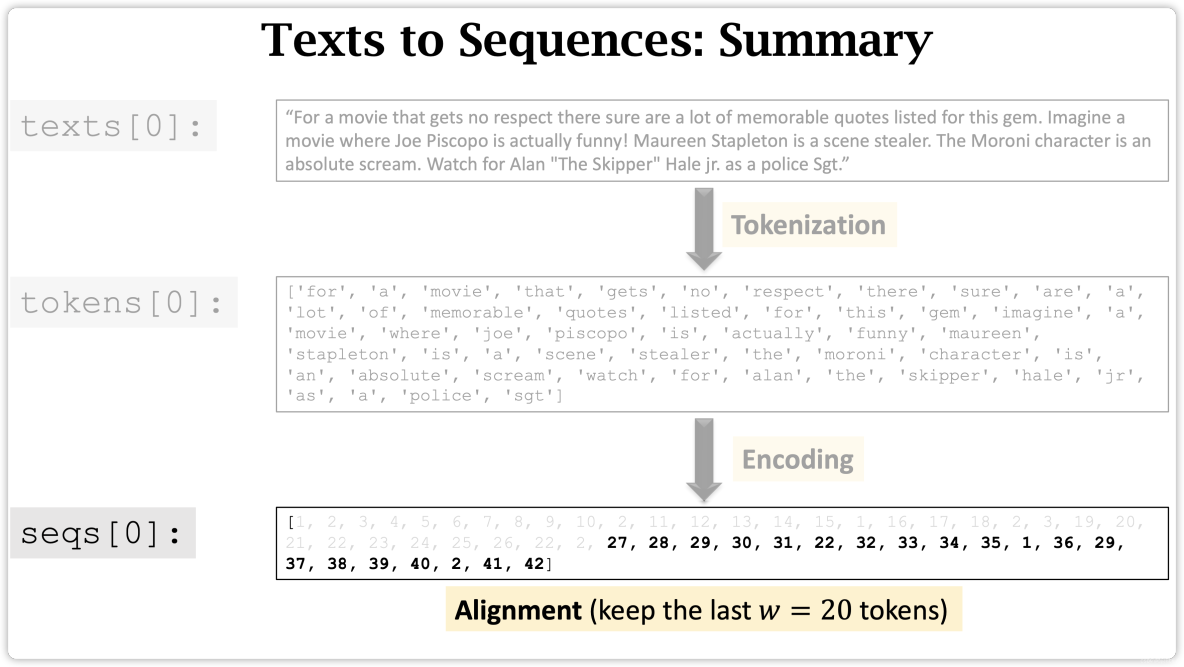
- Step 4: Align Sequences
- Text Processing in Keras
- Word Embedding: Word to Vector
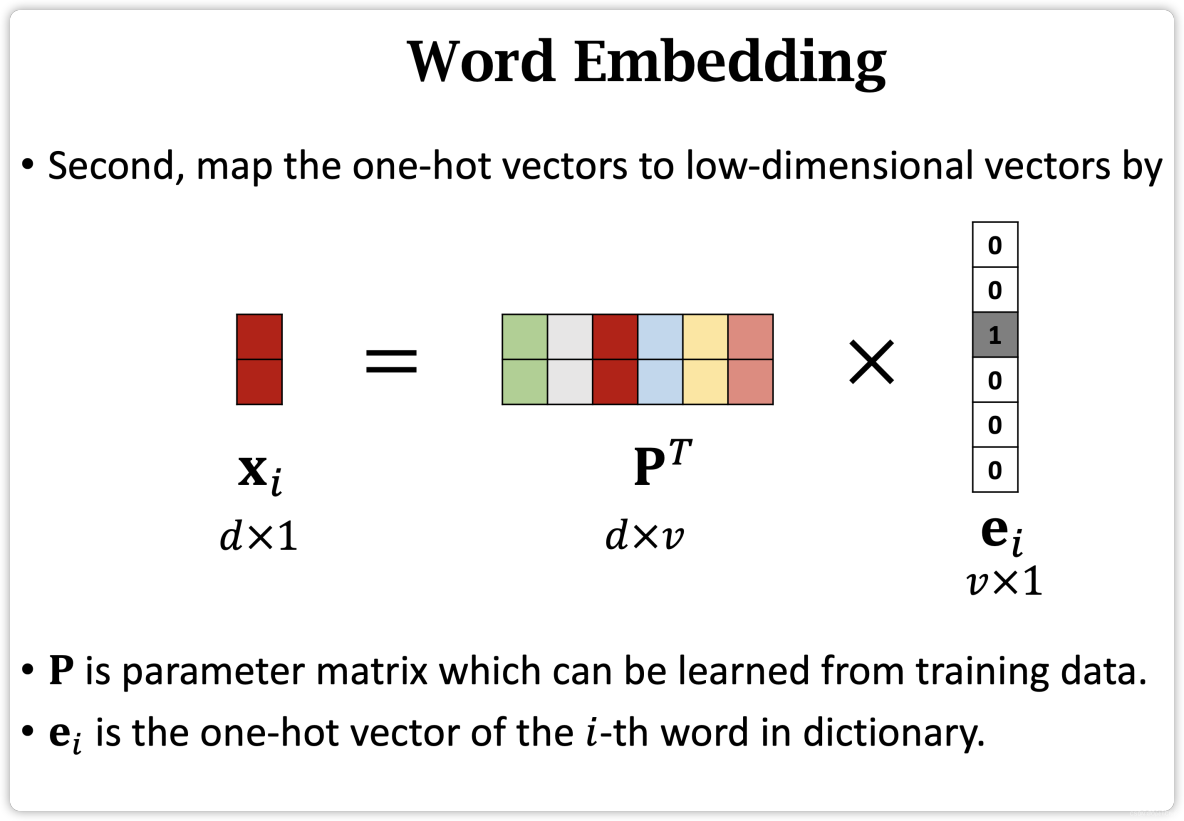
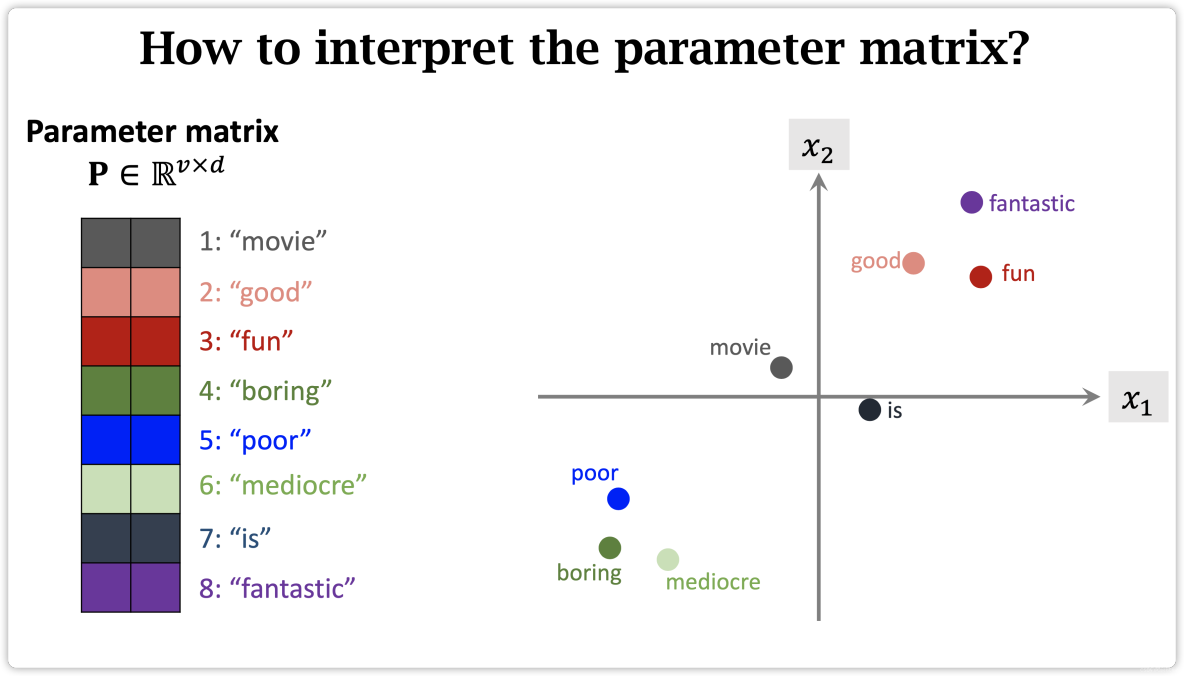
- How to map word to vector?
- One-Hot Encoding
- Logistic Regression for Binary Classification
- Summary
- 文本处理以及word embedding(词嵌入)算法原理讲解和代码详细实现(gpt-4)
- 一、文本处理
- 二、词嵌入
- 三、代码实现
- 文本处理以及word embedding(词嵌入)算法原理讲解和代码详细实现(gpt-4 Turbo)
- 文本处理
- 词嵌入(Word Embedding)
- Word2Vec
- GloVe
- FastText
- 代码实现
- 文本处理
- Word2Vec词嵌入
- 文本处理以及word embedding(词嵌入)算法原理讲解和代码详细实现(gpt-4-32k)
- 一、文本处理
- 1. 分词(Tokenization)
- 2. 去除停用词(Removing Stopwords)
- 3. 词干提取(Stemming)
- 4. 词形还原(Lemmatization)
- 5. 词袋模型(Bag of Words)
- 6. TF-IDF(Term Frequency-Inverse Document Frequency)
- 二、词嵌入(Word Embedding)
- 1. Word2Vec
- 2. GloVe(Global Vectors for Word Representation)
- 总结
【AI 实战】Text Processing and Word Embedding 文本处理以及词嵌入原理和代码实例讲解
Text to Sequence
Step 1: Tokenization

Step 2: Build Dictionary

Step 3: One-Hot Encoding
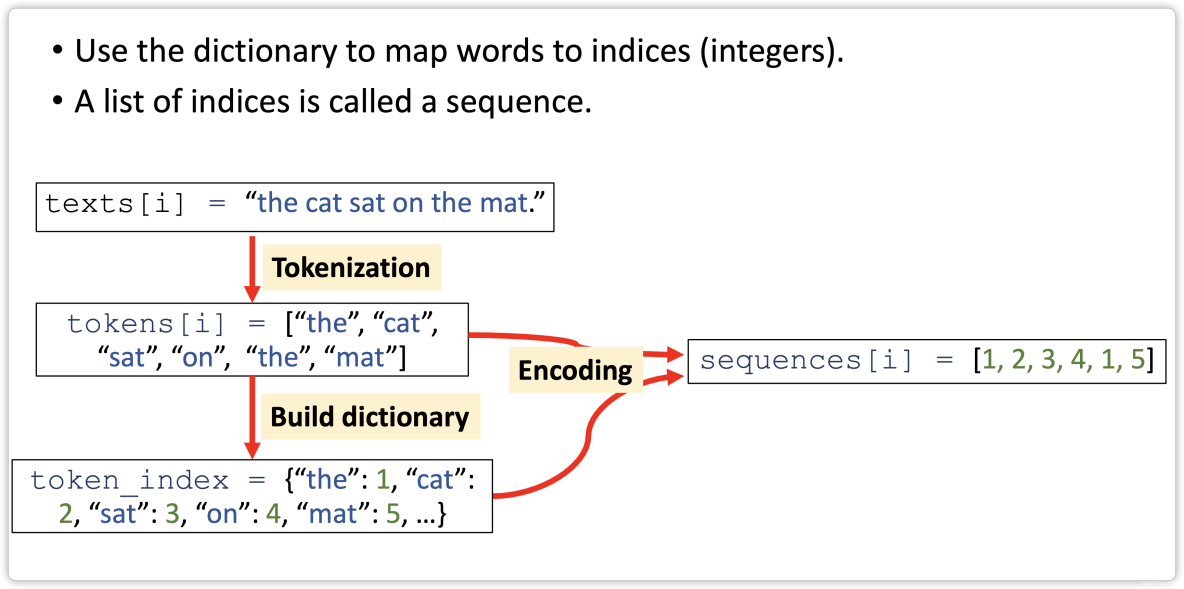


Step 4: Align Sequences

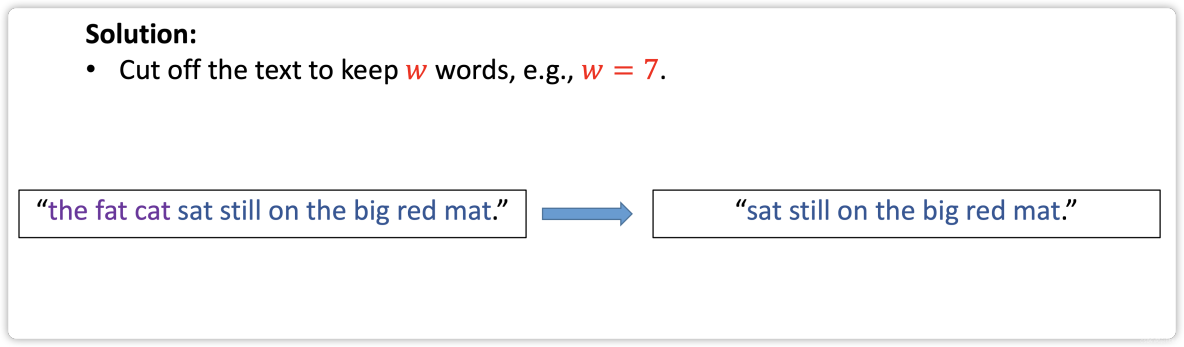
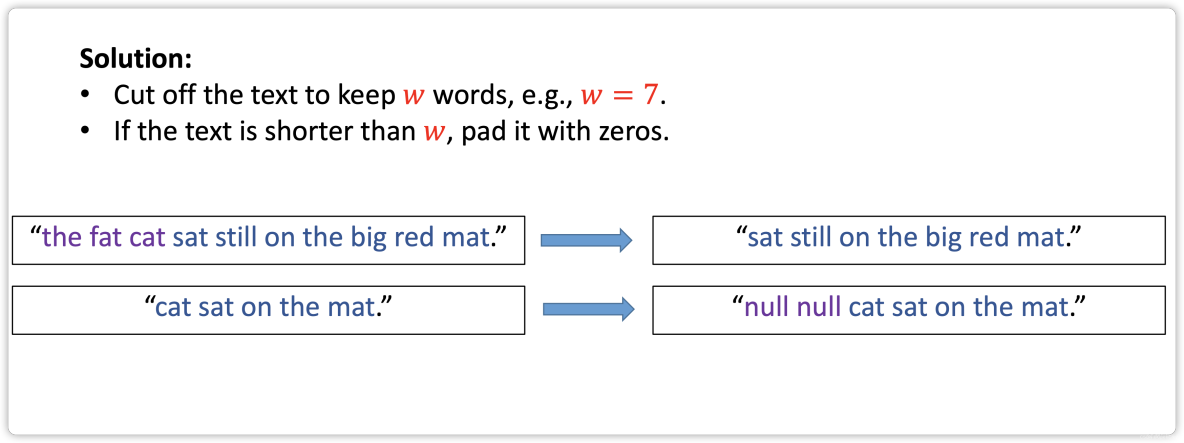
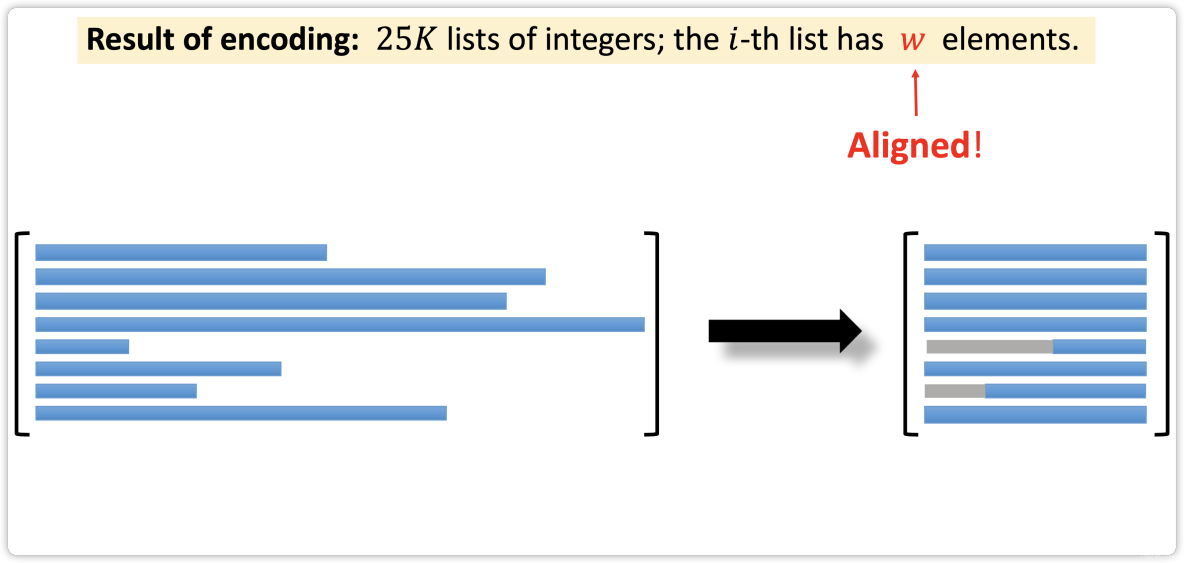
Text Processing in Keras





Word Embedding: Word to Vector
How to map word to vector?
One-Hot Encoding
https://www.youtube.com/watch?v=6_2_2CPB97s
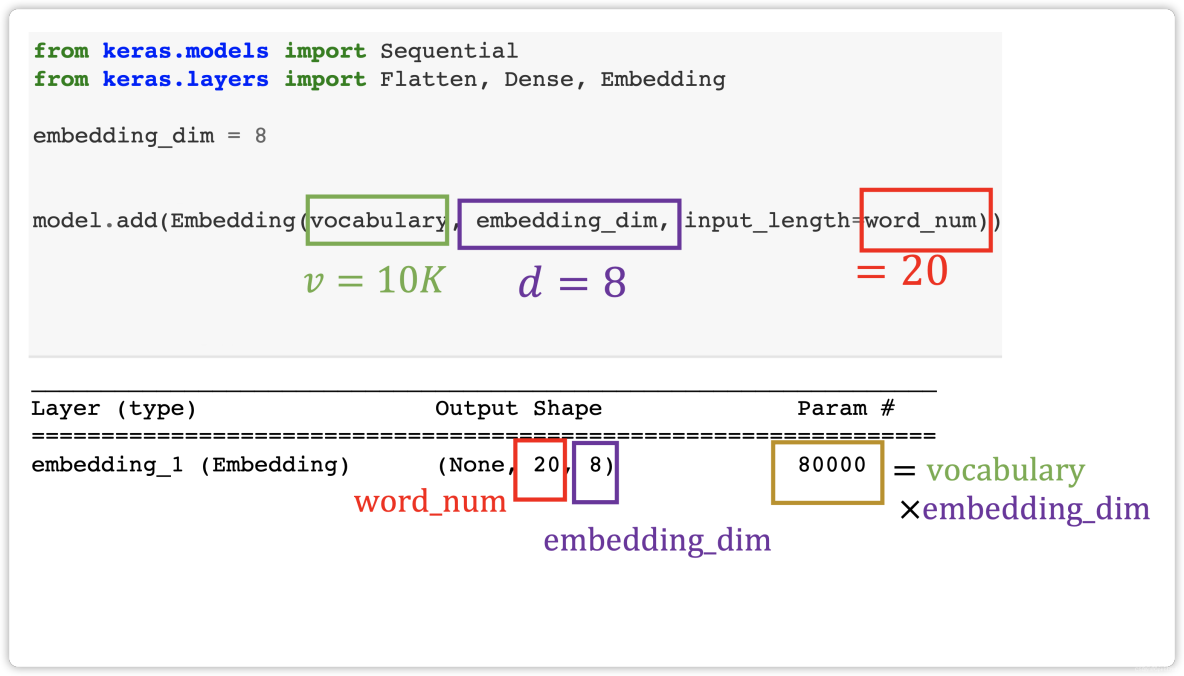
Logistic Regression for Binary Classification
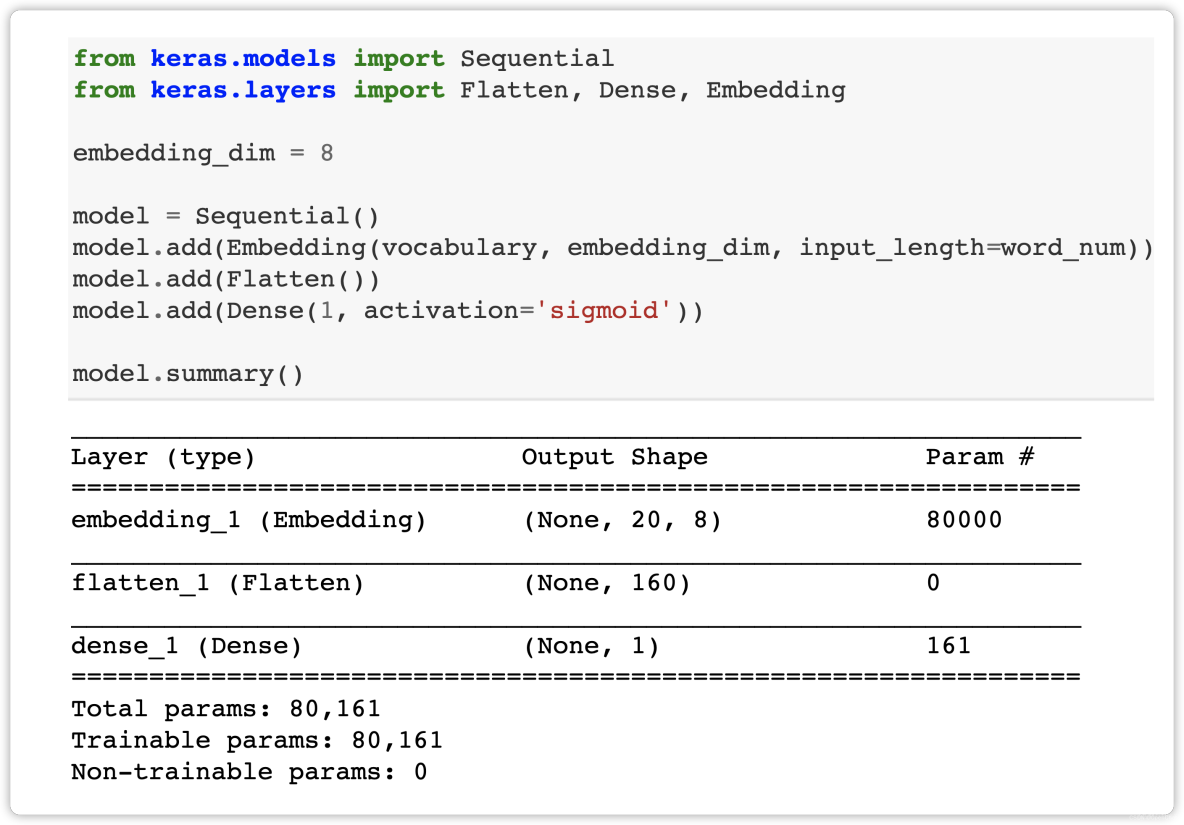

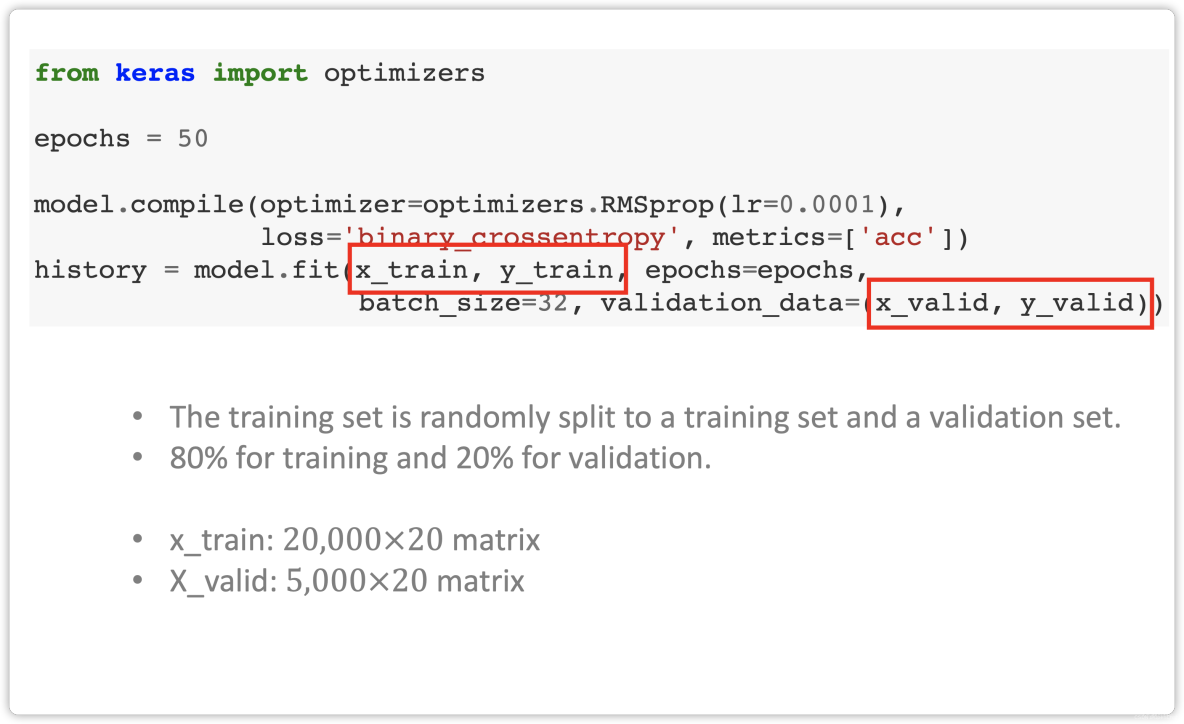

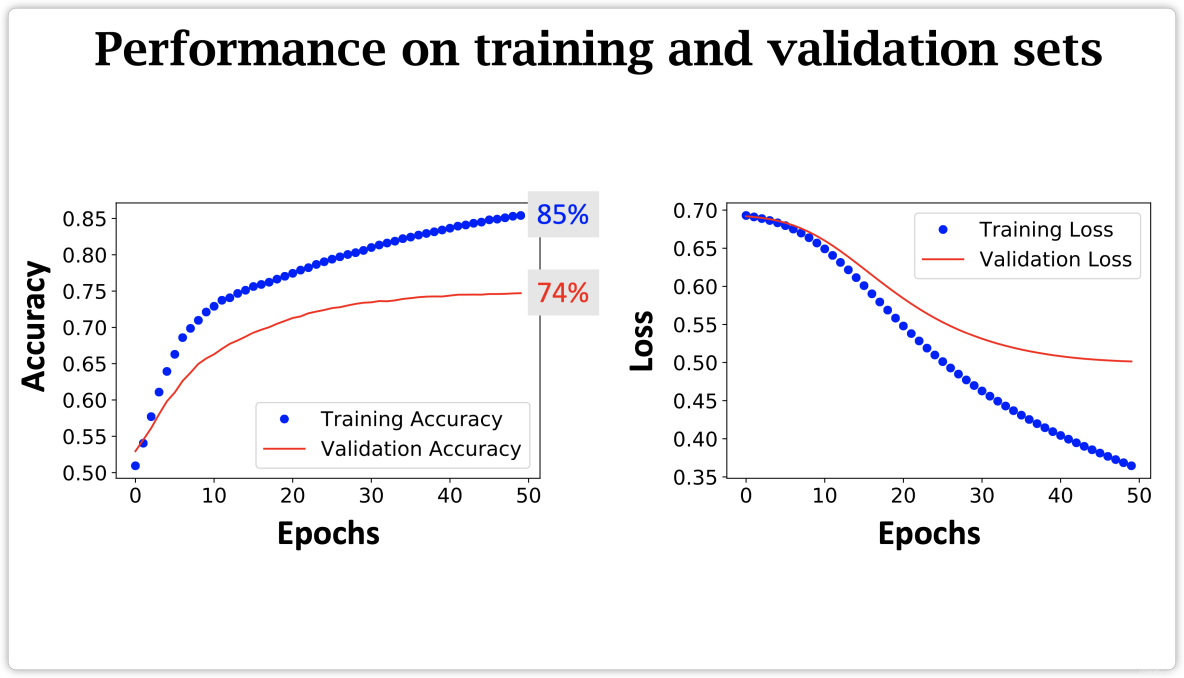

Summary



文本处理以及word embedding(词嵌入)算法原理讲解和代码详细实现(gpt-4)
一、文本处理
文本处理是自然语言处理(NLP)的一个重要部分,它涉及到将文本数据转化为可以被机器学习算法理解的格式。这个过程通常包括以下步骤:
- 文本清洗:这是文本处理的第一步,主要是去除文本中的噪声,如特殊字符、数字、标点符号等。
- 分词:将文本分解为单词或者词组。这是一个重要的步骤,因为机器学习算法通常处理的是单词级别的数据。
- 停用词移除:停用词是指在文本中频繁出现但对文本含义贡献不大的词,如“的”、“是”、“和”等。移除这些词可以减少数据的噪声。
- 词干提取和词形还原:这两个步骤都是为了将词汇简化为其基本形式。词干提取是去除词尾,而词形还原则是将词汇还原为其词典形式。
- 特征提取:将文本转化为可以被机器学习算法理解的特征。常见的方法有词袋模型(BoW)、TF-IDF等。
二、词嵌入
词嵌入是一种表示词汇的方法,它可以捕捉词汇的语义信息。词嵌入将每个词表示为一个高维空间中的向量,语义相近的词在空间中的距离也相近。
常见的词嵌入算法有Word2Vec、GloVe和FastText。
- Word2Vec:Word2Vec是一种预训练词嵌入模型,它有两种训练方式,CBOW(Continuous Bag of Words)和Skip-gram。CBOW是通过上下文预测当前词,而Skip-gram则是通过当前词预测上下文。
- GloVe:GloVe(Global Vectors for Word Representation)是另一种预训练词嵌入模型,它通过对词-词共现矩阵进行分解,得到词的向量表示。
- FastText:FastText是一种改进的Word2Vec模型,它不仅考虑了词的顺序,还考虑了词内部的字符信息。
三、代码实现
以下是使用Python和gensim库实现Word2Vec的示例代码:
from gensim.models import Word2Vec
sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
model = Word2Vec(sentences, min_count=1)
print(model['cat'])以下是使用Python和gensim库实现FastText的示例代码:
from gensim.models import FastText
sentences = [["cat", "say", "meow"], ["dog", "say", "woof"]]
model = FastText(sentences, min_count=1)
print(model['cat'])以上只是简单的示例,实际使用时,需要对文本进行预处理,如分词、去除停用词等。此外,模型的参数(如向量的维度、窗口大小等)也需要根据具体任务进行调整。
总结,文本处理和词嵌入是自然语言处理的重要步骤,它们可以将文本数据转化为机器学习算法可以理解的格式,从而进行后续的任务,如文本分类、情感分析等。
文本处理以及word embedding(词嵌入)算法原理讲解和代码详细实现(gpt-4 Turbo)
文本处理和词嵌入是自然语言处理(NLP)中的两个基础且重要的概念。文本处理通常涉及将原始文本数据转换为可以被机器学习模型处理的格式,而词嵌入则是将文本中的词汇映射到向量空间中的一种技术。
文本处理
文本处理的目的是将非结构化的文本数据转换为结构化的形式,以便于机器学习算法可以理解和处理。文本处理的步骤通常包括:
- 文本清洗:去除文本中的无关字符,如HTML标签、特殊符号等。
- 分词(Tokenization):将文本分割成单词或短语的过程。
- 去除停用词:停用词是指在文本中频繁出现但对于理解文本含义贡献不大的词,如“的”、“和”、“是”等。
- 词干提取(Stemming)/词形还原(Lemmatization):将词汇还原到基本形式,以减少词汇的多样性。
- 词性标注(Part-of-Speech Tagging):为每个单词标注词性,如名词、动词等。
- 向量化:将文本转换为数值形式,常见的方法有词袋模型(Bag of Words)、TF-IDF等。
词嵌入(Word Embedding)
词嵌入是一种表示文本中单词的方法,它可以捕捉单词之间的语义关系。词嵌入通常是通过训练一个神经网络模型来学习单词的向量表示。常见的词嵌入模型包括Word2Vec、GloVe和FastText。
Word2Vec
Word2Vec是一种流行的词嵌入方法,由Mikolov等人于2013年提出。它有两种结构:连续词袋模型(CBOW)和跳字模型(Skip-gram)。CBOW通过上下文来预测当前词,而Skip-gram则通过当前词来预测上下文。
GloVe
GloVe(Global Vectors for Word Representation)是另一种词嵌入方法,由Pennington等人于2014年提出。它结合了词袋模型的全局统计信息和Word2Vec的局部上下文特征。
FastText
FastText由Facebook的研究团队开发,它在Word2Vec的基础上进行了改进,可以考虑词内的子词信息,从而更好地处理罕见词或新词。
代码实现
以下是使用Python进行文本处理和Word2Vec词嵌入的简单示例。
文本处理
import re
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize
from nltk.stem import WordNetLemmatizer
# 初始化
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet服务器托管网')
# 示例文本
text = "The quick brown fox jumps over the lazy dog."
# 文本清洗
cleaned_text = re.sub(r'W', ' ', text) # 去除非字母字符
# 分词
tokens = word_tokenize(cleaned_text.lower()) # 转换为小写并分词
# 去除停用词
stop_words = set(stopwords.words('english'))
filtered_tokens = [w for w in tokens if not w in stop_words]
# 词形还原
lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(w) for w in filtered_tokens]
print(lemmatized_tokens)Word2Vec词嵌入
from gensim.models import Word2Vec
# 假设我们已经有了经过预处理的文本数据
sentences = [['the', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog'],
['the', 'dog', 'sleeps', 'in', 'the', 'kennel']]
# 训练Word2Vec模型
model = Word2Vec(sentences, vector_size=100, window=5, min_count=1, workers=4)
# 获取单词的向量
vector = model.wv['fox']
# 找到最相似的单词
similar_words = model.wv.most_similar('fox')
print(vector)
print(similar_words)在这个简单的例子中,我们首先对文本进行了清洗、分词、去除停用词和词形还原。然后,我们使用Gensim库中的Word2Vec模型对处理后的文本进行了词嵌入的训练,并获取了单词“fox”的向量表示以及与“fox”最相似的单词。
这些代码只是文本处理和词嵌入的一个简单示例。在实际应用中,文本处理和词嵌入的过程可能会更加复杂,需要根据具体任务和数据集进行调整。此外,还有许多其他的词嵌入技术和模型,如BERT、ELMo等,它们在处理复杂的语义关系和上下文信息方面更加强大。
文本处理以及word embedding(词嵌入)算法原理讲解和代码详细实现(gpt-4-32k)
文本处理和词嵌入算法原理讲解及代码详细实现
在自然语言处理(NLP)领域,文本处理和词嵌入是两个非常重要的概念。文本处理是将原始文本转换为计算机可以理解的格式的过程,而词嵌入是将词语表示为实数向量的方法。本文将详细介绍文本处理和词嵌入的原理,并提供相关代码实现。
一、文本处理
文本处理主要包括以下几个步骤:
1. 分词(Tokenization)
2. 去除停用词(Removing Stopwords)
3. 词干提取(Stemming)
4. 词形还原(Lemmatization)
5. 词袋模型(Bag of Words)
6. TF-IDF(Term Frequency-Inverse Document Frequency)1. 分词(Tokenization)
分词是将文本拆分为单词或符号的过程。这是文本处理的第一步,可以使用空格、标点符号等作为分隔符。
Python 代码实现:
import nltk
text = "This is an example sentence for tokenization."
tokens = nltk.word_tokenize(text)
print(tokens)2. 去除停用词(Removing Stopwords)
停用词是指在文本中频繁出现但对文本分析贡献不大的词,如“a”,“an”,“the”等。去除停用词可以减少数据噪声,提高分析效果。
Python 代码实现:
from nltk.corpus import stopwords
stop_words = set(stopwords.words("english"))
filtered_tokens = [token for token in tokens if token.lower() not in stop_words]
print(filtered_tokens)3. 词干提取(Stemming)
词干提取是将词语还原为其词干(词根)的过程。例如,“running”和“runner”的词干都是“run”。词干提取有助于减少词汇量,提高分析效果。
Python 代码实现:
from nltk.stem import PorterStemmer
stemmer = PorterStemmer()
stemmed_tokens = [stemmer.stem(token) for token in filtered_tokens]
print(stemmed_tokens)4. 词形还原(Lemmatization)
词形还原是将词语还原为其基本形式(词元)的过程。与词干提取相比,词形还原更注重词语的语义。例如,“better”的词元是“good”。
Python 代码实现:
from nltk.stem import WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
lemmatized_tokens = [lemmatizer.lemmatize(token) for token in filtered_tokens]
print(lemmatized_tokens)5. 词袋模型(Bag of Words)
词袋模型是一种将文本表示为词频向量的方法。向量的每个元素表示一个特定词在文本中出现的次数。
Python 代码实现:
from sklearn.feature_extraction.text import CountVectorizer
corpus = ["This is the first document.", "This is the second document."]
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.toarray())6. TF-IDF(Term Frequency-Inverse Document Frequency)
TF-IDF 是一种衡量词语在文档中的重要性的方法。它是词频(TF)和逆文档频率(IDF)的乘积。词频表示词语在文档中出现的次数,逆文档频率表示包含词语的文档数量的倒数。
Python 代码实现:
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = ["This is the first document.", "This is the second document."]
vectorizer = TfidfVectorizer()
X = ve服务器托管网ctorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.toarray())二、词嵌入(Word Embedding)
词嵌入是一种将词语表示为实数向量的方法。与词袋模型和 TF-IDF 相比,词嵌入可以捕捉词语之间的语义关系。常见的词嵌入算法有 Word2Vec 和 GloVe。
1. Word2Vec
Word2Vec 是一种基于神经网络的词嵌入算法。它有两种变体:CBOW(Continuous Bag of Words)和 Skip-gram。CBOW 通过上下文词预测目标词,而 Skip-gram 则通过目标词预测上下文词。
Python 代码实现(使用 Gensim 库):
import gensim.downloader as api
corpus = api.load("text8")
model = gensim.models.Word2Vec(corpus)
vector = model.wv["king"]2. GloVe(Global Vectors for Word Representation)
GloVe 是一种基于全局词频统计的词嵌入算法。它通过最小化词对的共现概率之间的差异来学习词向量。
Python 代码实现(使用 Gensim 库):
import gensim.downloader as api
corpus = api.load("text8")
model = gensim.models.glove2word2vec(corpus)
vector = model.wv["king"]总结
本文详细介绍了文本处理和词嵌入的原理,并提供了相关代码实现。文本处理是将原始文本转换为计算机可以理解的格式的过程,包括分词、去除停用词、词干提取、词形还原、词袋模型和 TF-IDF 等步骤。词嵌入是将词语表示为实数向量的方法,常见的词嵌入算法有 Word2Vec 和 GloVe。这些方法在自然语言处理任务中具有广泛的应用,如文本分类、情感分析、机器翻译等。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
