
问题
FATE框架1.x支持GPU训练吗?
寻找
先看了官网,搜官网,发现还是有的。 打开第一个后,里面可以用training param指定各个client的训练GPU,但是好像都是在large language model的。
打开第一个后,里面可以用training param指定各个client的训练GPU,但是好像都是在large language model的。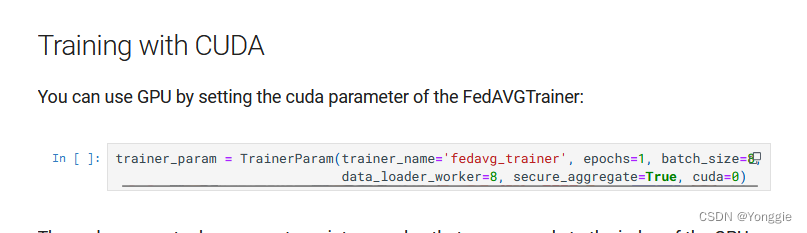 而在文档中搜寻到的gpu,其实是release的版本说明,里面搜来搜去,也是只有跟LLM相关的。莫非是一开始就支持GPU?我希望找到具体什么地方验证了FATE支持/不支持GPU
而在文档中搜寻到的gpu,其实是release的版本说明,里面搜来搜去,也是只有跟LLM相关的。莫非是一开始就支持GPU?我希望找到具体什么地方验证了FATE支持/不支持GPU
在官方群里提问后,群友提供了一个文档,说横向的联邦是支持GPU的,并且给了example:https://github.com/FederatedAI/FATE/blob/master/doc/tutorial/pipeline/nn_tutorial/README.md,简单把所有example搜了下gpu这个关键字,没有说明。。
淦,那就先探索一下这个trainer param吧,搜索文档后,只有简单的几行代码,这能看出来个毛。
def __init__(self, trainer_name=None, **kwargs):
super(TrainerParam, self).__init__()
self.trainer_name = trainer_name
self.param = kwargs结果在他源码https://github.com/FederatedAI/FATE/blob/master/python/federatedml/param/homo_nn_param.py里面,还真就只有这么些代码
class TrainerParam(BaseParam):
def __init__(self, trainer_name=None, **kwargs):
super(TrainerParam, self).__init__()
self.trainer_name = trainer_name
self.param = kwargs
def check(self):
if self.trainer_name is not None:
self.check_string(self.trainer_name, 'trainer_name')
def to_dict(self):
ret = {'trainer_name': self.trainer_name, 'param': self.param}
return ret可是他在调用的时候是写了这么多的。他既没有告诉我有什么kwargs,也没告诉我每个kwargs是什么作用,会有什么结果。感觉文档的提升空间还是有的。。好不方便啊。不但没明说GPU的支持与否,参数的具体意义和选项也没有给全(或者说给个全参数指引链接也好呀)。
trainer_param = TrainerParam(trainer_name='fedavg_trainer', epochs=1, batch_size=8,
data_loader_worker=8, secure_aggregate=True, cuda=0)解决
我是在/federatedml/param/homo_nn_param.py下找到的这个trainer param类,所以他大概率只能支持homo nn的场景。
使用的方法,根据文档,应该是通过trainer param类,把param给传入然后带动训练过程。
例子可以参考这个里面的例子,homo nn场景应该每个例子都会有trainer_param类,加入cuda=0这个参数应该就可以使用GPU了。
后续真实场景我会再测试
- 此参数 是否真是有效,通过查看GPU使用
- hetero场景能否使用GPU
到时再来更新。
更新:
确实有效。但是要注意有些函数的cuda参数是true或者false,而有些函数的参数是cuda的下标,一定要看好参数类型填参。
hetero场景是否能用?在1.11版本以及以前,是不能用GPU的。不知道2.x之后能不能有支持。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 来 GOTC 2023,从不同的角度谈开源及开源人才培养!
开源的发展离不开开源人才。中国的开源人才培养的发展潜力巨大。在最近的 Linux 基金会的开源工作岗位报告中,鉴于各行业持续采用云计算和进行数字化转型,对开源人才的需求非常强烈。开源生态中的企事业单位、高校、研究机构、甚至是培训机构均应视为己任,积极投身于此。…
