
1 基本概念

Hoodie 的所有操作都是基于文件的读写,整个文件组织可以分为两类:
- 数据文件:parquet(列存)和 arvo(行存)格式,COW(Copy On Write)表的话每次写的时候做合并,只存在 parquet,MOR(Merge On Read)则会有 base file(parquet)和增量 log file(arvo),本文里我们主要聊的是 MOR:

- 时间轴文件:根据时间线(instant time)记录对应的操作(compaction、delta commit 等)以及该操作当前处于的状态(REQUESTED、INFLIGHT、COMPLETED),文件里会记录该次操作关联的数据文件。
- Partition Path + File Id 定位一个 File Group => File Group Id = Partition Path + File IdFile Group + Base Instant Time 定位一个 File Slice.
2 Flink+Hudi 执行流程
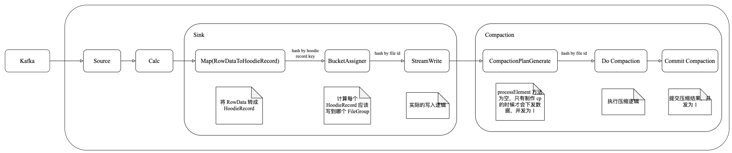
Hudi 在 HUDI-4397 中将 Rebalance 优化为 Hash 以避免压缩的时候出现并发冲突。
3 HoodieTableFactoryKeyGeneratorOptionsFlinkOptions
3.1 配置 Options
基于表定义设置配置,比如:
- 设置 hoodie record key 的获取策略(即怎么从 record 里拿到 hoodie record key);
- 设置 compaction 相关的配置;
- 设置 hive 相关的配置;
- 设置读相关的配置;
- 设置写相关的配置;
- 设置 source avro schema 的配置;
- 设置 hoodie record key 和 partition key 相关的配置;
- ……
最优先的是主键,如果 table 设置了主键,则以主键作为 FlinkOptions.RECORD_KEY_FIELD 的值:
if (pkColumns.size() > 0) {
// the PRIMARY KEY syntax always has higher priority than option FlinkOptions#RECORD_KEY_FIELD
String recordKey = String.join(",", pkColumns);
conf.setString(FlinkOptions.RECORD_KEY_FIELD, recordKey);
}Partitioned By 语法指定的 partition key 优先于 table properties:
if (partitionKeys.size() > 0) {
// the PARTITIONED BY syntax always has higher priority than option FlinkOptions#PARTITION_PATH_FIELD
conf.setString(FlinkOptions.PARTITION_PATH_FIELD, String.join(",", partitionKeys));
}如果只有一个 partition key 或没 partition key:
if (partitions.length == 1) {
final String partitionField = partitions[0];
// 没分区键,则设置 NonpartitionedAvroKeyGenerator 作为 FlinkOptions.KEYGEN_CLASS_NAME:
if (partitionField.isEmpty()) {
conf.setString(FlinkOptions.KEYGEN_CLASS_NAME, NonpartitionedAvroKeyGenerator.class.getName());
LOG.info("Table option [{}] is reset to {} because this is a non-partitioned table",
FlinkOptions.KEYGEN_CLASS_NAME.key(), NonpartitionedAvroKeyGenerator.class.getName());
return;
}
// 获取分区字段
DataType partitionFieldType = table.getSchema().getFieldDataType(partitionField)
.orElseThrow(() -> new HoodieValidationException("Field " + partitionField + " does not exist"));
// 检查分区字段 类型以及主键是否是联合主键,如果主键是某个字段且分区字段是日期类型,则设置 FlinkOptions.KEYGEN_CLASS_NAME 的值为时间相关
if (pks.length 如果分区字段个数大于一个或主键包含字段大于一个(且 FlinkOptions.KEYGEN_CLASS_NAME 尚未被配置过),则设置 ComplexAvroKeyGenerator 作为 FlinkOptions.KEYGEN_CLASS_NAME 的配置值。
4 HoodieTableSinkHoodieRecord
大体结构如下: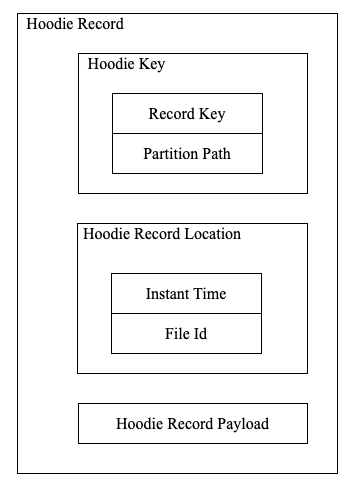
4.1 RowDataToHoodieFunction
public void open(Configuration parameters) throws Exception {
super.open(parameters);
this.avroSchema = StreamerUtil.getSourceSchema(this.config);
// 根据 rowType 递归创建 converter, 即 RowDataToAvroConverter
this.converter = RowDataToAvroConverters.createConverter(this.rowType);
// 创建 ComplexAvroKeyGenerator
this.keyGenerator =
HoodieAvroKeyGeneratorFactory
.createKeyGenerator(flinkConf2TypedProperties(this.config));
this.payloadCreation = PayloadCreation.instance(config);
}RowDataToAvroConverter
将 Flink SQL 的 RowData 转为 Hudi Record(Arvo 格式)。
ComplexAvroKeyGenerator
核心方法是 getKey,getRecordKeyFieldNames 从 TypedProperties 获取 hoodie.datasource.write.recordkey.field(即 FlinkOptions.RECORD_KEY_FIELD)对应的值。
return KeyGenUtils.getRecordKey(record, getRecordKeyFieldNames(), isConsistentLogicalTimestampEnabled());因此可知,有主键情况下,Hoodie Record 的 key 即数据主键,或无主键情况下,用户在 DDL With 里设置的 hoodie.datasource.write.recordkey.field。
4.2 BucketAssignFunction
计算每个 HoodieRecord 该写到哪个 File Group 里,即该 HoodieRecord 对应的 HoodieRecordLocation,由于 PartitionPath 在之前已计算得到,因此只需计算该 HoodieRecord 在确定的 PartitionPath 下会分到哪个 FileGroup,在计算过程中,Hoodie 将每个 FileGroup 抽象成一个 Bucket,因此这里也可以说是一个分桶的过程。
4.2.1 处理流程
这里的基本思路如下: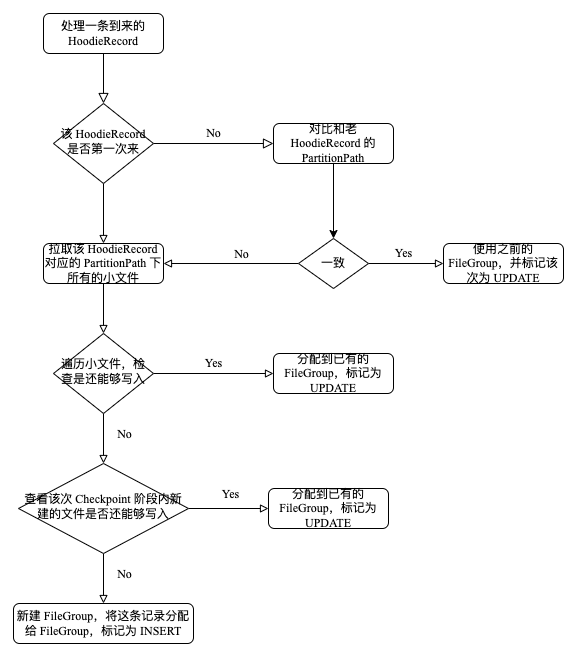
- 如果这条 HoodieRecord 来过,从状态里拿出老记录,对比新老的 PartitionPath 有没有变化,如果 PartitionPath 没变化,那么直接定位到之前对应的 FileGroup;
- 如果 PartitionPath 发生了变化,那么要重新计算这条 HoodieRecord 对应的 FileGroup(即 File Id);
- 如果这条 HoodieRecord 第一次来,获取分区下的所有 BaseFile,筛选小于“小文件阈值”(org.apache.hudi.config.HoodieCompactionConfig#PARQUET_SMALL_FILE_LIMIT 指定,默认是 100 MB)的 BaseFile,根据 File Id 筛选哪些 FileGroup 属于当前 SubTask KeyGroup Range 的处理范围;
-
在第二步的基础上遍历获取到的 FileGroup 数组对 HoodieRecord 尝试进行分配(类似数组遍历),如果当前指向 FileGroup 还能够写入数据,那么就将 HoodieRecord 分配给该 FileGroup,否则就指向下一个 FileGroup:
public boolean assign() { if (noSpace) { return false; } SmallFileAssignState state = states[assignIdx]; while (!state.canAssign()) { assignIdx += 1; if (assignIdx >= states.length) { noSpace = true; return false; } // move to next slot if possible state = states[assignIdx]; } state.assign(); return true; }如果这些 FileGroup 都写满了,那么创建一个新的 File Id(org.apache.hudi.sink.partitioner.BucketAssigner#createFileIdOfThisTask),将这条 HoodieRecord 分配给新的 FileGroup。
4.2.2 核心结构
4.2.2.1 BuckerAssignFunction
- indexState:KeyedState,记录了当前该记录对应的分区信息(在此之前有过一次对于 hoodie record key 的 hash);
- isChangingRecords:标记改作业数据的写模式是追加写还是可更新,如果 isChangingRecords 是 false,代表该作业只支持追加写,那么直接标记该记录为 INSERT;
- bucketAssigner:BucketAssigner,专用于计算该条记录分哪个桶(FileGroup)。
4.2.2.2 BucketAssigner
- smallFileAssignMap:存储 PartitionPath 和已有的小文件集合的映射;
-
newFileAssignStates:存储 PartitionPath 和新创建的小文件的映射;bucketInfoMap:存储 BucketID(PartitionPath_FileId)和 BucketInfo(PartitionPath + File Id + Bucket Type)的映射。如果该 partition path 对应的小文件都已写到阈值,那就需要创建新的小文件。
public BucketInfo addInsert(String partitionPath) { // for new inserts, compute buckets depending on how many records we have for each partition SmallFileAssign smallFileAssign = getSmallFileAssign(partitionPath); // first try packing this into one of the smallFiles if (smallFileAssign != null && smallFileAssign.assign()) { return new BucketInfo(BucketType.UPDATE, smallFileAssign.getFileId(), partitionPath); } // if we have anything more, create new insert buckets, like normal if (newFileAssignStates.containsKey(partitionPath)) { NewFileAssignState newFileAssignState = newFileAssignStates.get(partitionPath); if (newFileAssignState.canAssign()) { newFileAssignState.assign(); final String key = StreamerUtil.generateBucketKey(partitionPath, newFileAssignState.fileId); if (bucketInfoMap.containsKey(key)) { // the newFileAssignStates is cleaned asynchronously when received the checkpoint success notification, // the records processed within the time range: // (start checkpoint, checkpoint success(and instant committed)) // should still be assigned to the small buckets of last checkpoint instead of new one. // the bucketInfoMap is cleaned when checkpoint starts. // A promotion: when the HoodieRecord can record whether it is an UPDATE or INSERT, // we can always return an UPDATE BucketInfo here, and there is no need to record the // UPDATE bucket through calling #addUpdate. return bucketInfoMap.get(key); } return new BucketInfo(BucketType.UPDATE, newFileAssignState.fileId, partitionPath); } } BucketInfo bucketInfo = new BucketInfo(BucketType.INSERT, createFileIdOfThisTask(), partitionPath); final String key = StreamerUtil.generateBucketKey(partitionPath, bucketInfo.getFileIdPrefix()); bucketInfoMap.put(key, bucketInfo); NewFileAssignState newFileAssignState = new NewFileAssignState(bucketInfo.getFileIdPrefix(), writeProfile.getRecordsPerBucket()); newFileAssignState.assign(); newFileAssignStates.put(partitionPath, newFileAssignState); return bucketInfo; }通过 BucketAssigner 计算该条数据对应的 BucketInfo 信息:
- 调用 getSmallFileAssign 获取指定分区的所有小文件,并根据并行度和最大并行度计算分给当前 subtask 的小文件集合(SmallFileAssign),这一块逻辑可以类比 Flink 对 Key 进行 Hash Shuffle;
- 调用 SmallFileAssign 检查这些小文件集合是否还能写入数据(这些小文件类似一个链式的结构(实际用数组存),从头到尾检查是否还有空间允许数据写入),如果能,则标记 bucketType 为 UPDATE,每个 bucket 对应一个 FileGroup;
- 查看 PartitionPath 对应的已创建的 newFileAssignStates 还能否写入数据,能的话返回对应 BucketInfo,不能的话创建新的小文件;
- 更新映射信息的 map。
5 StreamWriteFunction
5.1 Buffer 机制
在为这些数据分完桶后,会先按桶的 ID(BucketID)hash,再由不同的 subtask 进行写入。一条一条写对 HDFS 的网络请求和文件I/O都是负担,因此这里采用了 buffer 机制,以 Bucket 为单位写一次。
Hudi 为这个 Buffer 机制设计了两层:
- 每个 Bucket 可缓存的数据量(默认256 MB);
-
所有 Bucket 一共可缓存的数据量(默认 1G)。

每处理一条记录时,根据 BucketID 放到对应的桶里,并判断这个桶是否已装满数据,如果装满则写出并清空。
如果该桶没装满,计算所有桶的数据加起来是否超出设定阈值,如果超出,则把存数据量最大的桶写出并清空,否则就缓存该数据不做操作。计算 Bucket 是否装满数据是按数据的大小总量而非条数来预估的,这里调用了 jol-core (java object layout) 来计算对象的实际占用空间,但由于涉及到一些对操作系统的调用开销,因此没有对每条 HoodieRecord 都进行严格计算,而是通过采样的方式预估该条数据大小:创建一个 [0,99] 的随机数,当这个随机数等于 1 的时候计算一次当前 HoodieRecord 的大小,直到下一次随机数等于 1 之前,都使用这个值作为后面 HoodieRecord 大小的预估值。经调研,jol-core 和 Oracle JDK8 存在不兼容的情况,
5.2 HoodieFlinkWriteClient
每个 checkpoint 可以对应为一次 delta commit 或 compaction,因此每次写数据之前需要读取 .aux/ckp_metadata 目录下的 checkpoint 元数据,以获取该次 delta commit 的 instant time(与 base instant time 不同)。
拿到 instant time 后,Hudi 会对相同 Hoodie Record Key 的数据进行预合并(precombine),之后 HoodieFlinkWriteClient 创建了 FlinkAppendHandle,FlinkAppendHandle 封装了对一个 FileGroup 的所有 I/O 操作,并保存了要写的 records 的迭代器,然后调用 BaseFlinkCommitActionExecutor.execute(List
public HoodieWriteMetadata> execute(List> inputRecords) {
HoodieWriteMetadata> result = new HoodieWriteMetadata();
List writeStatuses = new LinkedList();
final HoodieRecord> record = inputRecords.get(0);
final String partitionPath = record.getPartitionPath();
final String fileId = record.getCurrentLocation().getFileId();
final BucketType bucketType = record.getCurrentLocation().getInstantTime().equals("I")
? BucketType.INSERT
: BucketType.UPDATE;
handleUpsertPartition(
instantTime,
partitionPath,
fileId,
bucketType,
inputRecords.iterator())
.forEachRemaining(writeStatuses::addAll);
setUpWriteMetadata(writeStatuses, result);
return result;
}
这里又使用了模板方法设计模式,handleUpsertPartition 里面根据 Bucket 标识,主要调用两个方法:handleInsert 和 handlerUpdate,最终逻辑由 BaseFlinkDeltaCommitActionExecutor 实现并执行。
5.2.1 Update
public Iterator> handleUpdate(String partitionPath, String fileId, Iterator> recordItr) {
FlinkAppendHandle appendHandle = (FlinkAppendHandle) writeHandle;
appendHandle.doAppend();
List writeStatuses = appendHandle.close();
return Collections.singletonList(writeStatuses).iterator();
}handleUpdate 的逻辑很简单,其实就是调用 FlinkAppendHandle 的 doAppend 方法:public void doAppend() {
while (recordItr.hasNext()) {
HoodieRecord record = recordItr.next();
init(record);
flushToDiskIfRequired(record, false);
writeToBuffer(record);
}
appendDataAndDeleteBlocks(header, true);
estimatedNumberOfBytesWritten += averageRecordSize * numberOfRecords;
}
遍历数据并对每条数据按如下步骤进行处理:
- 做一些初始化操作(只会执行一次):拉取最新的 FileSlice 信息,如果没有,则新建一个 FileSlice;初始化 writeStatus(写入结果的统计信息);HUDI-1517(创建一个 marker);初始化 HoodieLogFormatWriter:用于把数据写到 LogFile 中,因此创建时会指向一个具体的 LogFile,初始化时获取最新一个 LogFile。
-
检查缓冲区的数据量是否达到阈值,是的话刷到磁盘:将这一批数据组装为一个 HoodieLogBlock(具体实现为 HoodieAvroDataBlock);并把这些 block 刷到对应的 LogFile 中,这里调用 HoodieLogFormatWriter 的 appendBlocks 方法;这里就连上 hadoop 提供的文件读写 API,最终利用 FSDataOutputStream 按一定格式将数据落盘到 hdfs 中;如果数据落盘后超出 log 文件大小,那么更新其拥有的文件句柄(LogFile),即自增 log version;更新 writeStatus:
// org.apache.hudi.io.HoodieAppendHandle#updateWriteStatus private void updateWriteStatus(HoodieDeltaWriteStat stat, AppendResult result) { updateWriteStat(stat, result); updateWriteCounts(stat, result); updateRuntimeStats(stat); statuses.add(this.writeStatus); } - 将该条数据写入到缓冲区。遍历完数据后,缓冲区中可能仍存在数据,因此最后需要再刷一次盘,最后更新下 estimatedNumberOfBytesWritten(该次 append 阶段数据写入量的预估值,在写 MOR 场景下似乎不需要)。
5.2.2 Insert
与 update 不同的是,处理 Insert Bucket 的数据时采用了类似懒触发的模型,其实就是在原先数据的迭代器上包了一层 FlinkLazyInsertIterable,当调到其 computeNext(上面的 forEachRemaining 最终会调到这里)方法创建了 HoodieExecutor(Hudi 默认使用 SimpleExecutor),做了两件事:做了一次 transform,根据 ExecutorFactory 的类型,判断是使用原先数据的引用还是原先数据的拷贝;如果是 BOUNDED_IN_MEMORY 或 DISRUPTOR,那么将数据通过生产消费者模式进行异步处理,否则就普通的遍历处理(默认):
public E execute() {
try {
LOG.info("Starting consumer, consuming records from the records iterator directly");
while (itr.hasNext()) {
O payload = transformFunction.apply(itr.next());
consumer.consume(payload);
}
return consumer.finish();
} catch (Exception e) {
LOG.error("Failed consuming records", e);
throw new HoodieException(e);
}
}至于 doWrite 方法,可以看做 doAppend 的单次处理逻辑,最终在 consumer.finish() 时再确保将所有数据刷出落盘。
思考:为什么 Insert 和 Update 的数据处理逻辑会有不同?
6 Compaction
做 Compaction 的流程大体可以分为四步:
- 调度 compaction:主要的作用是生成一个base instant time,这个时间点就是下一个 file slice 的基准时间;
- 基于第一步调度的 compaction 生成 compaction 执行计划(每个 file group 1 个),发送给下游;
- 下游算子负责执行 compaction,将 base file 和 log file 进行合并生成一个新的 base file,并将 compaction 结果发送给下游;
- 当收到所有 file group 的 compaction 结果,如果都压缩成功了则提交 compaction 结果。
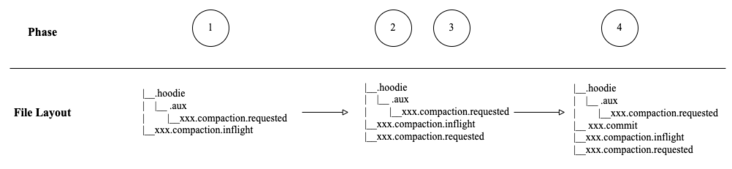
6.1 调度 Compaction
由 StreamWriteOperatorCoodinator 负责发起(notifyCheckpointComplete),需要满足两个条件:该表为 MOR;开启 compaction.schedule.enabled(默认为 true)。最终执行逻辑在方法 ScheduleCompactionActionExecutor#execute:
public Option execute() {
ValidationUtils.checkArgument(this.table.getMetaClient().getTableType() == HoodieTableType.MERGE_ON_READ,
"Can only compact table of type " + HoodieTableType.MERGE_ON_READ + " and not "
+ this.table.getMetaClient().getTableType().name());
if (!config.getWriteConcurrencyMode().supportsOptimisticConcurrencyControl()
&& !config.getFailedWritesCleanPolicy().isLazy()) {
// TODO(yihua): this validation is removed for Java client used by kafka-connect. Need to revisit this.
if (config.getEngineType() == EngineType.SPARK) {
// if there are inflight writes, their instantTime must not be less than that of compaction instant time
table.getActiveTimeline().getCommitsTimeline().filterPendingExcludingMajorAndMinorCompaction().firstInstant()
.ifPresent(earliestInflight -> ValidationUtils.checkArgument(
HoodieTimeline.compareTimestamps(earliestInflight.getTimestamp(), HoodieTimeline.GREATER_THAN, instantTime),
"Earliest write inflight instant time must be later than compaction time. Earliest :" + earliestInflight
+ ", Compaction scheduled at " + instantTime));
}
// Committed and pending compaction instants should have strictly lower timestamps
List conflictingInstants = table.getActiveTimeline()
.getWriteTimeline().filterCompletedAndCompactionInstants().getInstantsAsStream()
.filter(instant -> HoodieTimeline.compareTimestamps(
instant.getTimestamp(), HoodieTimeline.GREATER_THAN_OR_EQUALS, instantTime))
.collect(Collectors.toList());
ValidationUtils.checkArgument(conflictingInstants.isEmpty(),
"Following instants have timestamps >= compactionInstant (" + instantTime + ") Instants :"
+ conflictingInstants);
}
HoodieCompactionPlan plan = scheduleCompaction();
Option option = Option.empty();
if (plan != null && nonEmpty(plan.getOperations())) {
extraMetadata.ifPresent(plan::setExtraMetadata);
try {
if (operationType.equals(WriteOperationType.COMPACT)) {
HoodieInstant compactionInstant = new HoodieInstant(HoodieInstant.State.REQUESTED,
HoodieTimeline.COMPACTION_ACTION, instantTime);
table.getActiveTimeline().saveToCompactionRequested(compactionInstant,
TimelineMetadataUtils.serializeCompactionPlan(plan));
} else {
HoodieInstant logCompactionInstant = new HoodieInstant(HoodieInstant.State.REQUESTED,
HoodieTimeline.LOG_COMPACTION_ACTION, instantTime);
table.getActiveTimeline().saveToLogCompactionRequested(logCompactionInstant,
TimelineMetadataUtils.serializeCompactionPlan(plan));
}
} catch (IOException ioe) {
throw new HoodieIOException("Exception scheduling compaction", ioe);
}
option = Option.of(plan);
}
return option;
} - 做一些校验,比如不能有比该 instant 比当前 compaction 更加新的已完成的 compaction;
- 根据预设的 compaction 策略判断当前是否该生成 compaction,如 delta commit 次数是否达到阈值;获取 table 的所有分区,并从每个分区下获取所有最新的 flie slice(每个 file group 有好几个 file slice,获取 instant time 最大的一个),为每个 file slice 生成一个 HoodieCompactionOperation,将这些 HoodieCompactionOperation 包装成一个 HoodieCompactionPlan;
-
将序列化后的结果分别记录到 .aux 目录和 .hoodie 目录下,文件名为
.compaction.requested。 // org.apache.hudi.common.table.timeline.HoodieActiveTimeline#saveToCompactionRequested(org.apache.hudi.common.table.timeline.HoodieInstant, org.apache.hudi.common.util.Option, boolean) public void saveToCompactionRequested(HoodieInstant instant, Option content, boolean overwrite) { ValidationUtils.checkArgument(instant.getAction().equals(HoodieTimeline.COMPACTION_ACTION)); // Write workload to auxiliary folder createFileInAuxiliaryFolder(instant, content); createFileInMetaPath(instant.getFileName(), content, overwrite); } 思考:.hoodie 目录和 .axu 目录都存有执行 compaction 需要的元数据,看起来是冗余的,为什么每次先写 .aux 再写 .hoodie?有两次文件 I/O 操作,似乎是一个多余的开销?
根据HUDI-546:We need to stop writing compaction plans in .aux folder as we have stopped doing renames in timeline folder. THis is not done in 0.5.1 to preserve backwards compatibility between 0.5.0 and 0.5.1 for readers and writers. The PR (linked above) provides support to handle the case when future writers stop writing compaction plan. Once, the PR is released, we need a follow-up step to stop reading and writing to .aux folder.
hudi 的老版本中 .hoodie 目录下的文件可能被重命名,因此额外使用了 .aux 存取 compaction 需要的元数据。
6.2 生成 Compaction Plan
org.apache.hudi.sink.compact.CompactionPlanOperator,生成 CompactionPlanEvent,发送给下游执行 Compaction:
- 从 Active Timeline 里找到最老的 REQUESTED 状态的 instant time(从 .hoodie 目录下读相应文件),这里是考虑到可能调度了多个 compaction 都尚未执行,那么先执行最早的 compaction;
-
根据 instant time 计算得到文件名,从 basePath/.aux 里读取相应文件(如果找不到对应文件,则再从 .hoodie 目录下读),并反序列化得到 HoodieCompactionPlan,里面包含一系列 HoodieCompactionOperation,每个 HoodieCompactionOperation 标识该压缩操作对应的 file slice 信息;目前代码已经做了兼容,如果 .aux 目录读不到,就从 .hoodie 目录读。
public OptionreadCompactionPlanAsBytes(HoodieInstant instant) { try { // Reading from auxiliary path first. In future release, we will cleanup compaction management // to only write to timeline and skip auxiliary and this code will be able to handle it. return readDataFromPath(new Path(metaClient.getMetaAuxiliaryPath(), instant.getFileName())); } catch (HoodieIOException e) { // This will be removed in future release. See HUDI-546 if (e.getIOException() instanceof FileNotFoundException) { return readDataFromPath(new Path(metaClient.getMetaPath(), instant.getFileName())); } else { throw e; } } } - 将该 compaction 的状态从 REQUESTED 更新为 INFLIGHT,即在 .hoodie 目录下创建
.compaction.inflight - List
经过转换得到 List ,将每个 CompactionOperation 包装成 CompactionPlanEvent 下发给下游算子(其实就是增加了 instant time 字段标识该次压缩时间)。
6.3 执行 Compaction
将 BaseFile 和 LogFiles 合并,并将压缩结果(CompactionCommitEvent)下发,这里的压缩结果里记录的是该操作的一些结果信息而非实际数据,比如数据写到了哪个分区的哪个 FileGroup,写了多少条数据等等。
6.4 提交 Compaction 结果
- 从 CompactionCommitEvent 读取到 InstantTime;
-
读取 InstantTime 对应的 Compaction 元数据,检查是否所有的 CompactionCommitEvent 到齐;
HoodieCompactionPlan compactionPlan = compactionPlanCache.computeIfAbsent(instant, k -> { try { return CompactionUtils.getCompactionPlan( this.writeClient.getHoodieTable().getMetaClient(), instant); } catch (Exception e) { throw new HoodieException(e); } }); boolean isReady = compactionPlan.getOperations().size() == events.size(); - 如果有任意一个 CompactionCommitEvent 标记失败,rollback 回滚;
-
将压缩结果写到元数据表里:
Writer implementation backed by an internal hudi table. Partition and file listing are saved within an internal MOR table called Metadata Table. This table is created by listing files and partitions (first time) and kept in sync using the instants on the main dataset.Hoodie 新版本用一个 MOR 表存储整个表的元数据信息(
_metadata)。
更新该次 compaction 从 INFLIGHT 到 COMPLETED,即在 .hoodie 下创建
.commit 文件,写入压缩结果。 提交过程并不会删除 .aux 目录下的文件
flink数据湖阅读 257本作品系原创,采用《署名-非商业性使用-禁止演绎 4.0 国际》许可协议
Mulavar
18 声望12 粉丝推荐阅读Flink 批作业的运行时自适应执行管控
摘要:本文整理自阿里云高级技术专家朱翥,在 FFA 核心技术专场的分享。本篇内容是关于在过去的一年中,Apache Flink 对运行时的作业执行管控进行的一些改进。这些改进,让 Flink 可以更好的利用运行时的信息,来…ApacheFlink赞 1阅读 634

中原银行对金融行业实时数仓的现状与发展趋势思考
近期举办的 2022 第四届实时计算 Flink 挑战赛中,在各位大佬的指导下,完成了本课题的设计和实践,现在把本方案的设计思路分享给大家,希望通过本次经验分享可以为其它企业带来一点实时数据使用的新思路。ApacheFlink阅读 1.1k
基于 Log 的通用增量 Checkpoint
摘要:本文整理自 Apache Flink Contributor 俞航翔 9 月 24 日在 Apache Flink Meetup 的演讲。主要内容包括:Checkpoint 性能优化之路解析 Changelog一览 State/Checkpoint 优化ApacheFlink阅读 956
Flink SQL 在米哈游的平台建设和应用实践
摘要:本文整理自米哈游大数据实时计算团队负责人张剑,在 FFA 行业案例专场的分享。本篇内容主要分为三个部分:发展历程平台建设未来展望点击查看直播回放 & 演讲PPT一、发展历程随着公司业务的发展,实时计算需…ApacheFlink赞 1阅读 271
基于 Flink 流计算实现的股票交易实时资产应用
本次赛题思路源自于真实工作场景的一个线上项目,该项目在经过一系列优化后已稳定上线,在该项目开发的过程中数据平台组和技术负责人提供了许多资源和指导意见,而项目的结果也让我意识到了流计算在实际生产中优…ApacheFlink赞 1阅读 263
Apache Flink 社区 2022 年度报告:Evolution, Diversity, Connection
2022 年悄然落幕,Apache Flink 社区又迎来了蓬勃发展的一年。社区共发布了 2 个 Flink 主版本,孵化出了新的流批一体表格存储项目,举办了 13 场线上线下活动,包括分别面向亚洲(北京)和欧美(旧金山)的 2 次…ApacheFlink阅读 778
Flink CEP 新特性进展与在实时风控场景的落地
摘要:本文整理自阿里云开发工程师耿飙&阿里云开发工程师胡俊涛,在 FFA 实时风控专场的分享。本篇内容主要分为四个部分:Flink CEP 介绍&新功能解读动态多规则支持与 DemoFlink CEP SQL 语法增强未来规划■ 分享…ApacheFlink赞 1阅读 336
Mulavar
18 声望12 粉丝宣传栏
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net

**粗体** _斜体_ [链接](http://example.com) `代码` - 列表 > 引用。你还可以使用@来通知其他用户。