
此笔记为尚硅谷MySQL高级篇部分内容
目录
一、数据库的存储结构:页
1、磁盘与内存交互基本单位:页
2、页结构概述
3、页的大小
4、页的上层结构
二、页的内部结构
1、分三个部分看
2、从数据页角度看B + 树如何查询
三、InnoDB行格式(或记录格式)
四、区、段与碎片区
1、为什么要有区?
2、为什么要有段?
3、为什么要有碎片区?
4、区的分类
五、表空间
1、独立表空间
2、系统表空间
一、数据库的存储结构:页
索引结构给我们提供了高效的索引方式,不过索引信息以及数据记录都是保存在文件上的,确切说是存储在页结构中。另一方面,索引是在存储引擎中实现的,MySQL服务器上的存储引擎负责对表中数据的读取和写入工作。不同存储引擎中存放的格式一般是不同的,甚至有的存储引擎比如Memory都不用磁盘来存储数据。
由于InnoDB是MySQL的默认存储引擎,所以本章剖析InnoDB存储引擎的数据存储结构。
1、磁盘与内存交互基本单位:页
InnoDB将数据划分为若干个页,InnoDB中页的大小默认为 16KB
以
页作为磁盘和内存之间交互的基本单位,也就是一次最少从磁盘中读取16KB的内容到内存中,一次最少把内存中的16KB内容刷新到磁盘中。也就是说,在数据库中,不论读一行,还是读多行,都是将这些行所在的页进行加载。也就是说,数据库管理存储空间的基本单位是页(Page),数据库I/O操作的最小单位是页。一个页中可以存储多个行记录
记录是按照行来存储的,但是数据库的读取并不以行为单位,否则一次读取(也就是一次I/O操作)只能处理一行数据,效率会非常低。
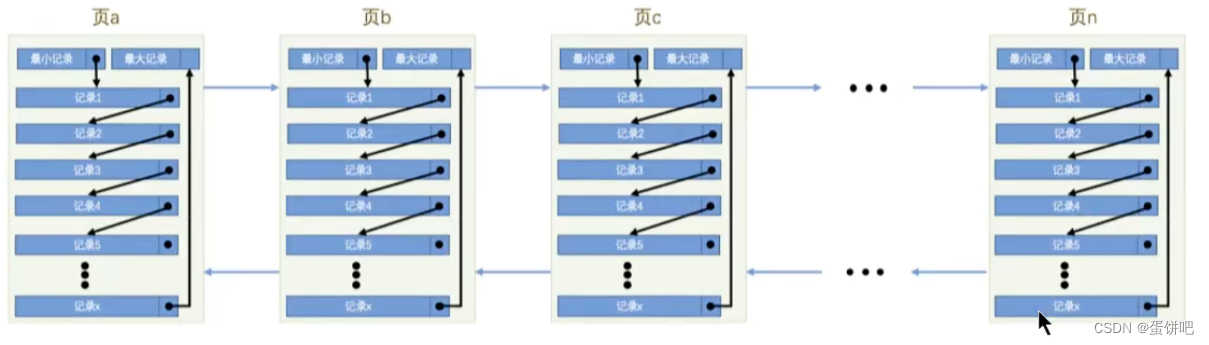
2、页结构概述
页a、页b、页c …页n这些页可以不
在物理结构上相连,只要通过双向链表相关联即可。每个数据页中的记录会按照主键值从小到大的顺序组成一个单向链表,每个数据页都会为存储在它里边的记录生成一个页目录,在通过主键查找某条记录的时候可以在页目录中使用二分法快速定位到对应的槽,然后再遍历该槽对应分组中的记录即可快速找到指定的记录。
3、页的大小
不同的数据库管理系统(简称DBMS)的页大小不同。比如在MySQL的InnoDB存储引擎中,默认页的大小是16KB,可以通过下面的命令
show variables like '%innodb_page_size%';
/*
+------------------+-------+
| Variable_name | Value |
+------------------+-------+
| innodb_page_size | 16384 |
+------------------+-------+
*/SQL Server中页的大小为 8KB,而在oracle中用术语”块’’(Block)来代表”页”,Oralce支持的块大小为2KB,4KB,8KB,16K8,32KB和64KB。
4、页的上层结构
另外在数据库中,还存在区(Extent)、段(Segment)和表空间(Tablespace)的概念。行、页、区、段、表空间的关系如下图所示:
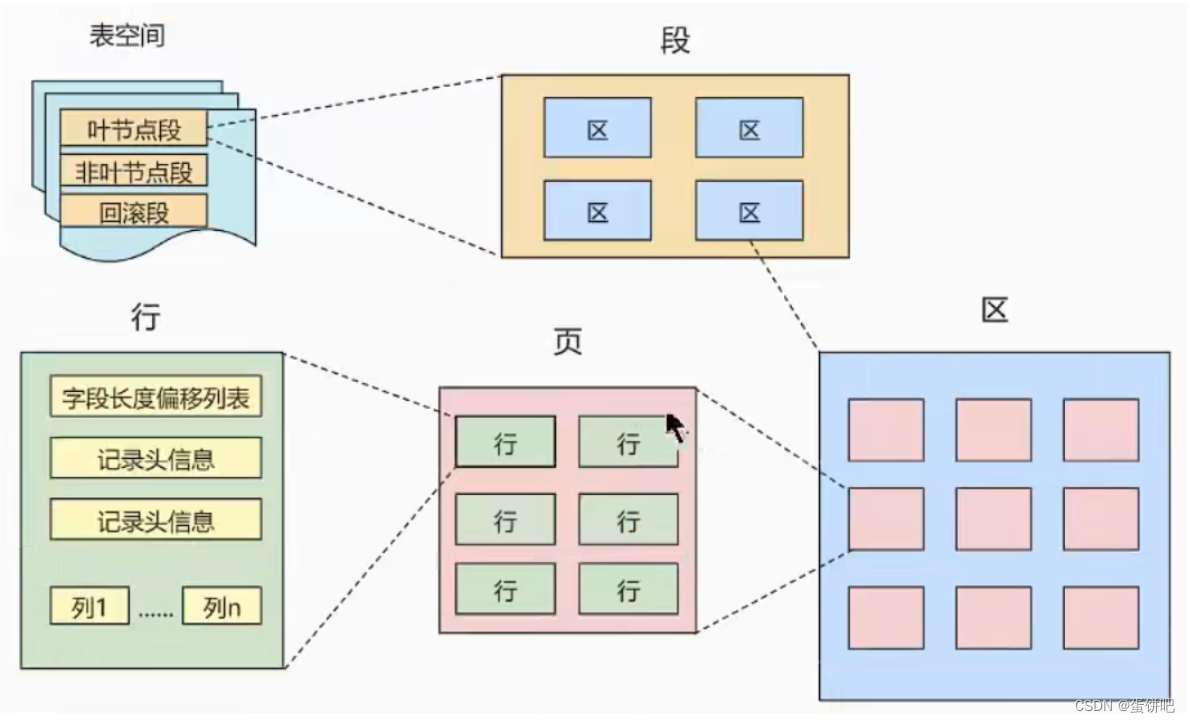
区(Extent)是比页大一级的存储结构,在InnoDB存储引擎中,一个区会分配
64个连续的页。因为InnoDB中的页大小默认是16KB,所以一个区的大小是64*16KB= 1MB。段(Segment)由一个或多个区组成,区在文件系统是一个连续分配的空间(在InnoDB中是连续的64个页),不过在段中不要求区与区之间是相邻的。
段是数据库中的分配单位,不同类型的数据库对象以不同的段形式存在。当创建数据表、索引的时候,就会相应创建对应的段,比如创建一张表时会创建一个表段,创建一个索引时会创建一个索引段。表空间(Tablespace)是一个逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一个段只能属于一个表空间。数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间,
用户表空间、撤销表空间、临时表空间等。
二、页的内部结构
页如果按类型划分的话,常见的有
数据页(保存B+树节点)、系统页、Undo页和事务数据页等。数据页是我们最常使用的页。 数据页的16KB大小的存储空间被划分为七个部分,分别是文件头(File Header)、页头(Page Header)、最大最小记录(Infimum+supremum)、用户记录(User Records)、空闲空间(Free Space)、页目录(Page Directory)和文件尾(File Tailer) 。
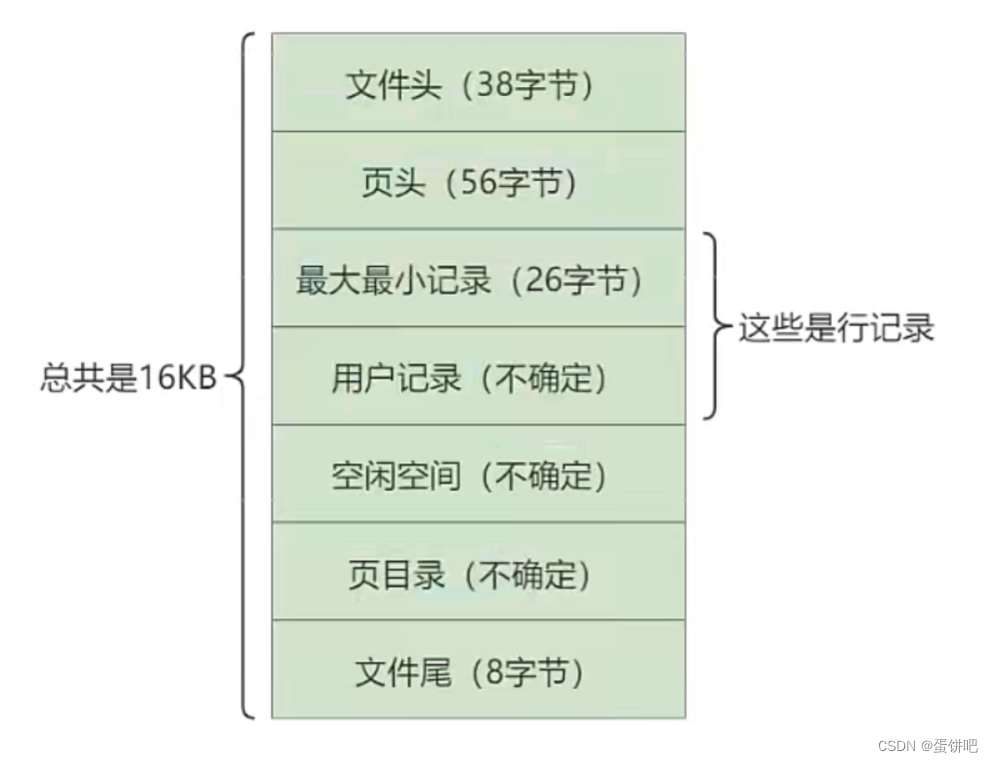
| 名称 | 占用大小 | 说明 |
|---|---|---|
| File Header | 38字节 | 文件头,描述页的信息 |
| Page Header | 56字节 | 页头,页的状态信息 |
| lnfimum-Supremum | 26字节 | 最大和最小记录,这是两个虚拟的行记录 |
| User Records | 不确定 | 用户记录,存储行记录内容 |
| Free Space | 不确定 | 空闲记录,页中还没有被使用的空间 |
| Page Directory | 不确定 | 页目录,存储用户记录的相对位置 |
| File Trailer | 8字节 | 文件尾,校验页是否完整 |
1、分三个部分看

2、从数据页角度看B + 树如何查询
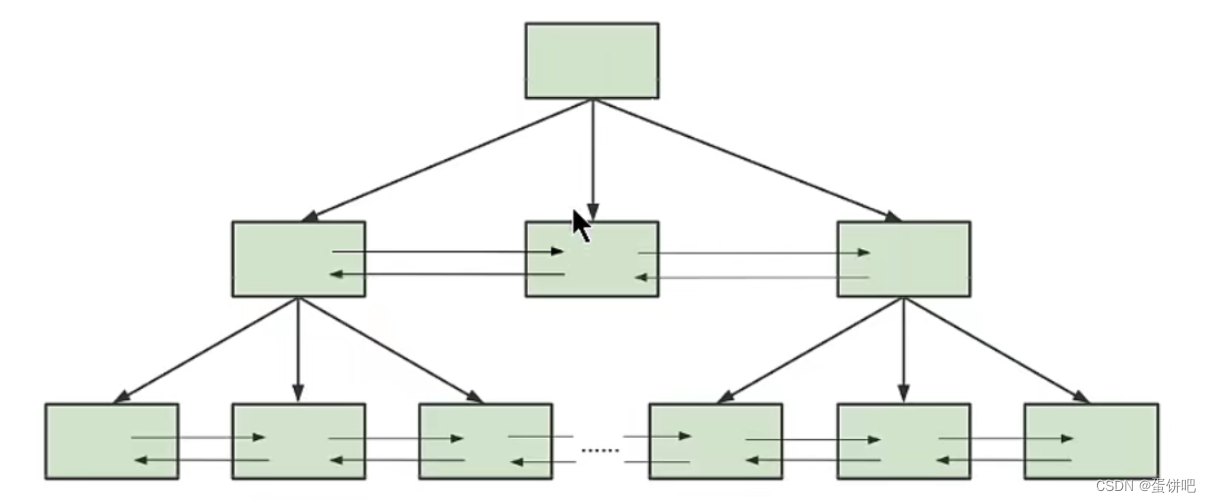
一棵B+树按照节点类型可以分成两部分:
1.叶子节点,B+树最底层的节点,节点的高度为o,存储行记录。
2.非叶子节点,节点的高度大于0,存储索引键和页面指针,并不存储行记录本身。

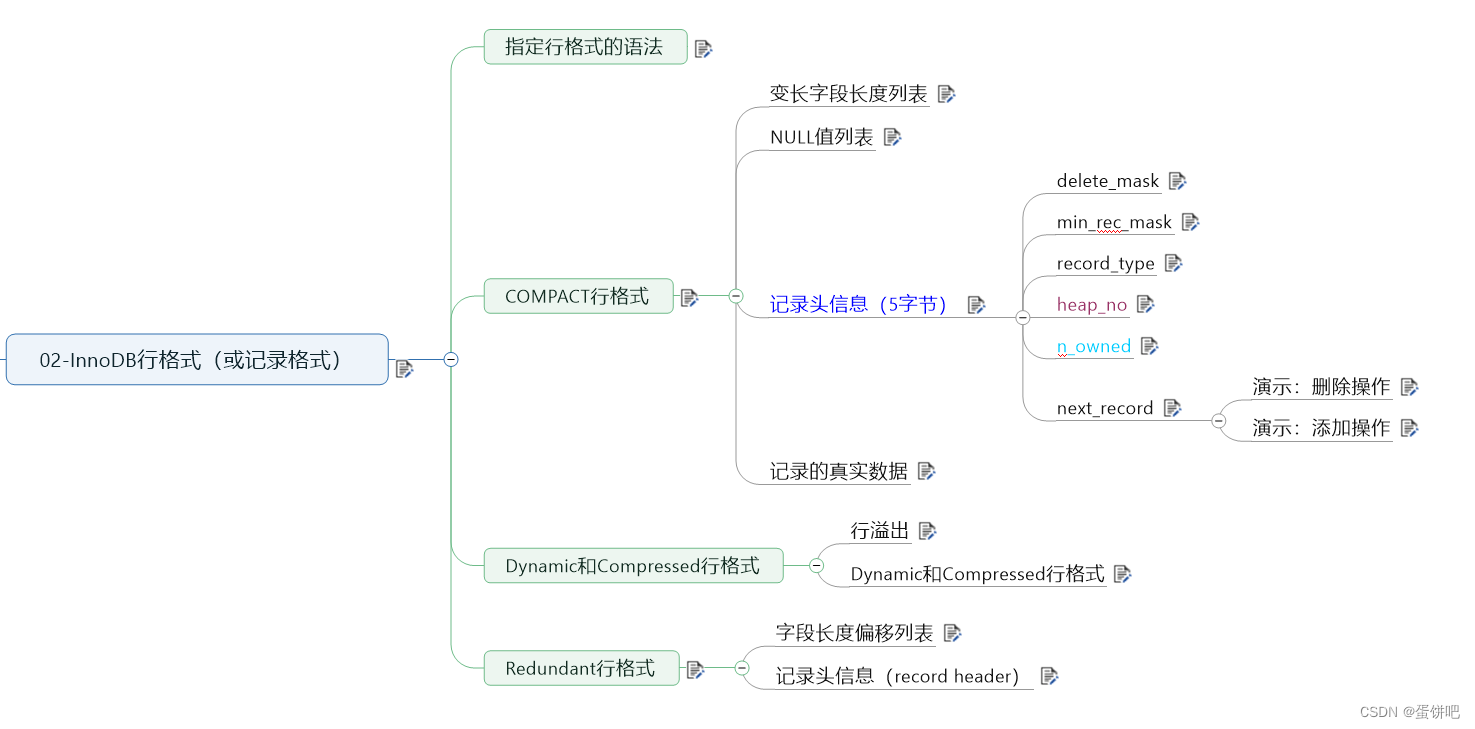
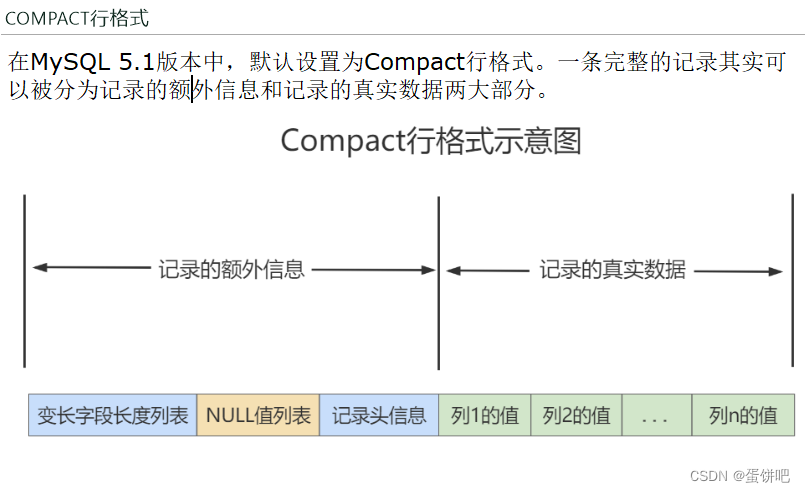
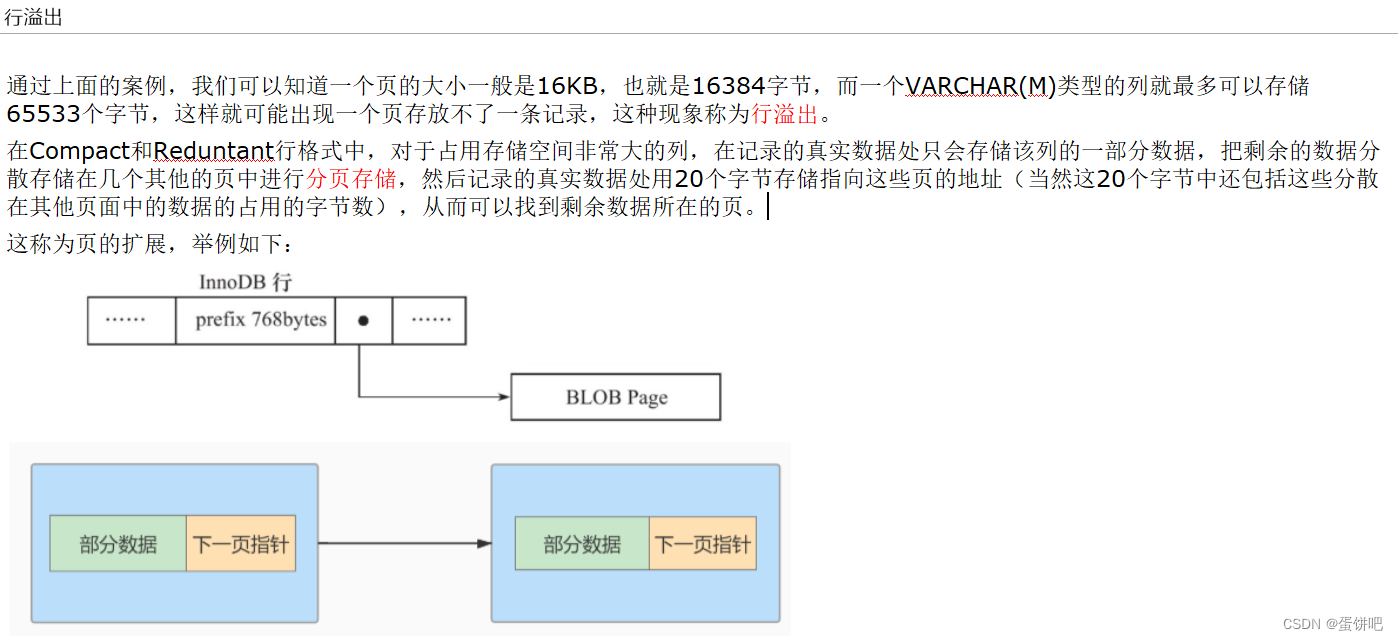
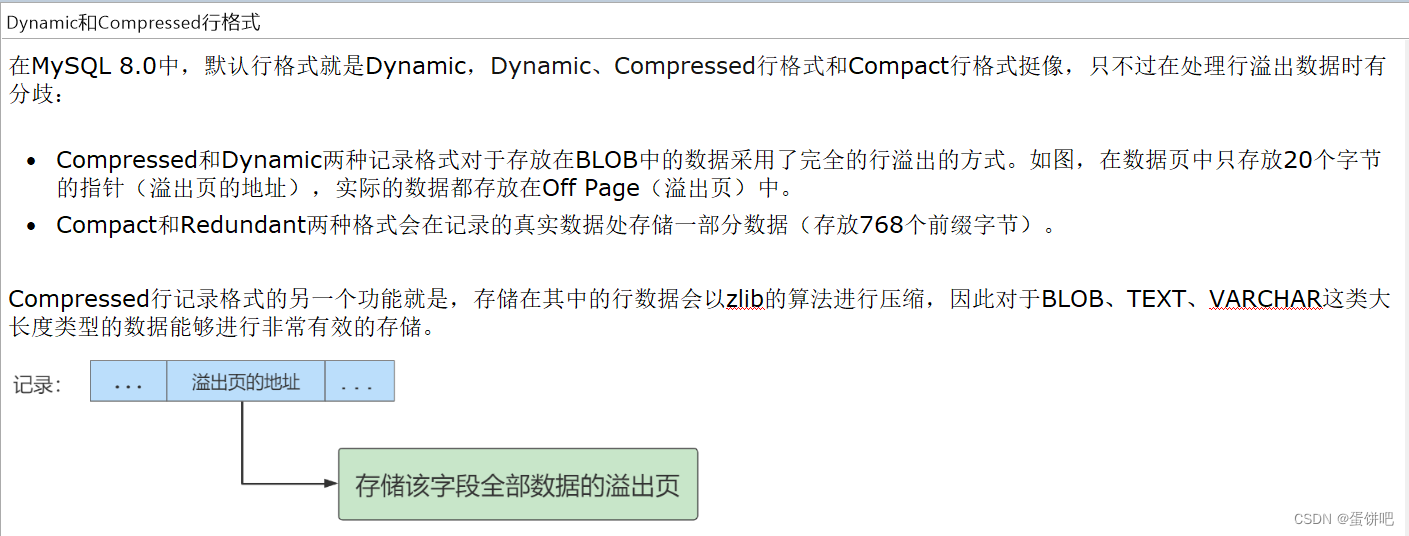
三、InnoDB行格式(或记录格式)
我们平时的数据以行为单位来向表中插入数据,这些记录在磁盘上的存放方式也被称为行格式或者记录格式。
InnoDB存储引擎设计了4种不同类型的行格式,分别是Compact(紧密)、Redundant(冗余)、Dynamic(动态)和Compressed(压缩)行格式。
MySQL8 与 MySQL5.7的默认行格式:dynamic

四、区、段与碎片区
1、为什么要有区?
B+树的每一层中的页都会形成一个双向链表,如果是以页为单位来分配存储空间的话,双向链表相邻的两个页之间的物理位置可能离得非常远。我们介绍B+树索引的适用场景的时候特别提到范围查询只需要定位到最左边的记录和最右边的记录,然后沿着双向链表一直扫描就可以了,而如果链表中相邻的两个页物理位置离得非常远,就是所谓的随机I/0。再一次强调,磁盘的速度和内存的速度差了好几个数量级,随机I/0是非常慢的,所以我们应该尽量让链表中相邻的页的物理位置也相邻,这样进行范围查询的时候才可以使用所谓的顺序I/0。
这样利用了磁盘的预读特性
引入
区的概念,一个区就是在物理位置上连续的64个页。因为InnoDB 中的页大小默认是16KB,所以一个区的大小是64*16KB=1MB。在表中数据量大的时候,为某个索引分配空间的时候就不再按照页为单位分配了,而是按照区为单位分配,甚至在表中的数据特别多的时候,可以一次性分配多个连续的区。虽然可能造成一点点空间的浪费(数据不足以填充满整个区),但是从性能角度看,可以消除很多的随机I/O,功大于过!
这里是连续的64个页, 但是具体的两个页之间还是用指针相连的。保证一大块区域连续。
2、为什么要有段?
对于范围查询,其实是对B+树叶子节点中的记录进行顺序扫描,而如果不区分叶子节点和非叶子节点,统统把节点代表的页面放到申请到的区中的话,进行范围扫描的效果就大打折扣了。所以InnoDB对B+树的
叶子节点和非叶子节点进行了区别对待,也就是说叶子节点有自己独有的区,非叶子节点也有自己独有的区。存放叶子节点的区的集合就算是一个段( segment),存放非叶子节点的区的集合也算是一个段。也就是说一个索引会生成2个段,一个叶子节点段,一个非叶子节点段。
除了索引的叶子节点段和非叶子节点段之外,InnoDB中还有为存储一些特殊的数据而定义的段,比如回滚段。所以,常见的段有
数据段、索引段、回滚段。数据段即为B+树的叶子节点,索引段即为B+树的非叶子节点。在InnoDB存储引擎中,对段的管理都是由引擎自身所完成,DBA不能也没有必要对其进行控制。这从一定程度上简化了DBA对于段的管理。
段其实不对应表空间中某一个连续的物理区域,而是一个逻辑上的概念,由若干个零散的页面以及一些完整的区组成。
零散的页面,看碎片区
3、为什么要有碎片区?
默认情况下,一个使用InnoDB存储引擎的表只有一个聚簇索引,一个索引会生成2个段,而段是以区为单位申请存储空间的,一个区默认占用1M (64*16Kb=1024Kb)存储空间,所以默认情况下一个只存了几条记录的小表也需要2M的存储空间么?以后每次添加一个索引都要多申请2M的存储空间么?这对于存储记录比较少的表简直是天大的浪费。这个问题的症结在于到现在为止我们介绍的区都是非常纯粹的,也就是一个区被整个分配给某一个段,或者说区中的所有页面都是为了存储同一个段的数据而存在的,即使段的数据填不满区中所有的页面,那余下的页面也不能挪作他用。

4、区的分类
区大体上可以分为4种类型:
空闲的区(FREE): 现在还没有用到这个区中的任何页面。
有剩余空间的碎片区(FREE_FRAG):表示碎片区中还有可用的页面。
没有剩余空间的碎片区(FULL_FRAG)︰表示碎片区中的所有页面都被使用,没有空闲页面。
附属于某个段的区(FSEG):每一个索引都可以分为叶子节点段和非叶子节点段。处于
FREE、FREE_FRAG以及FULL_FRAG这三种状态的区都是独立的,直属于表空间。而处于FSEG状态的区是附属于某个段的。

五、表空间
表空间可以看做是InnoDB存储引擎逻辑结构的最高层,所有的数据都存放在表空间中。
表空间是一个
逻辑容器,表空间存储的对象是段,在一个表空间中可以有一个或多个段,但是一个段只能属于一个表空间。表空间数据库由一个或多个表空间组成,表空间从管理上可以划分为系统表空间(System tablespace)、独立表空间(File-per-table tablespace)、撤销表空间(Undo Tablespace)和临时表空间(Temporary Tablespace)等。
1、独立表空间
独立表空间,即每张表有一个独立的表空间,也就是数据和索引信息都会保存在自己的表空间中。独立的表空间(即:单表)可以在不同的数据库之间进行
迁移。
空间可以回收(DROPTABLE操作可自动回收表空间;其他情况,表空间不能自己回收)。如果对于统计分析或是日志表,删除大量数据后可以通过:
alter table TableName engine=innodb;回收不用的空间。对于使用独立表空间的表,不管怎么删除,表空间的碎片不会太严重的影响性能,而且还有机会处理。
独立表空间结构
独立表空间由段、区、页组成。前面已经讲解过了。
真实表空间对应的文件大小
我们到数据目录里看,会发现一个新建的表对应的
.ibd文件只占用了96K,才6个页面大小(MySQL5.7中),这是因为一开始表空间占用的空间很小,因为表里边都没有数据。不过别忘了这些.ibd文件是自扩展的,随着表中数据的增多,表空间对应的文件也逐渐增大。# 查看是否独立表空间 mysql> show variables like 'innodb_file_per_table'; +-----------------------+-------+ | Variable_name | Value | +-----------------------+-------+ | innodb_file_per_table | ON | +-----------------------+-------+ 1 row in set, 1 warning (0.00 sec)MySQL8.0中 7个页面大小。原因.idb 还存了 表结构。。。表结构.frm取消了
2、系统表空间
系统表空间的结构和独立表空间基本类似,只不过由于整个MySQL进程只有一个系统表空间,在系统表空间中会额外记录一些有关整个系统信息的页面,这部分是独立表空间中没有的。
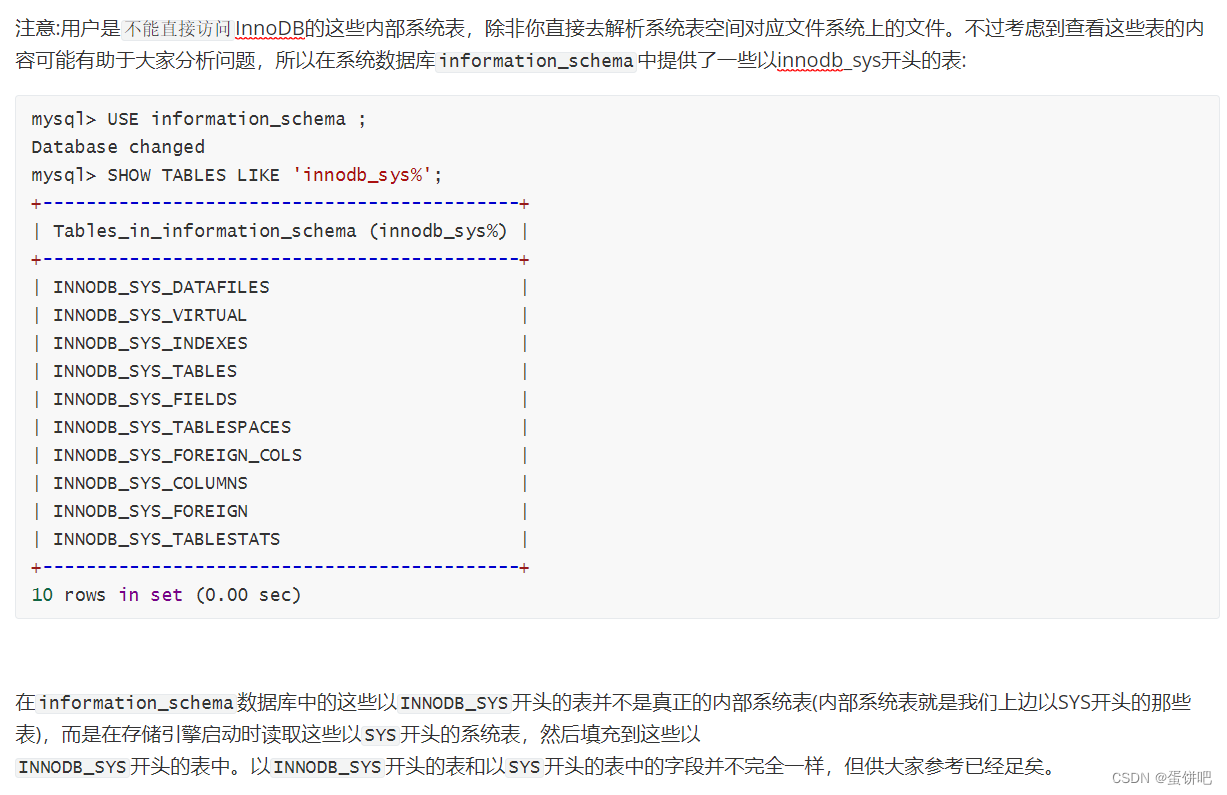
lnnoDB数据字典
每当我们向一个表中插入一条记录的时候,MySQL校验过程如下:
先要校验一下插入语句对应的表存不存在,插入的列和表中的列是否符合,如果语法没有问题的话,还需要知道该表的聚簇索引和所有二级索引对应的根页面是哪个表空间的哪个页面,然后把记录插入对应索引的B+树中。所以说,MySQL除了保存着我们插入的用户数据之外,还需要保存许多额外的信息,比方说:


高级篇笔记PDF自取
链接:https://pan.baidu.com/s/1pVqrTwIZFoED77i-EFmw6g?pwd=3333
提取码:3333
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
