
前言
本篇博文是《从0到1学习 Netty》系列的第一篇博文,主要内容是介绍 NIO 的核心之一 Buffer 中的 ByteBuffer,往期系列文章请访问博主的 Netty 专栏,博文中的所有代码全部收集在博主的 GitHub 仓库中;
什么是 Netty?
Netty 是一个高性能、异步事件驱动的网络应用程序框架,主要用于快速开发可维护、可扩展的高性能服务器和客户端。Netty 提供了简单易用的 API,支持多种协议和传输方式,并且有着高度灵活的扩展和自定义能力。
Netty 的设计目标是提供一种易于使用、高效、可扩展的异步 IO 网络编程框架。它采用了 NIO(Non-blocking IO)的方式来进行网络操作,避免了传统的阻塞式 IO 常常面临的性能瓶颈。同时,Netty 还提供了优秀的线程模型和内存管理机制,保证了高并发下的稳定性和性能。
通过 Netty,开发者可以方便地实现基于 TCP、UDP、HTTP、WebSocket 等多种协议的通信应用。同时,Netty 还提供了编解码器、SSL 支持等组件,使得开发者可以更加专注于业务逻辑的实现。
什么是 ByteBuffer?
ByteBuffer 是 Java 中的一个类,它提供了一种方便的方式来处理原始字节数据。ByteBuffer 可以被看作是一个缓冲区,它可以容纳一定数量的字节数据,并提供了一系列方法来操作这些数据。
使用 ByteBuffer,可以轻松地读取和写入二进制数据。它还提供了对不同类型数据的支持,如整数、浮点数等。ByteBuffer 还支持对数据进行切片,以及对缓冲区中的数据进行复制、压缩、解压等操作。
在 Java 中,ByteBuffer 通常用于处理 I/O 操作,例如从文件或网络中读取和写入数据。它也可以用于处理加密和解密数据,以及处理图像和音频文件等二进制数据。总之,ByteBuffer 是 Java 中非常有用的一个类,可以帮助开发人员更轻松地处理二进制数据。
基本使用
- 向 buffer 写入数据,例如调用
channel.read(buffer); - 调用
flip()切换至读模式;
-
flip会使得 buffer 中的 limit 变为 position,position 变为 0;
- 从 buffer 读取数据,例如调用
buffer.get(); - 调用
clear()或者compact()切换至写模式;
- 调用
clear()方法时,positinotallow=0,limit 变为 capacity; - 调用
compact()方法时,会将缓冲区中的未读数据压缩到缓冲区前面;
- 重复 1~4 的步骤;
编写代码进行测试:
@Slf4j
public class TestByteBuffer {
public static void main(String[] args) {
try (FileChannel channel = new FileInputStream("data.txt").getChannel()) {
// 准备缓冲区
ByteBuffer buffer = ByteBuffer.allocate(10);
while (true) {
// 从 channel 读取数据写入到 buffer
int len = channel.read(buffer);
log.debug("读取到的字节数 {}", len);
if (len == -1) break;
// 打印 buffer 内容
buffer.flip(); // 切换至读模式
while(buffer.hasRemaining()) { // 是否还有剩余未读数据
byte b = buffer.get();
log.debug("实际字节 {}", (char)b);
}
buffer.clear();
}
} catch (IOException e) {
}
}
}运行结果:

注意,日志需要进行配置,在 /src/main/resources/ 路径下,创建 logback.xml,其中的内容如下:
%date{HH:mm:ss} [%-5level] [%thread] %logger{17} - %m%n
logFile.log
logFile.%d{yyyy-MM-dd}.log
15
%date{HH:mm:ss} [%-5level] [%thread] %logger{17} - %m%n
将末尾部分的 中的 name 的属性值改成自己的包名即可。
部分读者可能会遇到如下问题:

这是由于 lombok 引起的,需要检查一下是否安装了 lombok 的插件,以及是否是最新版的 lombok,博主这里用的版本如下:
org.projectlombok
lombok
1.18.26
内部结构
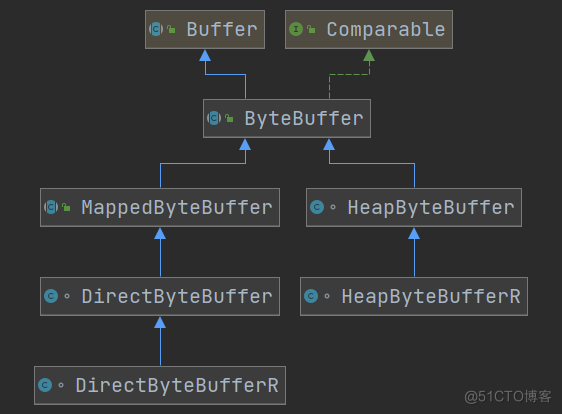
字节缓冲区的父类 Buffer 中有四个核心属性,从以下源码中可以清晰获知:
// Invariants: mark -
position:表示当前缓冲区中下一个要被读或写的字节索引位置,默认值为 0。当我们调用
put()方法往缓冲区中写入数据时,position 会自动向后移动,指向下一个可写的位置;当我们调用get()方法从缓冲区中读取数据时,position 也会自动向后移动,指向下一个可读的位置。 - limit:表示当前缓冲区的限制大小,默认值为 capacity。在写模式下,limit 表示缓冲区最多能够写入的字节数;在读模式下,limit 表示缓冲区最多能够读取的字节数。在一些场景下,我们可以通过设置 limit 来防止越界访问缓冲区。
- capacity:表示缓冲区的容量大小,默认创建 Buffer 对象时指定。capacity 只能在创建缓冲区时指定,并且不能改变。例如,我们可以创建一个容量为 1024 字节的 Buffer 对象,然后往里面写入不超过 1024 字节的数据。
-
mark:mark 和 reset 方法一起使用,用于记录和恢复 position 的值。在 ByteBuffer 中,我们可以通过调用
mark()方法来记录当前 position 的值,然后随意移动 position,最后再通过调用reset()方法将 position 恢复到 mark 记录的位置。使用 mark 和 reset 可以在某些情况下提高代码的效率,避免频繁地重新计算或查询某个值。
这些属性一起组成了 Buffer 的状态,我们可以根据它们的值来确定当前缓冲区的状态和可操作范围。
初始化时,position,limit,capacity 的位置如下:
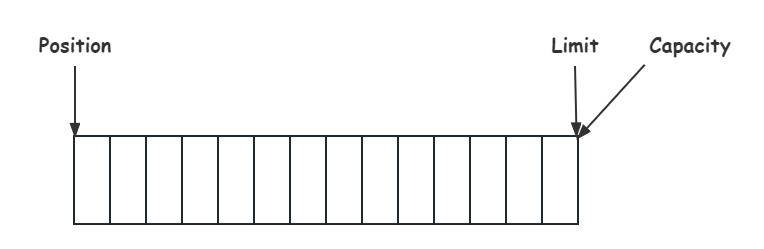
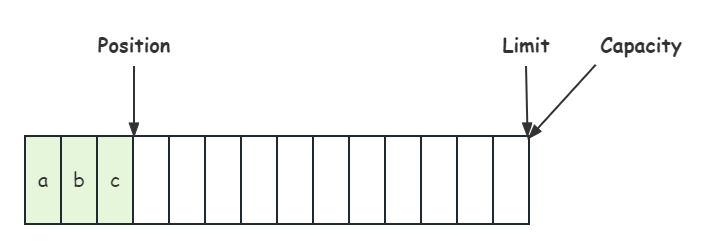
写模式下,position 代表写入位置,limit 代表写入容量,写入3个字节后的状态如下图所示:
当使用 flip() 函数切换至读模式后,position 切换为读取位置,limit 切换为读取限制:
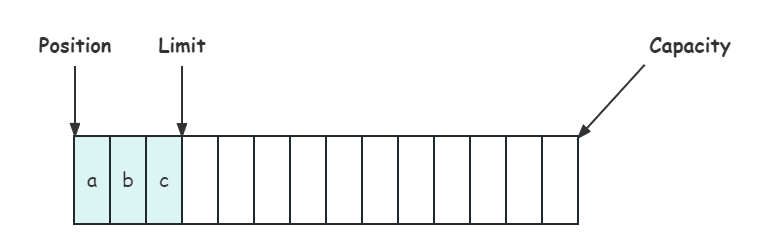
这个变换也可以从 flip() 的源码清晰的获知:
public Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}当读完之后,使用 clean() 函数清空缓存区,可从源码获知,缓冲区又变成了初始化时的状态:
public Buffer clear() {
position = 0;
limit = capacity;
mark = -1;
return this;
}这里还有一种方法 compact(),其作用是将未读完的部分向前压缩,然后切换至写模式,不过需要注意的是,这是 ByteBuffer 中的方法:
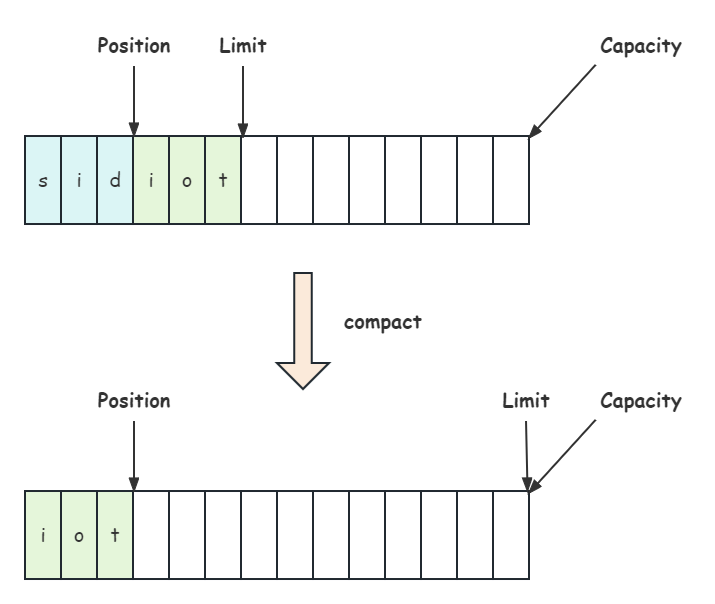
接下来,将要结合代码对上述内容进行深入理解;
这里用到了一个自定义的工具类 ByteBufferUtil,由于篇幅原因,自行从我的 Github 上进行获取: ByteBufferUtil.java;
编写一个测试类,对 ByteBuffer 的常用方法进行测试:
public class TestByteBufferReadWrite {
public static void main(String[] args) {
ByteBuffer buffer = ByteBuffer.allocate(10);
// 写入一个字节的数据
buffer.put((byte) 0x73);
debugAll(buffer);
// 写入一组五个字节的数据
buffer.put(new byte[]{0x69, 0x64, 0x69, 0x6f, 0x74});
debugAll(buffer);
// 获取数据
buffer.flip();
ByteBufferUtil.debugAll(buffer);
System.out.println((char) buffer.get());
System.out.println((char) buffer.get());
ByteBufferUtil.debugAll(buffer);
// 使用 compact 切换写模式
buffer.compact();
ByteBufferUtil.debugAll(buffer);
// 再次写入
buffer.put((byte) 102);
buffer.put((byte) 103);
ByteBufferUtil.debugAll(buffer);
}
}运行结果:
// 向缓冲区写入了一个字节的数据,此时 postition 为 1;
+--------+-------------------- all ------------------------+----------------+
position: [1], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 73 00 00 00 00 00 00 00 00 00 |s......... |
+--------+-------------------------------------------------+----------------+
// 向缓冲区写入了五个字节的数据,此时 postition 为 6;
+--------+-------------------- all ------------------------+----------------+
position: [6], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 73 69 64 69 6f 74 00 00 00 00 |sidiot.... |
+--------+-------------------------------------------------+----------------+
// 调用 flip() 切换至读模式,此时 position 为 0,表示从第 0 个数据开始读取;
// 同时要注意,此时的 limit 为 6,表示 position=6 时内容就读完了;
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [6]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 73 69 64 69 6f 74 00 00 00 00 |sidiot.... |
+--------+-------------------------------------------------+----------------+
// 读取两个字节的数据;
s
i
// 此时 position 变为 2;
+--------+-------------------- all ------------------------+----------------+
position: [2], limit: [6]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 73 69 64 69 6f 74 00 00 00 00 |sidiot.... |
+--------+-------------------------------------------------+----------------+
// 调用 compact() 切换至写模式,此时 position 及其后面的数据被压缩到 ByteBuffer 的前面;
// 此时 position 为 4,会覆盖之前的数据;
+--------+-------------------- all ------------------------+----------------+
position: [4], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 64 69 6f 74 6f 74 00 00 00 00 |diotot.... |
+--------+-------------------------------------------------+----------------+
// 再次写入两个字节的数据,之前的 0x6f 0x74 被覆盖;
+--------+-------------------- all ------------------------+----------------+
position: [6], limit: [10]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 64 69 6f 74 66 67 00 00 00 00 |diotfg.... |
+--------+-------------------------------------------------+----------------+
Process finished with exit code 0空间分配
在上述内容中,我们使用 allocate() 方法来为 ByteBuffer 分配空间,当然还有其他方法也可以为 ByteBuffer 分配空间;
public class TestByteBufferAllocate {
public static void main(String[] args) {
System.out.println(ByteBuffer.allocate(16).getClass());
System.out.println(ByteBuffer.allocateDirect(16).getClass());
/*
class java.nio.HeapByteBuffer - java 堆内存, 读写效率低, 受垃圾回收 GC 的影响;
class java.nio.DirectByteBuffer - 直接内存,读写效率高(少一次拷贝),不会受 GC 的影响;
- 使用完后 需要彻底的释放,以免内存泄露;
*/
}
}写入数据
- 调用
channel的read()方法:channel.read(buf); - 调用
buffer的put()方法:buffer.put((byte) 127);
读取数据
rewind
public Buffer rewind() {
position = 0;
mark = -1;
return this;
}rewind() 的作用是将 position 设置为0,这意味着下一次读取或写入操作将从缓冲区的开头开始。
@Test
public void testRewind() {
// rewind 从头开始读
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'s', 'i', 'd', 'i', 'o', 't'});
buffer.flip();
buffer.get(new byte[6]);
debugAll(buffer);
buffer.rewind();
System.out.println((char) buffer.get());
}运行结果:
+--------+-------------------- all ------------------------+----------------+
position: [6], limit: [6]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 73 69 64 69 6f 74 00 00 00 00 00 00 00 00 00 00 |sidiot..........|
+--------+-------------------------------------------------+----------------+
// 从头读到第一个字符 's';
s
Process finished with exit code 0mark 和 reset
public Buffer mark() {
mark = position;
return this;
}mark() 用于在缓冲区中设置标记;
public Buffer reset() {
int m = mark;
if (m reset() 用于返回到标记位置;
@Test
public void testMarkAndReset() {
// mark 做一个标记,用于记录 position 的位置;reset 是将 position 重置到 mark 的位置;
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'s', 'i', 'd', 'i', 'o', 't'});
buffer.flip();
System.out.println((char) buffer.get());
System.out.println((char) buffer.get());
buffer.mark(); // 添加标记为索引2的位置;
System.out.println((char) buffer.get());
System.out.println((char) buffer.get());
debugAll(buffer);
buffer.reset(); // 将 position 重置到索引2;
debugAll(buffer);
System.out.println((char) buffer.get());
System.out.println((char) buffer.get());
}运行结果:
s
i
d
i
+--------+-------------------- all ------------------------+----------------+
position: [4], limit: [6]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 73 69 64 69 6f 74 00 00 00 00 00 00 00 00 00 00 |sidiot..........|
+--------+-------------------------------------------------+----------------+
// position 从4重置为2;
+--------+-------------------- all ------------------------+----------------+
position: [2], limit: [6]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 73 69 64 69 6f 74 00 00 00 00 00 00 00 00 00 00 |sidiot..........|
+--------+-------------------------------------------------+----------------+
d
i
Process finished with exit code 0get(i)
get(i) 不会改变读索引的位置;
@Test
public void testGet_i() {
// get(i) 不会改变读索引的位置;
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put(new byte[]{'s', 'i', 'd', 'i', 'o', 't'});
buffer.flip();
System.out.println((char) buffer.get(2));
debugAll(buffer);
}运行结果:
d
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [6]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 73 69 64 69 6f 74 00 00 00 00 00 00 00 00 00 00 |sidiot..........|
+--------+-------------------------------------------------+----------------+
Process finished with exit code 0字符串与 ByteBuffer 的相互转换
getBytes
public byte[] getBytes() {
return StringCoding.encode(coder(), value);
}字符串调用 getByte() 方法获得 byte 数组,将 byte 数组放入 ByteBuffer 中:
@Test
public void testGetBytes() {
ByteBuffer buffer = ByteBuffer.allocate(16);
buffer.put("sidiot".getBytes());
debugAll(buffer);
}运行结果:
+--------+-------------------- all ------------------------+----------------+
position: [6], limit: [16]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 73 69 64 69 6f 74 00 00 00 00 00 00 00 00 00 00 |sidiot..........|
+--------+-------------------------------------------------+----------------+
Process finished with exit code 0charset
public final ByteBuffer encode(String str) {
return encode(CharBuffer.wrap(str));
}通过 StandardCharsets 的 encode() 方法获得 ByteBuffer,此时获得的 ByteBuffer 为读模式,无需通过 flip() 切换模式:
@Test
public void testCharset() {
ByteBuffer buffer = StandardCharsets.UTF_8.encode("sidiot");
debugAll(buffer);
System.out.println(StandardCharsets.UTF_8.decode(buffer));
}运行结果:
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [6]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 73 69 64 69 6f 74 |sidiot |
+--------+-------------------------------------------------+----------------+
sidiot
Process finished with exit code 0wrap
public static ByteBuffer wrap(byte[] array,
int offset, int length)
{
try {
return new HeapByteBuffer(array, offset, length, null);
} catch (IllegalArgumentException x) {
throw new IndexOutOfBoundsException();
}
}将字节数组传给 wrap() 方法,通过该方法获得 ByteBuffer,此时的 ByteBuffer 同样为读模式:
@Test
public void testWrap() {
ByteBuffer buffer = ByteBuffer.wrap("sidiot".getBytes());
debugAll(buffer);
}运行结果:
+--------+-------------------- all ------------------------+----------------+
position: [0], limit: [6]
+-------------------------------------------------+
| 0 1 2 3 4 5 6 7 8 9 a b c d e f |
+--------+-------------------------------------------------+----------------+
|00000000| 73 69 64 69 6f 74 |sidiot |
+--------+-------------------------------------------------+----------------+
Process finished with exit code 0后记
以上就是 从0到1(一):认识 ByteBuffer 的所有内容了,希望本篇博文对大家有所帮助!
📝 上篇精讲:这是第一篇,没有上一篇喔~
💖 我是 𝓼𝓲𝓭𝓲𝓸𝓽,期待你的关注;
👍 创作不易,请多多支持;
🔥 系列专栏:Netty
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
