
文章目录
- 8.缓存与数据库双写不一致问题及解决
-
- 8.1双写问题
-
- 8.1.1理想情况
- 8.1.2双写不一致
- 8.2数据更新策略
-
- 8.2.1先更新数据库,后更新缓存(不推荐)
- 8.2.2先更新缓存,后更新数据库(不推荐)
- 8.2.3先更新数据库,再删除缓存
-
- (1)理想情况
- (2)问题出现
- 8.2.4先删除缓存,再更新数据库
- 8.2.5探讨采取方案!!!
-
- (1)先删除缓存再操作数据库
- (2)先操作数据库再删除缓存
- (3)探讨
-
- ①发生概率角度
- ②数据不一致时间角度
- 8.2.6基于延迟双删对Cache Aside的优化
-
- (1)问题出现
- 8.3为什么不使用锁?
- 8.4总结
8.缓存与数据库双写不一致问题及解决
参考文章链接:
- https://liyuanxin.blog.csdn.net/article/details/134222029
- https://blog.csdn.net/qq_38322527/article/details/112908452
8.1双写问题
实际开发中,为了避免频繁查询数据库获取大量信息,造成额外的服务器性能开销和网络延迟问题。一般会增加缓存做数据查询后的临时保存,减少频繁操作数据库耗时问题。
但是,此时却容易出现缓存与数据库双写操作不一致的问题。
8.1.1理想情况
- 请求线程1向数据库写数据,同时更新缓存数据;
- 线程2在线程1处理完成后,向数据库写数据,更新缓存。
- 此时不会出现缓存数据库双写不一致的问题。

8.1.2双写不一致
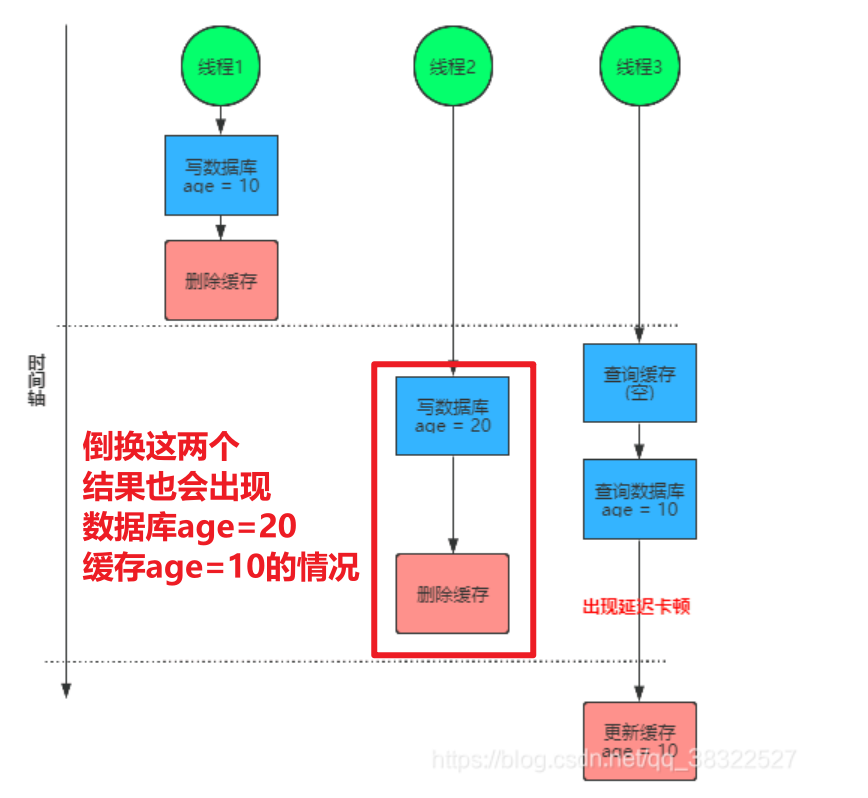
但是,由于在实际项目上线后,可能因为分布式环境下,某些服务器GC或其他因素,导致更新数据库后,出现卡顿,并未及时的删除(或更新)缓存信息,此时问题如下所示:
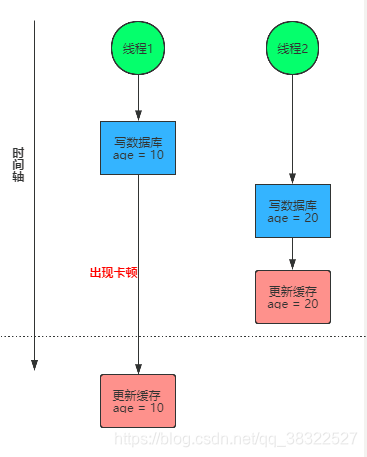
- 由于线程1更新缓存操作在线程2更新缓存操作之后进行,导致数据库中的数据为20,
- 但缓存中的数据被线程1修改为10。
- 出现缓存和数据库数据双写不一致的现象!!
8.2数据更新策略
数据更新策略主要可以分为三种:
-
Cache Aside Pattern(主动更新):开发人员在更新数据库的时候就直接更新缓存
而这种更新策略下,结合更新数据库和更新缓存的步骤,又可以分为以下四种:
- 先更新数据库,后更新缓存
- 先更新缓存,后更新数据库
- 先更新数据库,后删除缓存
- 先删除缓存,后更新数据库
-
Write Behind Caching Patter(异步操作):开发人员只操作缓存,增删改查全部都在缓存中进行,由其他异步线程把缓存数据持久化到数据库,最终保持一致性。
-
Read/Write Through Pattern(整合成一个服务):把缓存和数据库整合成为一个服务,由这个服务来维护一致性
8.2.1先更新数据库,后更新缓存(不推荐)
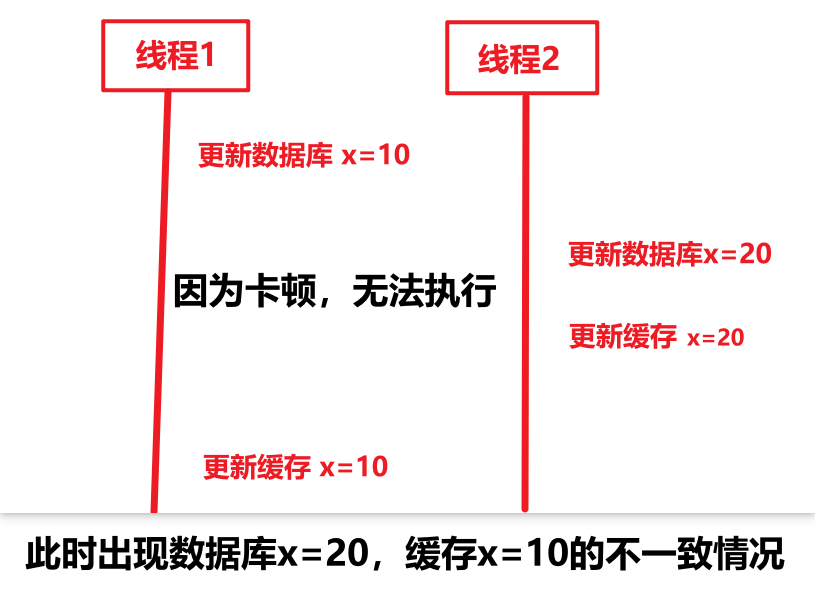
8.2.2先更新缓存,后更新数据库(不推荐)
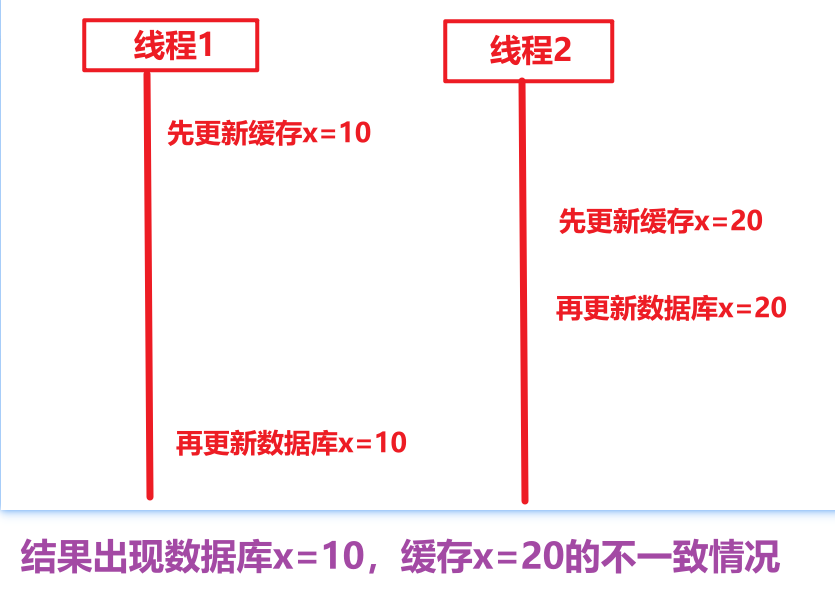
8.2.3先更新数据库,再删除缓存
(1)理想情况
- 线程1向数据库中写数据,写完后删除缓存。
- 线程3随后执行,由于查询到缓存中数据不存在,则从数据库中获取,并更新了缓存。
- 线程2执行,但是 删除缓存操作时间在线程3操作完成之后,此时缓存中不会存在脏数据(数据库的值为20,缓存为空)。
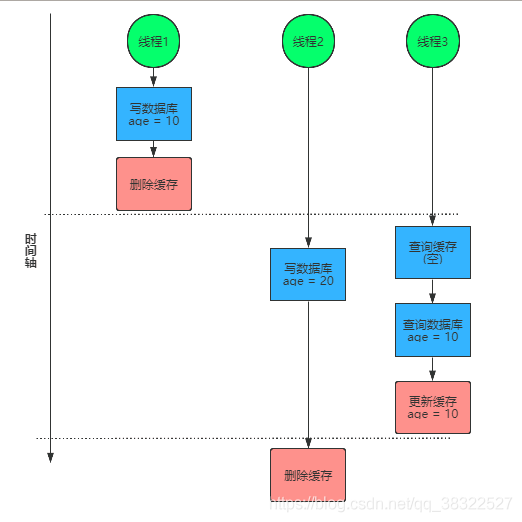
(2)问题出现
如果 线程3因为更新缓存操作延迟,导致更新时间在线程2删除缓存数据之后。
依然会出现双写不一服务器托管网致现象。

此时依旧出现数据库中数据age为20,但缓存中的数据信息为10的情况,也出现双写不一致的问题
8.2.4先删除缓存,再更新数据库
- 即使先删除缓存,再更新数据库,也会出现和上述的问题
8.2.5探讨采取方案!!!
结合上面介绍了这四种情况,我们最后采用先更新数据库,后删除缓存的策略,即Cache Aside Pattern(主动更新策略)
- 先更新数据库,后更新缓存
- 先更新缓存,后更新数据库
- 先更新数据库,后删除缓存
- 先删除缓存,后更新数据库
结合上面分析的情况,考虑下面三个问题?
- 为什么不更新缓存而是选择删除缓存?
- 我们选择删除缓存,相比较于更新缓存来说,删除缓存的效率更高,如果在更新数据库的时候同步更新缓存,则无用的写操作比较多,不如直接把整个缓存删掉,在查询对应数据的时候重新写入缓存。
- 如何保证缓存与数据库的操作同时成功或失败?
- 在单体项目中,我们使用的是思想是:将缓存与数据库放到一个事务中。
- 在分布式系统中,我们使用的思想是:利用TCC等分布式事务方案
- 什么不先删除缓存再更新数据?
对于缓存和数据库,一共就两种操作,我们分类讨论:
- 先删除缓存,再操作数据库。
- 先操作数据库,再操作缓存。
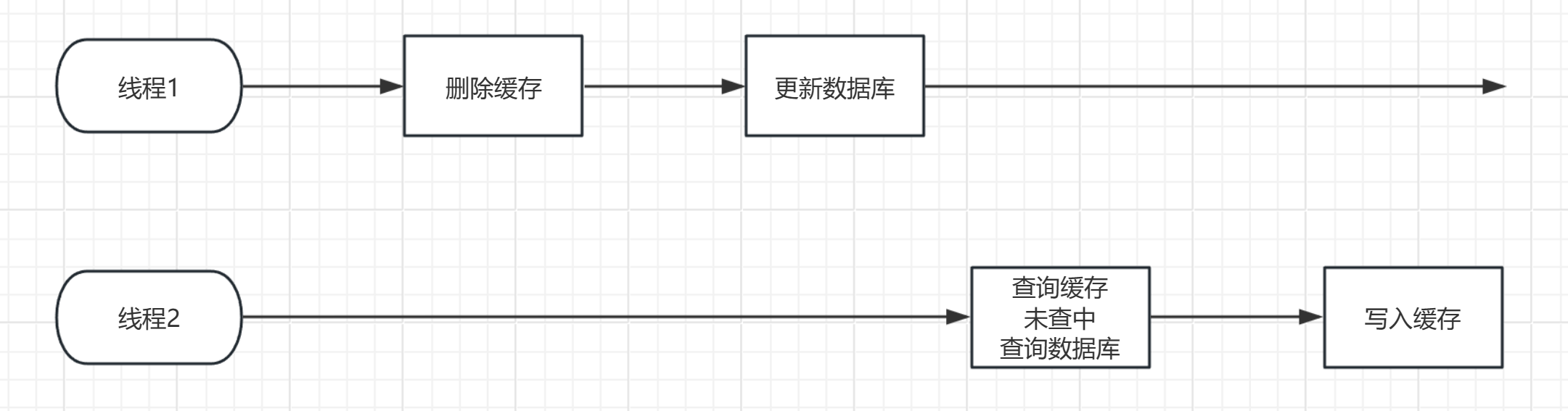
(1)先删除缓存再操作数据库
-
正常情况:
-
在这种情况下相安无事,可是我们都知道线程是交替执行的,既然是交替执行的,就极有可能发生以下这种情况:
-
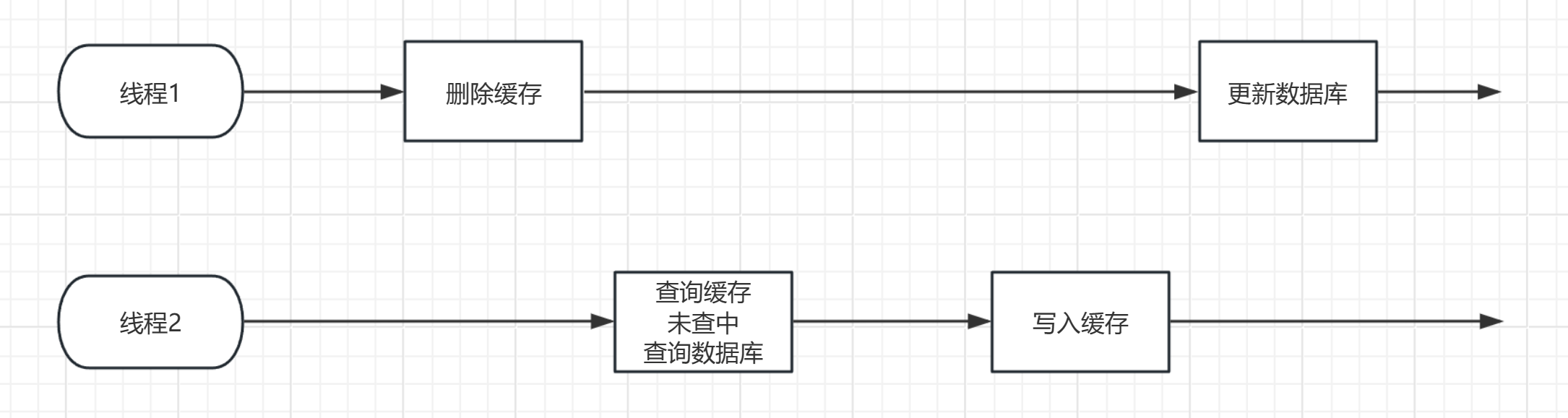
线程切换过程
- 线程1删除缓存后,切换到了线程2
- 线程2查询缓存,未命中,查询数据库,得到旧数据,并写入缓存
- 线程1此时重新拿回执行权,执行更新数据库
-
结果:在这种情况下,发生了缓存中的是旧数据,数据库的是新数据 的错误事件
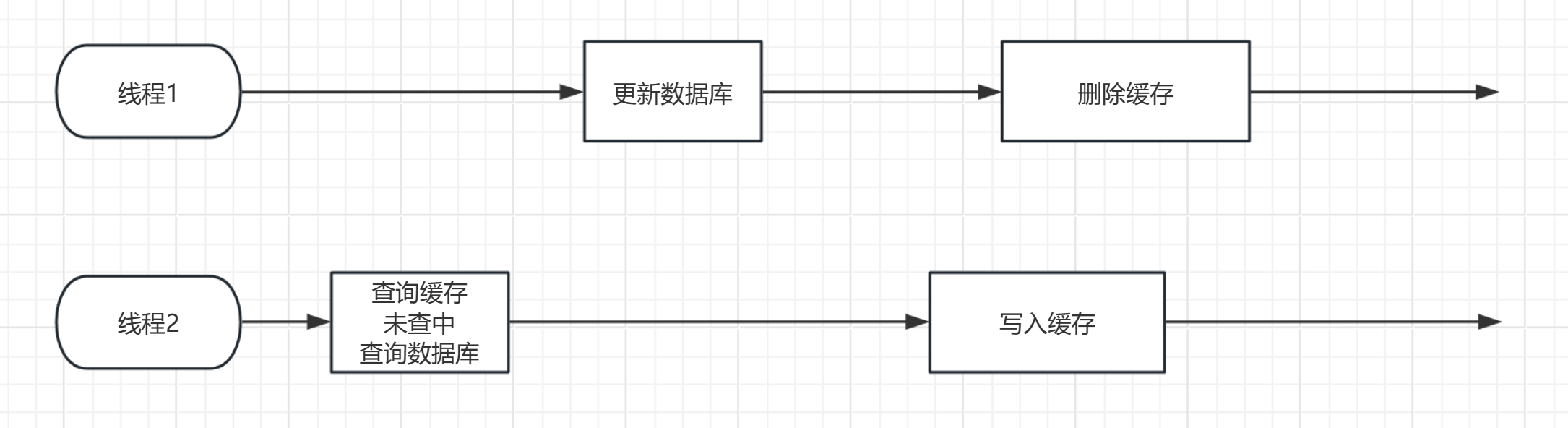
(2)先操作数据库再删除缓存
-
正常情况:

-
在这种情况下相安无事,可是我们都知道线程是交替执行的,既然是交替执行的,就极有可能发生以下这种情况:
-
线程切换过程
- 线程2拿到执行权之后,恰巧缓存数据过期,需要查询数据库,此时查到了旧数据
- 切换到线程1,线程1此时进行更新数据库。更新结束后。
- 切换到线程2,线程2把查询到的旧数据写入缓存
- 此时又到线程1,删除了缓存
-
结果:在这种情况下,发生了缓存中的是旧数据,**数据库的是新数据**的错误事件
(3)探讨
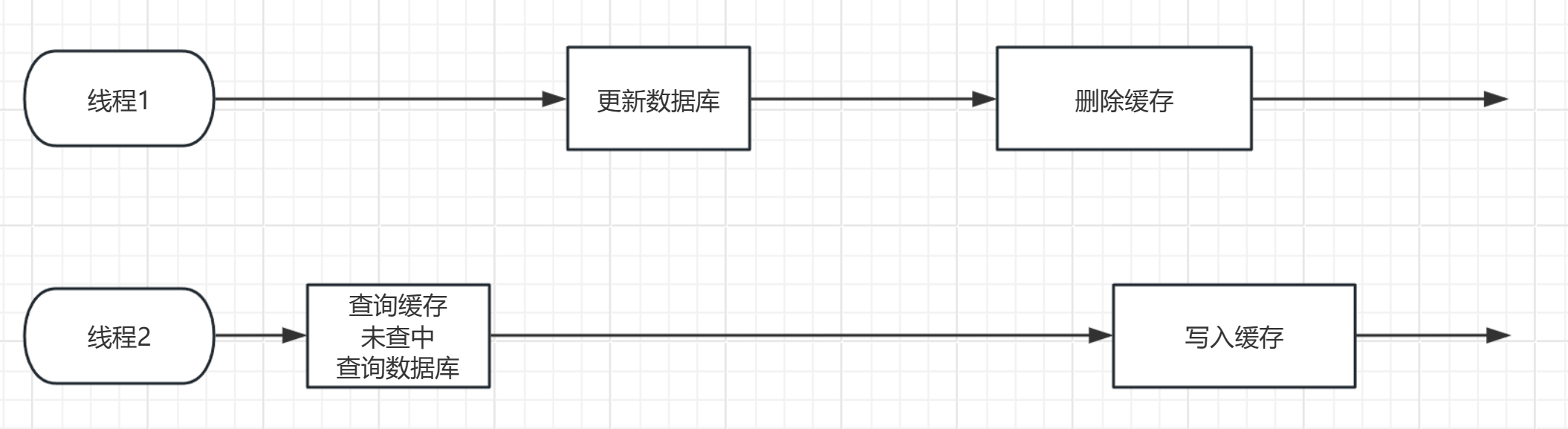
由此可以看出,其实两个操作都会有相同的问题,那么我们应该使用哪一种策略呢?
答案是 先操作数据库,再删除缓存。
①发生概率角度
这是因为这种操作下的异常情况出现的概率要小很多,首先要恰好缓存数据过期。
而且,写入缓存本就是一个很快的过程,
从理论上讲,在一个时间切片内,查询缓存未查中,转向查数据库和写入缓存是可以执行完的。
这也就意味着很难出现 查询缓存未查中,查询数据库后,转向线程1,执行更加费时的更新数据库操作。
②数据不一致时间角度
基于两个操作都异常的情况下,但我们先删除缓存再更新数据库的时候,我们的缓存与数据库==不一致的时间要长==:
在这些步骤完成后,数据库与缓存数据不一致的时期为:直到缓存失效或者下一次删除缓存
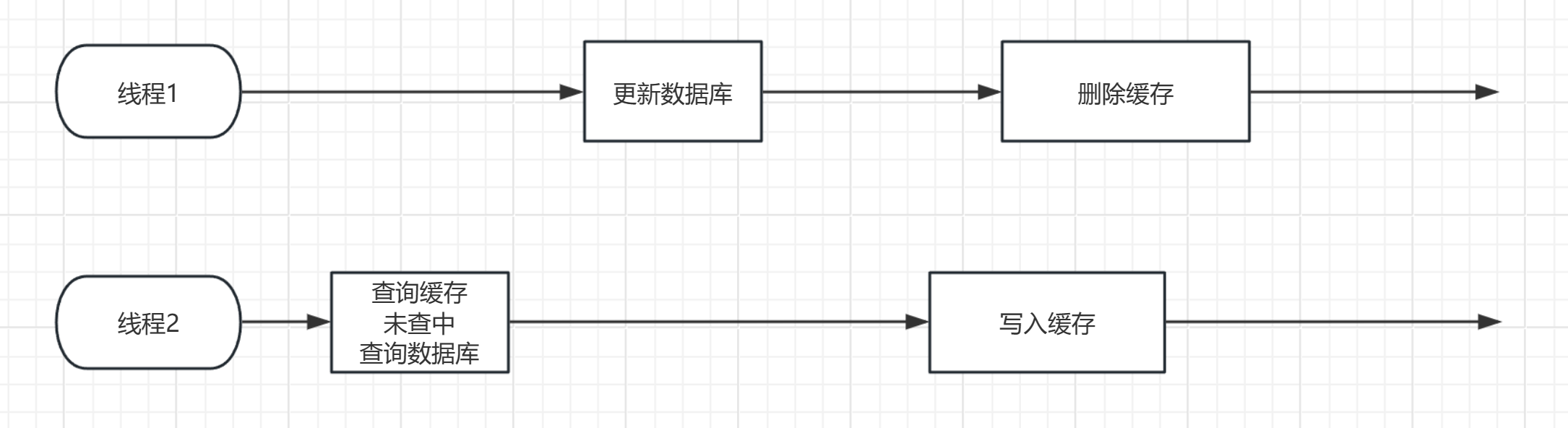
也就是说当先删除缓存,再更新数据库的时候,缓存与数据库数据不一致的时间只有:
从线程2写入缓存到线程1删除缓存
*Redis是基于内存的,也就是说它没有回滚操作。当我们的数据库更新异常时,如果是先更新数据库,再删除缓存的策略,此时我们只需要回滚数据库就可以了*。而如果是先删除缓存,再更新数据库这种机制,那就完蛋了,因为Redis没有回滚操作,除非我们自己手动实现,这样又会增加业务的复杂程度。
也就是说,在不引入锁的前提下,先操作数据库再删除缓存 这种操作策略,可以在最大程度上保持缓存与数据库数据的一致性。
而我们的Cache Aside 这种策略模式,不适合于需要高命中率的场景,因为他会对缓存进行频繁的删除。换句话来讲,Cache Aside 更加适合读多写少的场景
8.2.6基于延迟双删对Cache Aside的优化
延迟双删:先删除redis的缓存数据,再修改数据库,延迟一下下,再删除缓存(再删除一遍)
(1)问题出现
我们可以从上面的图中看出,即使是使用先删数据库,再删缓存的情况下,也仍然有数据不一致的窗口期,而且我们给出的图还是理想的情况下,而在实际生活中,是很有可能出现**写入缓存在删除缓存之后的这种极端情况**的,用图可以表示为:
一旦出现这种情况,那么数据不一致的窗口期就变为了:直到缓存过期或者下一次删除缓存
那么为了解决这种问题的出现,一种新的技术就出现了:*延时双删*
我们用人话来理解一下延时双删的思想:既然删除缓存之后,又把旧的数据写入缓存了,那我们****再删一次不就好了****!
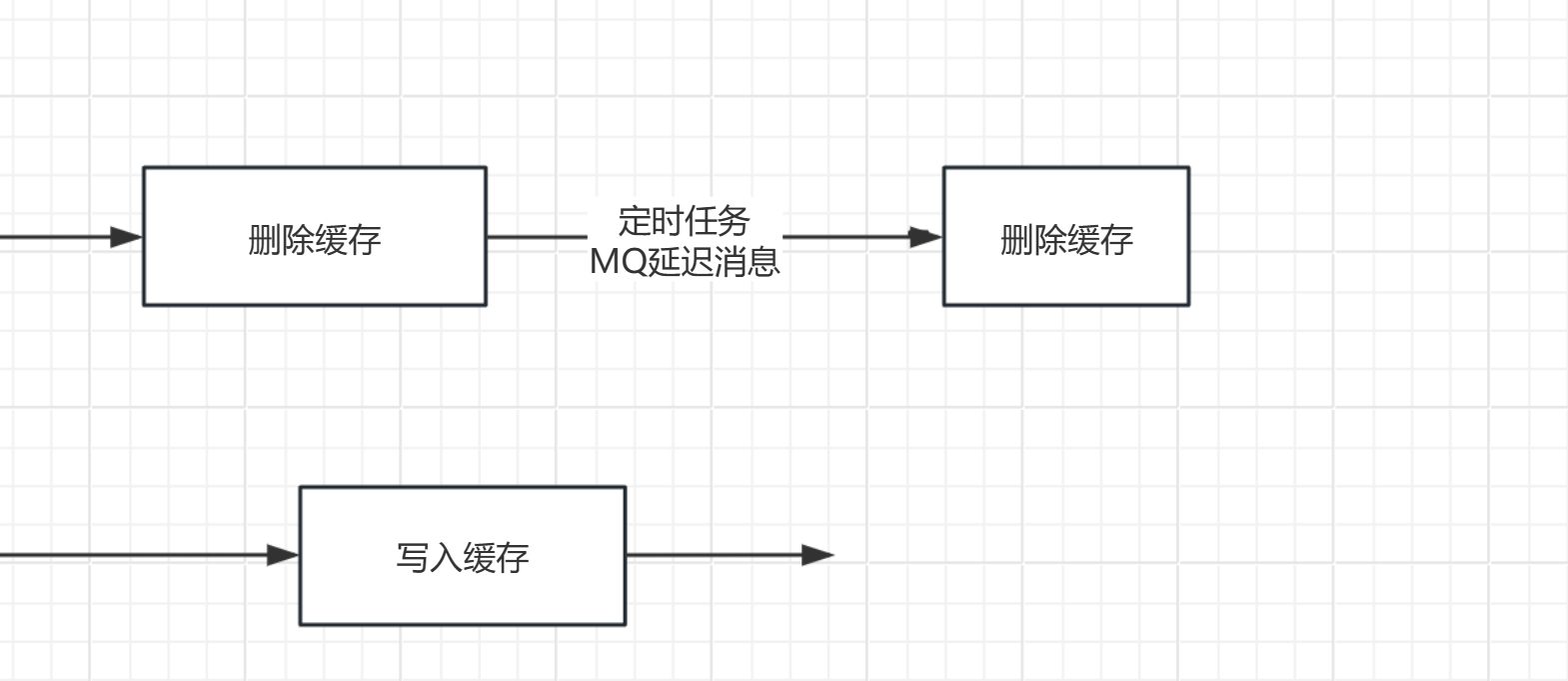
*延时双删* 就是当我们第一次删除缓存之后,设置一个定时任务或者MQ延迟消息,设置在几秒之后再次删除缓存,这样就避免了出现这种极端情况导致的数据不一致窗口期大大加长。
8.3为什么不使用锁?
如果只是为了解决缓存和数据库数据不一致的情况,那么是可以用分布式锁的。但是分布式锁会导致整个项目的并发性彻底完蛋。因此我们尽量要在无锁的情况下解决这种问题。
8.4总结
面对数据库与缓存的数据不一致的问题,我们普遍采用Cache Aside + 延时双删的无锁思想来解决这个问题。但是它并不能真正解决,只是在不断的缩短数据不一致的窗口期,如果想要做到数据库与缓存数据的强一致,那么就需要使用分布式锁,来使得单个线程操作数据库和Redis具有原子性,但是大量的分布式锁会导致项目的并发性完蛋。因此解决此类问题,还是要在无锁的思想基调下进行。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
