
RocketMQ支持集群部署来保证高可用。它基于主从模式,将节点分为Master、Slave两个角色,集群中可以有多个Master节点,一个Master节点可以有多个Slave节点。Master节点负责接收生产者发送的写入请求,将消息写入CommitLog文件,Slave节点会与Master节点建立连接,从Master节点同步消息数据。消费者可以从Master节点拉取消息,也可以从Slave节点拉取消息。
在RocketMQ 4.5版本之前,如果Master宕机,不支持自动将Slave切换为Master,需要人工介入,在4.5版本之后引入了DLedger来解决Master/Slave的主从切换问题,今天先来看主从模式下的数据同步原理。
RocketMQ主从模式下,是通过Slave节点主动向Master节点发送请求通知主节点进行数据同步的。
主从消息同步
建立连接
主节点监听连接事件
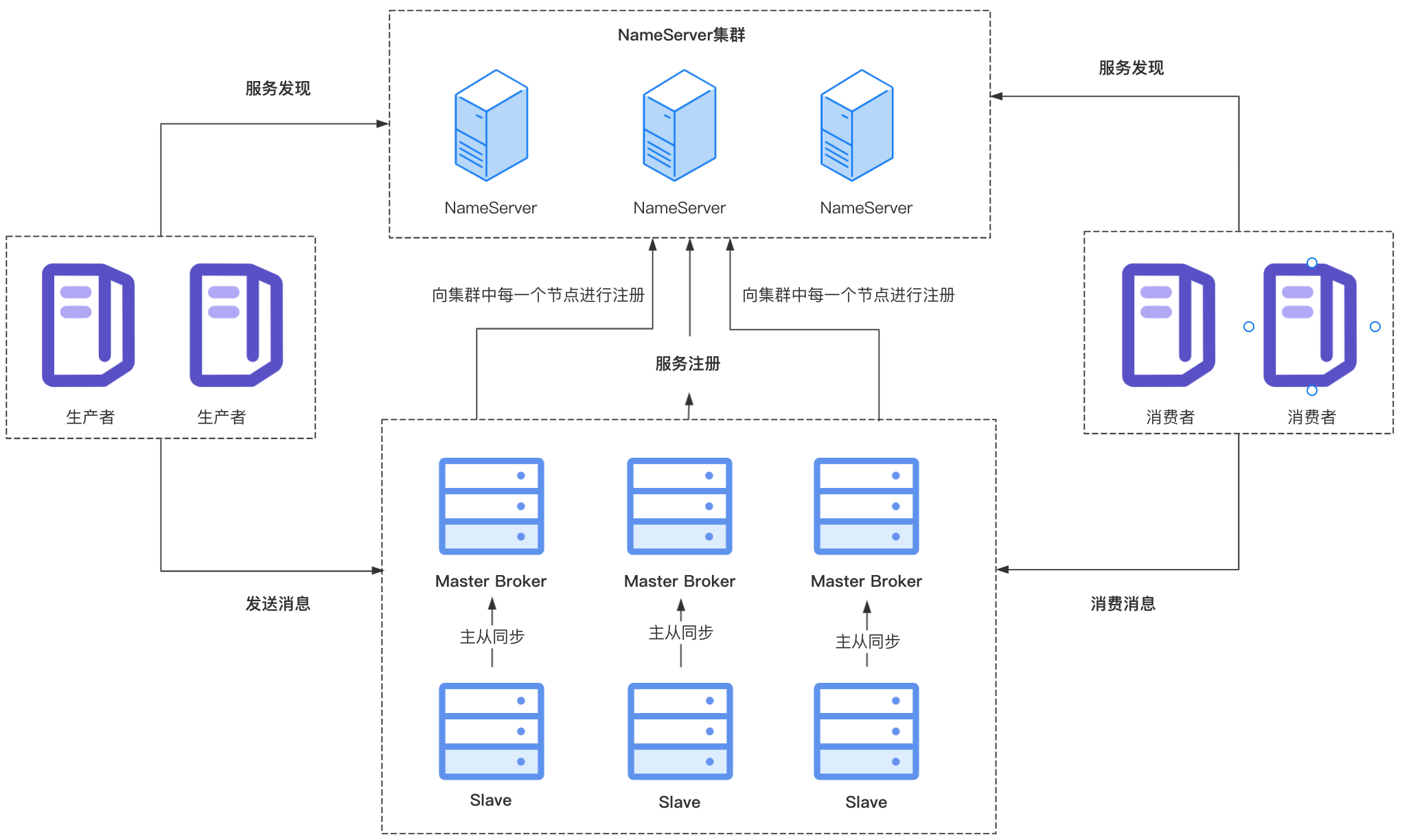
主从节点既然需要传输数据,那么肯定会先建立一个连接,所以主节点在启动的时候,会开启一个端口(haListenPort)用于监听从节点的连接请求(注册了ACCEPT连接事件的监听),默认端口是10912,当然也可以通过配置修改haListenPort的值,使用其他端口。
在端口绑定之后,主节点会专门开启一个线程,用于监听到从节点的连接事件,如果从节点发起了连接请求,会与从节点建立连接,与从节点的连接信息会封装在HAConnection类中,主节点和从节点的数据同步逻辑也在HAConnection中。
从节点发起连接请求
从节点在启动时会向主节点发起连接请求,上面说过主节点会监听从节点的连接请求,所以经过这一步主从节点的连接建立完成,建立成功后,从节点会在连接上注册READ可读事件监听,处理连接上的可读事件。
消息同步
从节点主从同步处理
从节点主从同步的逻辑主要在HAClient中,它开启了一个线程处理主从同步,只要Slave节点未停止,就会不断循环进行如下处理:
- 从节点会定时向主节点汇报消息同步的偏移量(同步进度),所以每次循环开始都会判断是否需要向主节点发送消息同步偏移量,如果已经有一段时间内没有向主节点汇报,此时就会向主节点发送消息同步偏移量,告诉主节点现在同步到哪条消息;
- 等待与Master节点建立的连接上产生可读事件;
- 处理可读事件,主要是判断Master节点是否发来了数据,如果Master节点发送了数据,就要从网络中读取数据,将读取到的消息内容写到从节点自己的CommmitLog。
主节点处理从节点发送请求
读事件处理(处理从节点发送的请求)
上面说到从节点会定时向主节点汇报消息同步的进度,主节点会开启一个线程专门处理监听到的可读事件,也就是处理从节点发来的请求,处理逻辑在ReadSocketService中。
主节点会将从节点发送的消息同步偏移量记录在slaveAckOffset中,表示从节点已经同步的消息位置,同时也会将消息同步偏移量更新到push2SlaveMaxOffset中,它代表了主节点向从节点推送消息的偏移量。slaveRequestOffset的值如果小于0,也会将其更新为从节点反馈的同步偏移量。
这里再对比一下这三个变量的值,之后主节点向从节点发送消息数据会使用slaveRequestOffset来判断是否需要向从节点推送数据:
-
slaveAckOffset:从节点响应的同步消息的偏移量,记录从节点已经同步的消息位置,每次收到从节点反馈的同步偏移量都会对这个值进行更新; -
slaveRequestOffset:默认值为-1,此时表示还未收到从节点反馈的消息偏移量,在收到从节点发送的消息同步偏移量之后,如果slaveRequestOffset的值小于0才会对其进行更新,也就是主节点首次收到从节点的反馈进度或者主节点重启等原因值又被恢复成了默认值-1再次收到反馈进度才会更新,之后不会对其进行更新; -
push2SlaveMaxOffset:默认值为0,在收到从节点反馈的消息偏移量时,会对该值进行更新,与slaveRequestOffset不同的是它每次收到从节点反馈的时候都会更新,表示主节点向从节点推送消息的偏移量;
写事件处理(向从节点发送消息数据)
主节点同样开启了一个线程来处理网络中的写事件,主节点向从节点发送同步消息数据的处理就是在这里进行的,它也会开启一个循环,只要主节点为停止服务,就不断进行如下处理:
-
首先根据
slaveRequestOffset的值判断是否需要进行推送,有以下两种情况:-
slaveRequestOffset值为-1(默认值),表示还未收到过从节点反馈的消息偏移量,所以此时会睡眠一段时间等待从节点发送消息拉取偏移量; -
slaveRequestOffset值不为-1表示已经接收到过从节点反馈的消息偏移量(上面提到从节点向主节点反馈同步进度之后,主节点会更新这个值),此时进入下一步;
-
-
判断
nextTransferFromWhere的值(默认值-1),它是主节点中记录的下次需要传输的消息在CommitLog文件中的偏移量,如果值不为-1表示已经进行过数据同步,此时可以进入下一步。这里我们看下值为-1也就是首次进行主从同步的情况:-
slaveRequestOffset为0,表示从节点向主节点发送的消息同步偏移量为0,也就是从节点还未同步到消息,本次是首次进行同步,那么就从主节点当前CommitLog文件记录的最新的那条消息开始同步,此时更新nextTransferFromWhere的值为当前CommitLog的最大的那个偏移量,然后进入下一步;每个CommitLog文件大小为1G,所以可能会有多个CommitLog文件,首次进行主从同步的时候从最近那个也就是当前正使用的那个CommitLog文件中的消息开始进行同步;
-
slaveRequestOffset大于0,表示从节点之前已经同步过消息,那么就从反馈的位置处开始消息同步,也就是之前同步到哪个消息了,就从那个消息继续往后同步,此时将nextTransferFromWhere的值更新为slaveRequestOffset的值,然后进入下一步;这一步主要是对
nextTransferFromWhere的值进行处理。
-
-
判断上次向从节点发送的消息是否已经传输完毕(有可能网络等原因数据还在发送中):
- 如果数据都已经发送完毕,会判断距离上次发送数据的时间间隔是否超过了设置的心跳时间,如果超过,为了避免连接空闲被关闭,需要发送一个心跳包,维护长连接;
- 如果上次发送的数据还在传输中,会继续先传输上次同步的数据;
-
根据
nextTransferFromWhere的值从CommitLog中获取本次要同步的消息内容; -
更新
nextTransferFromWhere的值为下次发送消息的偏移量; -
将第4步中获取到的消息内容,每次最大发送32KB的数据,发送给从节点,进行数据同步;
从节点对收到消息的处理
在从节点主从同步处理一节中,提到从节点会开启一个线程处理可读事件,当主节点向从节点推送消息数据进行同步后,从节点监听到可读事件,就会从请求中获取发送的消息数据,进行同步:
- 从缓冲区中读取数据,首先获取到的是消息在master节点的物理偏移量masterPhyOffset;
- 获取从节点当前CommitLog的最大物理偏移量
slavePhyOffset,如果不为0并且不等于masterPhyOffset,表示与Master节点的传输偏移量不一致,也就是数据不一致,此时终止处理; - 计算消息体在读缓冲区中的起始位置,从读缓冲区中根据起始位置,读取消息内容,将消息追加到从节点的CommitLog中;
- 继续处理下一条消息直到请求中的消息处理完毕;
从节点会监听到网络中的可读数据,收到消息后将消息写入从节点的CommitLog中。
等待主从复制传输结束
SYNC_MASTER同步复制:消息写入主节点之后,需要等待从节点也写入完毕才能返回成功。
ASYNC_MASTER异步复制:消息写入主节点之后即可返回成功,主从同步数据异步进行,不需要等待从节点写入完毕即可返回成功。
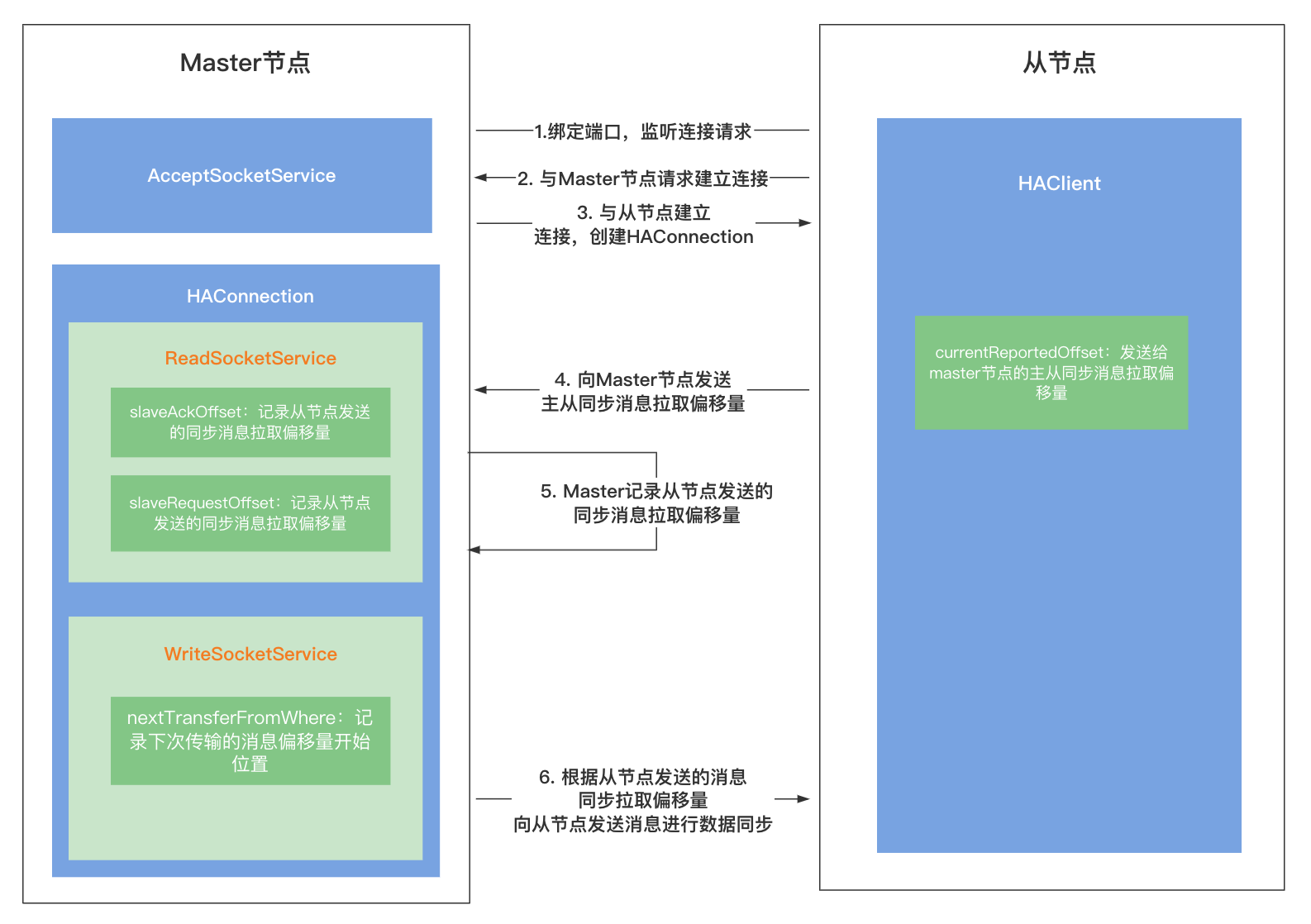
当主从同步开始之后,如果有新的消息写入主节点的CommitLog,如果Master节点配置的是SYNC_MASTER同步复制,在消息写入主节点之后还需要等待从节点同步完毕,主节点会开启一个线程,可以记作数据同步判断线程(GroupTransferService中实现),它专门来判断数据是否同步完毕。
首先消息在写入CommitLog之后会构建一个消息提交请求GroupCommitRequest,请求中会携带本次消息写入之后的偏移量,将其提交到一个求集合requestsRead中,这个线程可以记作主线程,然后主线程会唤醒数据同步判断线程来判断数据是否同步完毕,之后主线程进入等待状态。
在数据同步判断线程中,它会对消息提交请求集合requestsRead中的每一个请求进行处理,开启循环做如下处理:
-
push2SlaveMaxOffset记录了从节点已经同步的消息偏移量,将push2SlaveMaxOffset与本次消息提交请求的偏移量作对比:- 如果
push2SlaveMaxOffset值大,说明当前提交请求中的消息已经同步完毕,此时进入第2步唤醒正在等待的主线程,继续执行主线程的处理逻辑; - 如果
push2SlaveMaxOffset值比请求中的偏移量小,表示这条消息还未同步到从节点,此时当前线程会等待一段时间再进行判断,直到数据已经同步到从节点或者超时;
- 如果
- 唤醒主线程;
主从模式下的消息消费
在主从模式下,消费者向Broker发送拉取消息请求后,Broker对拉取请求进行处理时会设置一个broker ID,建议消费者下次从这个Broker拉取消息,接下来看下Broker是根据什么条件决定返回哪个Broker ID的。
Broker在处理消费者拉取请求时,获取消息后会在返回结果中设置一个是否建议从Slave节点拉取值放在isSuggestPullingFromSlave这个变量中,这个值的判断方式如下:
diff:当前Broker的CommitLog最大偏移量减去本次拉取消息的最大物理偏移量,表示剩余未拉取的消息;
memory:消息在PageCache中的总大小,计算方式是总物理内存 * 消息存储在内存中的阀值(默认为40)/100,也就是说MQ会缓存一部分消息在操作系统的PageCache中,加速访问;
如果dif大于memory的值,表示未拉取的消息过多,已经超出了PageCache缓存的数据的大小,还需要从磁盘中获取消息,所以此时会建议下次从Slave节点拉取,将isSuggestPullingFromSlave的值置为true,否则为false。
订阅分组配置
mqadmin命令的-i参数可以指定从哪个Broker消费消息(对应SubscriptionGroupConfig中的brokerId变量,默认是MASTER节点的ID);
-w参数可以指定建议从slave节点消费的时候,从哪个slave消费(对应SubscriptionGroupConfig中的whichBrokerWhenConsumeSlowly变量,默认值为1);
接下来会用到以上两个参数。
Broker获取到isSuggestPullingFromSlave的值之后,在构建返回结果时,会根据isSuggestPullingFromSlave的值进行以下处理:
- 如果建议从slave节点拉取消息(
isSuggestPullingFromSlave为true),会获取订阅分组配置中设置的whichBrokerWhenConsumeSlowly的值(默认-1)作为建议拉取消息的Broker ID,否则下次依旧建议从主节点拉取消息,将MASTER节点的ID设置到响应中; - 如果当前Broker的角色是slave节点,并且配置了不允许从slave节点读取数据(SlaveReadEnable = false),此时依旧建议从主节点拉取消息,将MASTER节点的ID设置到响应中;
- 如果开启了允许从slave节点读取数据(SlaveReadEnable = true),有以下两种情况:
-
isSuggestPullingFromSlave为true,表示建议从slave节点拉消息,会使用订阅分组配置中设置的whichBrokerWhenConsumeSlowly的值(默认-1)作为建议拉取消息的Broker ID; -
isSuggestPullingFromSlave为false,表示不建议从slave节点拉取消息,会从订阅分组配置中获取broke服务器托管网rId(默认值为Master节点ID)的值作为建议拉取消息的Broker ID;
-
当然,如果未开启允许从Slave节点读取数据,下次依旧建议从Master节点拉取;
总结
默认情况下,消费者从Master节点拉取消息,Broker在处理消息拉取时会根据消息的拉取进度,进行判断,如果未拉取消息的大小超过了总物理内存的40%,此时会建议消费者从Slave节点拉取消息,Broker会将下次建议拉取消息的BrokerID,设置到响应中返回给消费者。
从Sl服务器托管网ave节点拉取消息,需要开启配置项SlaveReadEnable,可以通过mqadmin命令更改订阅分组中的brokerId(默认值为Master节点ID)和whichBrokerWhenConsumeSlowly(默认-1),如果未设置使用默认值。
如果未开启SlaveReadEnable,依旧会从Master节点拉取消息;
消费进度管理
消费者会优先选择向主节点发送请求进行消费进度保存,假如主节点宕机等原因未能获取到主节点的信息,会迭代集合选择第一个节点返回,所以消费者也可以向从节点发送请求进行进度保存,待主节点恢复后,依旧优先选择主节点。
消费进度同步
从节点在启动时会注册定时任务,定时进行数据同步:
- 从节点向主节点发送请求获取消费进度数据;
- 从节点将获取到的消费进度数据进行持久化;
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
