
空间聚类算法是数据挖掘和机器学习领域中的一种重要技术。
本篇介绍的基于密度的空间聚类算法的概念可以追溯到1990年代初期。
随着数据量的增长和数据维度的增加,基于密度的算法逐渐引起了研究者的关注。
其中,DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是最具代表性的算法之一。
基于密度的空间聚类算法在许多领域都有应用,例如图像处理、生物信息学、社交网络分析等。
在图像处理中,该算法可以用于检测图像中的密集区域,用于识别物体或形状。
1. 算法概述
DBSCAN算法的基本思想是,对于给定的数据集,基于数据点的密度进行聚类。
在密度高的区域,数据点更为集中,而密度低的区域数据点较为稀疏。
基于密度的算法能够发现任意形状的簇,并且对噪声有较好的鲁棒性。
算法的核心在于:
- 定义邻域:对于数据集中的每个点,其邻域是由距离该点在一定半径(通常称为Eps)内的所有点组成的
- 定义密度:一个点的密度是其邻域内的点的数量。如果一个点的密度超过某个阈值(通常称为MinPts),则该点被视为核心点
- 寻找簇:从每个核心点出发,找到所有密度可达的点,即这些点通过一系列核心点可以与该核心点相连,这些点形成一个簇
- 标记噪声点:不属于任何簇的点被标记为噪声点
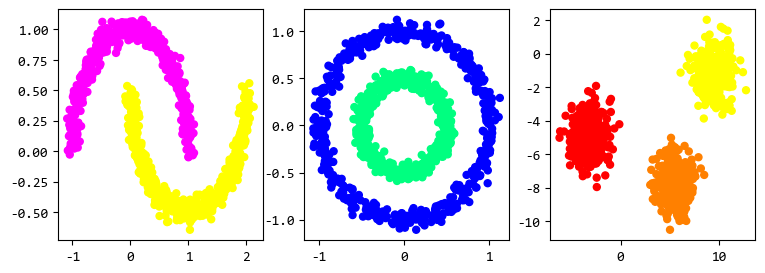
2. 创建样本数据
下面,创建三种不同的样本数据,来测试DBSCAN的聚类效果。
from sklearn.datasets import make_blobs, make_moons, make_circles
fig, axes = plt.subplots(nrows=1, ncols=3)
fig.set_size_inches((9, 3))
X_moon, y_moon = make_moons(noise=0.05, n_samples=1000)
axes[0].scatter(
X_moon[:, 0],
X_moon[:, 1],
marker="o",
c=y_moon,
s=25,
cmap=plt.cm.spring,
)
X_circle, y_circle = make_circles(noise=0.05, factor=0.5, n_samples=1000)
axes[1].scatter(
X_circle[:, 0],
X_circle[:, 1],
marker="o",
c=y_circle,
s=25,
cmap=plt.cm.winter,
)
X_blob, y_blob = make_blobs(n_samples=1000, centers=3)
axes[2].scatter(
X_blob[:, 0],
X_blob[:, 1],
marker="o",
c=y_blob,
s=25,
cmap=plt.cm.autumn,
)
plt.show()
3. 模型训练
用scikit-learn的DBSCAN模型来训练,这个模型主要的参数有两个:
-
eps (eps):这个参数表示邻域的大小,或者说是邻域的半径。具体来说,对于数据集中的每个点,其 eps-邻域包含了所有与该点的距离小于或等于
eps的点。 - min_samples (minPts):在给定 eps-邻域内,一个点需要有多少个邻居才能被视为核心点。
通过调节这2个参数,基于上面创建的样本数据,训练效果如下:
from sklearn.cluster import DBSCAN
# 定义
regs = [
DBSCAN(min_samples=2, eps=0.1),
DBSCAN(min_samples=2, eps=0.2),
DBSCAN(min_samples=3, eps=2),
]
# 训练模型
regs[0].fit(X_moon, y_moon)
regs[1].fit(X_circle, y_circle)
regs[2].fit(X_blob, y_blob)
fig, axes = plt.subplots(nrows服务器托管网=1, ncols=3)
fig.set_size_inches((9, 3))
# 绘制聚类之后的结果
axes[0].scatter(
X_moon[:, 0],
X_moon[:, 1],
marker="o",
c=regs[0].labels_,
s=25,
cmap=plt.cm.spring,
)
axes[1].scatter(
X_circle[:, 0],
X_circle[:, 1],
marker="o",
c=regs[1].labels_,
s=25,
cmap=plt.cm.winter,
)
axes[2].scatter(
X_blob[:, 0],
X_blob[:, 1],
marker="o",
c=regs[2].labels_,
s=25,
cmap=plt.cm.autumn,
)
plt.show()
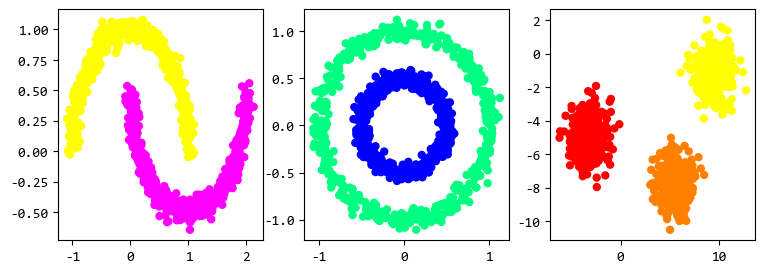
针对3种不同的样本数据,调节参数之后,聚类的效果还不错。
感兴趣的话,可以试试修改上面代码中的DBSCAN定义部分的参数:
# 定义
regs = [
DBSCAN(min_samples=2, eps=0.1),
DBSCAN(min_samples=2, eps=0.2),
DBSCAN(min_samples=3, eps=2),
]
调节不同的 min_sample和eps,看看不同的聚类效果。
4. 服务器托管网总结
总的来说,基于密度的空间聚类算法是一种强大的工具,能够从数据中提取有价值的信息。
但是,如同所有的算法一样,它也有其局限性,需要在合适的应用场景中使用,才能达到最佳的效果。
它的优势主要在于:
- 能够发现任意形状的簇
- 对噪声和异常值有较好的鲁棒性
- 不需要提前知道簇的数量
不足之处则在于:
- 对于高维数据,密度计算可能会变得非常复杂和计算量大
- 算法的性能高度依赖于密度阈值的选择
- 在处理密度变化较大的数据时可能效果不佳
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
Mac M3 芯片安装 Nginx 一、使用 brew 安装 未安装 brew 的可以参考 【Mac 安装 Homebrew】 或者 【Mac M2/M3 芯片环境配置以及常用软件安装-前端】 二、查看 nginx 信息 通过命令行查看 brew info n…
