
【YOLOX】用YOLOv5框架YOLOX
-
-
- 一、新建common_x.py
- 二、修改yolo.py
- 三、新建yolox.yaml
- 四、训练
-
最近在跑YOLO主流框架的对比实验,发现了一个很奇怪的问题,就是同一个数据集,在不同YOLO框架下训练出的结果差距竟然大的离谱。我使用ultralytics公司出品的v5、v3框架跑出的结果精度差距是合理的,然而用该Up主写的Yolov4代码,竟与ultralytics公司出品的v5、v3框架跑出的结果精度能低20-30%,帧率低的离谱。并且YOLOX也是一样结果。虽然不知道为什么,但确实无法进行对比实验,于是只能将Yolov4结构与YoloX结构在Yolov5框架中实现。Yolov4在Yolov5框架中的实现我参考了这个博主的博客,大家有需求可以参考:yolov4_u5版复现。是一系列文章。
下面我来实现将YoloX结构移植到Yolov5框架中,以下是结合网络结构以及YoloX源码进行实现:
一、新建common_x.py
该python文件存放的是YOLOX中用到的模块,主要包括BaseConv、CSPLayer、Dark,代码如下:
import torch
import torch.nn as nn
class SiLU(nn.Module):
"""export-friendly version of nn.SiLU()"""
@staticmethod
def forward(x):
return x * torch.sigmoid(x)
def get_activation(name="silu", inplace=True):
if name == "silu":
module = nn.SiLU(inplace=inplace)
elif name == "relu":
module = nn.ReLU(inplace=inplace)
elif name == "lrelu":
module = nn.LeakyReLU(0.1, inplace=inplace)
else:
raise AttributeError("Unsupported act type: {}".format(name))
return module
class BaseConv(nn.Module):
"""A Conv2d -> Batchnorm -> silu/leaky relu block"""
def __init__(
self, in_channels, out_channels, ksize, stride, groups=1, bias=False, act="silu"
):
super().__init__()
# same padding
pad = (ksize - 1) // 2
self.conv = nn.Conv2d(
in_channels,
out_channels,
kernel_size=ksize,
stride=stride,
padding=pad,
groups=groups,
bias=bias,
)
self.bn = nn.BatchNorm2d(out_channels)
self.act = get_activation(act, inplace=True)
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
class DWConv(nn.Module):
"""Depthwise Conv + Conv"""
def __init__(self, in_channels, out_channels, ksize, stride=1, act="silu"):
super().__init__()
self.dconv = BaseConv(
in_channels,
in_channels,
ksize=ksize,
stride=stride,
groups=in_channels,
act=act,
)
self.pconv = BaseConv(
in_channels, out_channels, ksize=1, stride=1, groups=1, act=act
)
def forward(self, x):
x = self.dconv(x)
return self.pconv(x)
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(
self,
in_channels,
out_channels,
shortcut=True,
expansion=0.5,
depthwise=False,
act="silu",
):
super().__init__()
hidden_channels = int(out_channels * expansion)
Conv = DWConv if depthwise else BaseConv
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = Conv(hidden_channels, out_channels, 3, stride=1, act=act)
self.use_add = shortcut and in_channels == out_channels
def forward(self, x):
y = self.conv2(self.conv1(x))
if self.use_add:
y = y + x
return y
class ResLayer(nn.Module):
"Residual layer with `in_channels` inputs."
def __init__(self, in_channels: int):
super().__init__()
mid_channels = in_channels // 2
self.layer1 = BaseConv(
in_channels, mid_channels, ksize=1, stride=1, act="lrelu"
)
self.layer2 = BaseConv(
mid_channels, in_channels, ksize=3, stride=1, act="lrelu"
)
def forward(self, x):
out = self.layer2(self.layer1(x))
return x + out
class SPPBottleneck(nn.Module):
"""Spatial pyramid pooling layer used in YOLOv3-SPP"""
def __init__(
self, in_channels, out_channels, kernel_sizes=(5, 9, 13), activation="silu"
):
super().__init__()
hidden_channels = in_channels // 2
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=activation)
self.m = nn.ModuleList(
[
nn.MaxPool2d(kernel_size=ks, stride=1, padding=ks // 2)
for ks in kernel_sizes
]
)
conv2_channels = hidden_channels * (len(kernel_sizes) + 1)
self.conv2 = BaseConv(conv2_channels, out_channels, 1, stride=1, act=activation)
def forward(self, x):
x = self.conv1(x)
x = torch.cat([x] + [m(x) for m in self.m], dim=1)
x = self.conv2(x)
return x
class CSPLayer(nn.Module):
"""C3 in yolov5, CSP Bottleneck with 3 convolutions"""
def __init__(
self,
in_channels,
out_channels,
n=1,
shortcut=True,
expansion=0.5,
depthwise=False,
act="silu",
):
"""
Args:
in_channels (int): input channels.
out_channels (int): output channels.
n (int): number of Bottlenecks. Default value: 1.
"""
# ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
hidden_channels = int(out_channels * expansion) # hidden channels
self.conv1 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv2 = BaseConv(in_channels, hidden_channels, 1, stride=1, act=act)
self.conv3 = BaseConv(2 * hidden_channels, out_channels, 1, stride=1, act=act)
module_list = [
Bottleneck(
hidden_channels, hidden_channels, shortcut, 1.0, depthwise, act=act
)
for _ in range(n)
]
self.m = nn.Sequential(*module_list)
def forward(self, x):
x_1 = self.conv1(x)
x_2 = self.conv2(x)
x_1 = self.m(x_1)
x = torch.cat((x_1, x_2), dim=1)
return self.conv3(x)
class Dark(nn.Module):
def __init__(self, c1, c2, n=1, act="silu"):
super().__init__()
self.cv1 = BaseConv(c1, c2, 3, 2, act=act)
self.cv2 = CSPLayer(c2, c2, n=n, depthwise=False, act=act)
def forward(self, x):
return self.cv2(self.cv1(x))
二、修改yolo.py
由于YOLOX里面使用的是Decoupled Head解藕头,所以需要重新设计Detect部分,这里参考了这位博主的博客:YOLO v5 引入解耦头部。
这里有一个需要注意的点是:在 class DecoupledHead 当中的 self.gd=0.5 ,这个参数对应中间隐藏层的输出通道数,原博主这里默认的256,yolox源代码里面这里是乘了 width_multiple 用来控制宽度,因此为了同样实现 -s 模型,我把他乘了对应的系数 self.gd 其对应于 yaml 文件中的 width_multiple 参数控制实现yolox的不同版本。因此,如果想要实现 yolox 的 -m -x -l版本,修改yaml的 width_multiple 参数的时候,不要忘记改这里的 self.gd。 这里因为还得修改函数接口等,就暂时以这种形式实现,后续有时间把这修改一下。
将以下代码,放入yolo.py:
class DecoupledHead(nn.Module):
def __init__(self, ch=256, nc=80, anchors=()):
super().__init__()
self.nc = nc # number of classes
# 中间隐藏层的输出通道数比例
self.gd = 0.5
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
c_ = int(ch * self.gd)
self.merge = Conv(ch, c_, 1, 1)
self.cls_convs1 = Conv(c_, c_, 3, 1, 1)
self.cls_convs2 = Conv(c_, c_, 3, 1, 1)
self.reg_convs1 = Conv(c_, c_, 3, 1, 1)
self.reg_convs2 = Conv(c_, c_, 3, 1, 1)
self.cls_preds = nn.Conv2d(c_, self.nc * self.na, 1)
self.reg_preds = nn.Conv2d(c_, 4 * self.na, 1)
self.obj_preds = nn.Conv2d(c_, 1 * self.na, 1)
def forward(self, x):
x = self.merge(x)
x1 = self.cls_convs1(x)
x1 = self.cls_convs2(x1)
x1 = self.cls_preds(x1)
x2 = self.reg_convs1(x)
x2 = self.reg_convs2(x2)
x21 = self.reg_preds(x2)
x22 = self.obj_preds(x2)
out = torch.cat([x21, x22, x1], 1)
return out
class Decoupled_Detect(nn.Module):
stride = None # strides computed during build
onnx_dynamic = False # ONNX export parameter
export = False # export mode
def __init__(self, nc=80, anchors=(), ch=(), inplace=True): # detection layer
super().__init__()
self.nc = nc # number of classes
self.no = nc + 5 # number of outputs per anchor
self.nl = len(anchors) # number of detection layers
self.na = len(anchors[0]) // 2 # number of anchors
self.grid = [torch.zeros(1)] * self.nl # init grid
self.anchor_grid = [torch.zeros(1)] * self.nl # init anchor grid
self.register_buffer('anchors', torch.tensor(anchors).float().view(self.nl, -1, 2)) # shape(nl,na,2)
self.m = nn.ModuleList(DecoupledHead(x, nc, anchors) for x in ch)
self.inplace = inplace # use in-place ops (e.g. slice assignment)
def forward(self, x):
z = [] # inference output
for i in range(self.nl):
x[i] = self.m[i](x[i]) # conv
bs, _, ny, nx = x[i].shape # x(bs,255,20,20) to x(bs,3,20,20,85)
x[i] = x[i].view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()
if not self.training: # inference
if self.onnx_dynamic or self.grid[i].shape[2:4] != x[i].shape[2:4]:
self.grid[i], self.anchor_grid[i] = self._make_grid(nx, ny, i)
y = x[i].sigmoid()
if self.inplace:
y[..., 0:2] = (y[..., 0:2] * 2 + self.grid[i]) * self.stride[i] # xy
y[..., 2:4] = (y[..., 2:4] * 2) ** 2 * self.anchor_grid[i] # wh
else: # for YOLOv5 on AWS Inferentia https://github.com/ultralytics/yolov5/pull/2953
xy, wh, conf = y.split((2, 2, self.nc + 1), 4) # y.tensor_split((2, 4, 5), 4) # torch 1.8.0
xy = (xy * 2 + self.grid[i]) * self.stride[i] # xy
wh = (wh * 2) ** 2 * self.anchor_grid[i] # wh
y = torch.cat((xy, wh, conf), 4)
z.append(y.view(bs, -1, self.no))
return x if self.training else (torch.cat(z, 1),) if self.export else (torch.cat(z, 1), x)
def _make_grid(self, nx=20, ny=20, i=0):
d = self.anchors[i].device
t = self.anchors[i].dtype
shape = 1, self.na, ny, nx, 2 # grid shape
y, x = torch.arange(ny, device=d, dtype=t), torch.arange(nx, device=d, dtype=t)
if check_version(torch.__version__, '1.10.0'): # torch>=1.10.0 meshgrid workaround for torch>=0.7 compatibility
yv, xv = torch.meshgrid(y, x, indexing='ij')
else:
yv, xv = torch.meshgrid(y, x)
grid = torch.stack((xv, yv), 2).expand(shape) - 0.5 # add grid offset, i.e. y = 2.0 * x - 0.5
anchor_grid = (self.anchors[i] * self.stride[i]).view((1, self.na, 1, 1, 2)).expand(shape)
return grid, anchor_grid
修改yolo.py中的parse_model函数:
在下面添加BaseConv、CSPLayer、Dark模块
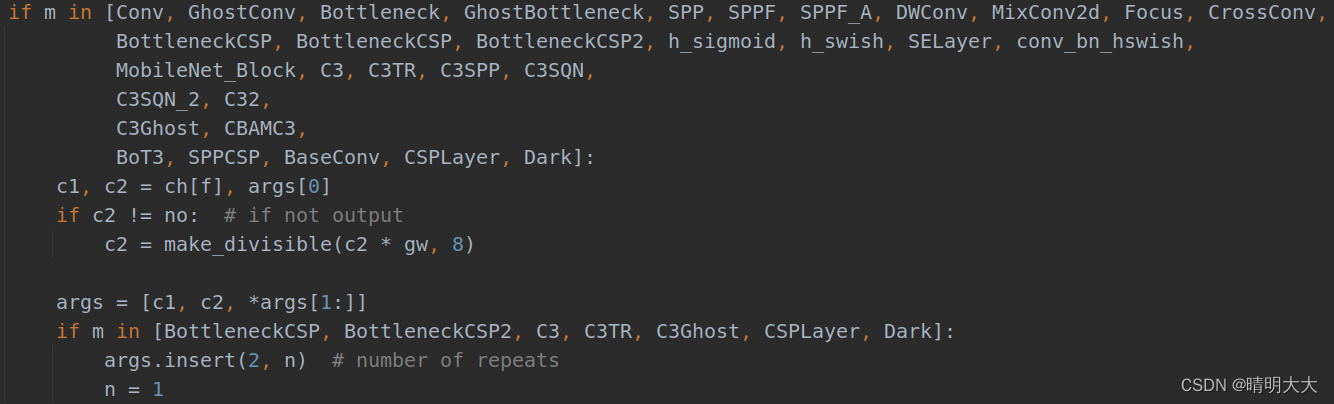 添加Decoupled_Detect模块
添加Decoupled_Detect模块
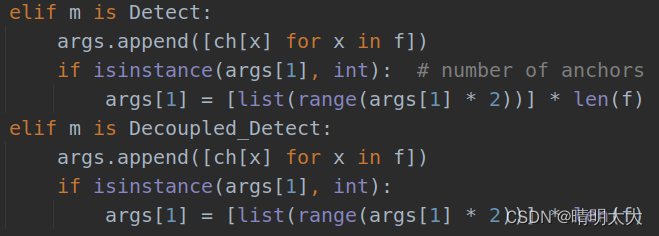
三、新建yolox.yaml
新建yolox.yaml
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # expand model depth
width_multiple: 0.5 # expand layer channels
# anchors
anchors:
- [12,16, 19,36, 40,28] # P3/8
- [36,75, 76,55, 72,146] # P4/16
- [142,110, 192,243, 459,401] # P5/32
# yolov4l backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3, 1]], # 0
[-1, 3, Dark, [128]], # 1-P1/2
[-1, 9, Dark, [256]],
[-1, 9, Dark, [512]], # 3-P2/4
[-1, 3, Dark, [1024]],
]
# yolov4l head
# na = len(anchors[0])
head:
[[-1, 1, BaseConv, [512, 1, 1]], # 11
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 3], 1, Concat, [1]],
[-1, 3, CSPLayer, [512]], # 16
[-1, 1, BaseConv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]],
[-1, 3, CSPLayer, [256]], # 21
[-1, 1, BaseConv, [256, 3, 2]],
[[-1, 9], 1, Concat, [1]], # cat
[-1, 3, CSPLayer, [512]], # 25
[-1, 1, BaseConv, [512, 3, 2]], # route backbone P3
[[-1, 5], 1, Concat, [1]], # cat
[-1, 3, CSPLayer, [1024]], # 29
[[12,15,18], 1, Decoupled_Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
四、训练
以上配置完之后,其他操作与训练Yolov5步骤一致,最终训练出来的效果,要比原YoloX训练结果好不少,看起来更加合理,与Yolov5训练结果差距也是在合理范围内。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
