
说到全文检索的分词,多半讲到的是中(日韩)文分词,少有英文等拉丁文系语言,因为英语单词天然就是分词的。
但更少讲到阿拉伯数字。比如金额,手机号码,座机号码等等。
以下不是传统的从0开始针对mysql全文索引前世今生讲起。
我更喜欢从一个小问题入手,见缝插针的将相关的知识点,以非时间线性顺序零散穿插起来。
从一个线上的BUG说起
我们有一张人口表,里面的数据有多种数据源合并而来,因此每个用户的手机号可能有多个。
这也很好理解,有的人就是有多个手机号,有的人就是经常换手机号,对吧。
现在有个功能需要通过手机号去关联用户。
因为手机号有多个,所以要么使用like进行模糊匹配。用户表有上千万条记录,这样的效率肯定是不能接受的。
select * from t_user where phone like '%13112345678%'
要么使用另一个折中的方案,将手机号单独成表,用户表对手机号表一对多关联。
这种方式效率上能接受,但需要改变现有数据结构,故放弃。
select u.id,u.username,u.phone from t_user u LEFT JOIN t_user_phone p on u.id = p.user_id where p.phone = '13112345678'
最终选用全文索引。(mysql 5.7.6+)
先在用户表针对手机号创建一个全文索引。
使用内置分词引擎ngram。
CREATE FULLTEXT INDEX idx_full_text_phone ON t_user (phone) WITH PARSER ngram;
当使用手机模糊查询关联用户时可使用以下语句。
- 布尔模式模糊检索
select * from t_user where match(phone) AGAINST('13996459860' in boolean mode)
- 自然语言模式。mysql默认为此模式,所以第2条sql没有显式指定时,仍然为自然语言模式。
select * from t_user where match(phone) AGAINST('13996459860' in NATURAL LANGUAGE mode)
或
select * from t_user where match(phone) AGAINST('13996459860')
根据我们的需求,查询手机号需要全匹配才算命中。所以选择布尔模式。
自然语言模式做不到。
关于布尔模式和自然语言模式的区别,后面做介绍。
以上算是简单的背景介绍。
但是
万恶的但是,虽迟但到
有一天产品过来告诉我,某个手机号关联出来上百个人。
他问,这种情况是正常的吗?
他如果直接说你这里有个bug,我可能直接就怼回去了(bushi 🤣
但是他说得这么委婉,我反而没底了。 🙈
不要对一个程序员说:你的代码有Bug。他的第一反应是:①你的环境有问题吧;②S13你会用吗?
如果你委婉地说:你这个程序和预期的有点不一致,你看看是不是我的使用方法有问题?
他本能地会想:woco!是不是出Bug了!
直觉告诉我这不正常,不然这个人是搞电诈或者海王吗?
我拿手机号去数据库里查询。使用布尔模式全文检索,确实关联出来多个人。
但也确实是个BUG.
我们来完整地模拟一下。
先创建一张测试用户表。
phone字段加上全文索引,使用ngram分词器。
CREATE TABLE `t_user` (
`id` int(11) NOT NULL,
`username` varchar(10) COLLATE utf8_bin DEFAULT NULL,
`phone` varchar(50) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (`id`),
FULLTEXT KEY `idx_full_text_phone` (`phone`) /*!50100 WITH PARSER `ngram` */
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
插入几条测试数据
-- ----------------------------
-- Records of t_user
-- ----------------------------
INSERT INTO `t_user` VALUES ('1', '张三', '13996459860,15987569874,0797-12345');
INSERT INTO `t_user` VALUES ('2', '李四', '0797-6789');
INSERT INTO `t_user` VALUES ('3', '王五', '0797-94649');
正常情况下
select * from t_user where match(phone) AGAINST('13996459860' in boolean mode)
select * from t_user where match(phone) AGAINST('13996459860' in NATURAL LANGUAGE mode)
select * from t_user where match(phone) AGAINST('13996459860')
都能得到

异常情况
select * from t_user where match(phone) AGAINST('0797-12345' in boolean mode)
得到结果
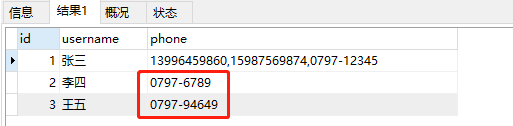
可以看到后面两条记录不是预期的结果。
也是产品经理反映的问题。
大家应该都猜到了,就是座机号的原因。嗯,用户有个座机,这很河狸嘛。

都是广义上的联系方式嘛。
看起来,这条SQL是将包含0797的数据行都返回了,但我使用的是布尔模式,要求全部匹配上0797-12345才返回。
我猜可能是’-‘导致分词的问题,将其分成了两部份。
分词器
分词就是对需要进行搜索的关键词进行拆分。MySQL最初支持全文索引时,使用的是parser (拉丁语法分词器,通过空格来分词),
如英文I am programmer ,天然可以通过空格拆分成I am programmer3个单词,这也就是前文说的英语天然没有分词的问题。
但对于像中文这类不以空格拆分词语的语言来说无法适用。
因此MYSQL5.7.6后提供了n_gram parser(字符长度分词器) ,对中文的全文索引支持更友好,分词器的使用也很简单,创建索引时添加 WITH PARSER ngram即为使用n_gram parser(字符长度分词器),不加则默认使用传统parser(拉丁语法空格分词器)。
注意字符长度分词器这几个字,故名思义,它就是按字符的长度来分词的,之所以单独提出来,是区别于基于NLP自然语义的分词,如复旦分词等。
比如我是程序员这个短句,如果按照自然语义分析来进行分词的话,它可能会分成我 是 程序 程序员等。
断不可能分出来序员。除非分词器有问题。
但n_gram parser分词器就有可能。 mysql默认分词长度为2,可在my.cnf里进行配置,ngram_token_size = 2指定分词长度。
针对不同的分词长度,我是程序员这个短句可以有以下多种分词效果。
ngram_token_size=1: '我', '是', '程', '序', '员'
ngram_token_size=2: '我是', '是程', '程序' , '序员'
ngram_token_size=3: '我是程', '是程序' , '程序员'
...
ngram_token_size=5: '我是程序员'
...
最大ngram_token_size=10
我的测试库ngram_token_size为2,加个字段简单测试一下。
单个字搜不到,因为最小分词单位为2。
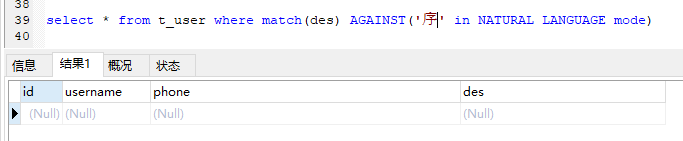
搜索程序和序员都能得到正确的结果。

以上是汉字的分词,回到今天的正题,对于阿拉伯数字呢?
如金额23.45元,手机号13912345678,座机号0797-12345678,日期2023-01-01等等。
针对上面说到的BUG,座机号0797-12345678关联出来了多个带0797但-后面不相同的号码,
我一开始以为是-的问题。它将0797-12345678分成了0797和12345678两部份。
但通过这一小节的n_gram parser的介绍,我们知道它是基于长度的分词器,那么原因肯定就不是这样的。
通过以下两句SQL可以证明它是两两拆分的。
select * from t_user where match(phone) AGAINST('7-' in NATURAL LANGUAGE mode)
select * from t_user where match(phone) AGAINST('07' in boolean mode)
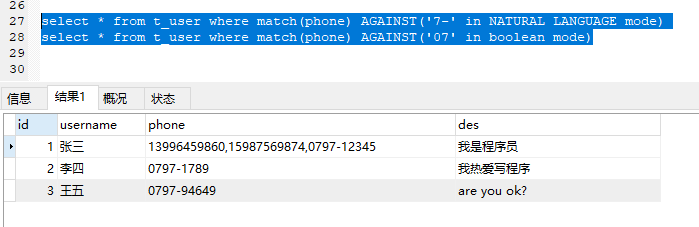
以7-和07都能将3条记录全部匹配出来。
但是在布尔模式下,7-搜索不出来。
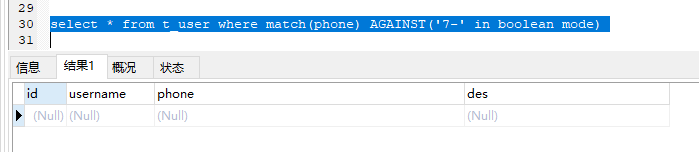
为什么呢?
这里mysql把7-中的-当成逻辑运算符了,而不是整体当作一个搜索关键词。
stopword
内置的MySQL全文解析器将单词与stopword 列表中的条目进行比较。如果一个单词在stopword列表当中,则该单词将从索引中排除。
对于ngram解析器,stopword处理的执行方式不同。ngram解析器不排除与stopword中的条目相等的令牌,而是排除包含stopword的令牌。
例如,假设ngram_token_size=2,包含a,b的文档将被解析为a,和,b。
如果逗号,被定义为stopword,则a,和,b都将从索引中排除,因为它们包含逗号。
同理,如果stopword当中包含-,同时ngram_token_size=4,那么座机号0797-1789就被拆分成两个大的部份,0797和1789。
其中 797-1 97-17 7-178 等都将被排除。
如此以上猜想成立的话,就有可能导致开头的BUG。 前提是wordstop当中包含-。
在innodb当中,stopword可以通过INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD表来查看。
可以通过此表来自定义删除或添加stopword,从而改变分词规则。
通过查看,可以发现’-‘并不在stopword当中,所以上面的猜想是错误的,并不是这个原因导致的BUG。
mysql> SELECT * FROM INFORMATION_SCHEMA.INNODB_FT_DEFAULT_STOPWORD;
+-------+
| value |
+-------+
| a |
| about |
| an |
| are |
| as |
| at |
| be |
| by |
| com |
| de |
| en |
| for |
| from |
| how |
| i |
| in |
| is |
| it |
| la |
| of |
| on |
| or |
| that |
| the |
| this |
| to |
| was |
| what |
| when |
| where |
| who |
| will |
| with |
| und |
| the |
| www |
+-------+
36 rows in set (0.00 sec)
布尔模式的逻辑运算符
mysql全文检索有两种最常用的方式。自然语言模式和布尔模式。
自然语言模式
对于自然语言模式搜索,搜索项被转换为ngram项的并集。例如,字符串abc(假设ngram_token_size=2)被转换为ab bc。给定两个文档,一个包含ab,另一个包含abc,搜索词ab bc匹配这两个文档。
可以简单的理解为,将搜索关键词再拆分,与文档进行模式匹配。
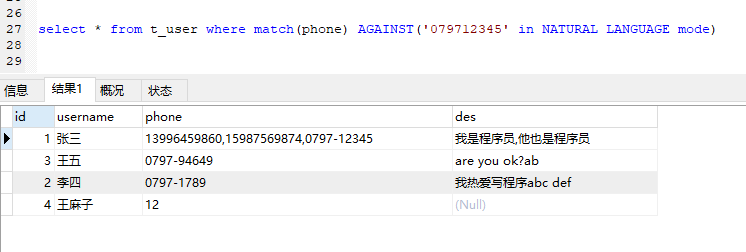
上图所示,文档中包含12和’0997’都被命中了。
布尔模式
对于布尔模式搜索,搜索项被转换为ngram短语搜索。例如,字符串abc(假设ngram_token_size=2)被转换为ab bc。给定两个文档,一个包含ab,另一个包含abc,搜索短语ab bc只匹配包含abc的文档。
可以理解为不会对关键词进行再拆分,相当于对搜索关键词进行全匹配。
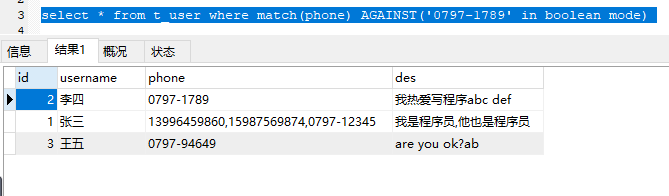
使用相同的测试数据和相当的搜索关键词,使用布尔模式搜索。
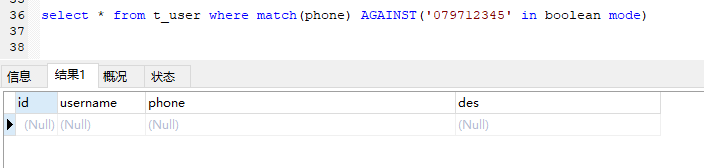
结果为空。 没有数据被命中。
但是
在布尔模式下搜索0797-12345命中了0797-94649和0797-1789。
但不会命中’07’,’09’,’12’等。
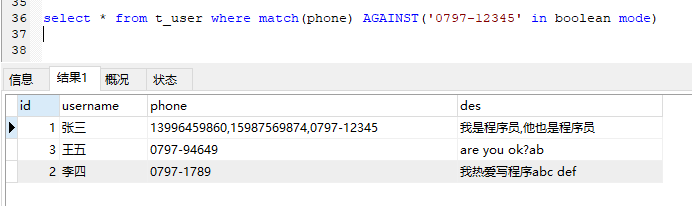
我只能解释为,布尔模式下,搜索关键词0797-12345中的’-‘被当成语法了,导致无形中被拆分成了0797和12345两部份。
但是,我从mysql官网没有找到证据。 所以此点存疑。各位看官要有自己的思考,不要被我误导!
跟上一小节当中’7-‘没有命中任何记录一样,也是布尔模式下语法的原因。
现在我们来讨论一下布尔模式下的逻辑运算符问题。
布尔模式的逻辑运算符
-
+
select * from t_user where match(phone) AGAINST('a +b' in boolean mode)
其中 + 会被识别成逻辑运算符,而不是将a +b作为一个整体,以下同理。
‘a +b’ 指’a’和’b’必须同时出现才满足搜索条件。 -
-
select * from t_user where match(phone) AGAINST('0797 -12345' in boolean mode)
0797 -12345指0797必须包含,但不包含12345才能满足搜索条件。
以下查询排除了包含0797-12345的记录。
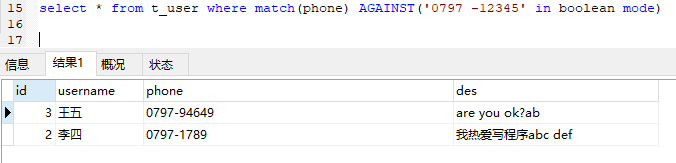
注意-前后空格0797 -12345才表示包含0797同时不包含12345.
0797-12345等于0797 - 12345,它并不等于0797 -12345。
有图为证:
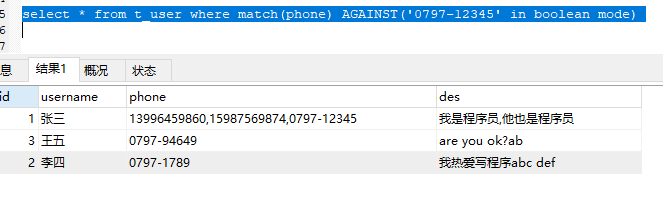
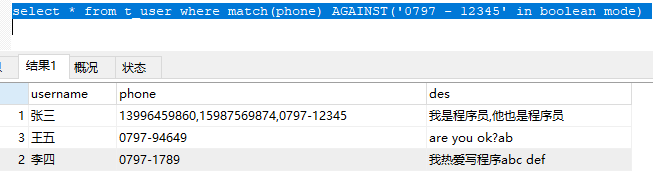
-
>
提高/降低该条匹配数据的权重值。不管使用>还是,其权重值均大于没使用其中任何一个的。
select * from t_user where match(phone) AGAINST('0797(>94649
表示匹配0797,同时包含94649的列往前排,包含12345的往后排
select * from t_user where match(phone) AGAINST('a > b' in NATURAL LANGUAGE mode)
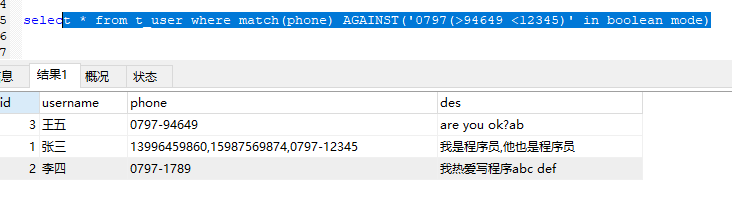
-
()
相当于表达式分组,参考上一个例子。 -
*
通配符,只能在字符串后面使用 -
"
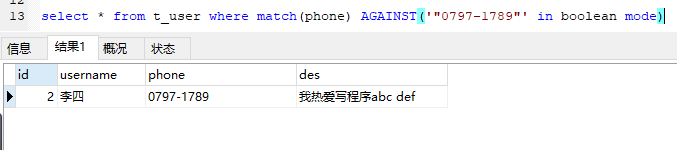
完全匹配,被双引号包起来的单词必须整个被匹配。
select * from t_user where match(phone) AGAINST('"0797-1789"' in boolean mode)
"0797-1789"中不可再分。其它包含0797-1234等记录就不再匹配。
解决方案
现在,让我们回到最初的美好。
我们遇到了一个问题,一个座机号0979-1789全文检索返回了不完全匹配的记录。
那么,想要完全匹配,需要怎么做呢。
经过上面的旅程,我们有了两种方案。
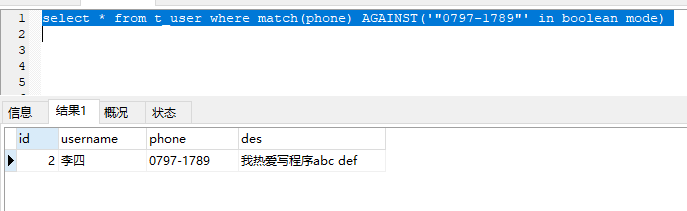
- 使用 “”
将座机号包起来,"0979-1789",表示此搜索关键词不可再分。自然就能全匹配。
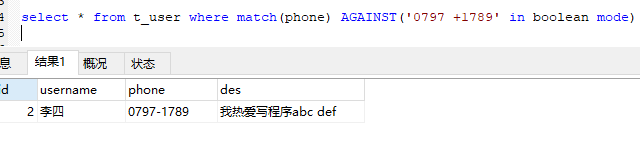
- 主动拆分,再使用+
我们知道,之所以座机号能将不完全匹配的记录查询出来,是因为将座机号当中的”-“当成了逻辑运算符,从而导致了座机号被拆分成了两部份。
那我们先主动将座机号拆分两部份,再使用逻辑运算符”+”,表示两部份都必须包含才能返回。
建议使用第一种方法。
其它的电话号码表示方法,比如区号+电话号码,023+12345678,国际长途0086-10-1234567或+86-573-82651630,610-643-4567等。
这里面涉及到+-等逻辑运算符,用第一种方法最安全。
倒排索引
全文索引即是倒排索引。
好像这种说法,在lucene或者elasticsearch更流行。
文末还是简单说一下它的原理。
传统数据库索引的方式是,【表->字段】。而倒排索引的方式是先将字段进行分词,然后将单词跟文档进行关联,变为【文档 -> 单词】,并将记录其它更为强大的信息(文档编号、词项频率、词项的位置、词项开始和结束的字符位置可以被存储)。
有两篇文章:
1 我是程序员
2 我热爱写程序
先分词(这里假设以自然语义分词)
1 【我】【是】【程序】【程序员】
2 【我】【热爱】【写】【程序】
前面文章对关键字,经倒排后变成关键字对文章
| 关键字 | 文章号 |
| 我 | 1,2 |
| 是 | 1 |
| 程序 | 1,2 |
| 程序员 | 1 |
| 热爱 | 2 |
| 写 | 2 |
为了快速定位和节省存储大小,还需要加上关键字出现频率和位置。
| 关键字 | 文章号(频率) | 位置 |
| 我 | 1(1) | 1 |
| 2(1) | 1 | |
| 是 | 1(1) | 2 |
| 程序 | 1(1) | 3 |
| 2(1) | 4 | |
| 程序员 | 1(1) | 4 |
| 热爱 | 1(1) | 1 |
| 写 | 1(1) | 3 |
如果我要对“程序”进行搜索,能就能快速定位到文档1,2,并且能直接知道它在文档当中出现了多少次,分别出现在哪里。
小结
关于分词,mysql有两种引擎,一种是基于空格的拉丁语系模式,默认就是这种。如’i love you’拆分为i love you三部份。
在5.7.6以后,针对中日韩文字内置了一种基于长度的分词器,n_gram parser。
此分词器并不区分中文和阿拉伯数字,两种文本分词的标准是一样的。
但一些特殊的文本里面带有布尔模式下的逻辑运算符(+->)的时候需要特别注意。
同时,mysql全文索引本身有很多限制,该用elasticsearch的时候也该大胆上:
1:只支持char、varchar、text类型。
2:MySQL的全文索引只有全部在内存中的时候,性能才非常好。如果内存无法装载全部索引,那么性能可能会非常慢(可以为全文索引设置单独的键缓存(key cache),保证不会被其他的索引缓存挤出内存)
3:相比其它的索引类型,当insert、update和delete操作进行时,全文索引的操作代价非常大。而且全文索引会有更多的碎片,可能需要做更多的optimize table操作。
4:全文索引优先级在索引中最高,即便这时有更合适的索引可用,MySQL也会放弃性能比较,优先使用全文索引。
5:全文索引不存储索引列的实际值,也就不可能用作索引覆盖扫描。
6:除了相关性排序,全文索引不能用作其他的排序。如果查询需要做相关性以外的排序操作,都需要使用文件排。
完
参考:
https://dev.mysql.com/doc/refman/8.0/en/fulltext-search-ngram.html
https://dev.mysql.com/doc/refman/8.0/en/fulltext-stopwords.html
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
