一、列表
1.列表的切片 [开始标签:结束标签:步长] 开始标签:结束标签是左闭右开(左包含右不包含)
下标 —-位置,默认是从0开始(从左到右)
从右到左的下标,第一个下标为-1
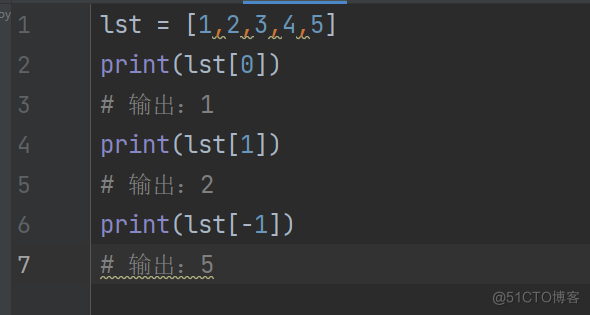
lst = [1,2,3,4,5]
print(lst[0])
输出:1
print(lst[1])
输出:2
print(lst[-1])
输出:5
切片
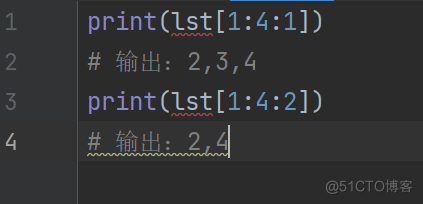
print(lst[1:4:1])
输出:2,3,4
print(lst[1:4:2])
输出:2,4
2.增
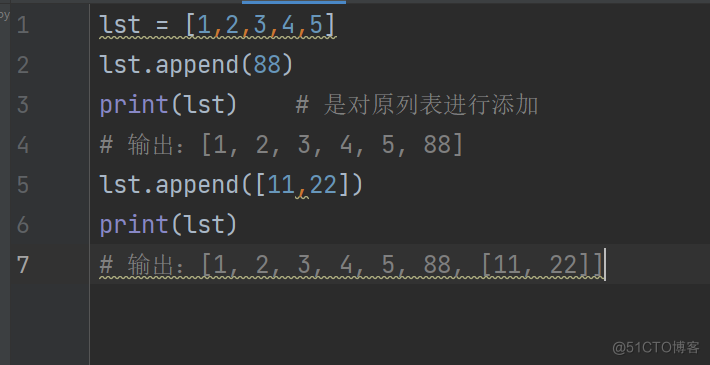
lst = [1,2,3,4,5]
lst.append(88)
print(lst) # 是对原列表进行添加
输出:[1, 2, 3, 4, 5, 88]
lst.append([11,22])
print(lst)
输出:[1, 2, 3, 4, 5, 88, [11, 22]]
-
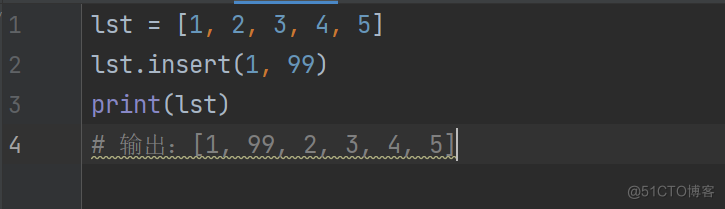
列表.insert(索引位置,插入元素) —–相当于插队
lst = [1, 2, 3, 4, 5]
lst.insert(1, 99)
print(lst)
输出:[1, 99, 2, 3, 4, 5]
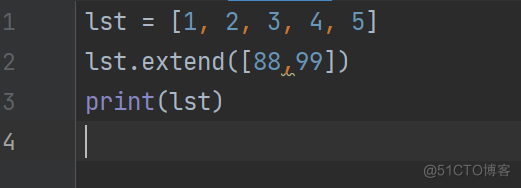
lst = [1, 2, 3, 4, 5]
lst.extend([88,99])
print(lst)
输出:[1, 2, 3, 4, 5, 88, 99]
3.删
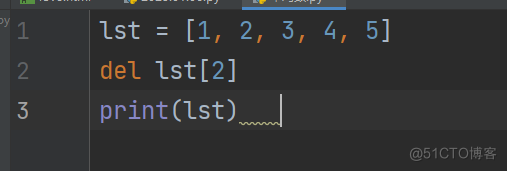
lst = [1, 2, 3, 4, 5]
del lst[2]
print(lst)
输出:[1, 2, 4, 5]
del lst
print(lst)
输出:NameError: name 'lst' is not defined
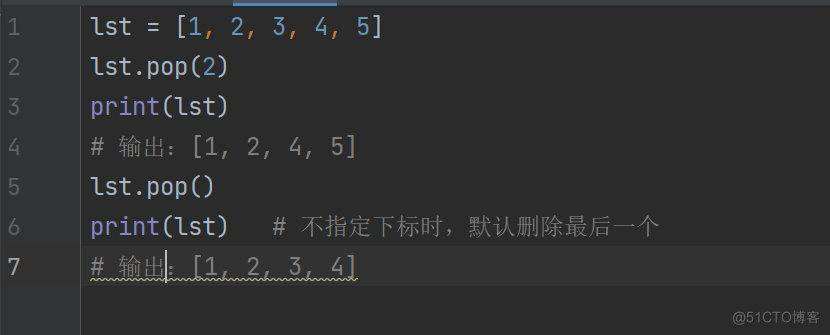
lst = [1, 2, 3, 4, 5]
lst.pop(2)
print(lst)
输出:[1, 2, 4, 5]
lst.pop()
print(lst) # 不指定下标时,默认删除最后一个
输出:[1, 2, 3, 4]
lst = [1, 2, 3, 4, 5]
lst.remove(3)
print(lst)
输出:[1, 2, 4, 5]

lst.clear()
print(lst)
输出: []
4.改
本质是通过赋值方式来实现
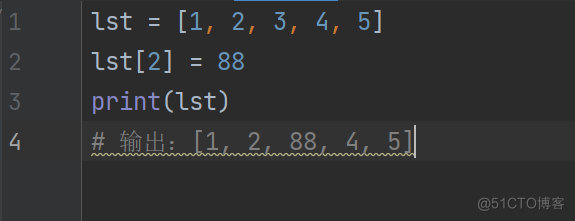
lst = [1, 2, 3, 4, 5]
lst[2] = 88
print(lst)
输出:[1, 2, 88, 4, 5]
5.查
-
列表.index(查询元素,起始位置,结束位置),找到了返回第一次出现的下标
nums = [1, 2, 3, 33, 67, -99, 2,100]
print(nums.index(2, 1, 10))
输出:ValueError: 2 is not in list

二、元组
不可变 元素不能直接修改—-增加代码安全性 —–特性
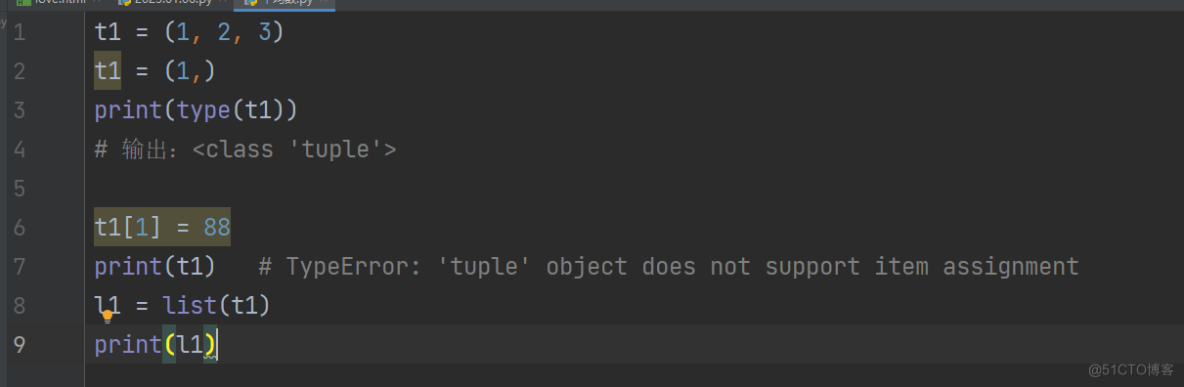
只有一个元素时,一定要添加逗号
t1 = (1,)
print(type(t1))
输出:
t1[1] = 88
print(t1) # TypeError: 'tuple' object does not support item assignment
l1 = list(t1)
print(l1)
查
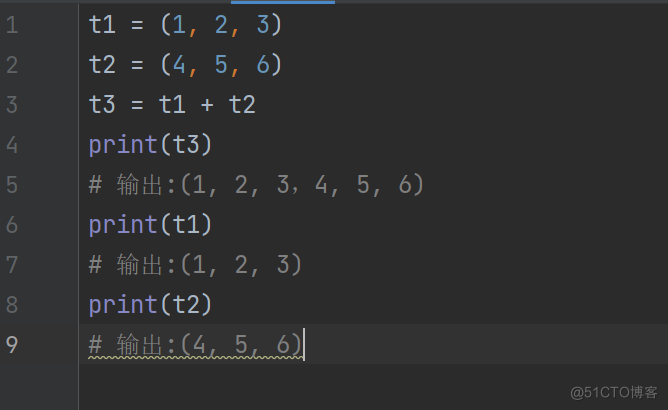
t1 = (1, 2, 3)
t2 = (4, 5, 6)
t3 = t1 + t2
print(t3)
输出:(1, 2, 3,4, 5, 6)
print(t1)
输出:(1, 2, 3)
print(t2)
输出:(4, 5, 6)
删
三、字符串
1.切片 [开始标签:结束标签:步长]
s1 = 'helloworld'
print(s1[2:5])

2.增
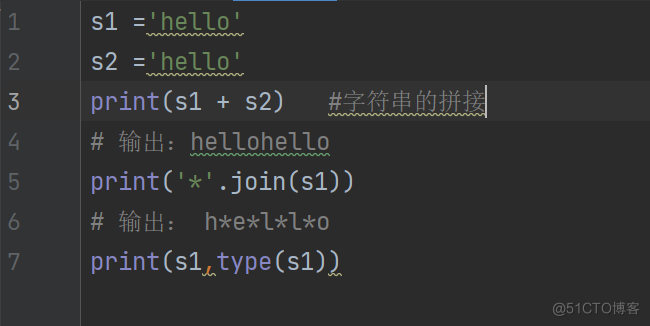
s1 ='hello'
s2 ='hello'
print(s1 + s2) #字符串的拼接
输出:hellohello
print('*'.join(s1))
输出: h*e*l*l*o
print(s1,type(s1))
3.删
-
lstrip() 删除字符串左边的空白;rstrip() 删除字符串右边的空白; strip() 删除两端空白
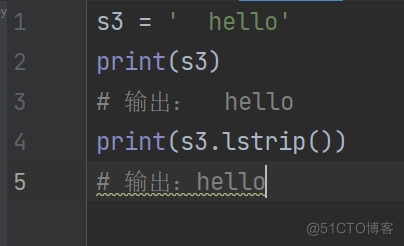
s3 = ' hello'
print(s3)
输出: hello
print(s3.lstrip())
输出:hello
4.改
- 字符串.replace(旧子串,新子串,替换次数)
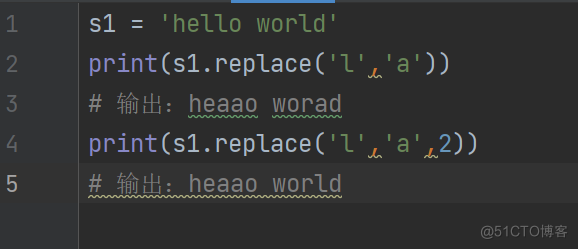
s1 = 'hello world'
print(s1.replace('l','a'))
输出:heaao worad
print(s1.replace('l','a',2))
输出:heaao world
split(分割符,分割次数)
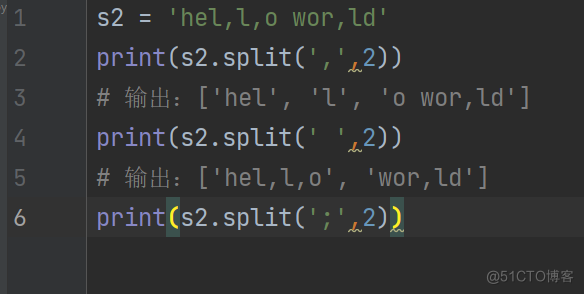
s2 = 'hel,l,o wor,ld'
print(s2.split(',',2))
输出:['hel', 'l', 'o wor,ld']
print(s2.split(' ',2))
输出:['hel,l,o', 'wor,ld']
print(s2.split(';',2))
- lower() 把所有字符小写
- upper() …大写
s1 = 'hello world'
print(s1.upper())
输出:HELLO WORLD
5.查
-
字符串.find(子串,开始下标,结束下标) 找子串,有则返回第一次找到的索引值,否则返回-1
s1 = 'hello world'
print(s1.find('h'))
print(s1.find('l',1,5))
-
字符串.index(子串,开始下标,结束下标) 找不到会报错
- count() 计数
6.判断
s3 = 'Hello WoRLD'
print(s3.islower())
- isupper() 判断是否都是由大写组成
- isdigit() 判断是否都是由数字组成
- startswith() 判断是否以……开头
print(s3.startswith('H'))
输出:True
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net

