
近日,袋鼠云大数据引擎专家郝卫亮,为大家带来了《袋鼠云在实时数据湖上的探索与实践》主题分享,帮助大家能了解到什么是实时数据湖、如何进行数据湖选型及数据平台建设数据湖的经验。

如今,大规模、高时效、智能化数据处理已是“刚需”,企业需要更强大的数据处理能力,来应对数据查询、数据处理、数据挖掘、数据展示以及多种计算模型并行的挑战。
因此,袋鼠云基于自研的一站式大数据基础软件——数栈提出相应的实时数据湖解决方案,能够兼容Iceberg、Hudi等数据湖平台。实时数据湖提供了多样化的分析能力,而不限于批处理、流处理、交互式查询和机器学习;提供了ACID事物能力,可以更好的保障数据质量;提供了完善的数据管理能力,包括数据格式、数据schema等;此外,实时数据湖还提供了存储介质可扩展的能力,支持HDFS、对象存储等。从而大大节省了数据存储成本、提升了开发效率,能够更快更好地挖掘数据价值。

该方案特点在于CDC数据实时入湖,能够保障技术自主可控、全增量一体化、分钟级时延、链路短、对业务稳定性无影响。
• 实时性高:CDC数据对实时性要求高,数据新鲜度越高,往往业务价值越高
• 历史数据量大:数据库的历史数据规模大
• 强一致性:数据处理必须要服务器托管网保证有序性而且结果需要一致性
• Schema动态演进:数据库对应的Schema会随着业务不断变更

在实时入湖落地过程中,研发团队也遇到了诸如小文件影响读写效率;客户群体使用的Flink版本大多还停留在1.12;因此需Hudi适配Flink1.12;存在多套Hadoop集群的场景下存在跨集群的需求等问题,最终都一一克服,提供了完美的解决方案。
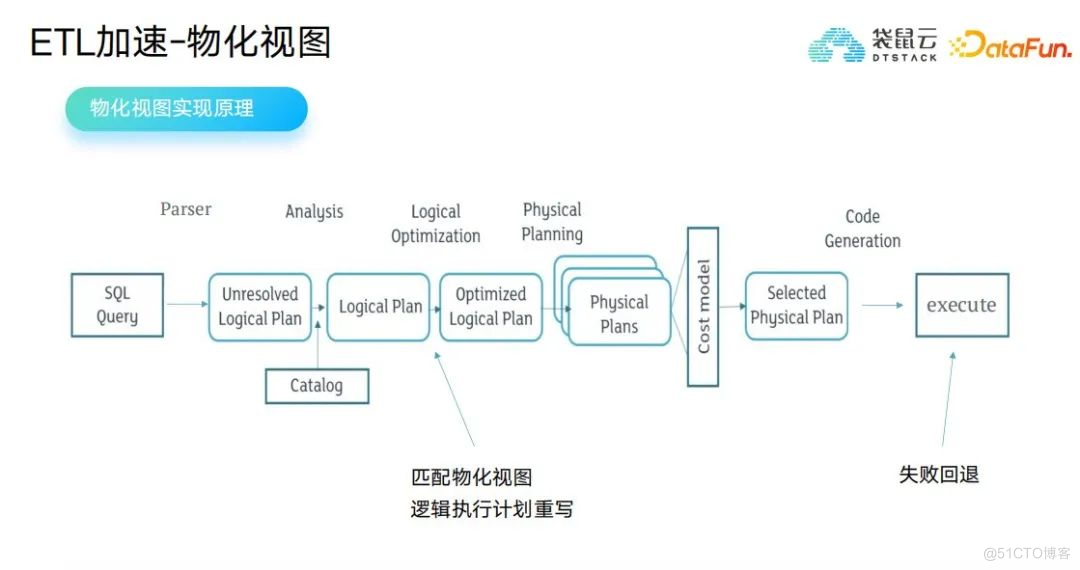
在实时数据湖中包含实时ETL、离线ETL、OLAP三类任务,这三类任务在从ODS层到ADS层加工的过程中,聚合操作越来越多,IO越来越密集,多个任务SQL中具有相同逻辑的SQL片段。为此,技术团队探索出了物化视图的方案,完成平台化数据湖物化视图管理,Spark、Trino、Flink支持基于数据湖表格式管理物化视图。
在实时数据湖中基于数据湖构建的物化视图可实现流、批和OLAP任务之间共享,从而进一步降低实时数据湖中数据在整条链路中的延时,从而节省计算成本。
未来,实时数据湖方案还将持续优化,不断增加平台湖表管理服务器托管网的易用性;引入Paimon,让数栈支持对接Paimon、增加基于Paimon的湖仓一体建设;深入并增强内核,提升入湖的的性能;数据湖提供数据共享、支持多引擎,探索数据湖的安全管理方案。
获取完整PPT:https://www.dtstack.com/resources/1051?src=szsm
想了解更多详情,可点击观看视频讲解:https://www.bilibili.com/video/BV1Yu411w7uc/?spm_id_from=333.999.0.0&vd
《数据治理行业实践白皮书》下载地址:https://fs80.cn/380a4b
《数栈V6.0产品白皮书》下载地址:https://fs80.cn/cw0iw1
想了解或咨询更多有关袋鼠云大数据产品、行业解决方案、客户案例的朋友,浏览袋鼠云官网:https://www.dtstack.com/?src=sz51cto
同时,欢迎对大数据开源项目有兴趣的同学加入「袋鼠云开源框架钉钉技术qun」,交流最新开源技术信息,qun号码:30537511,项目地址:https://github.com/DTStack
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
导读: 在万物云原生下的环境下,Java的市场份额也因耗资源、启动慢等缺点,导致在云原生环境里被放大而降低,通过这篇文章,读者可以更好地了解如何在云原生环境下通过升级相关版本和使用GraalVM打出原生镜像到方式,优化Java应用的性能和资源利用率,使Java…
