
写在前面
模块化开发是我们日常工作潜移默化中用到的基本技能,发展至今非常地简洁方便,但开发者们(指我自己)却很少能清晰透彻地说出它的发展背景, 发展过程以及各个规范之间的区别。故笔者决定一探乾坤,深入浅出学习一下什么是前端模块化。
通过本文,笔者希望各位能够收获到:
- 前端模块化发展的大致历史背景 🌟
- 各个规范之间的基本特性和区别 🌟🌟
- 着重深入 ESM 和 CommonJs 的异同、优缺点 🌟🌟🌟
- 深耕 CommonJS 和 ESM 的特性 🌟🌟🌟🌟
本文的重点会以大家熟知的 CommonJS 和 ESM 入手,深入浅出,结合示例 Demo 和一些小故事,希望给大家能够带到不一样的体验。
一、前端模块化背景
某个技术的起源几乎都是为了解决一些棘手的问题,模块化也不例外。下面以一个简单的例子来给大家讲个故事,通过故事给大家讲一讲大致的发展史。故事并未涵盖所有时间线上发生的事件,众所周知在前端模块化的长河里 AMD 和 CMD 一直打的不可开交,这里笔者挑选以 CMD 为支线向大家阐释。
本故事的攥写参考了部分 Sea.js 开源大佬发表在《程序员》杂志 2013 年 3 月刊的文章 (侵删)
在线链接:前端模块化开发的价值 ,本文推荐大家仔细阅读,包括评论区。
故事开始! 在很久之前(可能就是2012年之前),JS 模块化概念并未诞生的年代,前端开发们面临诸多问题:Web 技术虽说日益成熟、JS 能实现的功能也愈发地多,但与此同时代码量也是越来越大。那个年代往往会出现一个项目各个页面公用同一个 JS 的情况,为了解决这个情况,JS 文件出现了按功能拆分….
慢慢地,项目代码变成了如下:
...
...
...
拆分出来的代码类似于如下:
function mapList(list) {
// 具体实现
}
function canBuyIt(goodId) {
// 具体实现
}
看似拆分很细,但却有诸多的致命问题:
- 全局变量污染:各个文件的变量都是挂载到window对象上,污染全局变量;
- 变量可能重名:不同文件中的变量如果重名,后一份会覆盖前面的,造成错误;
- 文件依赖顺序:多个文件之间存在依赖关系,需要保证一定加载顺序问题严重……
拿上述 util 工具函数文件举例! 大家按规范模像样地把这些函数统一放在 util.js 里,需要用到时,直接引入该文件就好,非常方便。随着团队项目越来越大,问题随之越来越多:
空山:我想定义 mapList 方法遍历商品列表,但是已经有了,很烦,我的只能叫 mapGoodsList 了。
空河:我自定义了一个 canBuyIt 方法,为什么使用的时候,空山的代码出问题了呢?
满山:我明明都用了空山的方法,为什么结果还是不对呢?
经过团队激烈讨论,决定参照 Java 的方式,用 命名空间 来解决,于是乎代码变成了如下:
// 这是新的 Utils.js 文件
var userObj = {};
userObj.Auth = {};
userObj.Auth.Utils = {};
userObj.Auth.Utils.mapGoodsList = function (list) {
// 实现
};
userObj.Auth.Utils.canBuyIt = function (goodId) {
// 实现
};
现在通过命名空间的方式极大地解决了一部分冲突,但是仔细看上面的代码,如果开发人员想要调用某一个简单的方法,就需要他有强大的记忆力,个人负担变得很重。(这里值得提一嘴的是,Yahoo 的前端团队 YUI 采用了命名空间的解决方式,同时也通过利用沙箱机制很好的解决了命名空间过长的问题,有兴趣的同学可以自行了解)
书接上回。大家现在可以基于 util.js 开发各自的 UI 层通用组件了。举一个大佬写的 dialog.js 组件
可是无论大佬怎么写文档,以及多么郑重地发邮件宣告,时不时总会有同事询问为什么 dialog.js 有问题。通过一番排查,发现导致错误的原因经常是在 dialog.js 前没有引入 util.js。这样的问题和依赖依然还在可控范围内,但是当项目越来越复杂,众多文件之间的依赖经常会让人抓狂。下面这些问题,在当时每天都在真实地发生着:
- 通用组更新了前端基础类库,却很难推动全站升级。
- 业务组想用某个新的通用组件,但发现无法简单通过几行代码搞定。
- 一个老产品要上新功能,最后评估只能基于老的类库继续开发。
- 公司整合业务,某两个产品线要合并。结果发现前端代码冲突。
- ……
以上很多问题都是因为 文件依赖 没有很好的管理起来。在前端页面里,大部分脚本的依赖目前依旧是通过人肉的方式保证。当团队比较小时,这不会有什么问题。当团队越来越大,公司业务越来越复杂后,依赖问题如果不解决,就会成为大问题。文件的依赖,目前在绝大部分类库框架里,比如国外的 YUI3 框架、国内的 KISSY 等类库,目前是通过配置的方式来解决。抛一个例子,不深究。
YUI.add('my-module', function (Y) {
// ...
}, '0.0.1', {
requires: ['node', 'event']
});
上面的代码,通过 requires 等方式来指定当前模块的依赖。这很大程度上可以解决依赖问题,但不够优雅。当模块很多,依赖很复杂时,烦琐的配置会带来不少隐患。解决命名冲突和文件依赖,是前端开发过程中的两个经典问题,大佬们希望通过模块化开发来解决这些问题,所以 Sea.js 营运而生,再往后,CMD 规范也就水到渠成地形成了。(准确说来是因为先有了优秀的 Sea.js,才在后续更替过程逐渐形成了我们后来人所学习到的 CMD 规范。 )
故事讲到这里要告一段落了,是时候给大伙来个评书总结了。JS 在设计上其实并没有 模块 的概念,为了让 JS 变成一个功能强大的语言,业界大佬们各显神通,定了一个名为 CommonJS 的规范,实现了一个名为模块 的东西。但可惜当时环境下大多浏览器并不支持,只能用于 node.js,于是 CommonJS 开始分裂,变异了一个名为 AMD 规范的模块,可以用于浏览器端。由于 AMD 与 CommonJS 规范相去甚远,于是 AMD 自立门户,并且推出了 require.js 这个框架,用于实现并推广 AMD 规范。此时,CommonJS 的拥护者认为,浏览端也可以实现 CommonJS 的规范,于是稍作改动,推出了 sea.js 这个框架并形成了 CMD 规范。。
正在 AMD 与 CMD 打得火热的时候,ECMAScript6 给 JS 本身定了一个模块加载的功能,弯道超车:“你们俩别争了,JS 模块有原生的语法了”。
再后来,正因为 AMD 与CommonJS 如此不同,且用于不同的环境,为了能够兼容两个平台,UMD 就应运而生了,不过它仅仅是一个 polyfill,以兼容两个平台而已,严格意义上来说不能成为一种标准规范。

至此,大致历史背景已讲述完毕,上文出现的各大规范名词,接下来会跟大家见面。
二、模块化规范介绍
大致了解背景之后,接下来认真地跟各位探讨一下各大规范。
开始之前,想说明一下,针对于 AMD 和 CMD,笔者不打算带各位做源码级别的深究,笔者希望大家只是做一个了解或回顾,随后将重心放至第三、四章的 CommonJS 和 EMS 中。
老大哥 CommonJS
介绍
2009年,美国程序员 Ryan_Dahl 创造了 node.js 项目,将 JS 用于服务器端编程。这标志《 JS 模块化编程》正式诞生。不同于纯前端的服务器端,是一定要有模块的概念的,它与操作系统或其他应用程序有着各种各样的互动,否则编程会大受限制,甚至根本无法编程。
Node.js 后端编程中最重要的思想之一就是 “模块” ,正是这个思想,让 JavaScript 的大规模工程成为可能。也是基于此,随后在浏览器端,require.js 和 sea.js 之类的工具包也出现了;在 ES module 被完全实现之前,CommonJs 统治了之前时代模块化编程的大半江山,它的出现也弥补了当时 JS 对于模块化没有统一标准的缺陷。
简单举例 🌰
在 CommonJS 中, 模块通常使用 module.exports 和 exports,有一个全局性方法 require(),用于加载模块,如下:(module.exports 和 exports 后文有做阐述,此处暂且不表)
// 导出 a.js
module.exports = function sumIt(a,b){
return a + b
}
// 引入 main.js
const sumIt = require('./a.js');
console.log('sumIt===', sumIt(1,2));
AMD 自立门户
简介
AMD — Asynchronous Module Definition(异步模块定义)。它诞生于 Dojo 在使用 XHR+eval 时的实践经验,其支持者希望未来的解决方案都可以免受由于过去方案的缺陷所带来的麻烦。由于 CommonJS 奠定了服务器模块规范,大家便开始考虑客户端模块,而且想两者可以兼容,让一个模块可以同时在服务器和浏览器运行。
但是 CommonJS 是同步加载模块,服务器所有模块都存放在本地,硬盘读取时间很快,但对于浏览器来说,等待时间则取决于网速的快慢,如果时间过长,浏览器可能会处于“假死”。例如刚刚 main.js 的代码,当我们调用 sumIt(1,2) 的时候, 浏览器需要等待 a.js 加载完才能进行计算,所以浏览器端的模块化使用同步加载是有缺陷的,需用异步加载取代之,这也就是 AMD 规范诞生的背景。
AMD 采用异步方式加载模块,让模块的加载不影响它后面语句的运行。所有依赖这个模块的语句,都定义在一个回调函数中,等到加载完成之后,这个回调函数才会运行。
AMD 规范详览看这里
AMD 模块的设计模式请看这里
简单举例 🌰
define(id?, dependencies?, factory)
// id: 字符串,模块名称(可选)
// dependencies: 表示需要加载的依赖模块(可选)
// factory: 工厂方法,返回一个模块函数,也可理解为加载成功后的回调函数
//引入依赖 ,回调函数通过形参传入依赖
define(['Module1', ‘Module2’], function (Module1, Module2) {
function testIt () {
/// 业务代码
Module1.test();
}
return testIt
});
require([module],callback())
define(function (require, exports, module) {
var yourModule = require("./yourModule");
yourModule.test();
exports.yourKey = function () {
//...
}
});
不难发现,AMD 的优点是适合在浏览器环境中异步加载模块。可以并行加载多个模块。
而缺点是提高了开发成本,并且不能按需加载,而是必须提前加载所有的依赖。
CMD — 简单纯粹
简介
Common Module Definition 背景有讲,不多赘述,Sea.js 在推广中对模块定义的规范化产出,推崇依赖就近,延迟执行
简单举例 🌰
//AMD
define(['./a','./b'], function (a, b) {
//依赖一开始就写好
a.xxx();
b.xxx();
});
//CMD
define(id?, function (requie, exports, module) {
// 依赖可以就近书写
var a = require('./a');
a.xxx();
// 软依赖
if (status) {
var b = requie('./b');
b.xxx();
}
});
// require 是一个方法,用来获取其他模块提供的接口
// exports 是一个对象,用来向外提供模块接口
// module 是一个对象,上面存储了与当前模块相关联的一些属性和方法
CMD 规范看这里
AMD 和 CMD 对比
- 对于依赖的模块 AMD 是 提前执行,CMD 是 延迟执行。不过 Require.js 从2.0开始,也改成可以延迟执行(根据写法不同,处理方式不通过)。
- AMD 推崇 依赖前置(在定义模块的时候就要声明其依赖的模块),CMD 推崇 依赖就近(只有在用到某个模块的时候再去 require —— 按需加载)。
- AMD 的 api 默认是一个当多个用,CMD 严格的区分推崇职责单一。例如:AMD 里 require 分全局的和局部的。CMD 里面没有全局的 require, 提供 seajs.use() 来实现模块系统的加载启动。CMD 里每个API 都更简单纯粹。引用一下玉伯 2012 年的自评:

简谈下 — UMD
网络上关于 UMD (Universal Module Definition) 通用模块规范的说法五花八门,这里笔者不做任何评论,只做一个通用型认知的总结: UMD 像一种 polyfill,兼容支持多个模块规范。
参考引用:点这里可以看一下娜娜关于 UMD 的解释
UMD 理念、规范等官方资料: https://github.com/umdjs/umd
看一个简单的例子:
output: {
path: path.join(__dirname),
filename: 'index.js',
libraryTarget: "umd",//此处是希望打包的插件类型
library: "Swiper",
}
看一下打包之后:
!function(root,callback){
"object"==typeof exports&&"object"==typeof module?//判断是不是nodejs环境
module.exports=callback(require("react"),require("prop-types"))
:
"function"==typeof define&&define.amd?//判断是不是requirejs的AMD环境
define("Swiper",["react","prop-types"],callback)
:"object"==typeof exports?//相当于连接到module.exports.Swiper
exports.Swiper=callback(require("react"),require("prop-types"))
:
root.Swiper=callback(root.React,root.PropTypes)//全局变量
}(window,callback)
新大哥 ESM
使用 Javascript 中一个标准模块系统的方案。
在此之前的时期,社区在经历了 AMD 和 CMD 洗礼后提出了一种想法:既然都是 JS 规范,Node.js 模块能被浏览器环境下的 JS 代码随意引用吗?能! 本着这个想法,ES6 (ECMAScript 6th Edition, 后来被命名为 ECMAScript 2015) 于 2015年6月17日 横空出世,主要被人熟知的其中一个特性就是 es6 module, 下文简称为 ESM。具体深耕内容请详见第四章,在此介绍章节不过多赘述。
import React from 'react';
import { a, b } from './myPath';
......
export default {
function1,
const1,
a,
b
}
- 在很多现代浏览器可以使用
- 它兼具两方面的优点:具有 CJS 的简单语法和 AMD 的异步
- 得益于 ES6 的静态模块结构,可以进行 Tree Shaking
- ESM 允许像 Rollup 这样的打包器删除不必要的代码,减少代码包可以获得更快的加载
- 可以在 HTML 中调用,如下
三、CommonJS 的深耕
CJS 的简单使用
先看一个简单的 Demo:
let str = 'a文件导出'
module.exports = function logIt (){
return str
}
const logIt = require('./a.js')
module.exports = function say(){
return {
name: logIt(),
sex: 1
}
}
以上便是 CJS 最简单的实现,那么现在我们要带着问题了:
- module.exports,exports 的本质区别是什么?🤔🤔🤔
- require 的加载设计是怎样的?🤔🤔🤔
- CJS 的优缺点和与 ESM 的异同是什么?🤔🤔🤔
CJS 的实现原理
每个模块文件上存在 module,exports,require 三个变量(在 nodejs 中还存在 __filename 和 __dirname 变量),然而这几个变量是没有被定义的,但是我们可以在 Commonjs 规范下每一个 JS 模块上直接使用它们。
- module 记录当前模块信息。
- require 引入模块的方法。
- exports 当前模块导出的属性
- __dirname 在 node 中表示被执行 js 文件的绝对路径
- __filename 在 node 中表示被执行 js 文件的文件名
在编译过程中,Commonjs 会对 JS 的代码块进行包装, 以上述的 b.js 为 🌰,包装之后如下:
(function(exports,require,module,__filename,__dirname){
const logIt = require('./a.js')
module.exports = function say(){
return {
name: logIt(),
sex: 1
}
}
})
如何执行包装的呢? 让我们来看看包装函数的本质:
function wrapper (script) {
return '(function (exports, require, module, __filename, __dirname) {' +
script +
'n})'
}
// 然后是包装函数的执行
const modulefunction = wrapper(`
const logIt = require('./a.js')
module.exports = function say(){
return {
name: logIt(),
sex: 1
}
}
`)
script 为我们在 js 模块中写的内容,最后返回的就是如上包装之后的函数。当然这个函数暂且是一个字符串。在模块加载的时候,会通过 runInThisContext (可以理解成 eval ) 执行 modulefunction ,传入require ,exports ,module 等参数。最终我们写的 node.js 文件就执行了。(真实的 runInThisContext 函数执行思路和上述一致,但实现细节不一样)
runInThisContext(
modulefunction
)(module.exports, require, module, __filename, __dirname)
实现详情请参照官方文档: runInThisContext 的官方文档和示例
到此,整个模块执行的原理大致梳理完毕。🎉🎉
require 的文件加载流程
先以 node.js 为例,看一个简单的代码片段
const fs = require('fs');
const say = require('./b.js');
const moment = require('moment');
先对文件模块做一个简单的分类:
- fs 为 nodejs 底层的核心模块,其他常见的还有 path、http 模块等;
- b.js 为我们编写的文件模块;
- ./ 和 ../ 作为 相对路径 的文件模块, / 作为 绝对路径 的文件模块。
- moment 为自定义模块,其他常见的还有 crypto-js 等;像此类非路径形式也非核心的模块,将作为自定义模块。
当 require 方法执行的时候,接收的唯一参数作为一个 标识符
CJS 下对不同的标识符处理流程不同,但是目的都是找到对应的模块。
require 标识符加载原则
此章节借鉴了 @我不是外星人 的优秀文章中的部分内容(侵删)
在线链接:《深入浅出 Commonjs 和 Es Module》
笔者在巨人的肩膀上做了一些 Curd 润色,供大家享用 😄
- 缓存加载:已经被加载过一次的模块,会被记录放入缓存中;
- 核心模块:优先级仅次于 缓存加载,在 Node 源码编译中,已被编译成二进制代码,所以加载核心模块速度最快;
- 路径模块:已 ./ ,../ 和 / 开始的标识符,会被当作文件模块处理。require() 方法会将路径转换成真实路径,并以真实路径作为索引,将编译后的结果放入缓存,方便二次加载。
- 自定义块:在当前目录下的 node_modules 目录查找。如果没有,在父级目录的 node_modules 查找…… 直到根目录下的 node_modules 目录为止。在查找过程中,会找 package.json 下 main 属性指向的文件,如果没有 package.json ,在 node 环境下会以此查找 index.js ,index.json ,index.node。
- 从 Node.js 12+ 起,加载第三方模块时,exports 字段优先级比 main 字段要高
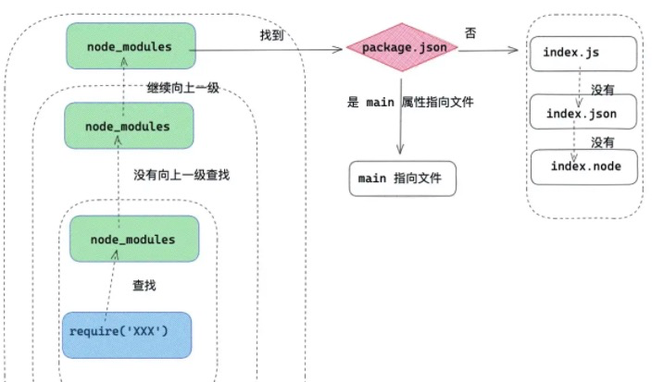
require 模块引入与处理
CommonJS 模块同步加载并执行模块文件,CommonJS 模块在执行阶段分析模块依赖
const logIt = require('./b');
console.log('我是 a 文件');
exports.say = function(){
const message = logIt();
console.log(message);
}
const say = require('./a');
const obj = {
name:'b 文件的 object 的 name',
author:'b 文件的 object 的 author'
}
console.log('我是 b 文件');
module.exports = function(){
return obj
}
const a = require('./a');
const b = require('./b');
console.log('我是 main 文件');
运行一下:
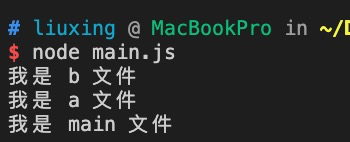
🤔️🤔️🤔️ 问题:
- main.js 和 a.js 模块都引用了 b.js 模块,但是 b.js 模块为什么只执行了一次?
- a.js 模块 和 b.js 模块互相引用,但是为什么没有循环引用报错?
我们先引入一个上文并未提及的概念:Module 和 module
module :在 Node 中每一个 js 文件都是一个 module ,module 上保存了 exports 等信息之外,
还有一个 loaded ( boolean 类型)表示该模块是否已经被加载过。
Module :以 nodejs 为例,整个系统运行之后,会用 Module 缓存每一个模块加载的信息。
然后,在回答上述思考问题之前,一起来看一下阮一峰老师关于 require 的源码解读:
// id 为路径标识符
function require(id) {
/* 查找 Module 上有没有已经加载的 js 对象*/
const cachedModule = Module._cache[id]
/* 如果已经加载了那么直接取走缓存的 exports 对象 */
if(cachedModule){
return cachedModule.exports
}
/* 创建当前模块的 module */
const module = { exports: {} ,loaded: false , ...}
/* 将 module 缓存到 Module 的缓存属性中,路径标识符作为 id */
Module._cache[id] = module
/* 加载文件 */
runInThisContext(wrapper('module.exports = "123"'))
(module.exports, require, module, __filename, __dirname)
/* 加载完成 *//
module.loaded = true
/* 返回值 */
return module.exports
}
代码还是非常容易理解的,解读总结如下:
require 会接收一个参数(文件标识符),然后分析定位文件(上一小节已经讲到),接下来从 Module 上查找有没有缓存,如果有缓存,那么直接返回缓存的内容。
如果没有缓存,会创建一个 module 对象,缓存到 Module 上,然后执行文件;加载完文件,将 loaded 属性设置为 true ,然后返回 module.exports 对象。
模块导出其实跟 a = b 赋值一样:基本类型导出的是值, 引用类型导出的是引用地址。(exports 和 module.exports 持有相同引用,后文会专门解读)
require 避免循环引用
我们先来分析刚刚的例子,下面先用一幅图来表示 a.js 的加载流程:
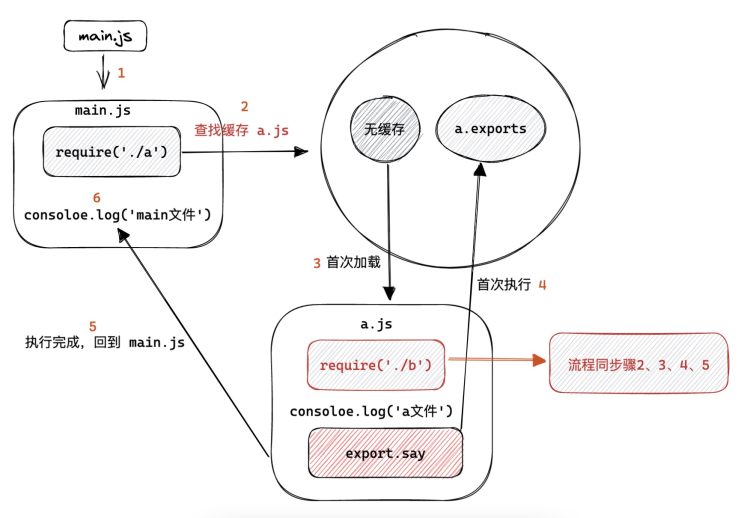
理解了这幅流程图后,再来看完整的流程图就不再吃力了:
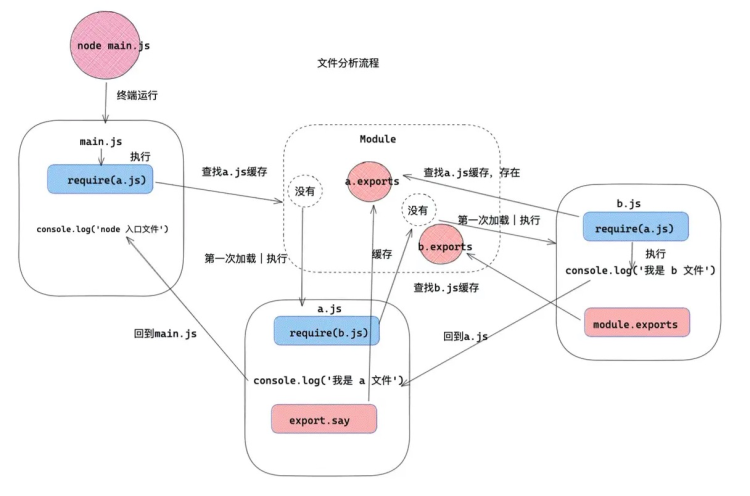
此时我们需要注意一点:
当我们第一次执行 b.js 模块的时候,a.js 还没有导出 say 方法,所以此时在 b.js 同步上下文中,是获取不到 say 的,那么如果想要获取 say ,办法有两个:
异步加载
const say = require('./a');
const obj = {
name:'b 文件的 object 的 name',
author:'b 文件的 object 的 author'
}
console.log('我是 b 文件');
setTimeout(()=>{
console.log('异步打印 a 模块' , say)
},0)
module.exports = function(){
return obj
}
动态加载
console.log('我是 a 文件');
exports.say = function(){
const logIt = require('./b');
const message = logIt();
console.log(message);
}
const a = require('./a');
a.say();
由此我们可见:
require 本质上就是一个函数,那么函数可以在任意上下文中执行,自由地加载其他模块的属性方法。
require 避免重复加载
正如上述所言,加载之后的文件的 module 会被缓存到 Module 上,比如一个模块已经 require 引入了 a 模块,如果另外一个模块再次引用 a ,那么会直接读取缓存值 module ,所以无需再次执行模块。
对应 demo 片段中,首先 main.js 引用了 a.js ,a.js 中 require 了 b.js。 此时 b.js 的 module 放入缓存 Module 中,接下来 main.js 再次引用 b.js ,那么直接走的缓存逻辑,所以 b.js 只会执行一次,也就是在 a.js 引入的时候,由此就避免了重复加载。
🤔🤔🤔🤔🤔🤔 这里给大家抛一个思考问题:
// a.js
const b = require('./b');
console.log('我是 a 文件',b);
const tets = Object.getPrototypeOf(b);
tets.aaa = 'new aaa test';
// b.js
console.log('我是 b 文件');
module.exports = {
str: 'bbbb'
}
// main.js
require('./a');
const b = require('./b');
console.log('b===', b);
console.log('proto===', Object.getPrototypeOf(b));
🤔🤔🤔 看完这个事例,你有什么启发吗?是不是和第三方侵入式的工具库很像呢?
exports 和 module.exports
module.exports 和 exports 在一开始都是一个空对象 { },但实际上,这两个对象应当是指向同一块内存的。在不去改变它们指向的内存地址的情况下,module.exports 和 exports 几乎是等价的。
require 引入的对象本质上其实是 module.exports 。那么这就产生了一个问题,当 module.exports和 exports 指向的不是同一块内存时,exports 的内容就会失效。
module.exports = { money: '20块 😭' };
exports.money = '一伯万!!!😊';
这时候,require 真实得到的是 { money: ’20块 😭’ } 。当他们二者 同时存在 的时候,会发生覆盖的情况,所以我们通常最好选择 exports 和 module.exports 两者之一。
- 思考问题1: 上述例子使用 exports = { money: ‘200’ } 这种形式赋值对象可以吗?
答:不可以。通过上述讲解都知道 exports , module 和 require 作为形参的方式传入到 js 模块中。我们直接 exports = { } 修改 exports ,等于重新赋值了形参,但是不会在引用原来的形参。举个例子:
function change(myName){
return myName.name = {
name: '老板'
}
}
let myName = {
name: '小打工人'
}
fix(myName);
console.log(myName);
- 简单来说 module.exports 是给 module 里面的 exports 属性赋值,值可以是任何类型;
- exports 是个对象,用它来暴露模块信息必须给它添加对应的属性;
- 需要注意的是:module.exports 当导出一些函数等非对象属性的时候,也有一些风险,就比如循环引用的情况下。对象会保留相同的内存地址,就算一些属性是后绑定的,也能通过异步形式访问到。
四、ES Module 的深耕
导入和导出
// 导出 a.js
const name = 'jiawen';
const game = 'lol';
const logIt = function (){
console.log('log it !!!')
}
export default {
name,
author,
logIt
}
// 引入 main.js
import { name , author , logIt } from './a.js'
// 对于引入默认导出的模块,可以自定义名称。
import allInfo from './a.js'
对于 ESM 规范中混合导出方式,日常使用,这里不再做举例。
提一下 “重署名导入和重定向导出”:
import { name as newName , say, game as newGame } from '/a.js';
console.log( newName , newGame , say );
export * from 'module'; // 1
export { name, author, ..., say } from 'module'; // 2
export { name as newName , game as newGame , ..., say } from '/a.js'; // 3
只运行,不关心导入:
import '/a.js'
动态导入:
import asyncComponent from 'dt-common/src/utils/asyncLoad';
let lazy = (async, name) => {
return asyncComponent(
() => async.then((module: any) => module.default), { name }
)
}
const ApiManage = lazy(import('./views/dataService/apiManage'), 'apiManage');
- 动态导入 import(‘xxx’) 返回一个 Promise. 使用时可能需要在 webpack 中做相应的配置处理。
ESM 的静态语法
- ES6 module 的引入和导出是静态的,import 会自动提升到代码的顶层。静态的语法意味着可以在编译时确定导入和导出,更加快速的查找依赖,可以使用 lint 工具对模块依赖进行检查,可以对导入导出加上类型信息进行静态的类型检查。
- import , export 不能放在块级作用域或条件语句中。(错误示范就不再举例了)
- import 的导入名不能为字符串或在判断语句中,不可以用模版字符串拼接的方式。
ESM 的执行特性
- 使用 import 导入的模块运行在严格模式下
- 使用 import 导入的变量是只读的。(可以理解默认为 const 装饰,无法被赋值)
- 使用 import 导入的变量是与原变量绑定/引用的,可以理解为 import 导入的变量无论是否为基本类型都是引用传递,请看下面的例子:
// js中 基础类型是值传递
let a = 1;
let b = a;
b = 2;
console.log(a, b) // 1 2
// js中 引用类型是引用传递
let a = { name: 'xxx' };
let b = obj
b.name = 'bbb'
console.log(a.name, b.name) // bbb bbb
// a.js
export let a = 1
export function add(){
a++
}
// main.js
import { a, add } from './a.js';
console.log(a); //1
add();
console.log(a); //2
ESM 的 import ()
刚刚已经举过 import () 在 TagEngine 里实际应用的例子,其核心在于返回一个 Promise 对象, 在返回的 Promise 的 then 成功回调中,可以获取模块的加载成功信息。下面举一些 import () 的社区常用:
- Vue 中的懒加载:
[
...
{
path: 'home',
name: '首页',
component: ()=> import('./home') ,
},
...
]
- React 中的懒加载
const LazyComponent = React.lazy(() => import('./text'));
class index extends React.Component {
render() {
return (
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
