
一、通信管理
openGauss查询响应是使用简单的“单一用户对应一个服务器线程”的客户端/服务器模型实现的。由于我们无法提前知道需要建立多少个连接,因此必
须使用主进程(GaussMaster)主进程在指定的TCP/IP(Transmission Control Protocol/Internet Protocol,传输控制协议/互联网协议)
端口上侦听传入的连接,只要检测到连接请求,主进程就会生成一个新的服务器线程。服务器线程之间使用信号量和共享内存相互通信,以确保整个并
发数据访问期间的数据完整性。
客户端进程可以被理解为满足openGauss协议的任何程序。许多客户端都基于C语言库libpq进行通信,但是该协议有几种独立的实现,例如Java JDBC
驱动程序。
建立连接后,客户端进程可以将查询发送到后端服务器。查询是使用纯文本传输的,即在前端(客户端)中没有进行解析。服务器解析查询语句、创建
执行计划、执行并通过在已建立的连接上传输检索到的结果集,将其返回给客户端。
openGauss数据库中处理客户端连接请求的模块叫做postmaster。前端程序发送启动信息给postmaster,postmaster根据信息内容建立后端响应线
程。postmaster也管理系统级的操作比如调用启动和关闭程序。postmaster在启动时创建共享内存和信号量池,但它自身不管理内存、信号量和锁操
作。
当客户端发来一个请求信息,postmaster立刻启动一个新会话,新会话对请求进行验证,验证成功后为它匹配后端工作线程。这种模式架构上处理简单,
但是高并发下由于线程过多,切换和轻量级锁区域的冲突过大导致性能急剧下降。因此openGauss通过线程资源池化复用的技术来解决该问题。线程池
技术的整体设计思想是线程资源池化,并且在不同连接直接复用。
1、postmaster源码组织
postmaster源码目录为:/src/gausskernel/process/postmaster。postmaster源码文件如表2所示。
表2 postmaster源码文件
postmaster.cpp 用户响应主程序
aiocompleter.cpp 完成预取(Prefetch)和后端写(BackWrite)I/O操作
alarmchecker.cpp 闹钟检查线程
lwlockmonitor.cpp 轻量锁的死锁检测
pagewriter.cpp 写页面
pgarch.cpp 日志存档
pgaudit.cpp 审计线程
pgstat.cpp 统计信息收集
startup.cpp 服务初始化和恢复
syslogger.cpp 捕捉并写所有错误日志
autovacuum.cpp 垃圾清理线程
bgworker.cpp 后台工作线程(服务共享内存)
bgwriter.cpp 后台写线程(写共享缓存)
cbmwriter.cpp remoteservice.cpp postmaster信号处理
checkpointer.cpp 检查点处理
fencedudf.cpp 保护模式下运行用户定义函数
gaussdb_version.cpp 版本特性控制
twophasecleaner.cpp 清理两阶段事务线程
walwriter.cpp 预写式日志写入
二、SQL引擎
数据库的SQL引擎是数据库重要的子系统之一,它对上负责承接应用程序发送过来的SQL语句,对下则负责指挥执行器运行执行计划。其中优化器作为SQL
引擎中最重要、最复杂的模块,被称为数据库的“大脑”,优化器产生的执行计划的优劣直接决定数据库的性能。
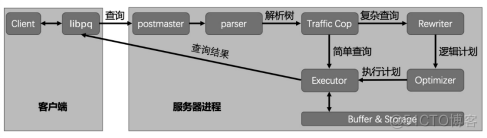
本篇从SQL语句发送到数据库服务器开始,对SQL引擎的各个模块进行全面的介绍与源码解析,以实现对SQL语句执行的逻辑与源码更深入的理解。其响
应流程如图1所示。
1、查询解析——parser
SQL解析对输入的SQL语句进行词法分析、语法分析、语义分析,获得查询解析树或者逻辑计划。SQL查询语句解析的解析器(parser)阶段包括如下:
词法分析:从查询语句中识别出系统支持的关键字、标识符、操作符、终结符等,每个词确定自己固有的词性。
语法分析:根据SQL语言的标准定义语法规则,使用词法分析中产生的词去匹配语法规则,如果一个SQL语句能够匹配一个语法规则,则生成对应的语法
树(Abstract Synatax Tree,AST)。
语义分析:对语法树(AST)进行检查与分析,检查AST中对应的表、列、函数、表达式是否有对应的元数据(指数据库中定义有关数据特征的数据,用
来检索数据库信息)描述,基于分析结果对语法树进行扩充,输出查询树。主要检查的内容包括:
①检查关系的使用:FROM子句中出现的关系必须是该查询对应模式中的关系或视图。
②检查与解析属性的使用:在SELECT句中或者WHERE子句中出现的各个属性必须是FROM子句中某个关系或视图的属性。
③检查数据类型:所有属性的数据类型必须是匹配的。
词法和语法分析代码基于gram.y和scan.l中定义的规则,使用Unix工具bison和flex构建产生。其中,词法分析器在文件scan.l中定义,它负责识别
标识符、SQL关键字等。对于找到的每个关键字或标识符,都会生成一个标记并将其传递给解析器。语法解析器在文件gram.y中定义,由一组语法规则
和每当触发规则时执行的动作组成,基于这些动作代码构架并输出语法树。在解析过程中,如果语法正确,则进入语义分析阶段并建立查询树返回,否
则将返回错误,终止解析过程。
解析器在词法和语法分析阶段仅使用有关SQL语法结构的固定规则来创建语法树。它不会在系统目录中进行任何查找,因此无法理解所请求操作的详细语
义。
语法解析完成后,语义分析过程将解析器返回的语法树作为输入,并进行语义分析以了解查询所引用的表、函数和运算符。用来表示此信息的数据结构
称为查询树。解析器解析过程分为原始解析与语义分析,分开的原因是,系统目录查找只能在事务内完成,并且我们不希望在收到查询字符串后立即启
动事务。原始解析阶段足以识别事务控制命令(BEGIN,ROLLBACK等),然后可以正确执行这些命令而无需任何进一步分析。一旦知道我们正在处理
实际查询(例如SELECT或UPDATE),就可以开始事务,这时才调用语义分析过程。
1) parser源码组织
parser源码目录为:/src/common/backend/parser。parser源码文件如表3所示。
表3 parser源码文件
parser.cpp 解析主程序
scan.l 词法分析,分解查询成token
scansup.cpp 处理查询语句转义符
kwlookup.cpp 将关键词转化为具体的token
keywords.cpp 标准关键词列表
analyze.cpp 语义分析
gram.y 语法分析,解析查询tokens并产生原始解析树
parse_agg.cpp 处理聚集操作,比如SUM(col1),AVG(col2)
parse_clause.cpp 处理子句,比如WHERE,ORDER BY
parse_compatibility.cpp 处理数据库兼容语法和特性支持
parse_coerce.cpp 处理表达式数据类型强制转换
parse_collate.cpp 对完成表达式添加校对信息
parse_cte.cpp 处理公共表格表达式(WITH 子句)
parse_expr.cpp 处理表达式,比如col, col+3, x = 3
parse_func.cpp 处理函数,table.column和列标识符
parse_node.cpp 对各种结构创建解析节点
parse_oper.cpp 处理表达式中的操作符
parse_param.cpp 处理参数
parse_relation.cpp 支持表和列的关系处理程序
parse_target.cpp 处理查询解析的结果列表
parse_type.cpp 处理数据类型
parse_utilcmd.cpp 处理实用命令的解析分析
2、SQL查询分流——traffic cop
traffic cop模块负责查询的分流,它负责区分简单和复杂的查询指令。事务控制命令(例如BEGIN和ROLLBACK)非常简单,因此不需要其它处理,
而其它命令(例如SELECT和JOIN)则传递给重写器(参考第6章)。这种区分通过对简单命令执行最少的优化,并将更多的时间投入到复杂的命令上,
从而减少了处理时间。简单和复杂查询指令也对应如下2类解析:
软解析(简单,旧查询):当openGauss共享缓冲区中存在已提交SQL语句的已解析表示形式时,可以重复利用缓存内容执行语法和语义检查,避免查
询优化的相对昂贵的操作。
硬解析(复杂,新查询):如果无缓存语句可重用,或者第一次将SQL语句加载到openGauss共享缓冲区中,则会导致硬解析。同样,当一条语句在共
享缓冲区中老化时,再次重新加载该语句时,还会导致另一次硬解析。因此,共享Buffer的大小也会影响解析调用的数量。
我们可以查询gs_prepared_statements来查看缓存了什么,以区分软/硬解析(它仅对当前会话可见)。此外,gs_buffercache模块提供了一种实
时检查共享缓冲区高速缓存内容的方法,它甚至可以分辨出有多少数据块来自磁盘,有多少数据来自共享缓冲区。
1) traffic cop(tcop)源码组织
traffic cop(tcop)源码目录为:/src/common/backend/tcop。traffic cop(tcop)源码文件如表4所示。
表4 traffic cop(tcop)源码文件
auditfuncs.cpp 记录数据库操作审计信息
autonomous.cpp 创建可被用来执行SQL查询的自动会话
dest.cpp 与查询结果被发往的终点通信
utility.cpp 数据库通用指令控制函数
fastpath.cpp 在事务期间缓存操作函数和类型等信息
postgres.cpp 后端服务器主程序
pquery.cpp 查询处理指令
stmt_retry.cpp SQL语句错误错误码并重试
3、查询重写——rewriter
查询重写利用已有语句特征和关系代数运算来生成更高效的等价语句,在数据库优化器中扮演关键角色;尤其在复杂查询中,能够在性能上带来数量级的
提升,可谓是“立竿见影”的“黑科技”。SQL语言是丰富多样的,非常的灵活,不同的开发人员依据经验的不同,手写的SQL语句也是各式各样,另外还可
以通过工具自动生成。同时SQL语言是一种描述性语言,数据库的使用者只是描述了想要的结果,而不关心数据的具体获取方式,输入数据库的SQL语言
很难做到是以最优形式表示的,往往隐含了一些冗余信息,这些信息可以被挖掘用来生成更加高效的SQL语句。查询重写就是把用户输入的SQL语句转换
为更高效的等价SQL,查询重写遵循2个基本原则:
等价性:原语句和重写后的语句,输出结果相同。
高效性:重写后的语句,比原语句在执行时间和资源使用上更高效。
介绍openGauss如下几个关键的查询重写技术:
常量表达式化简:常量表达式即用户输入SQL语句中包含运算结果为常量的表达式,分为算数表达式、逻辑运算表达式、函数表达式。查询重写可以对常
量表达式预先计算以提升效率。例如“SELECT * FROM table WHERE a=1+1; ”语句被重写为“SELECT * FROM table WHERE a=2”语句。
子查询提升:由于子查询表示的结构更清晰,符合人的阅读理解习惯,用户输入的SQL语句往往包含了大量的子查询,但是相关子查询往往需要使用嵌套
循环的方法来实现,执行效率较低,因此将子查询优化为“Semi Join”的形式可以在优化规划时选择其它的执行方法,或能提高执行效率。例如“SELECT
* FROM t1 WHERE t1.a in (SELECT t2.a FROM t2); ”语句可重写为“SELECT * FROM t1 LEFT SEMI JOIN t2 ON t1.a=t2.a”语句。
谓词下推:谓词(Predicate),通常为SQL语句中的条件,例如“SELECT * FROM t1 WHERE t1.a=1; ”语句中的“t1.a=1”即为谓词。等价类
(Equivalent-Class)是指等价的属性、实体等对象的集合,例如“WHERE t1.a=t2.a”语句中,t1.a和t2.a互相等价,组成一个等价类{t1.a,
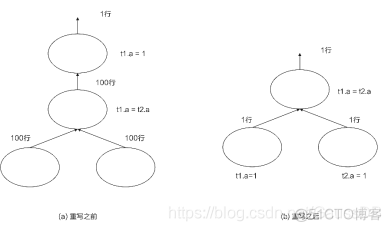
t2.a}。利用等价类推理(又称作传递闭包),我们可以生成新的谓词条件,从而达到减小数据量和最大化利用索引的目的。如图2所示,我们举一个形
象的例子来说明谓词下推的威力。假设有两个表t1、t2;它们分别包含[1,2,3,…100]共100行数据,那么查询语句“SELECT * FROM t1 JOIN t2
ON t1.a=t2.a WHERE t1.a=1”的逻辑计划在经过查询重写前后的对比。
查询重写的主要工作在优化器中实现,除此之外,openGauss还提供了基于规则的rewrite接口,用户可以通过创建替换规则的方法对逻辑执行计划进
行改写。例如视图展开功能即通过rewrite模块中的规则进行替换,而视图展开的规则是在创建视图的过程中默认创建的。
1) rewriter源码组织
rewriter源码目录为:/src/gausskernel/optimizer/rewrite。rewriter源码文件如表5所示。
表5 rewriter源码文件
rewriteDefine.cpp 定义重写规则
rewriteHandler.cpp 重写主模块
rewriteManip.cpp 重写操作函数
rewriteRemove.cpp 重写规则移除函数
rewriteRlsPolicy.cpp 重写行粒度安全策略
rewriteSupport.cpp 重写辅助函数
4、查询优化——optimizer
优化器(optimizer)的任务是创建最佳执行计划。一个给定的SQL查询(以及一个查询树)实际上可以以多种不同的方式执行,每种方式都会产生相同
的结果集。如果在计算上可行,则查询优化器将检查这些可能的执行计划中的每一个,最终选择预期运行速度最快的执行计划。
在某些情况下,检查执行查询的每种可能方式都会占用大量时间和内存空间,特别是在执行涉及大量连接操作(Join)的查询时。为了在合理的时间内
确定合理的(不一定是最佳的)查询计划,当查询连接数超过阈值时,openGauss使用遗传查询优化器(genetic query optimizer),通过遗传算法
来做执行计划的枚举。
优化器的查询计划(plan)搜索过程实际上与称为路径(path)的数据结构一起使用,该路径只是计划的简化表示,其中仅包含确定计划所需的关键信
息。确定代价最低的路径后,将构建完整的计划树以传递给执行器。这足够详细地表示了所需的执行计划,供执行者运行。在下文中,我们将忽略路径
和计划之间的区别。
5、查询执行——executor
执行器(executor)采用优化器创建的计划,并对其进行递归处理以提取所需的行的集合。这本质上是一种需求驱动的流水线执行机制。即每次调用一个计划节点时,它都必须再传送一行,或者报告已完成传送所有行。
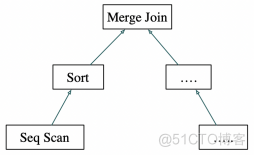
如图4所示的执行计划树示例,顶部节点是Merge Join节点。在进行任何合并操作之前,必须获取2个元组(MergeJoin节点的2个子计划各返回1个元
组)。因此,执行器以递归方式调用自身以处理其子计划(如从左子树的子计划开始)。Merge Join由于要做归并操作,因此它要子计划按序返回元组
,从图4可以看出,它的子计划是一个Sort节点。Sort的子节点可能是Seq Scan节点,代表对表的实际读取。执行SeqScan节点会使执行程序从表中获
取一行并将其返回到调用节点。Sort节点将反复调用其子节点以获得所有要排序的行。当输入完毕时(如子节点返回NULL而不是新行),Sort算子对获
取的元组进行排序,它每次返回1个元组,即已排序的第1行。然后不断排序并向父节点传递剩余的排好序的元组。
Merge Join节点类似地需要获得其右侧子计划中的第1个元组,看是否可以合并。如果是,它将向其调用方返回1个连接行。在下1次调用时,或者如果
它不能连接当前输入对,则立即前进到1个表或另1个表的下1行(取决于比较的结果),然后再次检查是否匹配。最终,1个或另1个子计划用尽,并且
Merge Join节点返回NULL,以指示无法再形成更多的连接行。
复杂的查询可能涉及多个级别的计划节点,但是一般方法是相同的:每个节点都会在每次调用时计算并返回其下1个输出行。每个节点还负责执行优化器
分配给它的任何选择或投影表达式。
执行器机制用于执行所有4种基本SQL查询类型:SELECT、INSERT、UPDATE和DELETE。
对于SELECT,顶级执行程序代码仅需要将查询计划树返回的每一行发送给客户端。
对于INSERT,每个返回的行都插入到为INSERT指定的目标表中。这是在称为ModifyTable的特殊顶层计划节点中完成的。(1个简单的“INSERT …
VALUES”命令创建了1个简单的计划树,该树由单个Result节点组成,该节点仅计算一个结果行,并传递给ModifyTable树节点实现插入)。
对于UPDATE,优化器对每个计算的更新行附着所更新的列值,以及原始目标行的TID(元组ID或行ID);此数据被馈送到ModifyTable节点,并使用
该信息来创建新的更新行并标记旧行已删除。
对于DELETE,计划实际返回的唯一列是TID,而ModifyTable节点仅使用TID访问每个目标行并将其标记为已删除。
执行器的主要处理控制流程如下:
创建查询描述。
查询初始化:创建执行器状态(查询执行上下文)、执行节点初始化(创建表达式与每个元组上下文、执行表达式初始化)。
查询执行:执行处理节点(递归调用查询上下文、执行表达式,然后释放内存,重复操作)。
查询完成;执行未完成的表格修改节点。
查询结束:递归释放资源、释放查询及其子节点上下文。
释放查询描述。
1) executor源码组织
executor源码目录为:/src/gausskernel/runtime/executor。executor源码文件如表7所示。
表7 executor源码文件
execAmi.cpp 各种执行器访问方法
execClusterResize.cpp 集群大小调整
execCurrent.cpp 支持WHERE CURRENT OF
execGrouping.cpp 支持分组、哈希和聚集操作
execJunk.cpp 伪列的支持
execMain.cpp 顶层执行器接口
execMerge.cpp 处理MERGE指令
execParallel.cpp 支持并行执行
execProcnode.cpp 分发函数按节点调用相关初始化等函数
execQual.cpp 评估资质和目标列表表达式
execScan.cpp 通用的关系扫描
execTuples.cpp 元组相关的资源管理
execUtils.cpp 多种执行相关工具函数
functions.cpp 执行SQL语言函数
instrument.cpp 计划执行工具
lightProxy.cpp 轻量级执行代理
node*.cpp 处理*相关节点操作的函数
opfusion.cpp、opfusion_util.cpp、opfusion_scan.cpp 旁路执行器:处理简单查询
spi.cpp 服务器编程接口
tqueue.cpp 并行后端之间的元组信息传输
tstoreReceiver.cpp 存储结果元组
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
