

数据分布是数据库的存储和计算关键设计之一,不同业务场景下不同的数据分布会有数量级的性能差异。现代分布式数据库系统数据分布在多节点上,对数据分布提出了更多挑战。
本文主要openGemini为例,介绍在现代分布式数据库上进行高性能数据分布设计范式,主要包括分区键、分片键、主键和排序键等的设计范式。
分区键
分区是SMP架构数据库系统开始使用的数据分布技术。
SMP:SymmetricMulti-Processor,即对称多处理器架构
现代数据库系统通常使用PARTITION BY来控制分区,比如按时间(datetime)分区
PARTITION BY datetime根据设定的分区字段值,将数据分布到不同的分区中。分区是物理存储单元,存储了不同范围区间的数据。
分区键设计范式:分区键值域连续且呈均匀分布。在Log, trace, event, metric等可观测性业务场景中,时间字段是作为分区键的最佳选择。
> show shards
name: mst
+---------+-----+-------------+----------------------+----------------------+----------------------+-----+
|database | rp | shard_group | start_time | end_time | expiry_time | ... |
+---------+-----+-------------+----------------------+----------------------+----------------------+-----+
| db | auto| 1 | 2023-09-25T00:00:00Z | 2023-10-02T00:00:00Z | 2023-10-02T00:00:00Z | ... |
+---------+-----+-------------+----------------------+----------------------+----------------------+-----+
10 columns, 1 rows in set
Elapsed: 4.599747msopenGemini默认使用时间字段作为分区键,使得:
-
查询谓词中存在时间谓词时,通过分区键进行剪枝,减少计算开销
-
保留策略基于分区键,分区数据易于管理
分片键
数据库系统从”scale-up”演进到”scale-out”,从”SMP”演进到”MMP”,都是为了更好解决大规模数据“存”和“算”问题。“分治”是大规模数据经典的解决方案。
MPP:MassivelyParallelProcessing,即大规模并行处理架构
现代数据库系统通常使用DISTRIBUTE BY来控制分片,比如按网络监控的主机地址(host)进行分片
DISTRIBUTE BY host
根据设定的分片字段值,将数据分布到不同的分片中。分片是物理存储单元,存储了离散聚簇的数据。
分片键设计范式:分片键值域离散且呈非均匀分布。通常需要根据实际的查询业务来选择分片键。
例如,业务需要对host去重,
SELECT DISTINCT host FROM t
数据库中DISTINCT通常会重写为GROUP BY,
SELECT host FROM t GROUP BY host
host字段在分片中的基数 C
> select cardinality(host) as C from t.shard.0
name: t.shard.0
+-------------+
| C |
+-------------+
| 5000000 |
+-------------+
1 columns, 1 rows in set
> select cardinality(host) as C from t.shard.1
name: t.shard.1
+-------------+
| C |
+-------------+
| 5000000 |
+-------------+
1 columns, 1 rows in set
Elapsed: 1.11137ms
当表的分片数量为N时,在reduce阶段,需要计算的数据量是:
O(C∗N)
选择host作为分片键,将reduce阶段需要计算的数据量从C * N(C: host的基数,N: shard的数量)优化到C,大幅减少待reduce的数据量。
> select cardinality(host) as C from t_sharding_host.shard.0
name: t_sharding_host.shard.0
+-----------+
| C |
+-----------+
| 2500000 |
+-----------+
1 columns, 1 rows in set
> select cardinality(host) as C from t_sharding_host.shard.1
name: t_sharding_host.shard.1
+-----------+
| C |
+-----------+
| 2500000 |
+-----------+
1 columns, 1 rows in set
Elapsed: 1.11137ms
openGemini默认使用Tags作为分区键,使得:
-
查询谓词中存在分片键时,通过分片键进行剪枝,减少计算开销
-
针对分片键的分组聚合计算,能对基于分片键的算子进行优化
主键和排序键
主键用于指导数据库构建索引以加速查询,数据库中通常使用PRIMARY KEYS来设置主键。
PRIMARY KEYS host排序键将数据按指定顺序排序,数据库中通常使用ORDERED KEYS来设置排序键。
ORDERED KEYS host主键和排序键设计范式:排序键值域基数小,主键为排序键前缀。为什么需要这样设计呢?
由于索引并不是直接指向PRIMARY KEYS对应行的值,而是对应到该行对应到的row_id,row_id能快速定位到数据所在位置,所以row_id才是真正的唯一主键。
> select __row_id__,host from tname: t+-----------+--------+| __row_id__ | host 服务器托管网 |+-----------+--------+| 1 | h1 |+-----------+--------+| 2 | h2 |+-----------+--------+| 3 | h3 |+-----------+--------+| 4 | h4 |+-----------+--------+| 5 | h5 |+-----------+--------+2 columns, 5 rows in setElapsed: 1.11137ms
row_id序列和PRIMARY KEYS序列顺序一致,数据有序分布实质上就是构建了一个高度为1的B-Tree,使得:
-
查询谓词中存在主键时,通过主键进行剪枝,减少计算开销
-
针对主键的分组聚合计算,能对基于主键采用BSP等算法对算子进行优化
openGemini默认使用Tags作为主键和排序键,支持在Tags上高效的搜索和聚合。
总结
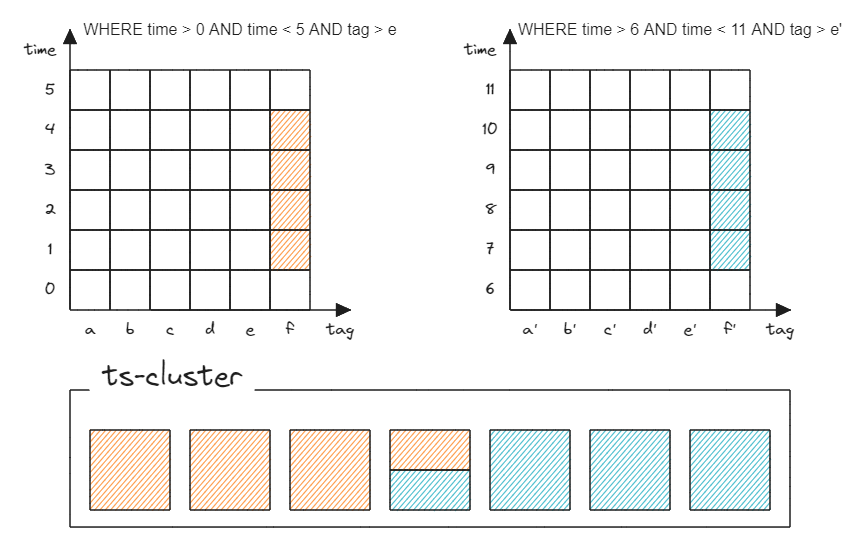
Purpose-Build分布式数据库系统与Cl服务器托管网assic分布式数据库系统在数据分布设计范式上是相同的。openGemini作为时序场景专用数据库,无需进行复杂数据分布设计,降低了使用门槛。数据分布范式能帮助我们正确设计Tags,以
-
避免出现“维度诅咒”,“高基维“等问题。
-
充分利用基于数据分布的查询优化技术,获得极致的性能体验。
openGemini官网:http://www.openGemini.org
openGemini开源地址:https://github.com/openGemini
openGemini公众号:

欢迎关注~ 诚邀你加入 openGemini 社区,共建、共治、共享未来!
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
