
概述:
在当今社会,程序员内卷非常的严重,如果没有过硬的技术,很难在众多的程序员中脱颖而出,例如,以前问数据库方面的知识,只会问些增删改查语句表面的东西,而如今却要问数据库底层的架构、索引原理及引擎等内容,本文就是面试官经常问到的问题:为什么MySQL索引更适合B+树而不是二叉树、B树。要回答这个问题,首先我们得了解什么是B+数、二叉树、B树。
一、什么是二叉树
二叉树(Binary Search Trees):二叉查找树的特点就是任何节点的左子节点的键值都小于当前节点的键值,右子节点的键值都大于当前节点的键值。 顶端的节点我们称为根节点,没有子节点的节点我们称之为叶节点,它的高度决定的查找效率。
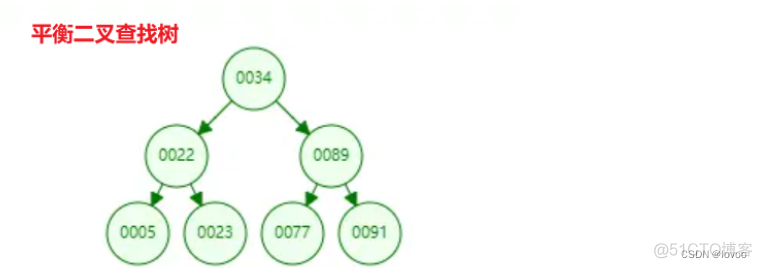
二叉树的查找过程,如图:

上面有一张user表,建立了建立了一个二叉查找树的索引。图中的圆为二叉查找树的节点,节点中存储了键(key)和数据(data)。
键对应user表中的id,数据对应user表中的行数据。
如果我们需要查找id=8的用户信息,利用我们创建的二叉查找树索引,查找流程如下:
- 将根节点作为当前节点,把8与当前节点的键值10比较,8小于10,接下来我们把当前节点
- 继续把8和当前节点的键值7比较,发现8大于7,把当前节点的左子节点作为当前节点。
- 把8和当前叶子节点的键值5对比,8大于5,然后找右子节点。
- 发现8等于8,满足条件,我们从当前节点中取出data,即id=8,name=xw。
利用二叉查找树我们只需要3次即可找到匹配的数据。如果在表中一条条的查找的话,我们需要6次才能找到。
为什么不选择二叉树
二叉树相比于顺序查找的确减少了查找次数,但是在最坏情况下,二叉树有可能退化为顺序查找。
而且就二叉树本身来说,当数据库的数据量特别大时,其层数也将特别大。
二叉树的高度一般是log_2^n。
B树的高度是log_t^((n+1)/2) + 1,其高度约比B树大lgt倍。n是节点总数,t是树的最小度数。
二、什么是B树
- B树是一种多路自平衡的搜索树,它类似普通的平衡二叉树,不同的是B树允许每个节点拥有更多的子节点。B-Tree相对于AVL Tree缩减了节点的个数,使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。I/O渐进复杂度是O(h)。
- 注意B-树就是B树,-只是一个符号。
- 如图:如果要查找0014,就需要查询2次,虽然和红黑树的I/O渐进复杂度一样,但是红黑树结构,h明显要深得多。
- 深度理解:
InnoDB存储引擎有页(Page)的概念,页是其磁盘管理的最新单位,innoDB存储引擎默认每个页面的大小为16KB,可通过参数innodb_page_size将页面的大小设置为4k、8K、16K,在mysql中可通过如下命令查看页面的大小

mysql> show variables like '%innodb_page_size%';而系统一个磁盘块的存储空间往往没有这么大,因此InnoDB每次申请磁盘空间时都会是若干地址连续磁盘块来到达页的大小16KB。innoDB在把磁盘数据读取到磁盘时会以页为基本单位,在查询数据时如果一个页中的每条数据都能有助于单位数据记录的位置,这将减少磁盘I/O的次数,提高查询效率。
总结:
B树可以看成平衡二叉树的扩展
1、每个节点最多有m个分支,最少分支数(根节点且不是叶子节点),至少有两个分支;最少分指数(非叶子节点非根节点),至少有两个m/2(向上取整)个分支
2、有n(k=3、节点内关键字各不相等
4、叶子节点处于同一层:可以用空指针表示,查找失败的位置
三、什么是B+Tree
B+树是B树的一种变形形式,B+树上的叶子节点存储关键字以及相应记录的地址,叶子节点以上各层作为索引使用。
一棵 M 阶的B+树定义如下:
1、每个节点至多有 M 个子树;
2、除根节点外,每个节点有ceil(M/2)至 M个子树,根节点至少有两个子树;
3、有 k 个子树的节点必有 k 个关键字。
4、叶子节点包含了全部关键字和数据指针,叶子节点内的关键字有序排列,叶子节点间也是有序排列,指针相连。
5、所有非叶子节点可以看成是索引,仅包含其子树中最大(或最小)关键字的值。
6、所有的叶子节点都位于同一层。
B+树的结构图:

根据上图我们来看下B+树和B树有什么不同。
1、在B树中,你可以将键和值存放在内部节点和叶子节点
2、在B+树中,内部节点都是键,没有值。叶子节点同时存放键和值
3、B+树的叶子节点有一条链相连,而B树的叶子节点各自独立。
使用B+树的好处
1、B+树的内部节点只存放键,不存放值,一次读取可以在内存页种获取更多的键,可以更快的缩小查找范围
2、B+树的叶子节点 有一条链连着。当需要进行一次全部数据遍历的时候,B+树只需要使用O(logN)时间找到最小的一个节点,然后通过链进行O(N)的顺序遍历即可。
但是B树则需要对每一层进行遍历,需要多次内存置换,需要花费更多的时间。
数据库为什么使用B+树,而不是B树
数据库的数据读取需要进行巨大的磁盘IO操作。
需要【更快地缩小范围和更少的读取次数】,所以数据库选用B+树作为底层实现。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.e1idc.net
