

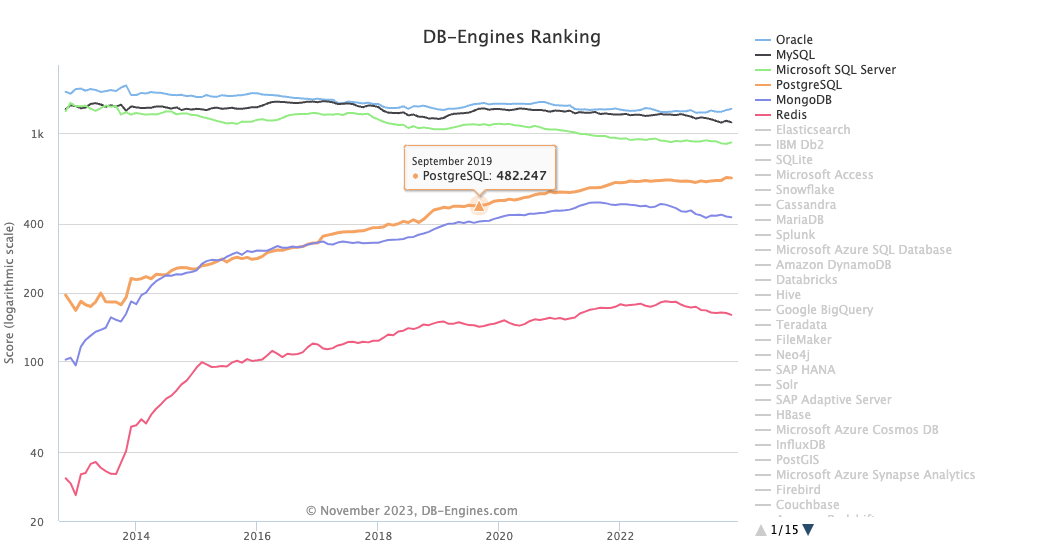
首先在全球范围内,MySQL 一直是领先于 PostgreSQL (下文简称 PG) 的。下图是 DB-Engines 的趋势图,虽然 PG 是近 10 年增长最快的数据库,但 MySQL 依然保持着优势。
再来看一下 Google Trends 过去一年的对比
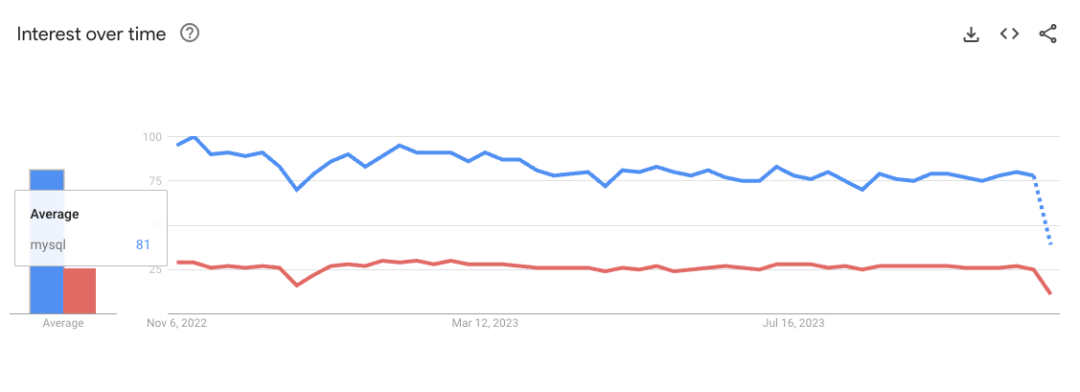
MySQL 也依然是明显领先的。而进一步看一下地域分布的话
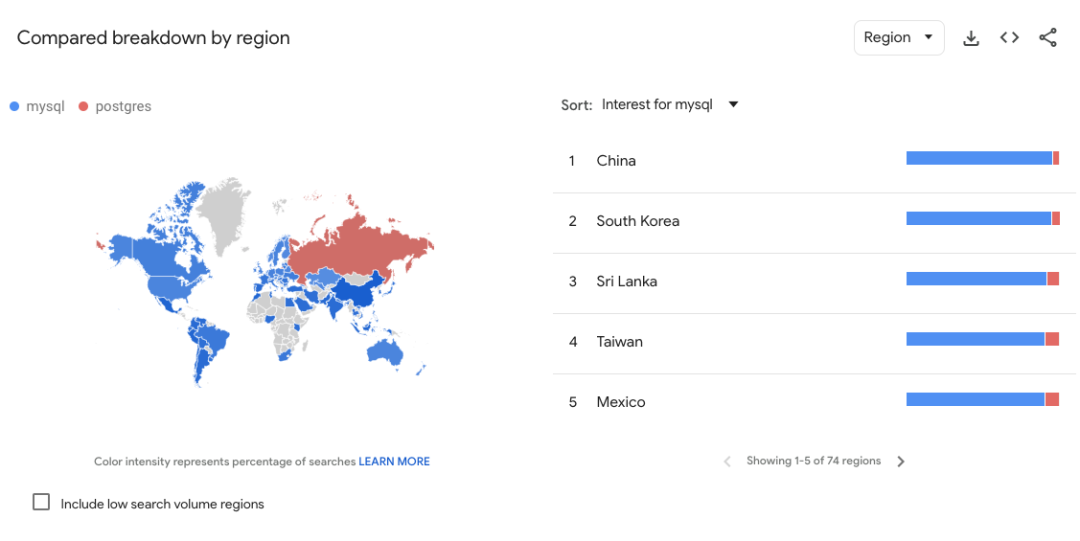
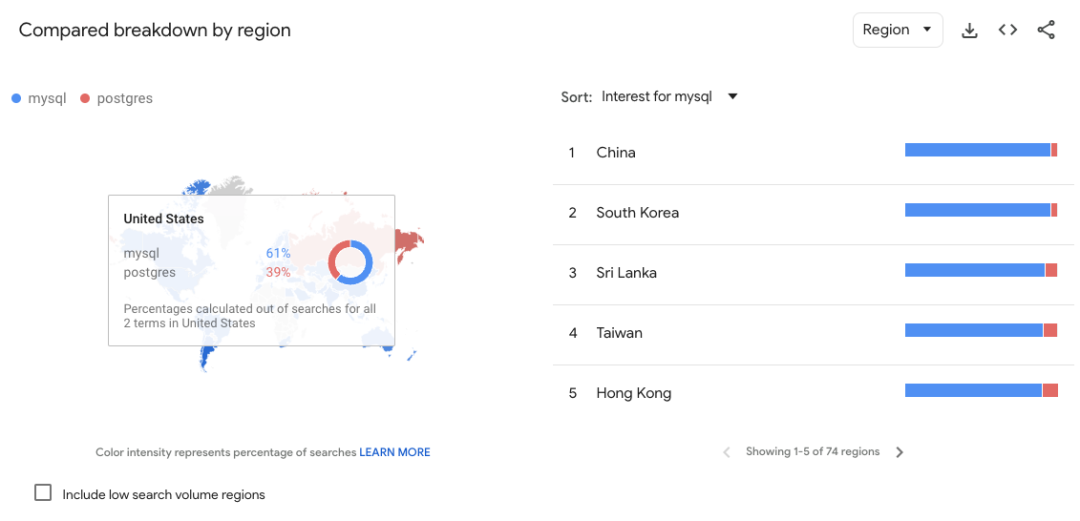
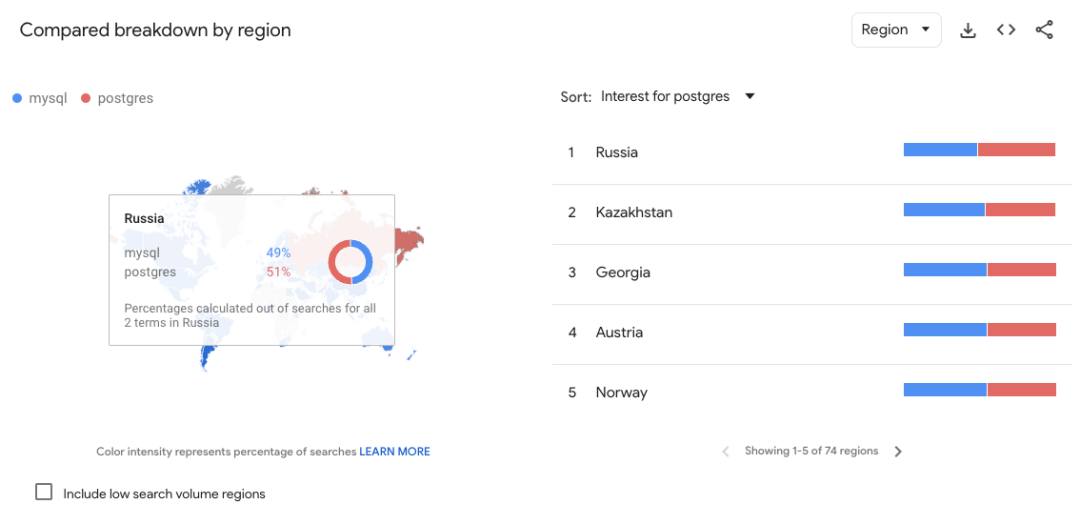
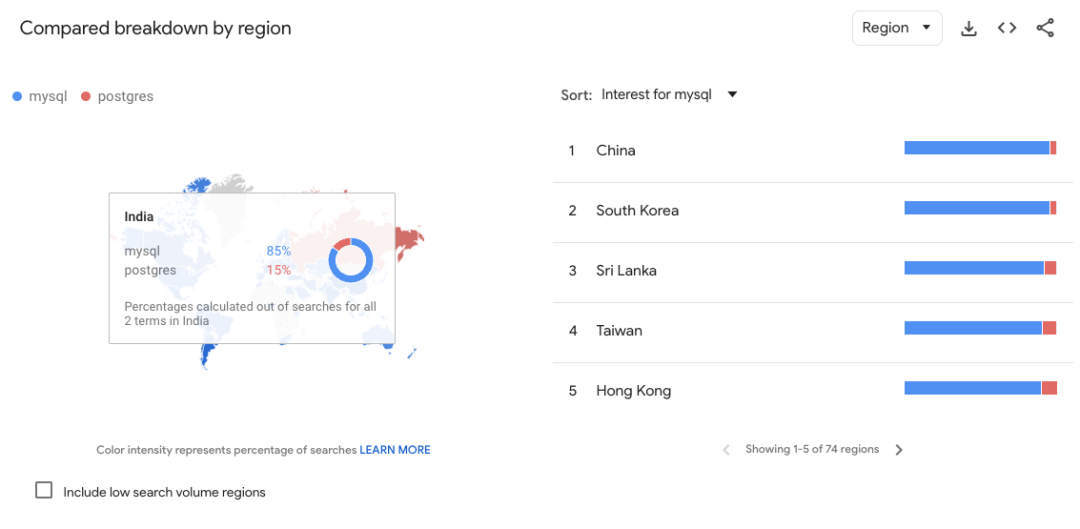
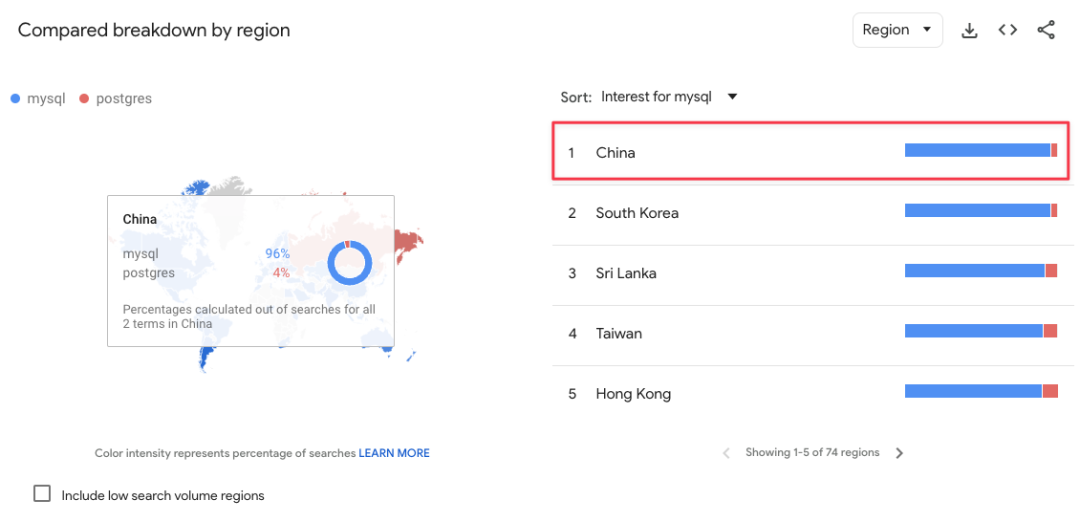
绝大多数地区依然是 MySQL 领先,份额对比在 60:40 ~ 70:30 之间;少数几个国家如俄罗斯不分伯仲;印度的对比是 85:15;而中国则是达到了 96:4,也是 Google Trends 上差异最明显的国家。
笔者从 2009 年左右开始学习数据库相关知识,接触到了 MySQL 5.1 和 PG 8.x。而深度在工作中使用则是 2013 年,那时加入 Google Cloud SQL 开始维护数据库,MySQL 从 5.5 开始,到之后 2017 年 Cloud SQL 推出了 PG 服务,从 9.6 开始,后来一直同时维护 Google 内部的 MySQL 和 PG 分支,也就一直关注着两边的发展。18 年回国后,进一步熟悉了国内的生态。
下面就来尝试分析一下 MySQL 在中国流行度遥遥领先于 PG 的原因。
Windows


MySQL 在 1998 年就提供了 Windows 版本,而 PostgreSQL 则到了 2005 年才正式推出。之前读到的原因是 Windows 早期的版本一直无法很好支持 PostgreSQL 的进程模型。
上手门槛
MySQL 上手更简单,举几个例子:
- 连 PG,一定需要指定数据库,而 MySQL 就不需要。psql 大家碰到的问题是尝试连接时报错 FATAL Database xxx does not exist。而 mysql 碰到的问题是连接上去后,执行查询再提示 no database selected。
- 访问控制的配置,首先 PG 和 MySQL 都有用户系统,但 PG 还要配置一个额外的 pg_hb服务器托管网a (host-based authentication) 文件。
- MySQL 的层级关系是:实例 -> 数据库 -> 表,而 PG 的关系是:实例(也叫集群)> 数据库 > Schema > 表。PG 多了一层,而且从行为表现上,PG 的 schema 类似于 MySQL 数据库,而 PG 的数据库类似于 MySQL 的实例。PG 的这个额外层级在绝大多数场景是用不到的,大家从服务器托管网习惯上还是喜欢用数据库作为分割边界,而不是 schema。所以往往 PG 数据库下,也就一个 public schema,这多出来的一层 schema 就是额外的负担。
- 因为上面机制的不同,PG 是无法直接做跨库查询的,早年要通过 dblink 插件,后来被 FDW (foreign data wrapper) 取代。
- PG 有更加全面的权限体系,数据库对象都有明确的所有者,但这也导致在做测试时,更经常碰到权限问题。
虽然 PostgreSQL 的设计更加严谨,但也更容易把人劝退。就像问卷设计的一个技巧是第一题放一个无脑就能答上来的二选一,这个的目的在于让对方开始答题。
性能
最早 Google 搜索和广告业务都是跑在 MySQL 上的,我读到过当时选型的备忘。其实一开始团队是倾向于 PG 的(我猜测是 PG 的工程质量更加符合团队的技术品味),但后来测试发现 MySQL 的性能要好不少,所以就选型了 MySQL。 现在两者的性能对比已经完全不一样了,而且性能和业务关联性很强,取决于 SQL 复杂度,并发,延迟这些不同的组合。目前在大部分场景下,MySQL 和 PG 的性能是相当的。有兴趣可以阅读 Mark Callaghan 的文章。

互联网
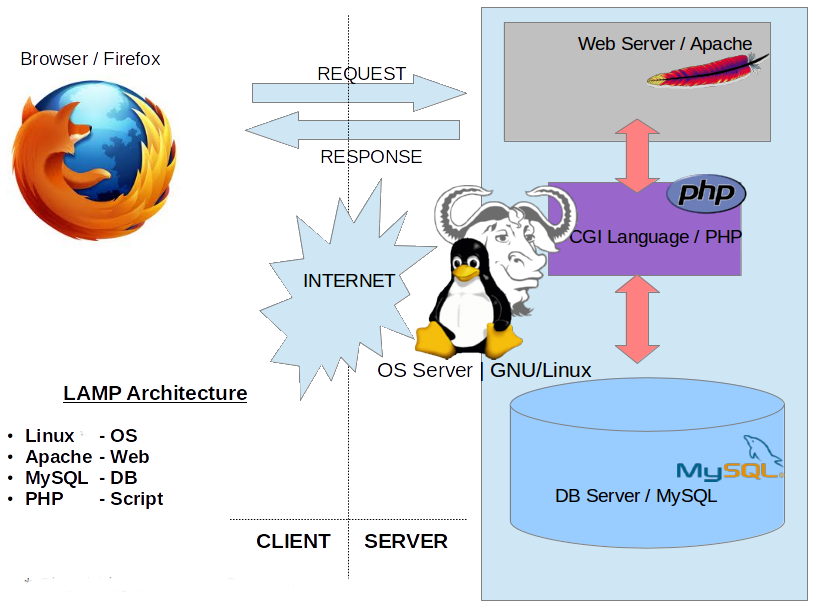
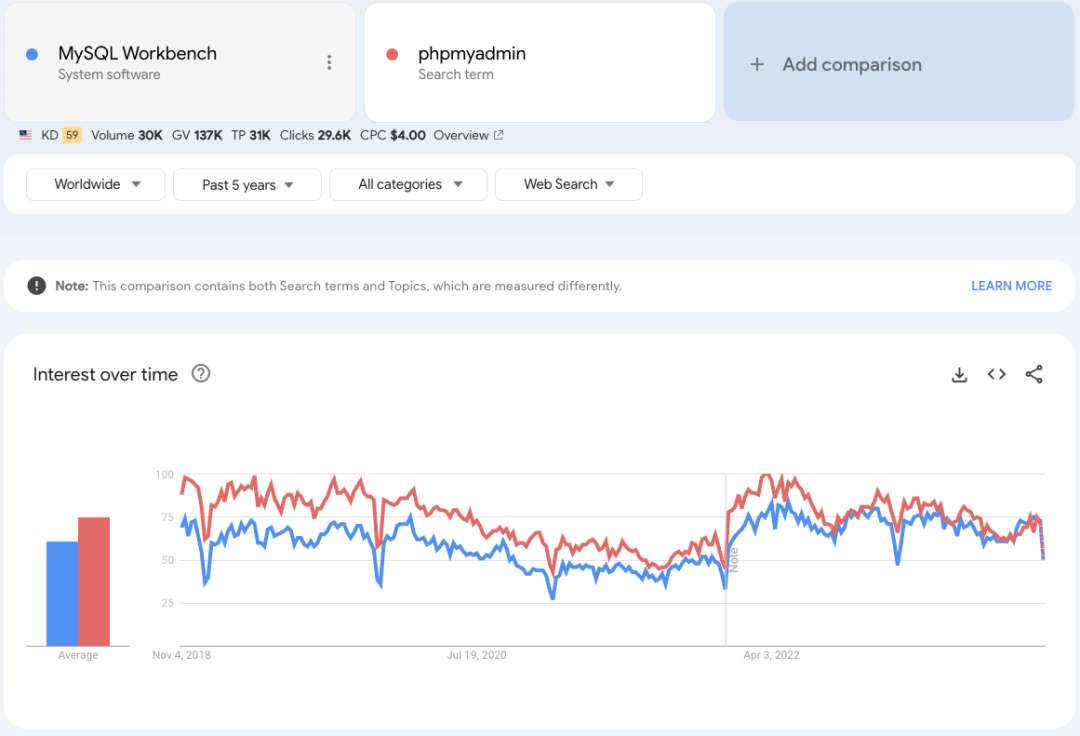
最重要的是 LAMP 技术栈,Linux + Apache + MySQL + PHP,诞生于 1998 年,和互联网崛起同步,LAMP 技术栈的普及也带火了 MySQL。这个技术栈的绑定是如此之深,所以时至今日,MySQL 官方客户端 MySQL Workbench 也还是不及 phpMyAdmin 流行。
大厂的号召力
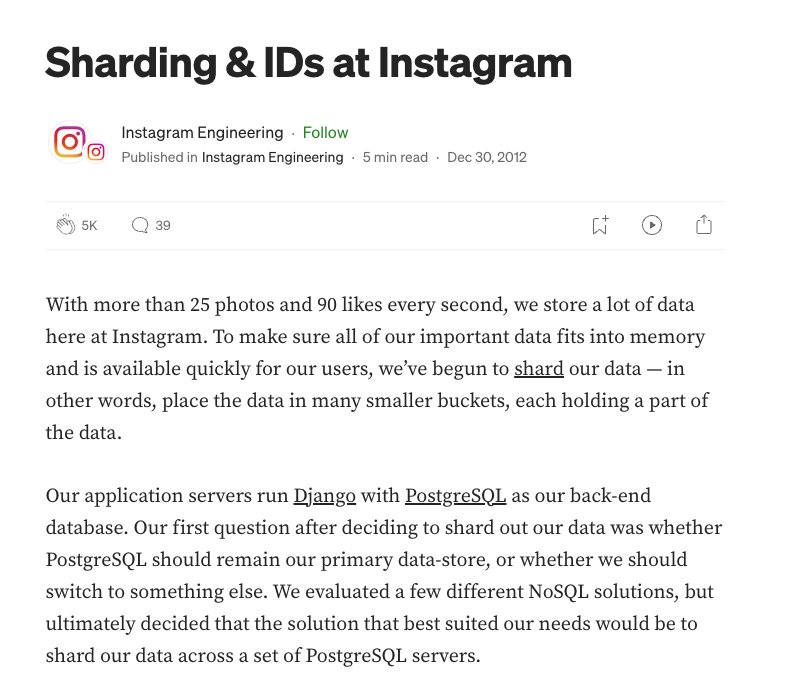
前面提到的 Mark Callaghan 一开始在 Google 的 MySQL 团队,他们给生态做了很多贡献,后来 Google 内部开始用 Spanner 替换 MySQL,Mark 他们就跑到了 Facebook 继续做,又进一步发展了 MySQL 的生态,像当时互联网公司都需要的高可用方案 MHA (Master High Availability) 就是 Mark 在 FB 时期打磨成熟的。当时整个互联网技术以 Google 为瞻,传播链差不多是 Google > Facebook / Twitter > 国内互联网大厂 > 其他中小厂。MySQL 在互联网公司的垄断就这样形成了。 相对的,那段时间 PG 有影响力的文章不多,我唯一有印象的是 Instagram 分享他们 sharding 的方案,提到用的是 PostgreSQL。
生态
有了大量使用后,自然就有人去解决碰到的各种问题。先是 InnoDB 横空出世,解决了事务和性能问题。主从,中间件分库分表方案解决了海量服务的扩展和高可用问题。各种 MySQL 相关书籍,培训资料也冒了出来,应该不少人都读过高性能 MySQL (High Performance MySQL) 这本书。

业界有 Percona 这样专注于做 MySQL 技术咨询的公司,他们还研发了一系列工具,比如做大表变更的 pt-online-schema-change(后来 GitHub 还发布了改良版 gh-ost),做备份的 xtrabackup。
国内也做了不少的贡献,阿里给上游贡献了许多 replication 的改进。SQL 审核优化这块,有去哪儿研发的 Inception,小米团队的 SOAR。Parser 有 PingCAP 的 MySQL Parser。
相对而言 PG 在工具链的生态还是差不少,比如 PG 生态里没有开箱即用的 Parser,没有 Parser 也就无法做 SQL 审核。Bytebase 在实现相关功能时,就只能从头开始做。当然这也成为了 Bytebase 产品的核心竞争力,我们是市面上对 PG 变更审核,查询脱敏支持最好的工具,除了大表变更外,功能完全对标 MySQL。
总结和展望
回到中国 MySQL 远比 PostgreSQL 流行的原因,在上面所有列出的要素里,我觉得最核心的还是第一条,MySQL 很早就能跑在 Windows 上,而 PG 不能。因为有了能跑 Windows 这个点,MySQL 成为了 LAMP 的一部分,到后来成为了支撑整个互联网的基石。当时国内大家手头装的都是 windows 操作系统,要开发 web 应用,都用 LAMP 架构,就顺便把 MySQL 带上了。
此外国内还有更明显的头部效应。国内所有互联网公司的技术体系都源自阿里,比如拿研发环境来说,SIT (System Integration Test) 是我回国加入蚂蚁后才接触到的名词,但后来在其他各个地方又都反复遇到。数据库方案也是如此,全套照搬了阿里的 MySQL 方案。就连技术职级也是,找工作先确认对标 P 几。
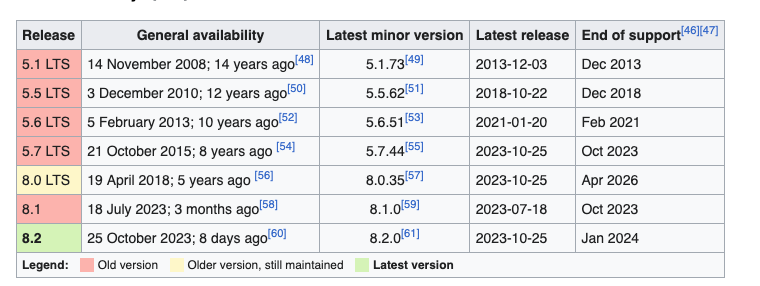
就在上月,MySQL 5.7 宣布了 EOL,算是给 MySQL 5 系,这个支撑了过去 15 年中国互联网的功勋做了一个告别。
随着 MySQL 的辞旧,PG 的崛起,在这 AI 的黎明,VR 的前夜,下一个 15 年,MySQL 和 PG 之间相爱相杀的故事又该会如何演绎呢。
I
更多资讯,请关注 Bytebase 公号:Bytebase
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
分块压缩算法是一种数据压缩方法,它将输入数据划分为不同的块,并对每个块进行独立的压缩。这种算法通常用于处理大型文件或流式数据,可以提高压缩和解压缩的效率。 以下是一个基本的分块压缩算法的示例: 将输入数据分成固定大小的块。块的大小可以根据具体情况进行调整,典型…
