
作者:徐之浩、车漾
“成本”、“性能”和 “效率”正在成为影响大模型生产和应用的三个核心因素,也是企业基础设施在面临生产、使用大模型时的全新挑战。AI 领域的快速发展不仅需要算法的突破,也需要工程的创新。
大模型推理对基础设施带来更多挑战
首先,AI 商业化的时代,大模型推理训练会被更加广泛的使用。比较理性的看待大模型的话,一个大模型被训练出来后,无外乎两个结果,第一个就是这个大模型没用,那就没有后续了;另一个结果就是发现这个模型很有用,那么就会全世界的使用,这时候主要的使用都来自于推理,不论是 openAI 还是 midjourney,用户都是在为每一次推理行为付费。随着时间的推移,模型训练和模型推理的使用比重会是三七开,甚至二八开。应该说模型推理会是未来的主要战场。
大模型推理是一个巨大的挑战,它的挑战体现在成本、性能和效率。 其中成本最重要,因为大模型的成本挑战在于模型规模越来越大,使用的资源越来越多,而模型的运行平台 GPU 由于其稀缺性,价格很昂贵,这就导致每次模型推理的成本越来越高。而最终用户只为价值买单,而不会为推理成本买单,因此降低单位推理的成本是基础设施团队的首要任务。
在此基础上,性能是核心竞争力,特别是 ToC 领域的大模型,更快的推理和推理效果都是增加用户粘性的关键。
应该说大模型的商业化是一个不确定性较高的领域,成本和性能可以保障你始终在牌桌上。效率是能够保障你能在牌桌上赢牌。
进一步,效率。模型是需要持续更新,这就模型多久可以更新一次,更新一次要花多久的时间。谁的工程效率越高,谁就有机会迭代出有更有价值的模型。

近年来,容器和 Kubernetes 已经成为越来越多 AI 应用首选的运行环境和平台。一方面,Kubernetes 帮助用户标准化异构资源和运行时环境、简化运维流程;另一方面,AI 这种重度依赖 GPU 的场景可以利用 K8s 的弹性优势节省资源成本。在 AIGC/大模型的这波浪潮下,以 Kubernetes 上运行 AI 应用将变成一种事实标准。
AIGC 模型推理服务在云原生场景下的痛点
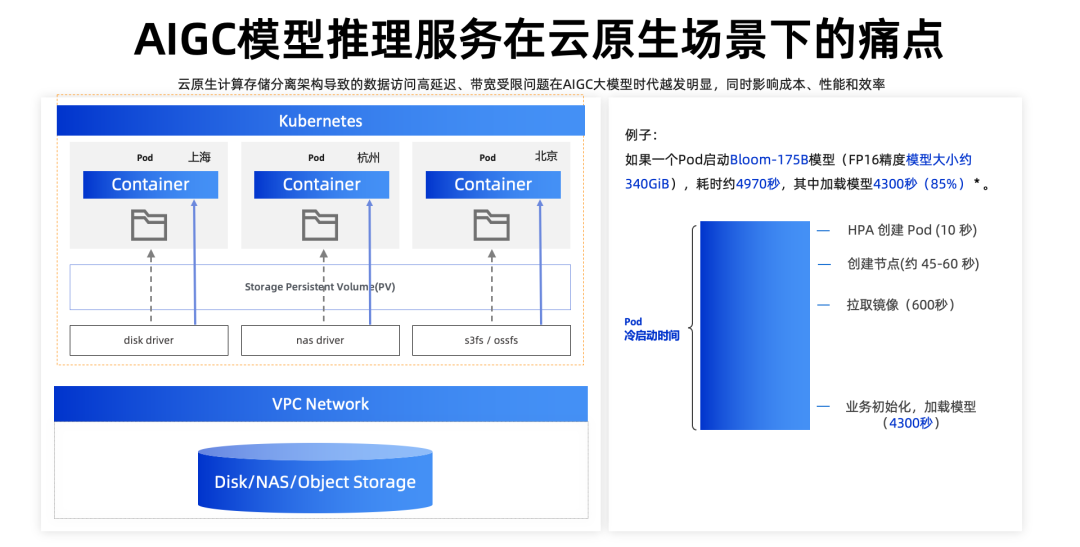
在 AIGC 推理场景下有个关键的矛盾,就是计算存储分离的架构导致的数据访问高延迟、带宽受限问题和大模型规模不断增长的矛盾, 它会同时影响成本、性能和效率。
模型弹性伸缩、按需使用,是控制大模型成本的利器。然而,如上图右所示,以 Bloom-175B 模型(FP16 精度模型大小约 340GiB)为例,模型的扩容耗时为 82 分钟,接近 1 个半小时,为了找到问题的根因,需要对模型启动时间进行拆解,其中主要耗时在于 HPA 弹性、创建计算资源、拉取容器镜像,加载模型。可以看到从对象存储加载一个约 340G 的大模型,耗时大约在 71 分钟,占用整体时间的 85%,这个过程中我们其实可以看到 I/O 吞吐仅有几百 MB 每秒。
要知道在 AWS 上 A100 按量付费的价格每小时 40 美元,而模型启动时刻 GPU 其实是处于空转的时刻,这本身就是成本的浪费。同时这也影响了模型的启动性能和更新频率。
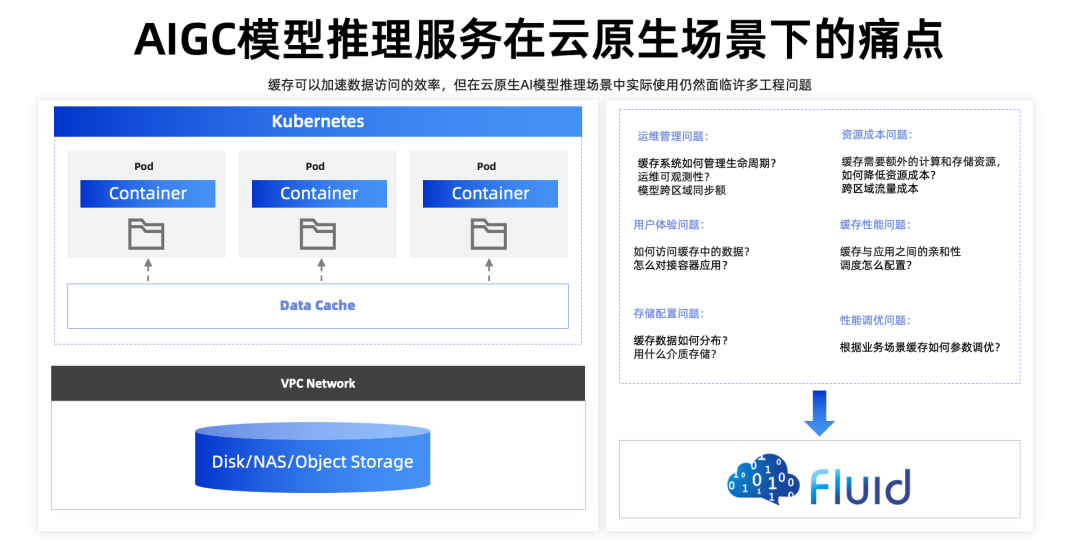
那么,我们有办法解决这个问题吗?一个直观的想法是增加一个缓存层,但是真的增加了缓存层就可以了吗?实践中其实并不是这样的,我们会遇到一系列的问题。首先就是快的问题: 能否用好缓存,如果加了缓存但是速度依旧不快,那么是缓存的规划问题?硬件配置问题?还是软件配置?网络问题?调度问题?
其次就是省: 关注成本问题,作为缓存的机器通常是高带宽、大内存、本地盘的机器,这些配置的机器往往并不便宜。如何能够实现性能最大化的同时也有合理成本控制。
接着就是好: 用户使用复杂不?用户代码是否需要相应的修改。运维团队工作量大吗?模型会服务器托管网不断更新和同步,如何降低这个缓存集群的运维成本。简化运维团队的负担。
正是在这种对于缓存工程化落地的思考中,诞生了 Fluid 这个项目。
Fluid 是什么?
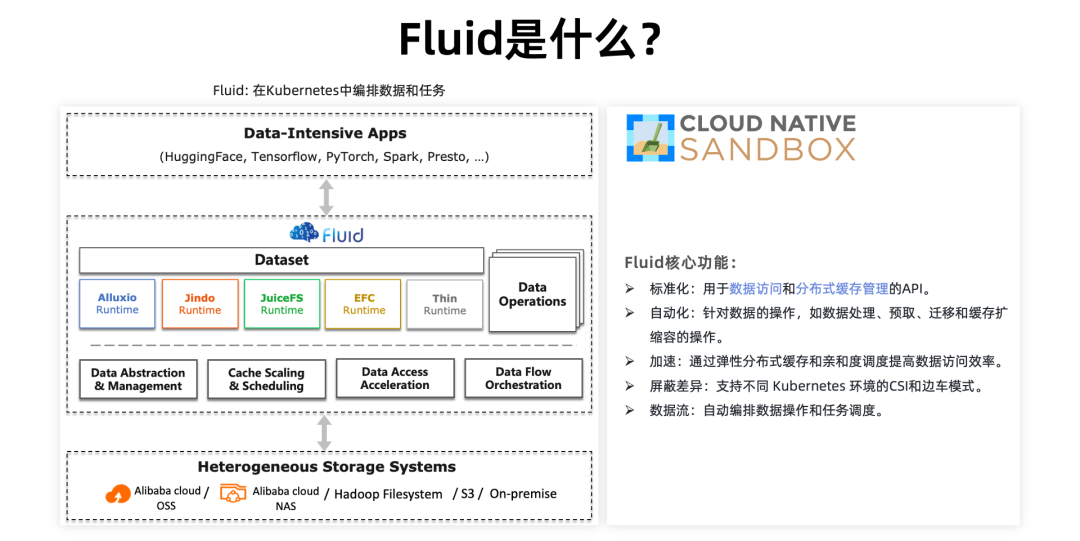
首先,让我们来了解一下 Fluid 的概念。Fluid 负责在 Kubernetes 中编排数据和使用数据的计算任务,不仅包括空间上的编排,也包括时间上的编排。空间上的编排意味着计算任务会优先调度到有缓存数据和临近缓存的节点上,这样能够提升数据密集型应用的性能。而时间上的编排则允许同时提交数据操作和任务,但在任务执行之前,要进行一些数据迁移和预热操作,以确保任务在无人值守的情况下顺利运行,提升工程效率。
从 Fluid 的架构图来看,Fluid 向上对接各种 AI/大数据的应用,对下我们可以对接各种异构的存储系统。Fluid 目前支持了包括 Alluxio、JuiceFS 还有阿里内部自研的 JindoFS、EFC 等多种缓存系统。
具体来说 Fluid 提供 5 个核心能力:
1. 首先是数据使用方式和缓存编排的标准化。
1.1一方面,针对场景化的数据访问模式进行标准化,比如大语言模型、自动驾驶的仿真数据、图像识别的小文件,都可以抽象出优化的数据访问方式。
1.2另一方面,越来越多的分布式缓存出现,比如 JuiceFS,Alluxio,JindoFS,EFC 可以加速不同的存储,但是他们并不是为 Kubernetes 而生。如果在 Kubernetes 上使用它们,需要抽象标准的 API;Fluid 负责将分布式缓存系统转换为具有可管理、可弹性,可观测和自我修复能力的缓存服务,并且暴露 Kubernetes API。
2. 其次是自动化, 以 CRD 的方式提供数据操作、数据预热、数据迁移、缓存扩容等多种操作,方便用户结合到自动化运维体系中。
3. 加速: 通过场景优化的分布式缓存和任务缓存亲和性调度,提升数据处理性能。
4. 随处运行,与 Kubernetes 运行时平台无关: 可以支持原生、边缘、Serverless Kubernetes、Kubernetes 多集群等多样化环境。可以根据环境的差异选择 CSI Plugin 和 sidecar 不同模式运行存储的客户端。
5. 数据和任务编排: 最终连点成线,支持定义以数据集为中心自动化操作流程,定义数据迁移、预热、任务的先后执行顺序依赖。
Fluid 在云原生 AIGC 模型推理场景的优化概述
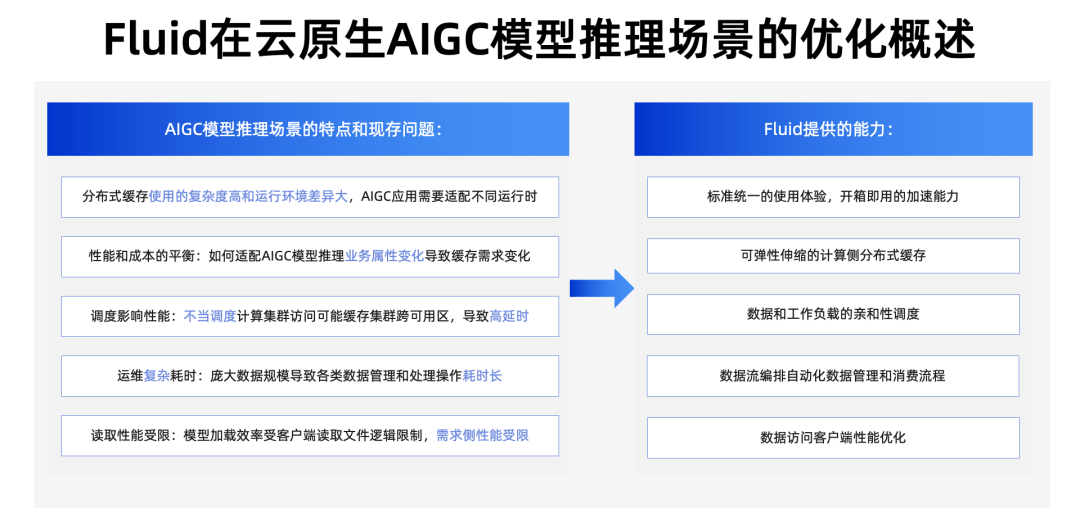
那么回到 AIGC 模型推理场景,Fluid 为这个场景带来了许多优化方案。
首先,分布式缓存使用的复杂度高和运行环境差异大,AIGC 应用需要适配不同运行时,包括 Alluxio,JuiceFS,JindoFS,而运行时环境包括公共云、私有云、边缘云、Serverless 云,Fluid 都可以提供一键部署、无缝衔接的能力。
第二,AIGC 模型推理服务本身有很多灵活多变的业务属性,通过 Fluid 提供的弹性缓存帮您实现需要的时候可以弹出来不用的时候缩回去,能很好地在性能和成本间取得利益最大化。
第三,Fluid 提供数据感知调度能力,将计算尽量调度到离数据更近的地方。
第四,Fluid 的数据流编排能力,帮助用户把很多推理的行为和数据的消费行为自动化起来,减少复杂度。
最后,在性能上,我们也提供了适合云原生缓存的读取优化方案,充分利用节点资源。
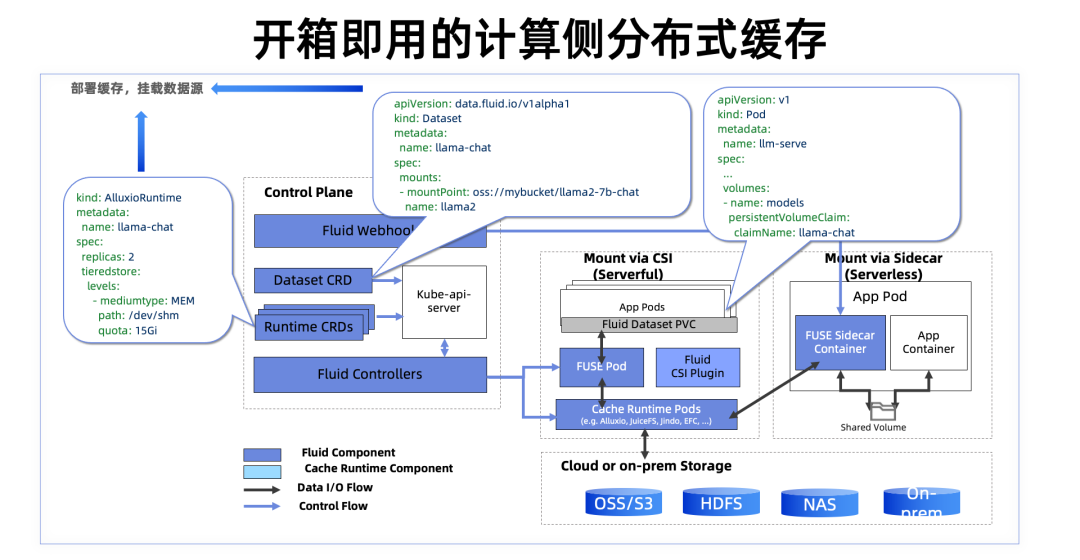
这边是一张 Fluid 的技术架构图。图中可以看到,Fluid 提供 Dataset 和 Runtime 这两种 CRD,它们分别代表了需要访问的数据源和对应的缓存系统。比如在这个例子里面我们使用的是 Alluxio 这个缓存系统,所以对应的就是 AlluxioRuntime 的 CRD。
Dataset 中描述了你需要访问的模型的数据路径,比如 OSS 存储桶中的一个子目录。创建了 Dataset 和对应的 Runtime 后,Fluid 会自动完成缓存的配置、缓存组件的拉起,并自动创建一个 PVC。而对于想要访问这个模型数据的推理应用来说,只需要挂载这个 PVC,就可以从缓存中读取模型数据,这和 K8s 标准的存储方式也是保持一致的。
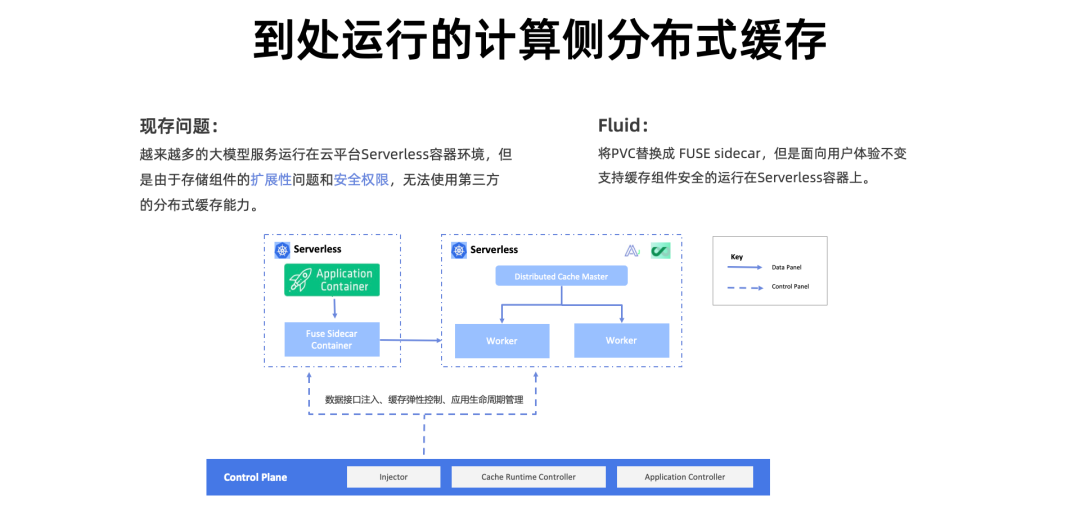
AIGC 推理的运行平台非常多样化,包括云服务的 Kubernetes、自建的 Kubernetes、边缘的 Kubernetes 以及 Serverless 形态的 Kubernetes。Serverless 形态的 Kubernetes 由于其易用性、低负担的好处,已经越来越多的成为用户的选择;但是 Serverless 由于安全的考量,没有开放第三方存储接口,所以只支持自身存储,以阿里云为例子,只有 NAS,OSS,CPFS 有限存储。
在 Serverless 容器平台上,Fluid 会将 PVC 自动转换成可以适配底层平台的 sidecar,开放了第三方的配置接口,可以允许并且控制这个 sidecar 容器的生命周期,保证它在应用容器启动前运行,当应用容器结束后自动退出。这样 Fluid 则提供了丰富的可扩展性,可以运行多种分布式缓存引擎。
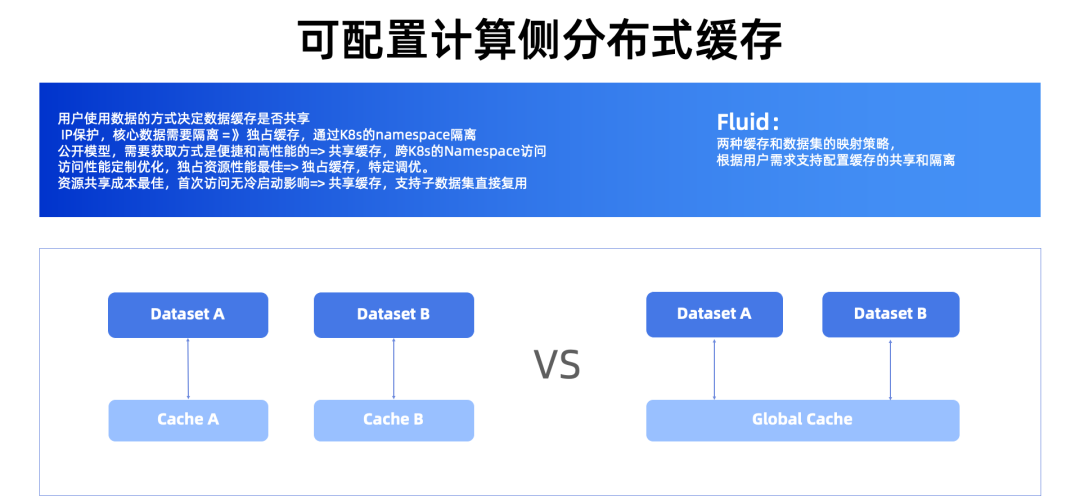
AIGC 模型需要共享还是独占,这不是一个“一刀切”的问题,需要结合真实的业务场景进行选择。有些 IP 保护,核心模型是需要访问隔离,而另一些开源模型则没有这部分的担心。有些模型性能高度敏感,特别一些最流行常用文生图的场景,需要在 20 秒内完成出图,这样 8-10G 的模型加载时间要控制到 5 秒以内。那就需要在缓存侧做吞吐独享、避免竞争、配合特定调优。而对于一些比较新的文生图,用户就需要考虑资源成本。而 Fluid 针对于独占缓存和共享缓存,都提供了完整的支持,通过 Fluid 都可以灵活配置支持。
Fluid 提供的第二个优化是可弹性伸缩的计算侧分布式缓存。这里讲的是如何提供高性能。
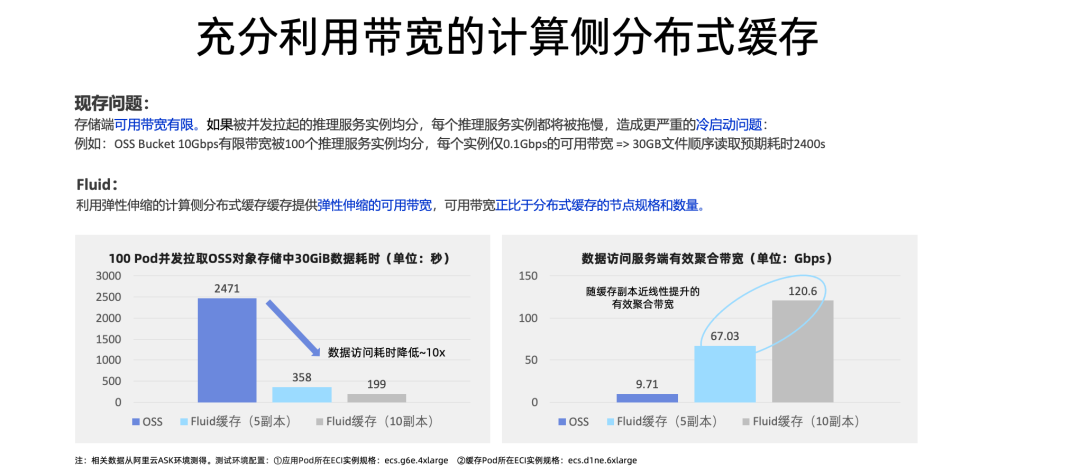
为什么需要弹性伸缩的计算侧分布式缓存?只是使用简单的分布式缓存不够吗?我们可以从技术角度来理解这个问题。在实际的生产场景中,AI 模型推理服务实例往往是多个并发启动的,例如:如果你一次性需要拉起 100 个推理服务实例,每个实例都需要从对象存储中拉取数据,那么每个实例能分到的可用带宽仅有总共可用带宽的百分之一。如果是默认 10Gbps 的 OSSBucket 加载 30G 的模型,这个预期耗时就会是 2400s,而且是每个实例都是 2400s。
事实上,弹性伸缩的计算侧分布式缓存就是把底层存储系统的有限可用带宽转变为了 K8s 集群内可以弹性伸缩的可用带宽,这个可用带宽的大小取决于你分布式缓存的节点数量。从这个角度来说,我们就能根据实际业务场景对于 I/O 的变化需求,变为可随时扩容缩容的分布式缓存集群。
这里有一些测试数据我们也可以看到,如果 100 个 Pod 并发启动,使用缓存都能获得很好的加速效果,而使用更多的缓存 Worker 节点,效果会更好。主要的原因就来自于更大的聚合带宽,使得每个 Pod 均分得到的带宽更多。从右边这张图也可以看到,当你使用更多的分布式缓存节点的时候,聚合带宽也是近线性地提升的。
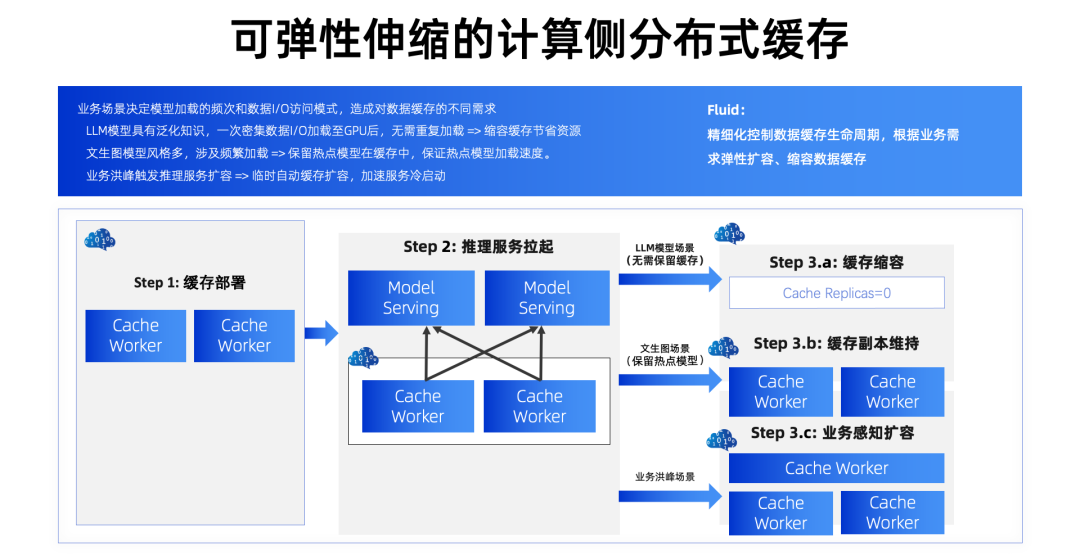
介绍完如何提升性能之后,接下来考虑的问题就是如何在尽可能节省成本的前提下最大化缓存带来的性能提升, 如何在成本和性能间取得平衡实质上是与业务场景的 I/O 访问模式相关的。Fluid 在缓存上暴露的可观测性,配合手动扩缩容、HPA、CronHPA 等 K8s 的扩缩容能力,可以根据业务需求弹性扩容、缩容数据缓存。我们可以举几个具体的例子:
对于大语言模型场景,大语言模型一个特点是拥有很强的泛化知识,因此把一个 LLM 加载到 GPU 显存后,它其实可以为多种不同的场景提供服务。因此这种业务的数据 I/O 特点是一次性对 I/O 有很高的要求。对应到缓存的弹性上来,就是一个先扩容,推理服务就绪后缩容到 0 的过程。
再来看文生图 Stable Diffusion 的场景,假如是一种 SD 模型市场的场景,那就会包含大量不同风格的 SD 模型,因此尤其对于热点模型,会有持续的 I/O 需求,此时保持一定的缓存副本就是更好的选择。
而无论哪种场景,如果因为业务洪峰造成服务端需要扩容,数据缓存可以跟随它做临时扩容,缓解扩容时的冷启动问题。
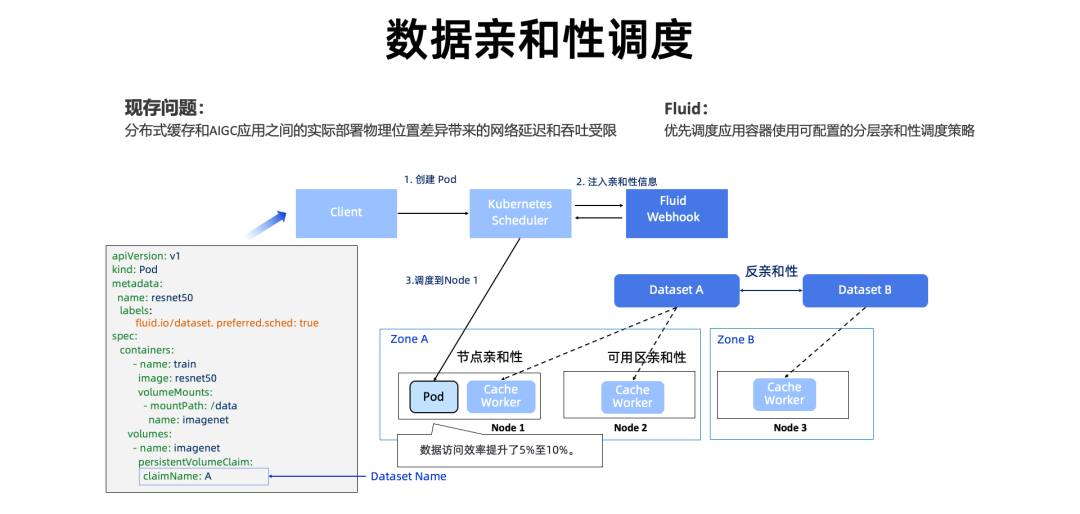
公共云提供灵活的弹性能力和高可用性,这是通过底层的多可用区实现的,多可用区对于互联网应用非常合适;它牺牲一点点的性能获得了应用稳定性。但是在 AIGC 大模型场景上,通过实际验证,我们发现跨可用区的延时还是有很大的影响,这是因为大模型文件一般比较大,它传的包就会非常多,对延时起到放大的作用。因此缓存和使用缓存应用之间的亲和性就非常重要,Fluid 提供无侵入性的亲和性调度,根据缓存的地理位置调度应用,优先同可用区调度;同时提供了弱亲和性和强亲和性的可配置性,帮助用户灵活使用。
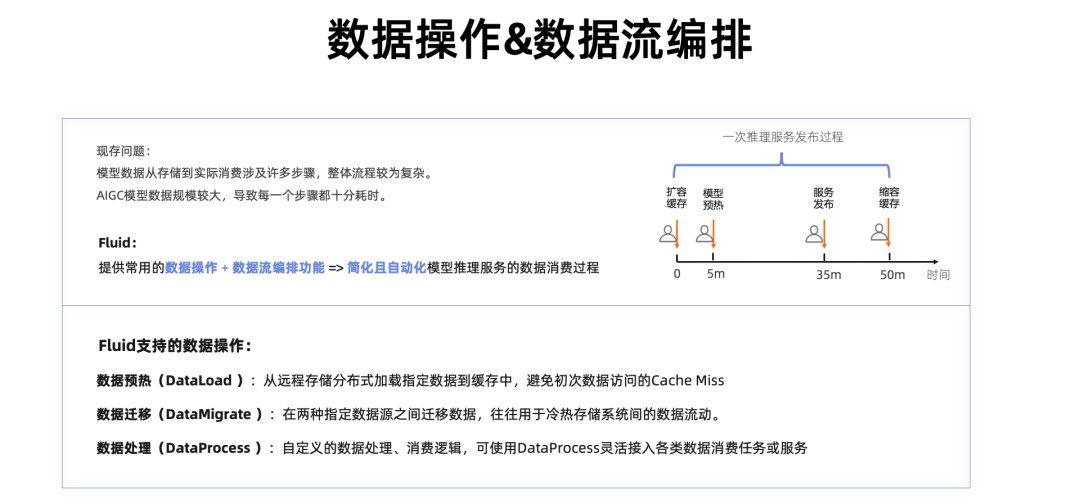
现在我们理解了弹性的缓存架构的必要性和优势,但实际用起来也许还是会有一些麻烦。
让我们试想这么一个流程,今天有个新的 AI 模型推理业务需要发布上线,为了避免服务冷启动,你先需要部署了一个分布式缓存并扩容到了一定的副本数,接下来你把待发布的模型数据预热到分布式缓存中避免 Cache Miss(这个过程可能要花 30min),最后你拉起 100 个服务实例,等到 100 个服务实例启动完成,这个过程又要花费 10~20 分钟;最后,确认服务上线没问题后,把缓存缩容掉减少成本。
这个过程中的每一步每隔一段时间就需要人工参与,确认状态并执行下一步。数据访问和消费过程运维过程复杂,耗时费力。
Fluid 为了解决这个问题,我们把数据消费过程定义为业务使用数据缓存的过程,以及系统准备数据缓存的过程,对于这些流程我们用数据操作抽象以及数据流编排能力去帮助用户自动化。比如最常见的与数据缓存相关的操作,像是数据迁移、预热以及和业务相关的数据处理,Fluid 都提供了 K8s 级别的抽象去描述。
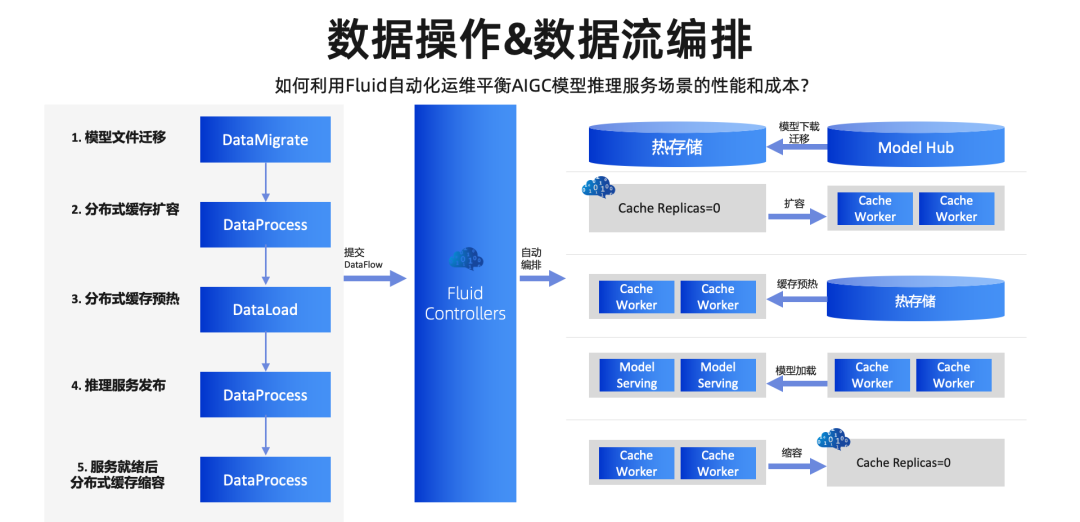
这些数据操作可以串联成一条数据流。于是刚才我们提到的这个例子,就可以用 5 步数据操作来轻松定义。运维人员只需要一次性提交这条数据流,Fluid 自动地会完成整个 AI 模型推理服务发布的流程,提升使用缓存过程的自动化比例。
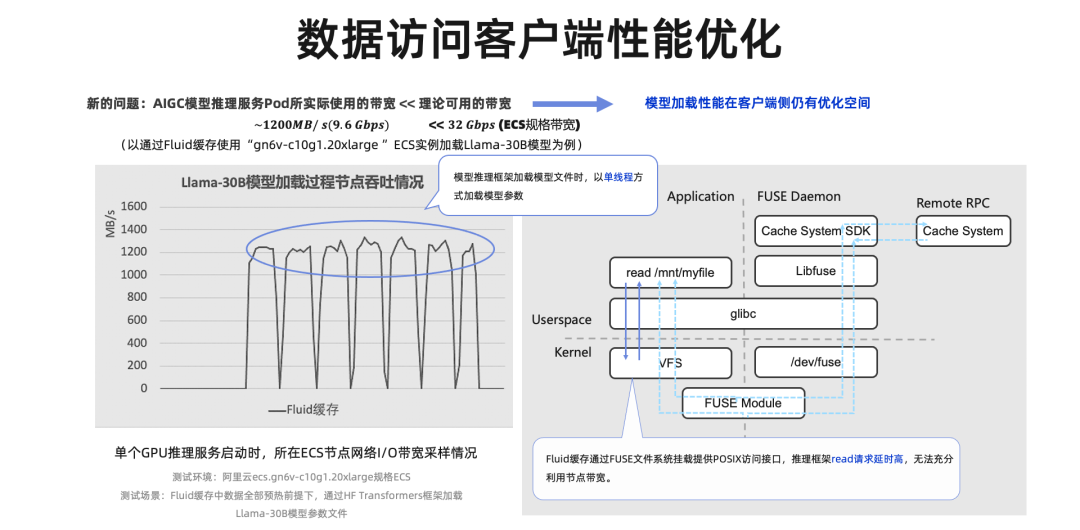
那么刚才提到的“用好缓存”的技巧其实都在资源成本和运维效率方面。但实际测试过程中我们发现,服务启动过程使用的带宽远小于这些 GPU 计算实例可用的带宽,这意味着模型的加载效率在客户端上仍然有可以优化的空间。
从节点吞吐情况上可以看到,这些 AI 推理的运行时框架会以单线程的方式去按序读取模型参数,这在非容器环境是没有什么问题的,如果使用本地 SSD 盘存储模型参数,加载吞吐很容易就可以到达 3~4GB/s。但是在计算存储分离架构下,哪怕我们使用了缓存,缓存也需要使用用户态文件系统(也就是 FUSE)这种技术挂载到容器中。FUSE 自身的开销和额外的 RPC 调用,都使得 read 请求的延时变得更高,单线程所能达到的带宽上限也就更低了。
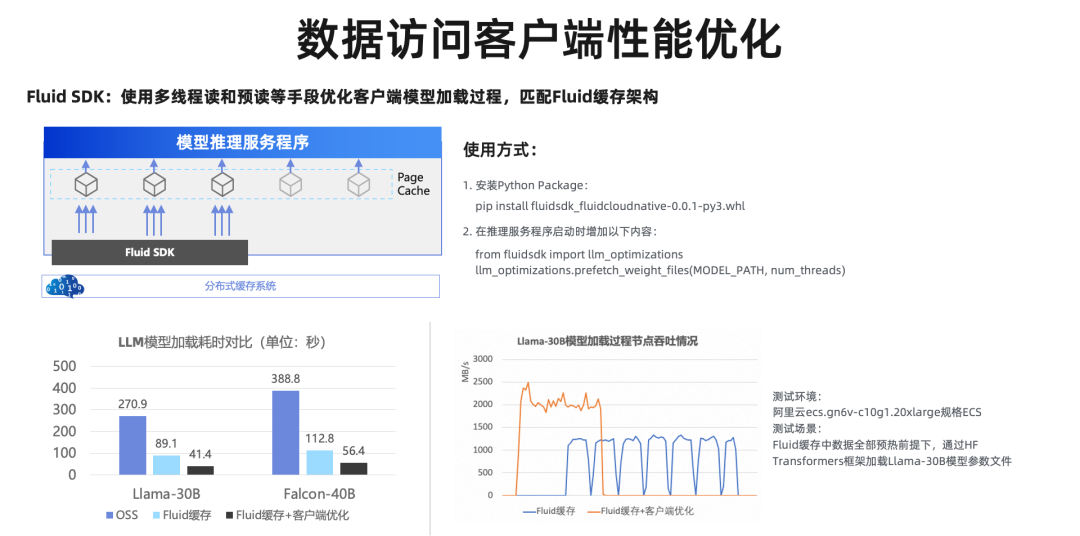
为了最大化发挥分布式缓存提供的巨大 I/O 吞吐,Fluid 可以提供一个 Python 的 SDK,在用户代码中使用多线程读和预读的方式去加速模型加载过程。从我们的测试结果来看,额外使用这种客户端的优化,可以在使用计算侧分布式缓存的基础上,将冷启动耗时缩短一半,做到 1 分钟内拉起一个接近 100G 的大模型。从右下角的这个 I/O 吞吐情况,也可以看出,我们更充分地利用了 GPU 计算节点的带宽资源。

为了评估 Fluid 的性能,我们采用了 HuggingFace Text-Generation-Inference 框架来构建大型语言模型(LLM)的推理服务。我们将模型存储在 OSS 对象存储中,并对用户体验以及直接从 OSS 对象存储拉取与通过 Fluid 拉取数据启动推理服务的性能差异进行了对比分析。
我们首先看一下直接访问 OSS 存储的运行效果。这里我们已经创建好了 OSS 的 PV 和 PVC。
接着,我们定义一个 deployment:deployment Pod 中挂载刚才的 OSS PVC,使用的容器镜像是 TGI 镜像。还有声明使用 1 张 GPU 卡,用于模型推理。接着把 deployement 创建下去。然后我们看下这个服务的就绪时间,这边 5 倍速加速了一下。终于就绪了,可以看到整个过程耗费了 101s,考虑到我们的模型大小仅为 12.55G,这个时间可以说是比较长的。
最后,让我们看看 Fluid 的优化效果。我们需要定义 Fluid 的 Dataset 和 Runtime 资源,并将分布式缓存部署到集群中。定义数据源、节点个数以及缓存数据的存储介质和大小。由于我们是初次部署弹性分布式缓存,这可能需要约 40 秒的时间。缓存准备完成后,我们可以看到一些缓存的监控信息。PVC 和 PV 也会自动创建。然后,我们定义一个新的 deployment,只需要进行几个修改:
- 添加一个 annotation 来触发 Fluid 的自动数据预热
- 将 OSS 的 PVC 更改为由 Fluid Dataset 自动创建的 PVC
- 替换为一个使用了客户端优化的镜像
观察服务的就绪时间,我们可以看到部署只花了 22 秒。我们还可以尝试对现有的 deployment 进行扩服务器托管网容,观察第二个服务实例的启动时间。由于所需的模型数据已被完全缓存,第二个服务实例只需 10 秒就能准备就绪。这个例子展示了 Fluid 优化的效果,我们成功提升了服务的启动速度约 10 倍。
总结
Fluid 为 AIGC 模型弹性加速提供开箱即用、优化内置的方案,在达到更好性能的同时还可以降低成本,同时还包含端到端的自动化能力;在此基础上使用 Fluid SDK 可以进一步充分发挥 GPU 实例的带宽能力实现极致的加速效果。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: cpu 支持内存带宽与内存最大长度的关系《鸟哥的 Linux 私房菜》
鸟哥的 Linux 私房菜 — 计算机概论 — 計算机:辅助人脑的好工具 同理,64 位 cpu 一次接受内存传递的 64bit 数据,内存字节地址用 64 位记录,最多能记录2^64个字节=2^64Bytes=2^34GB=17179869184GB=2…
