
导读
本文主要讲解了京东百亿级商品车型适配数据存储结构设计以及怎样实现适配接口的高性能查询。通过京东百亿级数据缓存架构设计实践案例,简单剖析了jimdb的位图(bitmap)函数和lua脚本应用在高性能场景。希望通过本文,读者可以对缓存的内部结构知识有一定了解,并且能够以最小的内存使用代价将位图(bitmap)灵活应用到各个高性能实际场景。
1.背景
整个汽车行业行特殊性,对于零配件有一个很强的对口特性,不同车使用的零配件(例如:轮胎、机油、三滤、雨刮、火花塞等)规格型号不一样。在售卖汽车零配件的时候,不能像3C家电、服饰,需要结合用户具体车辆信息,推荐适合的配件商品。基于此原因,京东自建人车档案模型并且利用算法清洗出百亿级的车型-零配件的适配关系数据,最终形成“人->车-〉货”关系链路,解决“人不识货”的问题。 具体使用场景如下图:
.
图1.1京东商详推荐商品 图1.2京东加购弹窗推荐商品
2.数据模型
“人-> 车->货”关系的核心链路是由人(京东用户)、乘用车和SKU这三部分组成。
首先,用户在京东APP的商搜页、商详页多个位置都可以选择自己的车型信息进行绑定(例如:图2.1,京东商详绑车入口位置“+添加爱车”按钮),建立“人车档案”数据。
.

图2.1.京东商详绑车入口位置 图2.2.京东商搜绑车入口位置
其次,运营在后台管理系统中将商品与车型进行绑定,建立“商品与车型关系”数据(商品与车型的关系数据量级在百亿级别)。
最终,购买商品的时候,京东推荐系统可以通过用户自己绑定的车型推荐出适合该车型的商品。具体商品适配车型数据模型,见图2.3。

图2.3京东商品适配车型数据模型
3.缓存结构设计
基于前面两个部分的介绍,我们可以了解到整个商品搜索适配推荐存在两个最核心问题。第一、百亿级商品适配车型数据的存储结构设计,尽可能的占用资源成本最小;第二、商详通过用户车型来搜索适配商品时,必须保证接口性能的TP99位于毫秒级。最终技术选型的时候,采用了jimdb的位图(bitmap)函数来进行数据存储。
3.1位图(bitmap)结构
位图(bitmap)是通过最小的单位bit来进行0或者1的设置,表示某个元素对应的值或者状态。一个bit的值是0或者1;也就是说一个bit能存储的最多信息是2。
位(bit):计算机内部数据存储的最小单位,例如:11001100是一个八位二进制数。
字节(byte):计算机中数据处理的基本单位,习惯上用大写B来表示,1B(byte,字节)=8bit。
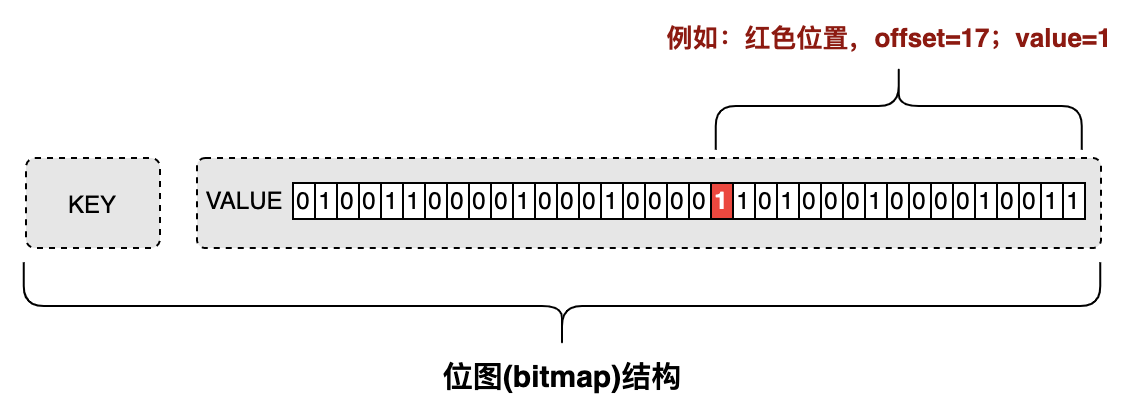
图3.1位图(bitmap)内部结构
3.2位图(bitmap)数据写流程
位图(bitmap)是基于jimdb的SDS(简单动态字符串)类型的一系列位操作,遵循jimdb的SDS特性,例如:位图(bitmap)最大长度512M,最大可以存储232位。以下是“big”字符串的SDS结构示例:
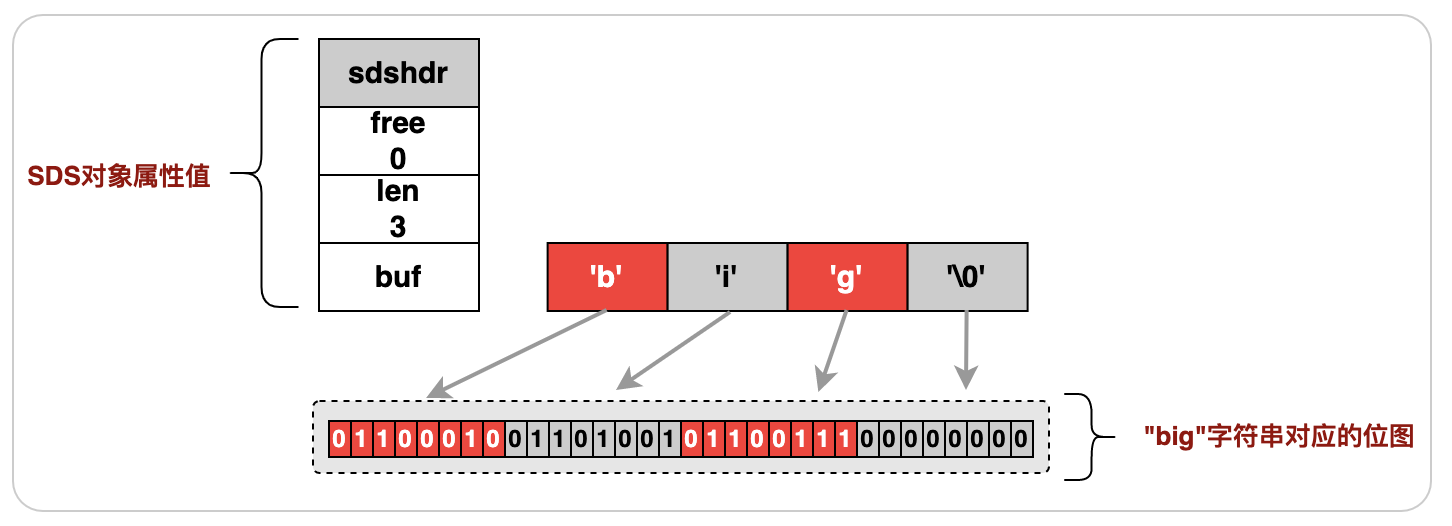
图3.2.1“big”字符串的SDS结构
SDS(简单动态字符串)为了保证性能采用了空间预分配的策略:空间预分配用于优化SDS的字符串增长操作。SDS的API对一个SDS进行修改并且需要对SDS进行空间扩展的时候,程序不仅会为SDS分配修改所必须要的空间,还会为SDS分配额外的未使用空。具体预分配流程图如下:

图3.2.2SDS预分配流程图
位置1:创建SDS简单字符串预分配空间为:偏移量/8+1。
位置2:剩余空间不足时,预分配空间流程。
3.3压缩商品与车关系缓存
| 偏移量(自增ID) | 全量车型 | 商品SKU |
|---|---|---|
| 1 | 1165788 | 101362 |
| 2 | 1165793 | 101362 |
商品适配车型关系(百亿级数据量)
商品与车关系缓存存储过程中,采用了商品SKU作为KEY,全量车型ID的偏移量(采用偏移量是为降低内存消耗)作为VALUE值来进行存储。
全量车型ID大约有几十万的数据量,极限情况下一个商品SKU可以适配几十万辆车,很容易造成缓存大KEY的问题,为此我们进行了偏移量(全量车型ID对应的自增ID)的分段处理。具体是按照:SKU作为缓存KEY的基础上,追加一个分段标记数字作为新KEY,每个偏移量都会按照分段范围对应一个分段标记数字。例如:偏移量1~50000,对应缓存KEY为SKU+0;偏移量50001~100000,对应缓存KEY为SKU+1,其它偏移量以此类推,这样就保证了一个SKU即使适配所有车辆也不会出现缓存大KEY的情况。
BitMap缓存结构底层使用SDS简单字符串,为了保证性能采用了预分配空间的策略(图3.2.2,“缓存BitMap内部存储流程图”的“位置2”中虚线框圈选),这样在缓存商品与车关系的时候浪费了大量的缓存空间。为此我们调整了偏移量存储顺序,首先获取到需要缓存的车型内最大的偏移量,保证同一个缓存KEY第1次创建SDS简单字符串(图3.2.2,“缓存BitMap内部存储流程图”的“位置1”中虚线框圈选)后,不再进行第2次空间扩容,这样来最大限度的提升缓存利用率,起到压缩空间目的。缓存数据关系流程如下:
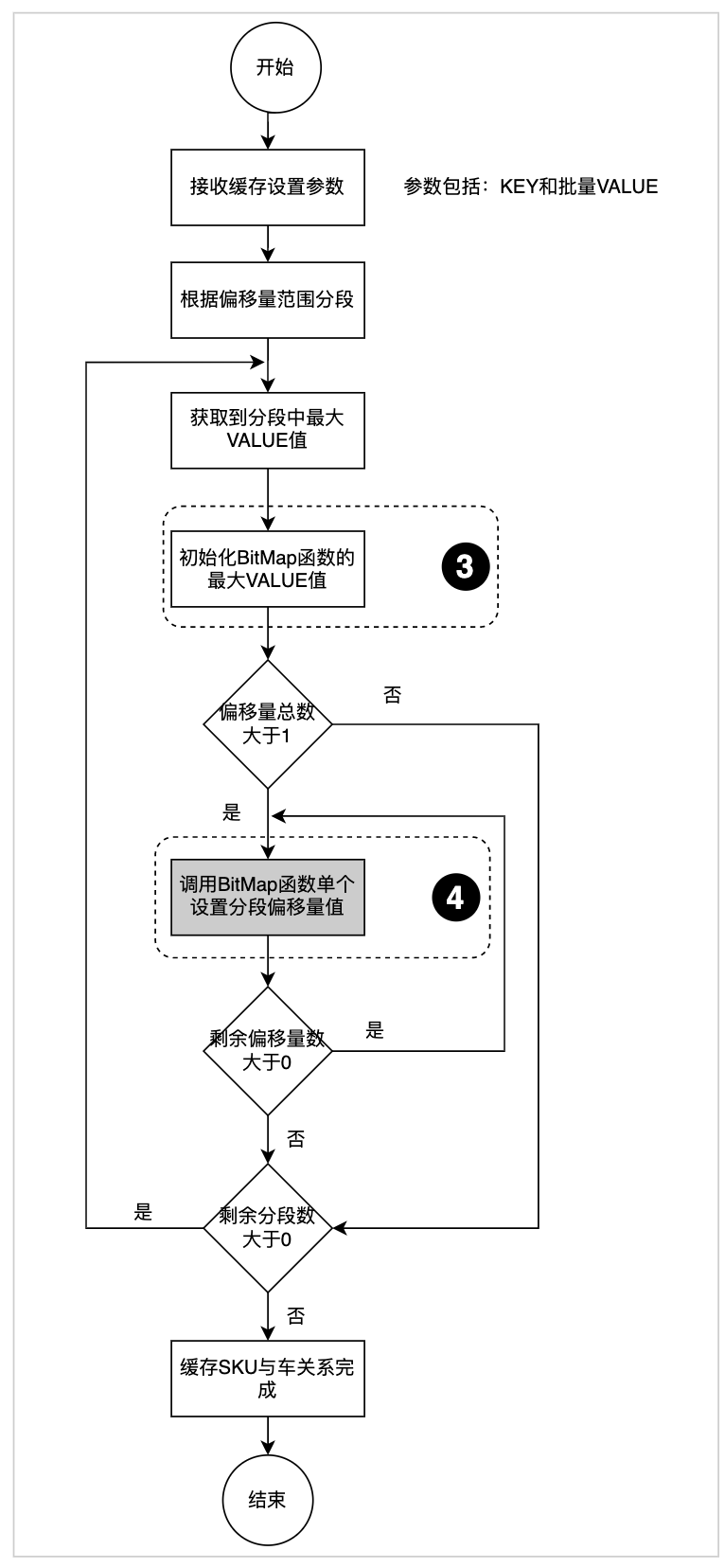
图3.3.1缓存数据关系流程
位置3:设置分段最大的偏移量,保证后续新增偏移量不再扩容空间。
位置4:设置分段较小的偏移量。
全量车型ID是定长7位的数字,如果用它作为偏移量将消耗内存巨大,所以采用对应自增ID作为偏移量。最终在bitmap缓存的商品SKU与车的适配关系缓存结构如下图:
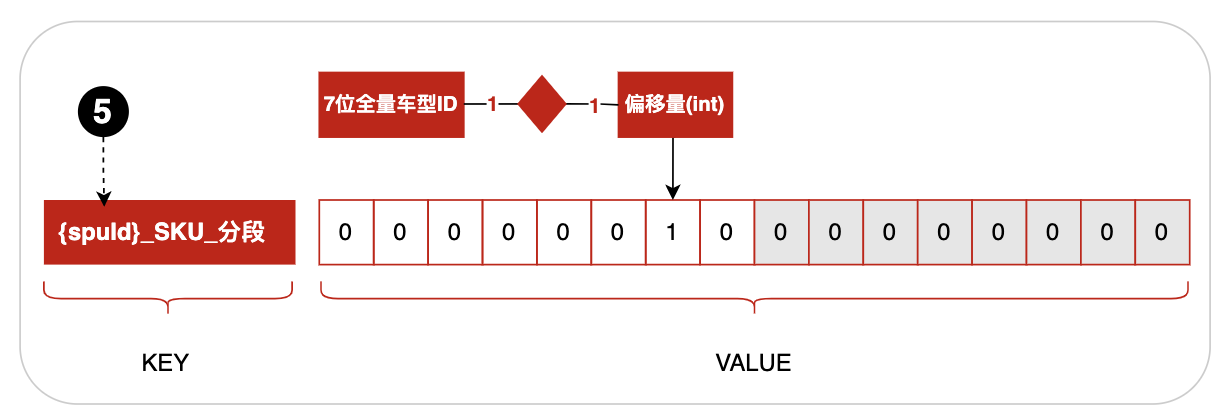
3.3.2商品与车缓存结构图
位置5:spuId用{}括起来表示缓存路由(Lua脚本中同一次请求,数据必须在缓存同一个分片上,否则会丢失数据)。POP商品spuId是SKU的产品ID,自营商品spuId是SKU的MainSkuId。
备注:
1、自营商品MainSkuId可能发生变化,所以我们接入了商品变化MQ消息,实时调整SKU与车适配关系的存储位置。
2、京东商详页面中每个不同的规格/型号分别对应不同的SKU,但是它们都对应同一个SpuId或者MainSkuId。
4.缓存架构设计
商品与车的关系数据量每天都在不断增长,要求缓存架构设计,需要支持集群横向/纵向扩容和来满足业务发展以及高可用性。整个缓存架构体系主要有前端、京东养车商品与车关系层和存储三部分组成。
“商品与车关系缓存架构”层核心包括:1、“集群路由”层,实现了集群横向扩容,保证数据量增涨的时候,缓存容量也能跟上。2、“分片路由”层,保证搜索的底层数据的分片相同,避免数据丢失。
“存储”层核心包括:1、实现了缓存压缩,参见3.3压缩商品与车关系缓存。2、单元化实现跨区域灾备,保障大促系统稳定性。具体商品与车关系缓存架构如下:
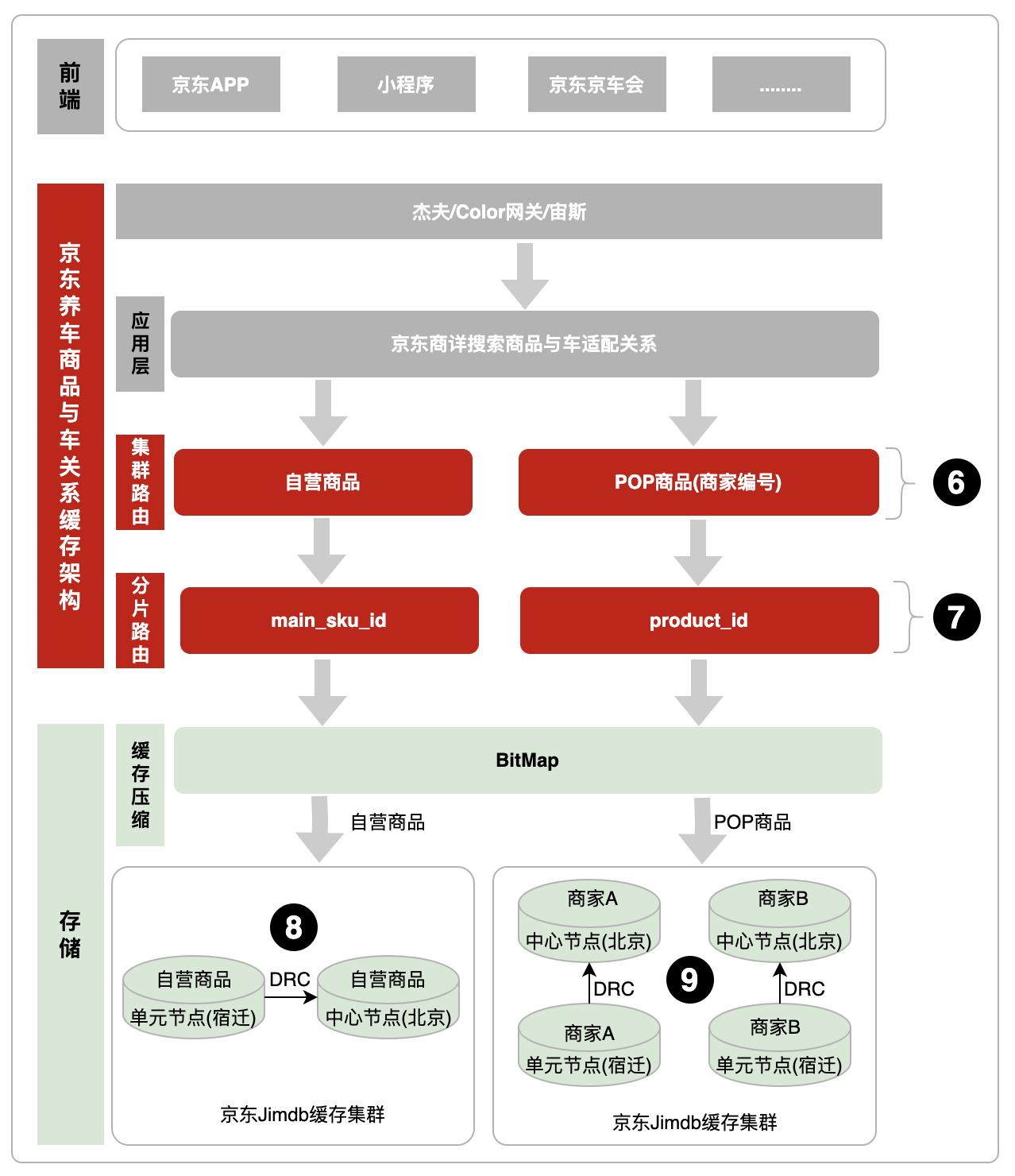
4.1商品与车关系缓存架构图
位置6:集群路由,通过商品类型或者商品编号(POP商品)路由到不同缓存集群,便于横向扩展,每个集群单分片限制,解决分片超过限制问题。
位置7:分片路由,保障Lua脚本搜索数据的底层数据集群分片相同,避免数据丢失。其中自营商品和POP商品的路由分别是main_sku_id和product_id。
位置8:自营商品缓存集群,单元化实现跨区域灾备,采用自研DRC(Data Replication Center)数据同步机制。
位置9:POP商品缓存集群,通过商家编号拆分为两个子集群。
5.高性能搜索
基于BitMap(位图)缓存的商品与车关系数据,商详调用接口的内部实现采用了Lua脚本来降低网络开销,保障整个接口的性能。以下是搜索接口的流程图:

5.1商详搜索商品与车适配关系流程图
位置10:商详调用接口的时候,要传两个参数。第1个参数是全量车型ID列表,大约5个全量车型ID。第2个参数是商品SKU列表,SKU的数量极限超过200个。最后全量车型ID与商品SKU组合为上千个商品与车的关系后,再到百亿级适配关系去搜索看是否匹配的。如果不匹配返回适配商品,反之则返回不适配。
Lua脚本减少了应用服务器与缓存服务器的交互,降低了网络开销的时间,达到提升搜索服务的性能。以下是Lua脚本具体代码:

5.2商详搜索商品与车适配关系Lua代码
基于以上缓存设计和Lua脚本的使用,整个接口T999小于13ms。具体的接口性能监控如下图:
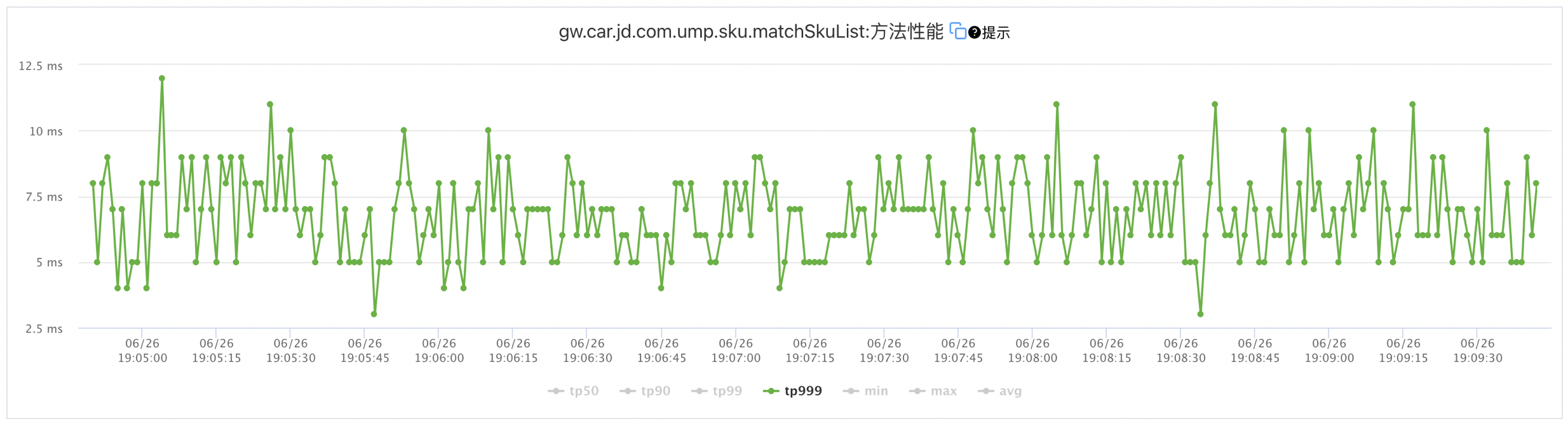
5.3商详搜索商品与车适配关系接口性能
6.总结
整个缓存结构设计的时候,使用BitMap(位图)来存储数据。解析SDS的内部存储流程,通过存储流程机制避开预分配空间节点,最大限度的利用缓存空间,避免资源浪费。采用Lua脚本来实现数据的适配搜索,降低网络开销,进一步提升接口的性能。希望此文对大家后续设计类似场景有一定的帮助和启发。
作者:京东零售 张强
内容来源:京东云开发者社区
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
