
运维自动化之域名系统的文章发出去之后,有小伙伴问既然拿到了域名及所有基础资源数据,那能不能从入口域名开始实现全链路自动化的系统拓扑构建?全链路的系统拓扑构建需要知道链路上所有节点之间的数据流转关系,之前在落地APM监控时有接触过,APM通过代码埋点拿到链路节点之间的数据流转关系,而流转关系仅通过基础资源是没有办法获取的,除非人工维护,人工往往不靠谱,代码埋点成本又太高,还是要从这些基础资源数据出发,寻求简洁点自动化解决方案。今天刚好有空就简单想了下这个问题,初步实现,效果如下
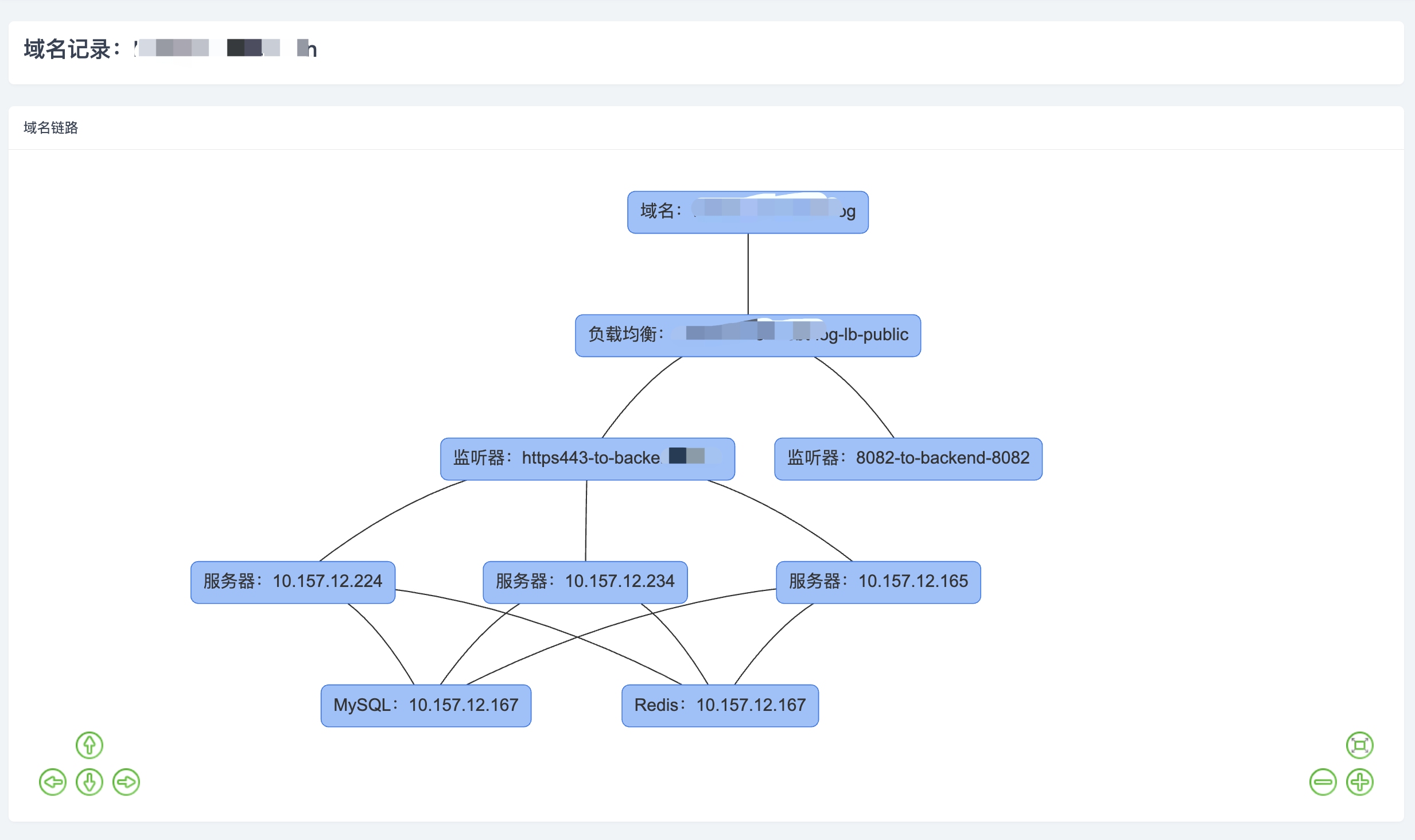
这篇文章就简单介绍一下我的实现方案,并不完美,甚至还有很多问题,欢迎探讨。这里有个前提就是无法通过埋点拿数据
域名可能指向到负载均衡、服务器、CDN、高防或者是CNAME到其他的域名,有一部分数据流转关系我们是确定的,那就是域名到服务器这一段,以上图域名指向负载均衡为例,域名到负载均衡的解析是固定的,然后可以通过负载均衡拿到监听器的数据,再通过监听器就能获取监听器下挂的服务器。再往下服务器究竟使用了哪些中间件我们就没办法获取了,如何知道接下来的数据链路呢?这里提供几个思路
子网
我们通常会拿不同的子网来做网络隔离,如果你的网络规划非常标准,一个项目/服务位于同一个子网下,不同项目/服务之间子网隔离,那就可以考虑使用这种方式
服务器数据已经拿到了,那服务器的子网也就是确定的了,就可以很容易的获取同一子网下的其他资源数据,例如数据库、缓存等等
这种方式的准确率取决于网络的规范程度
名称
如果子网划分不规范,存在多个项目/服务使用同一子网的情况,那上边的方法就不奏效了。此时如果你的资源命名都是规范的,也可以通过规范的资源名称来获取下一层的数据
例如如下命名:projec服务器托管网t-environment-service-name。同一项目同一环境同一服务不同资源的命名仅有最后一部分不同,那就可以遍历资源,获取到相同命名规则的资源,也能继续进行下一级的自动拓扑
这种方式的准确率取决于命名的规范程度
关系树
如果以上两种都没有,那还可以通过服务树来获取,我们在构建多云系统时确定,所有资源都隶属于服务树上的某个节点,服务树往往是规范的,那获取与服务器同一服务树节点下的其他资源也是属于同一个业务,之间的数据流向几乎也是确定的
这种方式的话就要求你的服务树是规范的
很明显,虽然可以通过以上几种方式来获取最后一段的关系数据,但都不够准确,尤其是在业务逻辑比较复杂的情况下,仅是做个参考而已。几个小时的时间从思服务器托管网考到编码实现,有很多不完善的地方,此文也就抛砖引玉
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
作者 |wunan 导读 日志中中台每日传输的日志PV量级可达千亿级,在上报过程中减少冗余日志数据,能够降低下游数据处理的难度和成本,提高数据的准确性和质量,更好地支持业务系统的运行和优化。本文介绍了UBC SDK对日志重复打包的优化实践,通过对数据库、进程和…
