
InnoDB 是如何存储数据的?
MySQL支持多种存储引擎,不同的存储引擎,存储数据的方式也不相同,我们最常使用的是 InnoDB 存储引擎。
在数据库中的记录是按照行来存储的,但是数据库的读取并不是按照 [ 行] 为单位,否则一次读取只能处理一行数据,效率会非常低
因此,InnoDB 的数据是按 [ 数据页 ] 为单位进行读写的,也就是说,当需要读一条记录的时候,并不是将这条记录本身从磁盘中读出来,而是以页为单位,将其整体读入内存。
数据库的 I/O 操作的最小单位是页,InnoDB 数据页的默认大小是 16 KB,意味着数据库每次读写都是以 16KB 为单位的,一次最少从磁盘中读取 16K 的内容到内存中,一次最少把内存中的 16K 内容刷新到磁盘中。
数据页包含七个部分,结构如下:
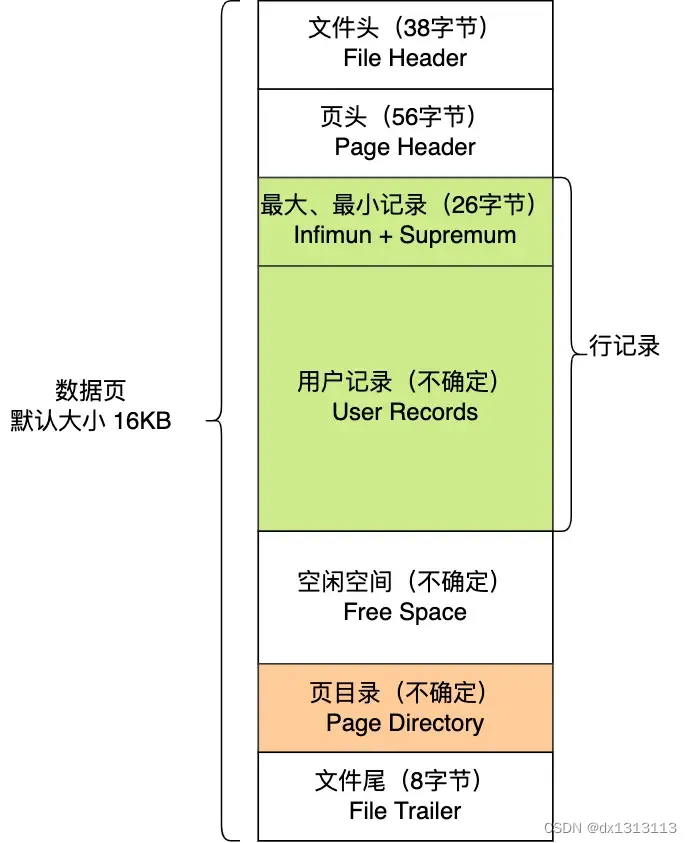
这七个部分的作用如下图:

在File.Header 中有两个指针,分别指向上一个数据页和下一个数据页,连接起来的页相当于一个双向的链表,如下图所示:
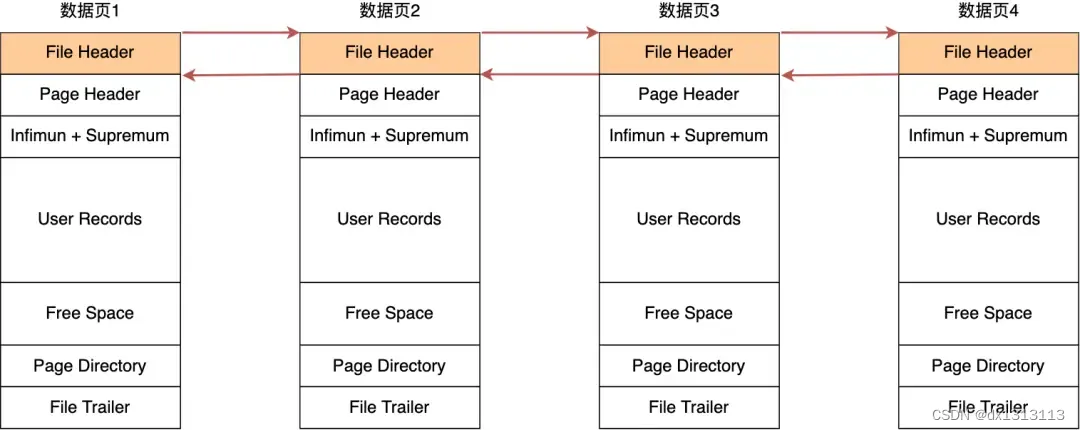
采用链表的结构是让数据页之间不需要物理上是连续的,而是逻辑上的连续。
数据页的主要作用是存储记录,也就是数据库的数据,所以重点说一下数据页中 User Records 是怎么组织数据的。
数据页的记录按照 [主键] 顺序组成单向链表,单向链表的特点就是插入、删除非常方便,但是检索效率不高,最差的情况下需要遍历链表上的所有节点才能完成检索。
因此,数据页中有一个页目录,起到记录的索引作用,就像书的目录一样,书中内容的每个章节都设立了一个目录,想看某个章节的时候,可以查看目录,快速找到对应的章节的页数,而数据页中的页目录就是为了能快速找到记录。
那么InnoDB 是如何给记录创建页目录的呢?页目录与记录的关系如下图:

页目录的创建过程如下:
- 将所有的记录划分为几组,这些记录包含最小记录和最大记录,但不包括标记为“已删除”的记录;
- 每个记录组的最后一条记录就是组内最大的那条记录,并且最后一条记录的头信息中会存储组一共有多少条记录,作为 n_owned 字段。
- 页目录用来存储每组最后一条记录的地址的偏移量,这些偏移量会按照先服务器托管网后顺序存储起来,每组的地址偏移量也被称为槽(slot),每个槽相当于指针指向了不同组的最后一个记录。
从图中可以看到,页目录就是由多个槽组成的,槽相当于分组记录的索引。然后,因为记录是按照 [主键值] 从小到大排序的,所以我们通过槽查找记录时,可以使用二分法快速定位要查询的记录在哪个槽(哪个记录分组),定位到槽后,再遍历槽内的所有记录,找到对应的记录,无需从最小记录开始遍历整个页中的记录链表。
举个例子,上图 5 个槽的编号分别为 0,1,2,3,4 ,想要查找主键为 11 的用户记录:
- 先二分得出槽中间位是 (0 + 4 )/2 = 2,2号槽里最大记录为 8。因为 11 > 8 ,所以需要从 2 号槽后继续搜索记录;
- 再使用二分搜索出 2 号和 4 号槽的中间位是 (2+4)/2=3,3号槽里最大记录为 12.因为 11
- 问题:[槽对应的值都是这个组的主键最大的记录,如何找到组里最小的记录]?比如 3 号槽对应的最大主键是 12,那么如何找到最小记录 9? 解决办法:通过槽 3 找到 槽 2 对应的记录,也就是主键为 8 的记录。主键为 8 的记录的下一条记录就是槽 3 当中主键最小的 9 记录,然后开始向下搜索 2 次,定位到主键为 11 的记录,取出该记录的信息即为我们想要找到的内容。
InnoDB对每个分组的记录条数是有规定的,槽内的记录就只有几条:
- 第一个分组中的记录只有一条
- 最后的分组中的记录条数在 1- 8 之间
- 中间的分组记录条数在 4 – 8 之间
因此,虽然组内的记录是使用单链表连接的,但是每次查询时间复杂度由于记录少所以并不高。
B+Tree 是如何进行查询的?
上面说的都是一个数据页中的记录检索,因为一个数据页中的记录是有限的,且主键值是有序的,所以通过对所有记录进行分组,然后将组号(槽号)存储到目录,使其起到索引作用,通过二分查找的方法快速检索到哪个分组,来降低检索的时间复杂度。
但是,当我们需要存储大量的记录时,就需要多个数据页。磁盘的I/O操作次数对索引的使用效率至关重要,才能方便定位记录所在的页。
为了解决这个问题,InnoDB 采用了 B+Tree 作为索引。磁盘的I/O操作次数对索引的使用效率至关重要,因此在构造索引的时候,更倾向于采用 “矮胖”的 B+Tree 数据结构,这样所需要进行的磁盘 I/O 次数更少,而且 B+Tree 更适合进行关键字的范围查询。
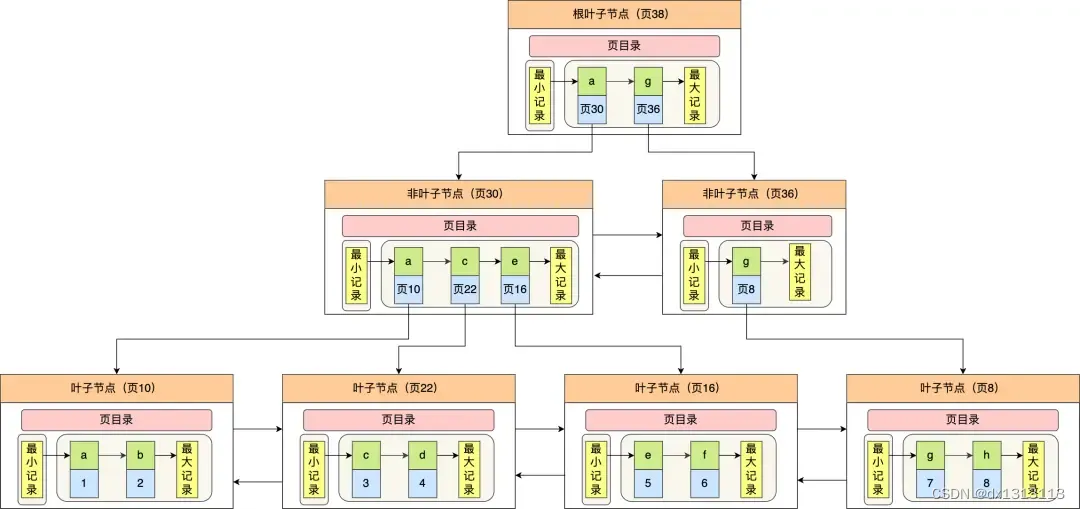
InnoDB 里的 B+Tree 中的每个节点都是一个数据页,结构示意图如下:

通过上图可以看到 B+Tree 的特点:
- 只有叶子节点(最底层的节点)才存放了数据,非叶子节点仅用来存放目录作为索引
- 非叶子节点分为不同层次,通过分层来降低每一层的搜索量
- 所有的节点按照索引键的大小排序,构成一个双向链表,便于范围查询
来看看 B+Tree 如何实现快速查找主键为 6 的记录,以上图为例子:
- 从根节点开始,通过二分法快速定位到符合页内范围包含查询值的页,因为查询的主键值为 6 ,在 [1,7) 范围之间,所以到 页30 中查找到更详细的目录项;
- 在非叶子节点(页30)中,继续通过二分法快速定位到符合页内范围包含查询值的页,主键值大于 5,所以就到叶子节点(页16)中查找记录;
- 接着,在叶子节点(页16),通过槽查找记录时,使用二分法快速定位要查询的记录在哪一个槽(记录分组),定位到槽后,再遍历槽内的所有记录,找到主键为 6 的记录。
可以看到,在定位记录所在哪一个页时,也是通过二分法快速定位到包含该记录的页。定位到该页后,又会在该页内进行二分法快速定位记录所在的分组(槽号),最后在分组内进行遍历查找。
聚簇索引和二级索引
另外,索引又可以分为聚簇索引(主键索引)和非聚类索引(二级索引),它们的区别就在于叶子节点存放的是什么数据:
- 聚簇索引的叶子节点存放的是实际数据,所有完整的用户记录都存放在聚簇索引的叶子节点
- 二级索引的叶子节点存放的是主键值,而不是实际数据
因为表的数据都是存放在聚簇索引的叶子节点里,所以 InnoDB 存储引擎一定会为表创建一个聚簇索引,且由于数据在物理上只会保存一份,所以聚簇索引只能有一个。
InnoDB 在创建索引的时候,会根据不同场景选择不同的列作为索引:
- 如果有主键,默认会使用主键作为聚簇索引的索引键
- 如果没有主键,就会选择第一个不包含 NULL 值的唯一列作为聚簇索引的索引键
- 在上面两个都没有的情况下,InnoDB 会自动生成一个隐式自增id 列作为聚簇索引的索引键
一张表只能有一个聚簇索引,那为了实现非主键字段的快速索引,就引出了二级索引(非聚簇索引/辅助索引),它也是利用了 B+Tree 的数据结构,但是二级索引的叶子节点存放的是主键值,不是实际数据。
二级索引的B+Tree如下图,数据部分为主键值:
如果某个查询语句使用了二级索引,但是查询的数据不是主键值,这时在二级索引找到主键值后,需要去聚簇索引中获得数据行,这个过程叫做 回表 ,也就是说要查两个 B+Tree 才能查到数据。不过,当查询的数据是主键值时,因为只在二级索引就能查询到,不用再去聚簇索引查,这个过程叫做 索引覆盖 ,也就只需要查一个 B+Tree 就能找到数据。
总结
InnoDB的数据是按照 [ 数据页 ] 为单位来读写的,默认数据页大小为 16KB。每个数据页之间通过双链表的形式组织起来,物理上不连续,但是逻辑上连续。
数据页内包含用户记录,每个记录之间用单向链表的方式组织起来,为了加快在数据页内高效的查询记录,设计了一个页目录,页目录存储各个槽(分组),且主键值是有序的,于是可以通过二分查找的方式进行行检索,从而提高效率。
为了高效查询记录所在的数据页,InnoDB 采用 B+Tree 作为索引,每个节点都是一个数据页。
如果叶子节点存储的是实际数据,那么就是聚簇索引,一个表只能有一个聚簇索引;如果叶子节点存储的不是实际数据,而是主键值,那么就是二级索引,一个表中可以有多个二级索引。
在使用二级索引进行查找数据时,如果查询的数据能在二次索引找到,那么就是 覆盖索引 操作,如果查询的数据不在二级索引里,就需要在二级索引先查询主键值,再通过主键值从聚簇索引中获取数据,这就是 回表 操作。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 应急照明与疏散指示系统在城市综合体中的应用—安科瑞张田田
摘要】:结合自身从事的大型城市商业综合体物业设施的运行管理的实际工作经验,对应急照明和疏散指示系统的集中电源集中控制型系统在商业综合体内的应用进行分析。 【关键词】:集中控制型系统;应急照明控制器;集中电源;应急灯具;智能疏散 0.引言 随着城市化的推进,现在…
