
从自研走向开源的 TinyVue 组件库
TinyVue 的开源征程
OpenTiny 提供企业级的 Web 应用前端开发套件,包括 TinyVue/TinyNG 组件库、TinyPro 管理系统模板、TinyCLI 命令行工具以及 TinyTheme 主题配置系统等。这些前端开发的基础设施和技术已在华为内部积累和沉淀多年,其中 TinyVue 组件库更是历经九年的磨练,从最初的封闭自研逐步走向社区开源。
TinyVue 九年的开源征程大致分为三个阶段:第一阶段走完全自研的线路,当时称为 HAE 前端框架;第二阶段开始引入开源的 Vue 框架,更名为 AUI 组件库;第三阶段对架构进行重新设计,并逐步演变为现在开源的 TinyVue 组件库。本文将围绕 TinyVue 三个阶段的技术发展历程,深入代码细节讲解不同阶段的核心竞争力。
全文包含以下章节:
- 完全自研的 HAE 前端框架
- 实现数据的双向绑定
- 实现面向对象的 JS 库
- 配置式开发的注册表
- 迁移到 Vue 的 AUI 组件库
- 封装成 Vue 组件
- 后端服务适配器
- 标签式与配置式
- 全新架构的 TinyVue 组件库
- 开发组件库面临的问题
- 面向逻辑编程与无渲染组件
- 跨端跨技术栈TODO组件示例
完全自研的 HAE 前端框架
时间回到2014年,彼时的我刚加入公共技术平台部,参与 HAE 前端框架的研发。HAE 的全称是 Huawei Application Engine,即华为应用引擎。当时我们部门负责集团 IT 系统的基础设施建设,在规划 HAE 时我们对行业和技术趋势进行了分析,并得出结论:云计算、大数据牵引 IT 架构变化,并带来商业模式转变和产品变革,而云计算和大数据需要新的 IT 基础架构的支撑。
基于这个背景,我们提出 IT 2.0 架构的目标:利用互联网技术打造面向未来的更高效、敏捷的下一代 IT。作为云开发平台,HAE 需要支持全面的云化:云端开发、云端测试、云端部署、云端运营,以及应用实施的云化。其中,云端开发由 Web IDE 负责实现,这个 IDE 为用户提供基于配置的前端开发能力,因此需要支持可配置的 HAE 前端框架。
基于配置的开发模式,用户可通过可视化界面来配置前端应用开发中的各种选项,比如定义系统生命周期、配置页面路由、设置组件的属性等。相比之下,传统的开发模式需要用户手写代码来实现这些功能。当时业界还没有能满足这种需求的前端开发框架,走完全自研的路是历史必然的选择。
实现数据的双向绑定
在2014年,主流的前端技术仍以 jQuery 为主。传统的 jQuery 开发方式是通过手动操作 DOM 元素来更新和响应数据的变化。开发者需要编写大量的代码来处理数据和 DOM 之间的同步。这种单向的数据流和手动操作的方式,在处理复杂应用的数据和视图之间的同步时,可能会导致代码冗余、维护困难以及出错的可能性增加。
当时刚刚兴起的 AngularJS 带来了数据双向绑定的概念。数据双向绑定可以自动将数据模型和视图保持同步,当数据发生变化时,视图会自动更新,反之亦然。这种机制减少了开发者在手动处理数据和 DOM 同步方面的工作量。通过AngularJS 开发者只需要关注数据的变化,而不必显式地更新 DOM 元素。这使得开发过程更加简洁、高效,并减少了出错的可能性。
在 HAE 前端框架的研发初期,为了引入数据双向绑定功能,我们在原本基于 jQuery 的架构上融合了 AngularJS 框架。然而,经过几个月的尝试,我们发现这种融合方式存在两个严重问题:首先,当页面绑定数据量较大时,性能显著下降。其次,框架同时运行两套生命周期,导致两者难以协调相互同步。因此,我们决定移除 AngularJS 框架,但又不想放弃已经使用的数据双向绑定的特性。
在此情形下,我们深入研究 AngularJS 的数据双向绑定。它采用脏读(Dirty Checking)机制,该机制通过定期检查数据模型的变化来保持视图与模型之间的同步。当数据发生变化时,AngularJS 会遍历整个作用域(Scope)树来检查是否有任何绑定的值发生了改变。当绑定的数据量较大时,这个过程会消耗大量的计算资源和时间。
用什么方案替换 AngularJS 的数据双向绑定,并且还要保证性能优于脏读机制?当时我们把目光投向 ES5 的 Object.defineProperty 函数,借助它的 getter 和 setter 方法实现了数据双向绑定。这个方案比 Vue 框架早了整整一年,直到2015年10月,Vue 1.0 才正式发布。
接下来,我们通过代码来展现该方案的技术细节,以下是 AngularJS 数据双向绑定的使用示例:
{{ message }}
// 创建一个名为"myApp"的AngularJS模块
var app = angular.module('myApp', []);
// 在"myApp"模块下定义一个控制器"myController"
app.controller('myController', function($scope) {
$scope.message = "Hello AngularJS"; // 初始值
// 监听message的变化
$scope.$watch('message', function(newValue, oldValue) {
console.log('新值:', newValue);
console.log('旧值:', oldValue);
});
});
我们的替换方案就是要实现上面示例中的 $scope 变量,该变量拥有一个可以双向绑定的 message 属性。从以下 HTML 代码片段:
可以得知 input 输入框的值绑定了 message 属性,而另一段代码:
{{ message }}
则表明 P 标签也绑定了 message 属性,当执行以下语句:
$scope.message = "Hello AngularJS";
之后 message 的值就被修改了。此时,与 message 双向绑定的 input 输入框的值和 P 标签的内容也同步被修改为 Hello AngularJS。
要实现 $scope 变量,就必须实现一个 Scope 类,$scope 变量就是 Scope 类的一个实例。这个类有一个添加属性的方法,假设方法名为 $addAttribute,并且还有一个监听属性的方法,假设方法名为 $watch。
我们来看如何实现这两个方法(为突出核心片段,以下代码有删减):
function createScope() {
var me = this;
var attrs = {};
var watches = {};
function Scope() {
}
Scope.prototype = {
/**
* 添加属性
* @param {String} attrName 属性名
* @param {Object} attrValue 属性值
* @returns {Scope}
*/
$addAttribute: function(attrName, attrValue, readOnly) {
if (attrName && typeof attrName === "string" && !attrs[attrName] && attrName.indexOf("$") !== 0) {
Object.defineProperty(attrObject, attribute, {
get: function() {
return attrs[attrName].value;
},
set: function(newValue) {
var attr = attrs[attrName];
var oldValue = attr.value;
var result = false;
var watch;
// 判断新旧值是否完全相等
if (oldValue !== newValue && !(oldValue !== oldValue && newValue !== newValue)) {
watch = watches[attrName];
// 是否有监听该属性的回调函数
if (watch && !attr.watching) {
attr.watching = true;
result = watch.callbacks.some(function(callback) {
try {
// 如果监听回调函数返回 false,则终止触发下一个回调函数
return callback.call(scope, newValue, oldValue, scope) === false;
} catch (e) {
me.error(e);
}
});
delete attr.watching;
}
if (!result) {
if (attr.watching) {
try {
// 如果监听回调函数执行过程中又更改值,则抛出异常
throw new Error("Cannot change the value of '" + attrName + "' while watching it.");
} catch (e) {
me.error(e, 2);
}
} else {
// 所有监听回调函数执行完,再赋予新值
attr.value = newValue;
}
}
}
},
enumerable: true,
configurable: true
});
}
return this;
},
/**
* 监听属性变化
* @param {String} attrName 属性名
* @param {Function} callback 监听回调函数
* @param {Number} [priority] 监听的优先级
* @returns {Scope}
*/
$watch: function(attrName, callback, priority) {
if (attrName && typeof attrName === "string" && attrs[attrName] && typeof callback === "function") {
var watch = watches[attrName] || {
callbacks: [],
priorities: [],
minPriority: 0,
maxPriority: 0
};
var callbacks = watch.callbacks;
var priorities = watch.priorities;
var nIndex = callbacks.length;
if (typeof priority !== "number") {
priority = me.CALLBACK_PRIORITY;
}
// 判断监听回调函数的优先级
if (priority > watch.minPriority) {
if (priority > watch.maxPriority) {
// 优先级数值最高的监听回调函数放在队尾
callbacks.push(callback);
priorities.push(priority);
watch.maxPriority = priority;
} else {
priorities.some(function(item, index) {
if (item > priority) {
nIndex = index;
return true;
}
});
// 按照优先级的数值在队列适当位置插入监听回调函数
callbacks.splice(nIndex, 0, callback);
priorities.splice(nIndex, 0, priority);
}
} else {
// 优先级数值最小的监听回调函数放在队首
callbacks.unshift(callback);
priorities.unshift(priority);
watch.minPriority = priority;
}
watches[attrName] = watch;
}
return this;
}
}
// 返回 Scope 类新建的实例,即 $scope 变量
return new Scope();
}
上述代码因篇幅关系并不包含数据绑定的功能,仅实现为 $scope 添加属性以及设置监听回调函数,并且考虑了多个监听回调函数的执行顺序及异常处理的情况。借助 Object.defineProperty,我们不再需要遍历整个作用域(Scope)树来检查是否有任何绑定的值发生了改变。一旦某个值发生变化,就会立即触发绑定的监听回调函数,从而解决脏读机制的性能问题。
实现面向对象的 JS 库
同样在2014年,具有面向对象编程特性的 TypeScript 仍处于早期阶段,微软在当年4月份发布了 TypeScript 1.0 版本。HAE 前端框架在研发初期没有选择不成熟的 TypeScript 方案,而是利用 JavaScript 原型链机制来实现面向对象的设计模式,即通过共享原型对象的属性和方法,实现对象之间的继承和多态性。
然而,使用 JavaScript 原型链来实现面向对象设计存在两个问题:首先,原型链的使用方式与传统的面向对象编程语言(例如 Java 和 C++)有明显的区别,在当时前端开发人员大多是由 Java 后端转行做前端,因此需要花费较高的学习成本来适应原型链的概念和用法。其次,JavaScript 本身没有提供显式的私有属性和方法的支持,我们一般通过在属性或方法前添加下划线等约定性命名,来暗示这是一个私有成员。而在实际开发过程中,用户往往会直接访问和使用这些私有成员,这导致在后续框架的升级过程中必须考虑向下兼容这些私有成员,从而增加了框架的开发成本。
为了解决上述问题,我们自研了 jClass 库,这个库用 JavaScript 模拟实现了面向对象编程语言的基本特性。jClass 不仅支持真正意义上的私有成员,还支持保护成员、多重继承、方法重载、特性混入、静态常量、类工厂和类事件等,此外还内置自研的 Promise 异步执行对象,提供动态加载类外部依赖模块的功能等。
接下来,我们通过代码来展现 jClass 面向对象的特性,以下是基本使用示例:
// 定义 A 类
jClass.define('A', {
privates: {
name1: '1' // 私有成员,内部可以访问,但子类不能访问
},
protects: {
name2: '2' // 保护成员,子类可以访问,类的实例不能访问
},
publics: {
name3: '3' // 公有成员,子类可以访问,类的实例可以访问
}
});
// 定义 B 类,继承 A 类
jClass.define('B', {
extend: ['A'],
publics: {
// 公有方法,子类可以访问,类的实例可以访问
say: function(str) {
alert(str + this.name2); // 可以访问父类的保护成员 name2,但无法访问其私有成员 name1
}
}
});
// 创建 B 类的实例
var b = jClass.create('B');
b.say(b.name3); // B 继承 A 的 name3 属性,由于类的实例可以访问公有成员,因此弹出框内容为 3
我们再来看 jClass 如何继承多个父类,在上述代码后面添加如下代码:
// 定义 C 类
jClass.define('C', {
// 类的构造函数,初始化 title 属性
init: function(title) {
this.title = title; // 设置保护成员 title 的值
},
protects: {
title: '' // 保护成员,子类可以访问,类的实例不能访问
}
});
// 定义 D 类,同时继承 B 类和 C 类
jClass.define('D', {
extend: ['B', 'C'],
publics: {
// 公有方法,类的实例可以访问
say: function() {
alert(this.title + this.name2); // 访问 C 的保护成员 title 和 B 的保护成员 name2
}
}
});
// 创建 D 的实例,传入 C 构造函数所需的参数,弹出框内容为 32
jClass.create('D', ['3']).say();
jClass 的类工厂与类继承有相似之处,而类事件则为类方法的调用、类属性的修改提供监听能力,两者的使用示例如下:
// 创建一个工厂的实例
var tg = jClass.factory('triggerFactory', {
// 类的构造函数,初始化 name 属性
init: function(name) {
this.name = name;
},
// 公有成员,类的实例可以访问
publics: {
name: '',
show: function(str) {
this.name += 'x' + str;
return this;
},
hide: function(str) {
this.$fire('gone', [str]); // 抛出名为 gone 的事件,事件参数为 str
}
}
});
// 通过工厂定义一个名为 tg1 的类
tg.define('tg1', {
publics: {
name: '1' // 重载工厂的 name 属性值
}
});
var resShow = '', resName = '', resGone = '';
// 监听 tg1 类的 show 方法调用,如果该方法被执行,则触发以下函数
tg.on('show', 'tg1', function(str) {
resShow = this.name + '=' + str;
});
// 监听 tg1 类的 name 属性设置,如果该属性被重新赋值,则触发以下函数
tg.on('name', 'tg1', function(oldValue, newValue) {
resName = newValue;
});
// 监听所有子类的 gone 事件,如果该事件被抛出,则触发以下函数
tg.on('gone', function(str) {
resGone = str;
});
// 创建 tg1 的实例,执行该实例的 show 方法和 hide 方法
tg.create('tg1').show('2').hide('3');
alert(resShow + ' ' + resName + ' ' + resGone); // 弹出框内容为 1x2=2 1x2 3
基于 jClass 面向对象的特性,我们就可以用面向对象的设计模式来开发 HAE 组件库,以下就是定义和扩展组件的示例:
// 定义组件的基类 Widget
jClass.define('Widget', {
// 组件的构造函数,设置宽度和标题
init: function(width, title) {
this.width = width;
this.title = title;
this.setup(); // 初始化组件的属性
this.compile(); // 根据组件属性编译组件模板
this.render(); // 渲染输出组件的 HTML 字符串
},
protects: {
width: 0,
title: '',
templet: '',
// 初始化组件的属性
setup: function() {
this.width = this.width + 'px';
},
// 根据组件属性编译组件模板
compile: function() {
this.templet = this.templet.replace(/{{:width}}/g, this.width);
},
// 渲染输出组件的 HTML 字符串
render: function() {
this.html = this.templet.replace(/{{:title}}/g, this.title);
}
},
publics: {
html: '' // 记录组件的 HTML 字符串
}
});
// 定义一个 Button 组件,继承 Widget 基类
jClass.define('Button', {
extend: ['Widget'],
protects: {
// 设置 Button 组件的模板
templet: ''
}
});
// 创建一个 Button 组件的实例
jClass.create('Button', [100, 'OK']).html; // 返回
// 定义一个 LongButton 组件,继承 Button 父类
jClass.define('LongButton', {
extend: ['Button'],
protects: {
// 重载父类的 setup 方法,将长度自动加 100
setup: function() {
this.width = this.width + 100 + 'px';
}
}
});
// 创建一个 LongButton 组件的实例
jClass.create('LongButton', [100, 'OK']).html; // 返回
上述代码只演示了 jClass 部分特性,因篇幅关系没有展示其实现的细节。从2014年10月开始,jClass 陆续支撑 120 多个组件的研发,累积 30 多万行的代码。经过四年的发展,作为 HAE 前端框架的基石,jClass 在华为内部 IT 各个领域 1000 多个项目中得到广泛应用。通过这些项目的不断磨练,jClass 在功能和性能上已经达到了企业级的要求。
配置式开发的注册表
一个前端框架需要支撑生命周期,主要目的是在 Web 应用的不同阶段提供可控的执行环境和钩子函数,以便开发者可以在适当的时机执行特定的逻辑和操作。通过生命周期的支持,前端框架能够更好地管理 Web 应用的初始化、渲染、更新和销毁等过程,提供更灵活的控制和扩展能力。
在 HAE 前端框架中,存在三个不同层次的生命周期:系统生命周期、页面生命周期和组件生命周期。
-
系统生命周期:系统生命周期指的是整个前端应用的生命周期,它包含了应用的启动、初始化、运行和关闭等阶段。系统生命周期提供了应用级别的钩子函数,例如应用初始化前后的钩子、应用销毁前后的钩子等。通过系统生命周期的支持,开发者可以在应用级别执行一些全局的操作,例如加载配置、注册插件、处理全局错误等。
-
页面生命周期:页面生命周期指的是单个页面的生命周期,它描述了页面从加载到卸载的整个过程。页面生命周期包含了页面的创建、渲染、更新和销毁等阶段。在页面生命周期中,HAE 前端框架提供了一系列钩子函数,例如页面加载前后的钩子、页面渲染前后的钩子、页面更新前后的钩子等。通过页面生命周期的支持,开发者可以在页面级别执行一些与页面相关的逻辑,例如获取数据、处理路由、初始化页面状态等。
-
组件生命周期:组件生命周期指的是单个组件的生命周期,它描述了组件从创建到销毁的整个过程。组件生命周期包含了组件的实例化、挂载到 DOM、更新和卸载等阶段。组件生命周期的钩子函数与页面生命周期类似,通过组件生命周期的支持,开发者可以在组件级别执行一些与组件相关的逻辑,例如初始化状态、处理用户交互、与外部组件通信等。
总的来说,系统生命周期、页面生命周期和组件生命周期在粒度和范围上有所不同。系统生命周期操作整个 Web 应用,页面生命周期操作单个页面,而组件生命周期操作单个组件。通过这些不同层次的生命周期,HAE 前端框架能够提供更精细和灵活的控制,使开发者能够在合适的时机执行相关操作,实现更高效、可靠和可扩展的前端应用。
基于配置的开发模式,HAE 前端框架要让用户通过配置的方式,而不是通过手写代码来定义生命周期的钩子函数。为此,我们引入 Windows 注册表的概念,将框架内置的默认配置信息保存在一个 JSON 对象中,并命名为 register.js。同时,每个应用也可以根据自身需求创建应用的 register.js,系统在启动前会合并这两个文件,从而按照用户期望的方式配置生命周期的钩子函数。
以下是框架内置的注册表中,有关系统生命周期的定义:
framework: {
load_modules: { // 加载框架所需的模块
hae_runtime: true,
extend_modules: true
},
set_config: { // 初始化框架的服务配置
Hae_Service_Mock: true,
Hae_Service_Environment: true,
Hae_Service_Ajax: true,
Hae_Service_Personalized: true,
Hae_Service_Permission: true,
Hae_Service_DataSource: true
},
init_runtime: { // 框架运行过程中所需的服务
Hae_Service_Router: true,
Hae_Service_Message: true,
Hae_Service_Popup: true,
},
boot_system: { // 启动框架的模板引擎和页面渲染
Hae_Service_Templet: true,
Hae_Service_Page: true
},
start_services: { // 运行用于处理全局错误和日志信息的服务
Hae_Service_DebugToolbar: true,
Hae_Service_LogPanel: true
}
}
假设用户自定义的应用注册表内容如下:
framework: {
load_modules: { // 加载框架所需的模块
},
set_config: { // 初始化框架的服务配置
Hae_Service_Mock: false,
Hae_Service_Environment: true,
Hae_Service_Ajax: true,
Hae_Service_BehaviorAnalysis: true
Hae_Service_Personalized: true,
Hae_Service_Permission: true,
Hae_Service_DataSource: true,
},
init_runtime: { // 框架运行过程中所需的服务
},
boot_system: { // 启动框架的模板引擎和页面渲染
},
start_services: { // 运行用于处理全局错误和日志信息的服务
}
}
可以看到用户在 load_modules、init_runtime、boot_system 和 start_services 阶段不做调整,但是在 set_config 阶段禁用了 Hae_Service_Mock 服务,同时在 Hae_Service_Ajax 服务后面插入了 Hae_Service_BehaviorAnalysis 服务。
生命周期的钩子函数在哪里体现?其实答案就在服务里面,以 Hae_Service_Mock 服务为例,下面是该服务的定义:
/**
* 请求模拟服务
* @class Hae.Service.Mock
*/
Hae.loadService({
id: 'Hae.Service.Mock', // 服务 ID
name: 'HAE_SERVICE_MOCK', // 服务名称
callback: function() {} // 服务的钩子函数
});
以上代码需要包含在 load_modules 阶段加载的模块中。除了调用 loadService 方法定义服务之外,还可以通过 jClass 定义类的方式定义服务,代码示例如下:
/**
* 请求模拟服务
* @class Hae.Service.Mock
*/
Hae.define('Hae.Service.Mock', { // 服务 ID
services: {
// 服务名称
HAE_SERVICE_MOCK: function() {} // 服务的钩子函数
}
}
上面的 Hae 变量就是加强版的 jClass。我们再来看一下框架内置的注册表中,有关页面生命周期的定义:
page: {
loadHtml: {
Hae_Service_Page: "loadHtml"
},
initContext: {
Hae_Service_Page: "initContext"
},
loadJs: {
Hae_Service_Page: "loadJs"
},
loadContent: {
Hae_Service_Locale: "translate",
Hae_Service_Page: "loadContent",
Hae_Service_Personalized: "setRoutePath"
},
compile: {
Hae_Service_Permission: "compile",
Hae_Service_DataBind: "compile",
Hae_Service_ActionController: "compile",
Hae_Service_ValidationController: "compile"
},
render: {
Hae_Service_Page: "render"
},
complete: {
Hae_Service_DataBind: "complete",
Hae_Service_ActionController: "complete",
Hae_Service_ValidationController: "complete"
},
domReady: {
Hae_Service_Page: "domReady",
Hae_Service_DataBind: "domReady",
Hae_Service_TipHelper: "initHelper"
}
}
系统生命周期各个服务多以开关的形式定义,而页面生命周期各个服务多以名称的形式定义,以 Hae.Service.DataBind 服务为例,其定义如下:
/**
* 数据双向绑定
* @class Hae.Service.DataBind
*/
Hae.define('Hae.Service.DataBind', {
services: {
HAE_SERVICE_DATABIND_COMPILE: function(pageScope) {},
HAE_SERVICE_DATABIND_COMPLETE: function(pageScope) {},
HAE_SERVICE_DATABIND_DOMREADY: function(pageScope) {}
}
}
最后再简单介绍一下组件的生命周期,借助 jClass 面向对象的特性,组件的生命周期各阶段钩子函数在组件的基类 Widget 中定义的,代码示例如下:
/**
* 所有 Widget 组件的基类
* @class Hae.Widget
* @extends Hae
*/
Hae.define('Hae.Widget', {
protects: {
/**
* 初始化阶段
*/
setup: function() {},
/**
* 编译模板阶段,返回异步对象
* @returns {Hae.Promise}
*/
compile: function() {
this.template = Hae.create('Hae.Compile').compile(this.widgetType, this.op);
return Hae.deferred().resolve();
},
/**
* 渲染模板阶段,返回异步对象
* @returns {Hae.Promise}
*/
render: function() {
this.dom.html(Hae.create('Hae.Render').render(this.template, this.dataset, this.op));
},
/**
* 绑定事件阶段
*/
bind: function() {},
/**
* 组件完成阶段
*/
complete: function() {},
/**
* 组件销毁
*/
destroy: function() {}
}
}
可以看到组件基类的编译模板阶段和渲染模板阶段都有默认的实现,由于这两个阶段一般需要读取后端数据等延迟操作,因此要返回 Hae.Promise 异步对象。这个异步对象是 HAE 框架参照 jQuery 的 Deferred 异步回调重新实现的,主要解决 Deferred 异步性能慢的问题。
迁移到 Vue 的 AUI 组件库
时间来到2017年,以 Vue 为代表的现代前端工程化开发模式带来了许多改进和变革。与以 jQuery 为代表的传统开发模式相比,这些改进和变革体现在以下方面:
-
声明式编程:Vue 采用了声明式编程的思想,开发者可以通过声明式的模板语法编写组件的结构和行为,而无需直接操作 DOM。这简化了开发流程并提高了开发效率。
-
组件化开发:Vue 鼓励组件化开发,将 UI 拆分为独立的组件,每个组件具有自己的状态和行为。这样可以实现组件的复用性、可维护性和扩展性,提高了代码的可读性和可维护性。
-
响应式数据绑定:Vue 采用了响应式数据绑定的机制,将数据与视图自动保持同步。当数据发生变化时,自动更新相关的视图部分,大大简化了状态管理的复杂性。
-
自动化流程:前端工程化引入了自动化工具,例如构建工具(例如 Webpack)、任务运行器(例如 npm)和自动化测试工具,大大简化了开发过程中的重复性任务和手动操作。通过自动化流程,开发者可以自动编译、打包、压缩和优化代码,自动执行测试和部署等,提高了开发效率和一致性。
-
模块化开发:前端工程化鼓励使用模块化开发的方式,将代码拆分为独立的模块,每个模块负责特定的功能。这样可以提高代码的可维护性和复用性,减少了代码之间的耦合性,使团队协作更加高效。
-
规范化与标准化:前端工程化倡导遵循一系列的规范和标准,包括代码风格、目录结构、命名约定等。这样可以提高团队协作的一致性,减少沟通和集成的成本,提高项目的可读性和可维护性。
-
静态类型检查和测试:前端工程化鼓励使用静态类型检查工具(例如 TypeScript)和自动化测试工具(例如 Mocha)来提高代码质量和稳定性。通过静态类型检查和自动化测试,可以提前捕获潜在的错误和问题,减少Bug的产生和排查的时间。
考虑到人力成本、学习曲线和竞争力等因素,HAE 前端框架需要向现代前端开源框架与工程化方向演进。由于 HAE 属于自研框架,仅在华为内部使用,新进的开发人员需要投入时间学习和掌握该框架,这对他们的技术能力要求较高。然而,如果选择采用开源框架,庞大的社区支持和广泛的文档资源,使得开发人员可以更快速地上手和开发。同时,采用开源框架也使得 HAE 框架能够紧跟业界趋势。开源框架通常由全球的开发者社区共同维护和更新,能够及时跟进最新的前端技术和最佳实践。这有助于提升 HAE 框架自身的竞争力,使其具备更好的适应性和可扩展性。
早在2016年10月上海 QCon 大会上,Vue 框架的作者尤雨溪首次亮相,登台推广他的开源框架,那也是我们初次接触 Vue。当时 React 作为另一个主流的开源框架也备受业界关注,我们需要在 Vue 和 React 之间做出选择。随后,在2017年6月我们远赴波兰的佛罗茨瓦夫参加 Vue 首届全球开发者大会,那次我们有幸与尤雨溪本人进行了交流。回来后,我们提交了 Vue 与 React 的对比分析报告,向上级汇报了我们的技术选型意向,最终我们决定选择 Vue。
封装成 Vue 组件
要全面迁移到 Vue 框架,抛弃已使用 jQuery 开发的 30 万行代码,在有限的时间和人力下是一个巨大的挑战。为了找到折中的解决方案,我们采取这样的迁移策略:将 HAE 前端框架的系统和页面生命周期进行剥离,只保留与 HAE 组件相关的代码,然后将底层架构替换为 Vue,并引入所有前端工程化相关的能力,最后成功实现了让用户以 Vue 的方式来使用我们的组件。这样的迁移策略在保证项目进展的同时,也能够逐步融入 Vue 的优势和工程化的便利性。
为了让用户以 Vue 的方式来使用 jQuery 开发的组件,我们需要在 Vue 组件的生命周期中动态创建 HAE 组件。当时,我们正在研究 Webix 组件库,它底层使用的是纯 JavaScript 技术实现的,没有依赖于其他框架或库,是一个独立的前端组件库。Webix 可以无缝地集成到各种不同的平台和框架中,包括 Vue、React、Angular 等。这使得开发人员能够在现有的项目中轻松地引入和使用 Webix 组件,而无需进行大规模的重构。以下是 Webix 官方提供的与 Vue 集成的示例(原文链接):
app.component("my-slider", {
props: ["modelValue"],
// always an empty div
template: "",
watch: {
// updates component when the bound value changes
value: {
handler(value) {
webix.$$(this.webixId).setValue(value);
},
},
},
mounted() {
// initializes Webix Slider
this.webixId = webix.ui({
// container and scope are mandatory, other properties are optional
container: this.$el,
$scope: this,
view: "slider",
value: this.modelValue,
});
// informs Vue about the changed value in case of 2-way data binding
$$(this.webixId).attachEvent("onChange", function() {
var value = this.getValue();
// you can use a custom event here
this.$scope.$emit("update:modelValue", value);
});
},
// memory cleaning
destroyed() {
webix.$$(this.webixId).destructor();
},
});
上述示例代码定义了一个名为 my-slider 的 Vue 组件,在该组件生命周期的 mounted 阶段,通过调用 webix.ui 方法动态创建了一个 Webix 组件,然后监听该组件的 onChange 事件并抛出 Vue 的 update:modelValue 事件,并且利用 Vue 的 watch 监听其 value 属性,一旦它发生变化则调用 Webix 的 setValue 方法重新设置 Webix 组件的值,从而实现数据的双向绑定。由于 HAE 组件也支持动态创建,按照这个思路,我们很快写出 HAE 版本的 Vue 组件:
export default {
name: 'AuiSlider',
render: function (createElement) {
// 渲染一个 div 标签,类似于 Webix 的 template: ""
return createElement('div', this.$slots.default)
},
props: ['modelValue', 'op'],
data() {
return {
widget: {}
}
},
created() {
// 在 Vue 组件的创建阶段监听 value 属性
this.$watch('value', (value) => {
// 一旦它发生变化则调用 widget 的 setValue 方法重新 HAE 组件的值
this.widget.setValue && this.widget.setValue(value)
})
},
methods: {
createcomp() {
let dom = $(this.$el)
let fullOp = this.$props['op']
let extendOp = {
// 监听 HAE 组件的 `onChange` 事件
onChange: (val) => {
// 抛出 Vue 的 `update:modelValue` 事件
this.$emit('update:modelValue', val)
}
}
// 获取 Vue 组件的配置参数
let op = fullOp
? Hae.extend({}, fullOp, extendOp, { value: this.$props.value })
: Hae.extend({}, this.$props, extendOp)
this.$el.setAttribute('widget', 'Slider')
// 调用 Hae 的 widget 方法动态创建了一个 HAE 组件
this.widget = Hae.widget(dom, 'Slider', op)
}
},
mounted() {
// 在 Vue 组件的挂载阶段创建 HAE 组件
this.createcomp()
}
}
以上的迁移策略毕竟是折中的临时方案,并没有充分发挥 Vue 的模板和虚拟 DOM 优势,相当于用 Vue 套了一层壳。虽然该方案也提供了数据双向绑定功能,但不会绑定数组的每个元素,并不是真正的基于数据驱动的组件。这个临时方案的好处在于为我们赢得了时间,以最快速度引入开源的 Vue 框架以及前端工程化的理念,使得业务开发能够尽早受益于前端变革所带来的降本增效。
经过近半年的研发,HAE 组件库成功迁移到 Vue 框架,并于2017年12月正式发布。在2018年,为统一用户体验遵循 Aurora 主题规范,我们对组件库进行升级改造,并改名为 AUI。在支撑了制造、采购、供应、财经等领域的大型项目后,到了2019年 AUI 进入成熟稳定期,我们才有时间去思考如何将 jQuery 的 30 万行代码重构为 Vue 的代码。
后端服务适配器
在 HAE 框架中,组件能够自动连接后端服务以获取数据,无需开发人员编写请求代码或处理返回数据的格式。例如人员联想框组件,其功能是根据输入的工号返回相应的姓名。该组件已经预先定义了与后端服务进行通信所需的接口和数据格式,因此开发人员只需要在页面中引入该组件即可直接使用。
这样的设计使得开发人员能够更专注于页面的搭建和功能的实现,而无需关注与后端服务的具体通信细节。HAE 框架会自动处理请求和响应,并确保数据以一致的格式返回给开发人员。通过这种自动连接后端服务的方式,开发人员能够节省大量编写请求代码和数据处理逻辑的时间,加快开发速度,同时减少了潜在的错误和重复劳动。
HAE 框架的后端服务是配套的,组件设计当初没有考虑连接不同的后端服务。升级到 AUI 组件库之后,业务的多样化场景使得我们必须引入适配器来实现对接不同后端服务的需求。适配器作为一个中间层,其目的和作用如下:
-
解耦前后端:适配器充当前后端之间的中间层,将前端组件与后端服务解耦。通过适配器,前端组件不需要直接了解或依赖于后端服务的具体接口和数据格式。这种解耦使得前端和后端能够独立地进行开发和演进,而不会相互影响。
-
统一接口:不同的后端服务可能具有不同的接口和数据格式,这给前端组件的开发带来了困难。适配器的作用是将不同后端服务的接口和数据格式转化为统一的接口和数据格式,使得前端组件可以一致地与适配器进行交互,而不需要关心底层后端服务的差异。
-
灵活性和扩展性:通过适配器,前端组件可以轻松地切换和扩展后端服务。如果需要替换后端服务或新增其他后端服务,只需添加或修改适配器,而不需要修改前端组件的代码。这种灵活性和扩展性使得系统能够适应不同的后端服务需求和变化。
-
隐藏复杂性:适配器可以处理后端服务的复杂性和特殊情况,将这些复杂性隐藏在适配器内部。前端组件只需与适配器进行交互,无需关注后端服务的复杂逻辑和细节。这种抽象和封装使得前端组件的开发更加简洁和高效。
以 AUI 内置的 Jalor 和 HAE 两个后端服务适配器为例,对于相同的业务服务,我们来看一下这两个后端服务接口的差异,以下是 Jalor 部分接口的访问地址:
Setting.services = {
Area: 'servlet/idataProxy/params/ws/soaservices/AreaServlet',
Company: 'servlet/idataProxy/params/ws/soaservices/CompanyServlet',
Country: 'servlet/idataProxy/params/ws/soaservices/CountryServlet',
Currency: 'servlet/idataProxy/params/ws/soaservices/CurrencyServlet',
}
以下是对应 HAE 接口的访问地址:
Setting.services = {
Area: 'services/saasIdatasaasGetGeoArea',
Company: 'services/saasIdatasaasGetCompany',
Country: 'services/saasIdatasaasGetCountry',
Currency: 'services/saasIdatasaasGetCurrency',
}
这些相同的业务服务不仅接口访问地址不同,就连请求的参数格式以及返回的数据格式都有差异。适配器就是为开发人员提供统一的 API 来连接这些有差异的服务。在具体实现上,我们首先创建一个核心层接口 @aurora/core,以下是该接口的示例代码:
class Aurora {
// 注册后端服务适配器
get registerService() {
}
// 返回后端服务适配器的实例
get getServiceInstance() {
}
// 删除后端服务适配器的实例
get destroyServiceInstance() {
}
// 基础服务,主要提供获取和设置环境信息、用户信息、菜单、语言、权限等数据信息的方法
get base() {
return getService().base
}
// 通用服务,主要提供和业务(地区、部门等)相关的方法
get common() {
return getService().common
}
// 消息服务,主要用于订阅消息、发布消息、取消订阅
get message() {
return getService().message
}
// 网络服务,基于 axios 实现的,用法和 axios 基本相同,只支持异步请求
get network() {
return getService().network
}
// 存储服务,默认基于 window.localstorage 方法扩展
get storage() {
return getService().storage
}
// 权限服务,校验当前用户是否有该权限点的某个操作权限。计算权限点,支持标准逻辑运算符 |, &
get privilege() {
return getService().privilege
}
// 资源服务,主要是资源请求,追加配置资源路径,用于加载依赖库,从公共库,组件目录,或者远程加载
get resource() {
return resource
}
}
然后我们为每一个后端服务创建一个适配器,以下是 Jalor 适配器 @aurora/service-jalor 的示例代码:
class JalorService {
constructor(config = {}) {
this.utils = utils(this)
// 注册服务到全局的适配器实例中
Aurora.registerService(this, config)
this.ajax = ajax(this)
this.init = init(this)
// 初始化适配器的配置信息
config.services = services(this)
config.options = options(this)
config.widgets = widgets(this)
// 需要使用柯里化函数初始化的服务方法
this.fetchEnvService = fetchEnvService(this)
this.fetchLangResource = fetchLangResource(this)
this.fetchArea = fetchArea(this)
this.fetchCompany = fetchCompany(this)
this.fetchCountry = fetchCountry(this)
this.fetchCurrency = fetchCurrency(this)
this.fetchFragment = fetchFragment(this)
// 其他需要初始化的服务方法
fetchDeptList(this)
fetchUser(this)
fetchLocale(this)
fetchLogout(this)
fetchRole(this)
fetchCustomized(this)
fetchEdoc(this)
}
// 服务适配器的名称
get name() {
return 'jalor'
}
}
export default JalorService
以上面的 fetchArea 方法为例,Jalor 服务的实现代码如下:
export default function (instance) {
return ({ label, parent }) => {
return new Promise((resolve, reject) => {
// 调用 @aurora/core 的 network 网络服务发送请求
instance.network.get(instance.setting.services.Area, {
params: {
'area_label': label,
'parent': parent
}
})
.then((response) => {
resolve(response.data.area)
})
.catch(reject)
})
}
}
而 HAE 服务适配器 @aurora/service-hae 对应的 fetchArea 方法的实现代码如下:
export default function (instance) {
return ({ label, parent }) => {
return new Promise((resolve, reject) => {
// 调用 @aurora/core 的 network 网络服务发送请求
instance.network.get(instance.setting.services.Area, {
params: {
'geo_org_type': label,
'parent': parent
}
}).then(response => {
resolve(response.data.BO)
}).catch(reject)
})
}
}
两者主要区别在于 parmas 参数以及 response.data 数据格式。有了统一的 API 接口,开发人员只需按以下方式调用 getArea 方法就能获取地区的数据,不需要区分数据来自是 Jalor 服务还是 HAE 服务:
this.$service.common.getArea({ label: 'Region', parent: '1072' }).then(data => { console.log(data) })
标签式与配置式
AUI 组件继承了 HAE 框架的特点,即天然支持配置式开发。如何理解这个配置式开发?我们用前面 封装成 Vue 组件 章节里的代码来讲解:
var op = {
min: 0,
max: 100,
step: 10,
range: 'min'
}
// 调用 Hae 的 widget 方法动态创建了一个 HAE 组件
this.widget = Hae.widget(dom, 'Slider', op)
代码中的 op 变量是 option 配置项的缩写,变量的值为一个 JSON 对象,该对象描述了创建 HAE 的 Slider 组件所需的配置信息。这些配置信息在 HAE 框架中通过 Web IDE 的可视化设置面板来收集,这就是配置式开发的由来。相比之下,如果我们用 Vue 常规的标签方式声明 AUI 的 Slider 组件,则代码示例如下:
import { Slider } from '@aurora/vue'
export default {
components: {
AuiSlider: Slider
},
data() {
return {
value: 30
}
}
}
由于 AUI 组件天然支持配置式开发,除了上面的标签式声明,AUI 还提供与上述代码等价的配置式声明:
import { Slider } from '@aurora/vue'
export default {
components: {
AuiSlider: Slider
},
data() {
return {
value: 30,
op: {
min: 0,
max: 100,
step: 10,
range: 'min'
}
}
}
}
可见配置式声明沿用 HAE 的方式,将所有配置信息都放在 op 变量里。以下是这两种声明方式的详细差异:
| 标签式声明 | 配置式声明 | |
|---|---|---|
| 用法 | 使用一个或多个具有特定功能的标签来定义组件,每个标签都有自己的属性和配置 | 使用单个标签,并通过传递一个包含所有配置信息的 JSON 对象来定义组件 |
| 优点 | 直观易懂,易于理解组件的结构和配置。开发人员可以直接在模板中进行修改和调整 | 配置信息集中在一个对象中,便于整体管理和维护,可以使用变量和动态表达式来动态生成配置信息,灵活性更高 |
| 缺点 | 如果组件的结构复杂或标签较多,标签式声明可能会显得冗长和混乱 | 对于不熟悉配置结构和属性的开发人员来说,可能需要花费一些时间去理解和编写配置对象 |
| 开发效率 | 在开发初期可能更快速,因为可以直接在模板中进行编辑和调试 | 在组件结构复杂或需要动态生成配置信息时,可以减少重复的标签代码,提高代码复用性和维护性 |
| 业务场景 | 更适用于静态页面,开发人员更关注组件的结构和外观 | 更适用于动态页面,开发人员更关注组件的数据和行为 |
如果将两者放在特定的业务领域比较,比如低代码平台,则配置式声明的优势更加明显,理由如下:
- 简化 DSL 开发流程:配置式声明将组件的配置信息集中在一个对象中,低代码 DSL 开发人员可以通过修改对象的属性值来自定义组件的行为和外观。这种方式避免生成繁琐的标签嵌套和属性设置,简化了 DSL 的开发流程。
- 提高配置的可复用性:配置式声明可以将组件的配置信息抽象为一个可重复使用的对象,可以在多个组件实例中共享和复用。低代码平台开发人员可以定义一个通用的配置对象,然后在不同的场景中根据需要进行定制,减少了重复的代码编写和配置调整。
- 动态生成配置信息:配置式声明允许低代码平台开发人员使用变量、动态表达式和逻辑控制来低代码组件配置面板生成的配置信息。这样可以根据不同的条件和数据来动态调整组件的配置,增强了组件配置面板的灵活性和适应性。
- 可视化配置界面:配置式声明通常与可视化配置界面相结合,低代码平台的使用人员可以通过低代码的可视化界面直接修改物料组件的属性值。这种方式使得配置更直观、易于理解,提高了开发效率。
- 适应复杂业务场景:在复杂的业务场景中,组件的配置信息可能会非常繁琐和复杂。通过配置式声明,低代码物料组件的开发人员可以更方便地管理和维护大量的配置属性,减少了出错的可能性。
全新架构的 TinyVue 组件库
时间来到2019年,如前面提到的,AUI 进入成熟稳定期,我们有了时间去思考如何将 jQuery 的 30 万行代码重构为 Vue 的代码。同年5月16日,美国商务部将华为列入出口管制“实体名单”,我们面临前所未有的困难,保证业务连续性成为我们首要任务。我们要做最坏的打算,如果有一天所有的主流前端框架 Angular、React、Vue 都不能再继续使用,那么重构后的 Vue 代码又将何去何从?
因此,我们组件的核心代码要与主流前端框架解耦,这就要求我们不仅仅要重构代码,还要重新设计架构。经过不断的打磨和完善,拥有全新架构的 TinyVue 组件库逐渐浮出水面,以下就是 TinyVue 组件的架构图:
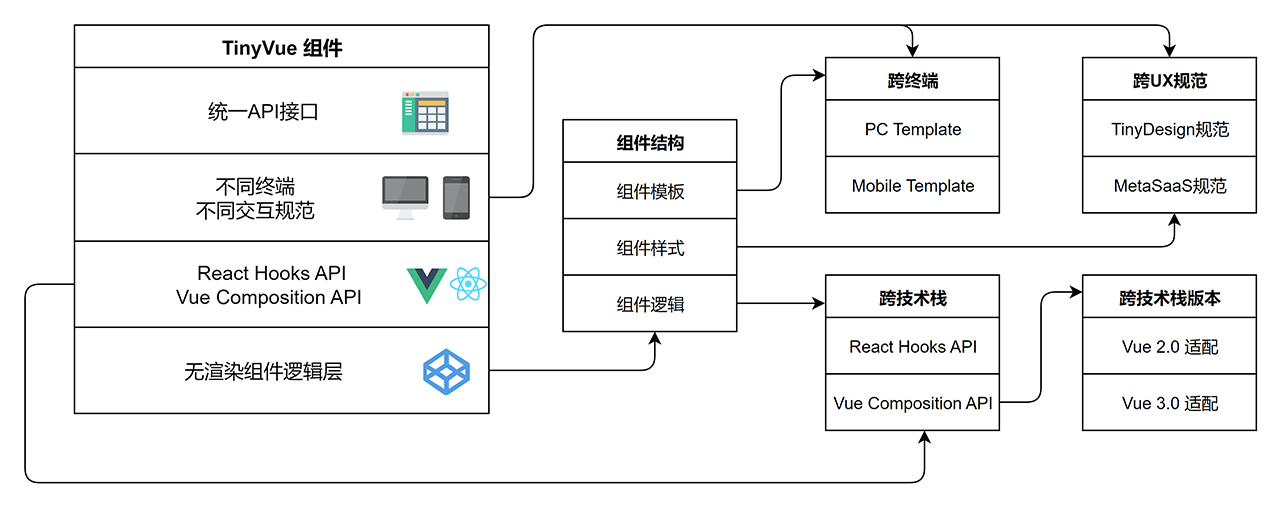
在这个架构下,TinyVue 组件有统一的 API 接口,开发人员只需写一份代码,组件就能支持不同终端的展现,比如 PC 端和 Mobile 端,而且还支持不同的 UX 交互规范。借助 React 框架的 Hooks API 或者 Vue 框架的 Composition API 可以实现组件的核心逻辑代码与前端框架解耦,甚至实现一套组件库代码,同时支持 Vue 的不同版本。
接下来,我们先分析开发组件库面临的问题,再来探讨面向逻辑编程与无渲染组件,最后以实现一个 TODO 组件为例,来阐述我们的解决方案,通过示例代码展现我们架构的四个特性:跨技术栈、跨技术栈版本、跨终端和跨 UX 规范。
其中,跨技术栈版本这个特性,已经为华为内部 IT 带来巨大的收益。由于 Vue 框架最新的 3.0 版本不能完全向下兼容 2.0 版本,而 2.0 版本又将于2023年12月31日到达生命周期终止(EOL)。于是华为内部 IT 所有基于 Vue 2.0 的应用都必须在这个日期之前升级到 3.0 版本,这涉及到几千万行代码的迁移整改,正因为我们的组件库同时支持 Vue 2.0 和 3.0,使得这个迁移整改的成本大大降低。
开发组件库面临的问题
目前业界的前端 UI 组件库,一般按其前端框架 Angular、React 和 Vue 的不同来分类,比如 React 组件库,Angular 组件库、Vue 组件库,也可以按面向的终端,比如 PC、Mobile 等不同来分类,比如 PC 组件库、Mobile 组件库、小程序组件库等。两种分类交叉后,又可分为 React PC 组件库、React Mobile 组件库、Angular PC 组件库、Angular Mobile 组件库、Vue PC 组件库、Vue Mobile 组件库等。
比如阿里的 Ant Design 分为 PC 端:Ant Design of React、Ant Design of Angular、Ant Design of Vue,Mobile 端:Ant Design Mobile of React(官方实现)Ant Design Mobile of Vue(社区实现)。
另外,由于前端框架 Angular、React 和 Vue 的大版本不能向下兼容,导致不同版本对应不同的组件库。以 Vue 为例,Vue 2.0 和 Vue 3.0 版本不能兼容,因此 Vue 2.0 的 UI 组件库跟 Vue 3.0 的 UI 组件库代码是不同的,即同一个技术栈也有不同版本的 UI 组件库。
比如阿里的 Ant Design of Vue 其 1.x 版本 for Vue 2.0,而 3.x 版本 for Vue 3.0。再比如饿了么的 Element 组件库,Element UI for Vue 2.0,而 Element Plus for Vue 3.0。
我们将上面不同分类的 UI 组件库汇总在一张图里,然后站在组件库使用者的角度上看,如果要开发一个应用,那么先要从以下组件库中挑选一个,然后再学习和掌握该组件库,可见当前多端多技术栈的组件库给使用者带来沉重的学习负担。
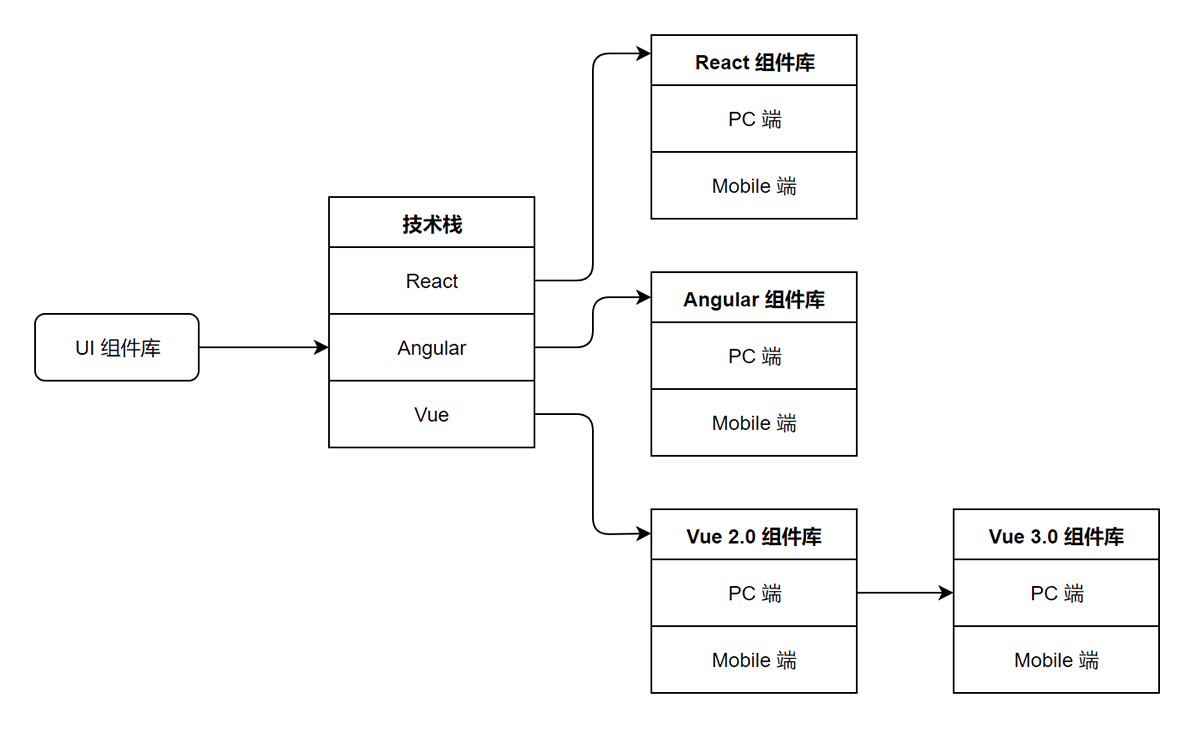
这些 UI 组件库由于前端框架不同、面向终端不同,常规的解决方案是:不同的开发人员来开发和维护不同的组件库,比如需要懂 Vue 的开发人员来开发和维护 Vue 组件库,需要懂 PC 端交互的开发人员来开发和维护 PC 组件库等等。
很明显,这种解决方案首先需要不同技术栈的开发人员,而市面上大多数开发人员只精通一种技术栈,其他技术栈则只是了解而已。这样每个技术栈就得独立安排一组人员进行开发和维护,成本自然比单一技术栈要高得多。另外,由于同一技术栈的版本升级导致的不兼容,也让该技术栈的开发人员必须开发和维护不同版本的代码,使得成本进一步攀升。
面对上述组件开发和维护成本高的问题,业界还有一种解决方案,即以原生 JavaScript 或 Web Component 技术为基础,构建一套与任何开发框架都无关的组件库,然后再根据当前开发框架流行的程度,去适配不同的前端框架。比如 Webix 用一套代码适配任何前端框架,既提供原生 JavaScript 版本的组件库,也提供 Angular、React 和 Vue 版本的组件库。
这种解决方案,其实开发难度更大、维护成本更高,因为这相当于先要自研一套前端框架,类似于我们以前的 HAE 框架,然后再用不同的前端框架进行套壳封装。显然,套壳封装势必影响组件的性能,而且封闭自研的框架其学习门槛、人力成本要高于主流的开源框架。
面向逻辑编程与无渲染组件
当前主流的前端框架为 Angular、React 和 Vue,它们提供两种不同的开发范式:一种是面向生命周期编程,另一种是面向业务逻辑编程。基于这些前端框架开发应用,页面上的每个部分都是一个 UI 组件或者实例,而这些实例都是由 JavaScript 创造出来的,都具有创建、挂载、更新、销毁的生命周期。
所谓面向生命周期编程,是指基于前端框架开发一个 UI 组件时,按照该框架定义的生命周期,将 UI 组件的相关逻辑代码注册到指定的生命周期钩子函数里。以 Vue 框架的生命周期为例,一个 UI 组件的逻辑代码可能被拆分到 beforeCreate、created、beforeMount、mounted、beforeUnmount、unmounted 等钩子函数里。
所谓面向逻辑编程,是指在前端开发的过程中,尤其在开发大型应用时,为解决面向生命周期编程所引发的问题,提出新的开发范式。以一个文件浏览器的 UI 组件为例,这个组件具备以下功能:
- 追踪当前文件夹的状态,展示其内容
- 处理文件夹的相关操作 (打开、关闭和刷新)
- 支持创建新文件夹
- 可以切换到只展示收藏的文件夹
- 可以开启对隐藏文件夹的展示
- 处理当前工作目录中的变更
假设这个组件按照面向生命周期的方式开发,如果为相同功能的逻辑代码标上一种颜色,那将会是下图左边所示。可以看到,处理相同功能的逻辑代码被强制拆分在了不同的选项中,位于文件的不同部分。在一个几百行的大组件中,要读懂代码中一个功能的逻辑,需要在文件中反复上下滚动。另外,如果我们想要将一个功能的逻辑代码抽取重构到一个可复用的函数中,需要从文件的多个不同部分找到所需的正确片段。

如果用面向逻辑编程重构这个组件,将会变成上图右边所示。可以看到,与同一个功能相关的逻辑代码被归为了一组:我们无需再为了一个功能的逻辑代码在不同的选项块间来回滚动切换。此外,我们可以很轻松地将这一组代码移动到一个外部文件中,不再需要为了抽象而重新组织代码,从而大大降低重构成本。
早在2018年10月,React 推出了 Hooks API,这是一个重要的里程碑,对前端开发人员乃至社区生态都产生了深远的影响,它改变了前端开发的传统模式,使得函数式组件成为构建复杂 UI 的首选方式。到了2019年初,Vue 在研发 3.0 版本的过程中也参考了 React 的 Hooks API,并且为 Vue 2.0 版本添加了类似功能的 Composition API。
当时我们正在规划新的组件架构,在了解 Vue 的 Composition API 后,意识到这个 API 的重要性,它就是我们一直寻找的面向逻辑编程。同时,我们也发现业界有一种新的设计模式 —— 无渲染组件,当我们尝试将两者结合在一起,之前面临的问题随即迎刃而解。
无渲染组件其实是一种设计模式。假设我们开发一个 Vue 组件,无渲染组件是指这个组件本身并没有自己的模板(template)以及样式。它装载的是各种业务逻辑和状态,是一个将功能和样式拆开并针对功能去做封装的设计模式。这种设计模式的优势在于:
-
逻辑与 UI 分离:将逻辑和 UI 分离,使得代码更易于理解和维护。通过将逻辑处理和数据转换等任务抽象成无渲染组件,可以将关注点分离,提高代码的可读性和可维护性。
-
提高可重用性:组件的逻辑可以在多个场景中重用。这些组件不依赖于特定的 UI 组件或前端框架,可以独立于界面进行测试和使用,从而提高代码的可重用性和可测试性。
-
符合单一职责原则:这种设计鼓励遵循单一职责原则,每个组件只负责特定的逻辑或数据处理任务。这样的设计使得代码更加模块化、可扩展和可维护,减少了组件之间的耦合度。
-
更好的可测试性:由于无渲染组件独立于 UI 进行测试,可以更容易地编写单元测试和集成测试。测试可以专注于组件的逻辑和数据转换,而无需关注界面的渲染和交互细节,提高了测试的效率和可靠性。
-
提高开发效率:开发人员可以更加专注于业务逻辑和数据处理,而无需关心具体的 UI 渲染细节。这样可以提高开发效率,减少重复的代码编写,同时也为团队协作提供了更好的可能性。
比如下图的示例,两个组件 TagsInput A 和 TagInput B 都有相似的功能,即提供 Tags 标签录入、删除已有标签两种能力。虽然它们的外观截然不同,但是录入标签和删除标签的业务逻辑是相同的,是可以复用的。无渲染组件的设计模式将组件的逻辑和行为与其外观展现分离。当组件的逻辑足够复杂并与它的外观展现解耦时,这种模式非常有效。
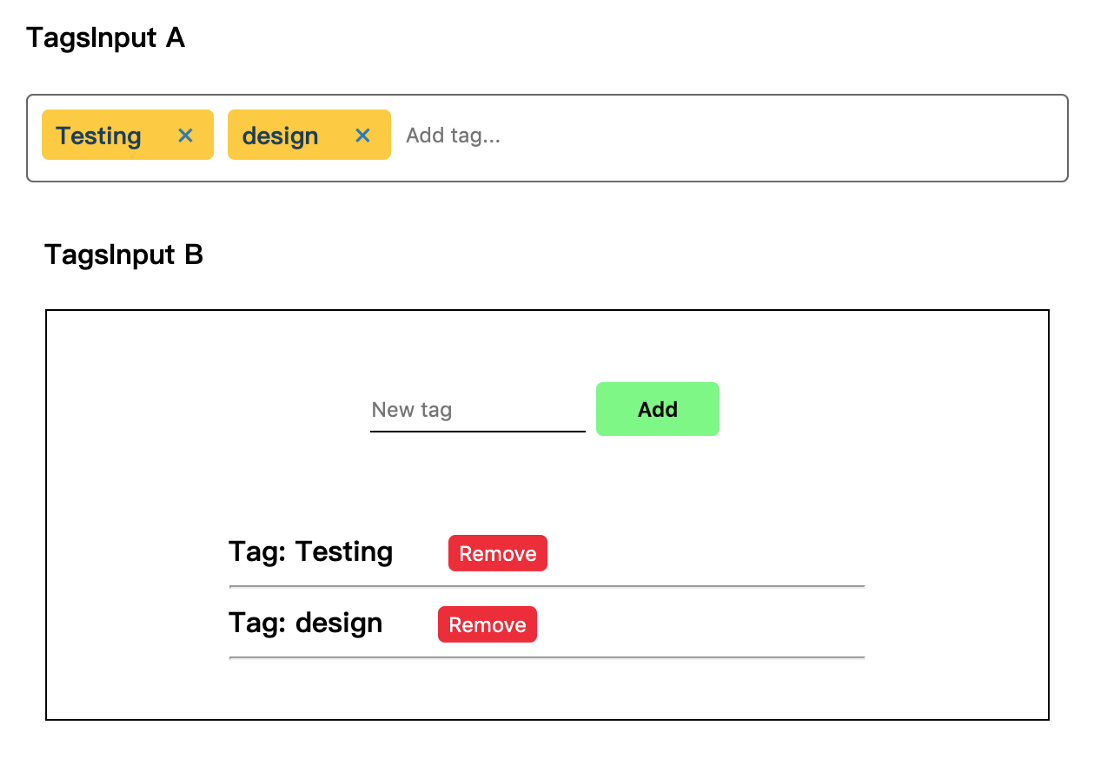
单纯使用面向逻辑的开发范式,仅仅只能让相同的业务逻辑从原本散落到生命周期各个阶段的部分汇聚到一起。无渲染组件的设计模式的实现方式有很多种,比如 React 中可以使用 HOC 高阶函数,Vue 中可以使用 scopedSlot 作用域插槽,但当组件业务逻辑日趋复杂时,高阶函数和作用域插槽会让代码变得难以理解和维护。
要实现组件的核心逻辑代码与前端框架解耦,实现跨端跨技术栈,需要同时结合面向逻辑的开发范式与无渲染组件的设计模式。首先,按照面向逻辑的开发范式,通过 React 的 Hooks API,或者 Vue 的 Composition API,将与前端框架无关的业务逻辑和状态拆离成相对独立的代码。接着,再使用无渲染组件的设计模式,将组件不同终端的外观展现,统一连接到已经拆离相对独立的业务逻辑。
跨端跨技术栈TODO组件示例
接下来,我们以开发一个 TODO 组件为例,讲解基于新架构的组件如何实现跨端跨技术栈。假设该组件 PC 端的展示效果如下图所示:

对应 Mobile 端的展示效果如下图所示:

该组件的功能如下:
- 添加待办事项:在输入框输入待办事项信息,点击右边的 Add 按钮后,下面待办事项列表将新增一项刚输入的事项信息。
- 删除待办事项:在待办事项列表里,选择其中一个事项,点击右边的X按钮后,该待办事项将从列表里清除。
- 移动端展示:当屏幕宽度缩小时,组件将自动切换成如下 Mobile 的展示形式,功能仍然保持不变,即输入内容直接按回车键添加事项,点击 X 删除事项。
这个 TODO 组件的实现分为 Vue 版本和 React 版本,即支持两个不同的技术栈。以上特性都复用一套 TODO 组件的逻辑代码。这套 TODO 组件的逻辑代码以柯里化函数形式编写。柯里化(英文叫 Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术。举一个简单的例子:
// 普通函数
var add = function(x, y) {
return x + y
}
add(3, 4) // 返回 7
// 柯里化函数
var foo = function(x) {
return function(y) {
return x + y
}
}
foo(3)(4) // 返回 7
本来应该一次传入两个参数的 add 函数,柯里化函数变成先传入 x 参数,返回一个包含 y 参数的函数,最终执行两次函数调用后返回相同的结果。一般而言,柯里化函数都是返回函数的函数。
回到 TODO 组件,按照无渲染组件的设计模式,首先写出不包含渲染实现代码,只包含纯业务逻辑代码的函数,以 TODO 组件的添加和删除两个功能为例,如下两个柯里化函数:
/**
* 添加一个标签,给定一个 tag 内容,往已有标签集合里添加该 tag
*
* @param {object} text - 输入框控件绑定数据
* @param {object} props - 组件属性对象
* @param {object} refs - 引用元素的集合
* @param {function} emit - 抛出事件的方法
* @param {object} api - 暴露的API对象
* @returns {boolean} 标签是否添加成功
*/
const addTag = ({ text, props, refs, emit, api }) => tag => {
// 判断 tag 内容是否为字符串,如果不是则取输入框控件绑定数据的值
tag = trim(typeof tag === 'string' ? tag : text.value)
// 检查已存在的标签集合里是否包含新 tag 的内容
if (api.checkTag({ tags: props.tags, tag })) {
// 如果已存在则返回添加失败
return false
}
// 从组件属性对象获取标签集合,往集合里添加新 tag 元素
props.tags.push(tag)
// 清空输入框控件绑定数据的值
text.value = ''
// 从引用元素集合里找到输入控件,让其获得焦点
refs.input.focus()
// 向外抛出事件,告知已添加新标签
emit('add', tag)
// 返回标签添加成功
return true
}
/**
* 移除一个标签,给定一个 tag 内容,从已有标签集合里移除该 tag
*
* @param {object} props - 组件属性对象
* @param {object} refs - 引用元素的集合
* @param {function} emit - 抛出事件的方法
* @returns {boolean} 标签是否添加成功
*/
const removeTag = ({ props, refs, emit }) => tag => {
// 从组件属性对象获取标签集合,在集合里查找 tag 元素的位置
const index = props.tags.indexOf(tag)
// 如果位置不是-1,则表示能在集合里找到对应的位置
if (index !== -1) {
// 从组件属性对象获取标签集合,在集合的相应位置移除该 tag 元素
props.tags.splice(index, 1)
// 从引用元素集合里找到输入控件,让其获得焦点
refs.input.focus()
// 向外抛出事件,告知已删除标签
emit('remove', tag)
// 返回标签移除成功
return true
}
// 如果找不到则返回删除失败
return false
}
// 向上层暴露业务逻辑方法
export {
addTag,
removeTag
}
可以看到这两个组件的逻辑函数,没有外部依赖,与技术栈无关。这两个逻辑函数会被组件的 Vue 和 React 的 Renderless 函数调用。其中 Vue 的 Renderless 函数部分代码如下:
// Vue适配层,负责承上启下,即引入下层的业务逻辑方法,自动构造标准的适配函数,提供给上层的模板视图使用
import { addTag, removeTag, checkTag, focus, inputEvents, mounted } from 'business.js'
/**
* 无渲染适配函数,根据 Vue 框架的差异性,为业务逻辑方法提供所需的原材料
*
* @param {object} props - 组件属性对象
* @param {object} context - 页面上下文对象
* @param {function} value - 构造双向绑定数据的方法
* @param {function} onMounted - 组件挂载时的方法
* @param {function} onUpdated - 数据更新时的方法
* @returns {object} 返回提供给上层模板视图使用的 API
*/
export const renderless = (props, context, { value, onMounted, onUpdated }) => {
// 通过页面上下文对象获取父节点元素
const parent = context.parent
// 通过父节点元素获取输入框控件绑定数据
const text = parent.text
// 通过父节点元素获取其上下文对象,再拿到抛出事件的方法
const emit = parent.$context.emit
// 通过页面上下文对象获取引用元素的集合
const refs = context.refs
// 以上为业务逻辑方法提供所需的原材料,基本是固定的,不同框架有所区别
// 初始化输入框控件绑定数据,如果没有定义则设置为空字符串
parent.text = parent.text || value('')
// 构造返回给上层模板视图使用的 API 对象
const api = {
text,
checkTag,
focus: focus(refs),
// 第一次执行 removeTag({ props, refs, emit }) 返回一个函数,该函数用来给模板视图的 click 事件
removeTag: removeTag({ props, refs, emit })
}
// 在组件挂载和数据更新时需要处理的方法
onMounted(mounted(api))
onUpdated(mounted(api))
// 与前面定义的 API 对象内容进行合并,新增 addTag 和 inputEvents 方法
return Object.assign(api, {
// 第一次执行 addTag({ text, props, refs, emit, api }) 返回一个函数,该函数用来给模板视图的 click 事件
addTag: addTag({ text, props, refs, emit, api }),
inputEvents: inputEvents({ text, api })
})
}
React 的 Renderless 函数部分代码如下,这与 Vue 非常类似:
import { addTag, removeTag, checkTag, focus, inputEvents, mounted } from 'business.js'
export const renderless = (props, context, { value, onMounted, onUpdated }) => {
const text = value('')
const emit = context.emit
const refs = context.refs
const api = {
text,
checkTag,
focus: focus(refs),
removeTag: removeTag({ props, refs, emit })
}
onMounted(mounted(api))
onUpdated(mounted(api), [context.$mode])
return Object.assign(api, {
addTag: addTag({ text, props, refs, emit, api }),
inputEvents: inputEvents({ text, api })
})
}
可以看到,TODO 组件的两个逻辑函数 addTag 和 removeTag 都有被调用,分别返回两个函数并赋值给 api 对象的两个同名属性。而这个技术栈适配层代码里的 Renderless 函数,不包含组件逻辑,只用来抹平不同技术栈的差异,其内部按照面向业务逻辑编程的方式,分别调用 React 框架的 Hooks API 与 Vue 框架的 Composition API,这里要保证组件逻辑 addTag 和 removeTag 的输入输出统一。
上述 Vue 和 React 适配层的 Renderless 函数会被与技术栈强相关的 Vue 和 React 组件模板代码所引用,只有这样才能充分利用各主流前端框架的能力,避免重复造框架的轮子。以下是 Vue 页面引用 Vue 适配层 Renderless 函数的代码:
import { renderless, api } from '../../renderless/Todo/vue'
import { props, setup } from '../common'
export default {
props: [...props, 'newTag', 'tags'],
components: {
TodoTag: () => import('../Tag')
},
setup(props, context) {
return setup({ props, context, renderless, api })
}
}
React 页面引用 React 适配层 Renderless 函数,代码如下所示:
import { useRef } from 'react'
import { renderless, api } from '../../renderless/Todo/react'
import { setup, render, useRefMapToVueRef } from '../common/index'
import pc from './pc'
import mobile from './mobile'
import '../../theme/Todo/index.css'
export default props => {
const { $mode = 'pc', $template, $renderless, listeners = {}, tags } = props
const context = {
$mode,
$template,
$renderless,
listeners
}
const ref = useRef()
useRefMapToVueRef({ context, name: 'input', ref })
const { addTag, removeTag, inputEvents: { keydown, input }, text: { value } } = setup({ context, props, renderless, api, listeners, $renderless })
return render({ $mode, $template, pc, mobile })({ addTag, removeTag, value, keydown, input, tags, ref, $mode })
}
至此已完成 TODO 组件支持跨技术栈、复用逻辑代码。根据无渲染组件的设计模式,前面已经分离组件逻辑,现在还要支持组件不同的外观。TODO 组件要支持 PC 端和 Mobile 两种外观展示,即组件结构支持 PC 端和 Mobile 端。所以我们在 Vue 里要拆分为两个页面文件,分别是 pc.vue 和 mobile.vue,其中 pc.vue 文件里的 template 组件结构如下:
而 mobile.vue 文件里的 template 组件结构如下:
由上可见,PC 端和 Mobile 的组件结构虽然不一样,但是都引用相同的接口,这些接口就是 TODO 组件逻辑函数输出的内容。
同理,React 也分为两个页面文件,分别是 pc.jsx 和 mobile.jsx,其中 pc.jsx 文件里的 template 组件结构如下:
import React from 'react'
import Tag from '../Tag'
export default props => {
const { addTag, removeTag, value, keydown, input, tags, ref, $mode } = props
return (
{tags.map(tag => {
return (
)
})}
)
}
而 mobile.jsx 文件里的 template 组件结构如下:
import React from 'react'
import Tag from '../Tag'
import '../../style/mobile.scss'
export default props => {
const { removeTag, value, keydown, input, tags, ref, $mode } = props
return (
{tags.map(tag => {
return (
)
})}
)
}
由上可见,Vue 和 React 的 PC 端及 Mobile 端的结构基本一样,主要是 Vue 和 React 的语法区别,因此同时开发和维护 Vue 和 React 组件结构的成本并不高。以下是 TODO 组件示例的全景图:
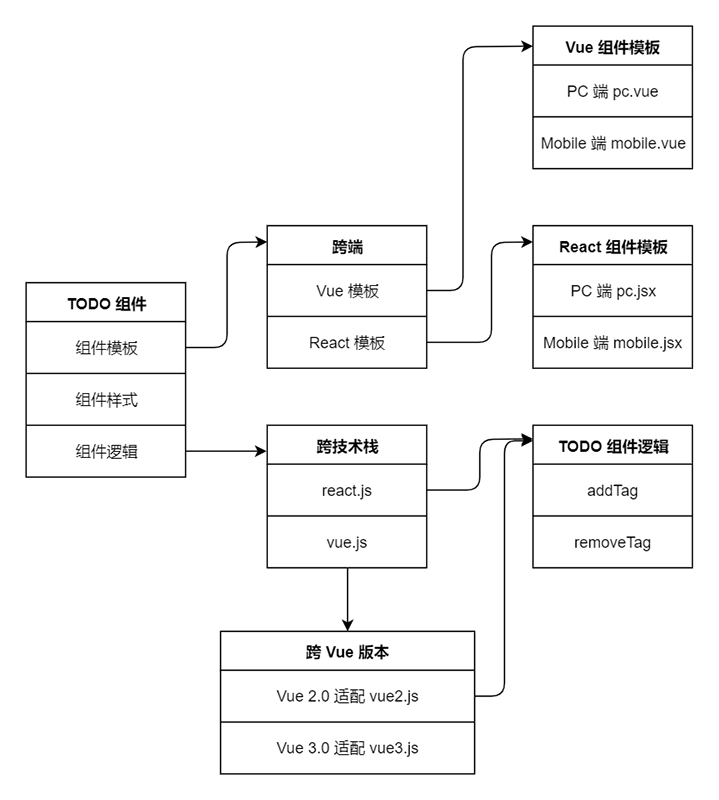
回顾一下我们开发这个 TODO 组件的步骤,主要分为三步:
- 按无渲染组件的设计模式,首先要将组件的逻辑分离成与技术栈无关的柯里化函数。
- 在定义组件的时候,借助面向逻辑编程的 API,比如 React 框架的
Hooks API、Vue 框架的Composition API,将组件外观与组件逻辑完全解耦。 - 按不同终端编写对应的组件模板,再利用前端框架提供的动态组件,实现动态切换不同组件模板,从而满足不同外观的展示需求。
总结
虽然在 HAE 自研阶段,我们实现的数据双向绑定、面向对象的 JS 库、配置式开发的注册表等特性,随着前端技术的高速发展现在已经失去存在的意义,但是在 AUI 阶段探索的新思路新架构,经过大量的业务落地验证,再次推动前端领域的创新。TinyVue 继承了 HAE、AUI 的基因,所有的新技术都从业务中来,到业务中去。而且,在这个过程中,我们通过不断吸收、融合开源社区的最佳实践和创新,不断提升自身的核心竞争力。
开源文化在不仅在前端技术,甚至整个软件行业都已得到广泛接受和普及,我们也在开源项目中受益匪浅,TinyVue 从自研走向开源也是顺应了这一开源文化的趋势。目前 TinyVue 已于2023年初正式开源(https://opentiny.design/)。我们希望通过开源,让华为内外的开发者可以共同协作改进和完善我们的组件库,共享华为沉淀多年的知识和经验。我们希望通过开源,与社区用户共同探索和实验新的技术、框架和模式,推动前端领域的创新。我们希望通过开源,为开发者提供更多选择和灵活性,让整个前端社区都能受益。
欢迎加入 OpenTiny 开源社区。添加微信小助手:opentiny-official一起参与共建~
OpenTiny 官网:https://opentiny.design/
OpenTiny 代码仓库:https://github.com/opentiny/
欢迎进入 OpenTiny 代码仓库 Star🌟TinyVue、TinyNG、TinyCLI~
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
