
摘要:本文为大家介绍一下深度学习中的混合精度训练,并通过代码实战的方式为大家讲解实际应用的理论,并对模型进行测试。
本文分享自华为云社区《浅谈深度学习中的混合精度训练》,作者:李长安。
1 混合精度训练
混合精度训练最初是在论文Mixed Precision Training中被踢出,该论文对混合精度训练进行了详细的阐述,并对其实现进行了讲解,有兴趣的同学可以看看这篇论文。
1.1半精度与单精度
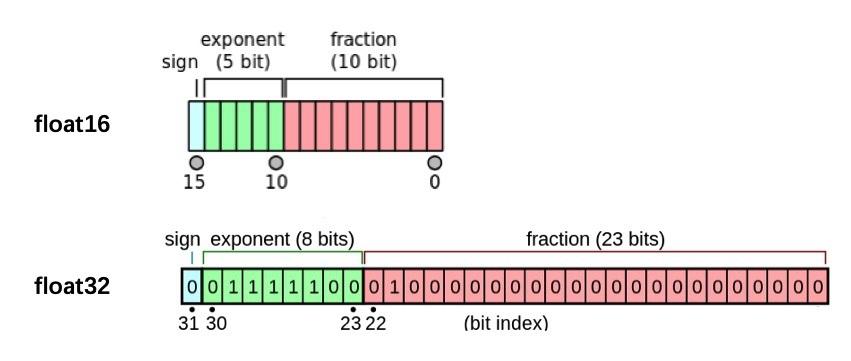
半精度(也被称为FP16)对比高精度的FP32与FP64降低了神经网络的显存占用,使得我们可以训练部署更大的网络,并且FP16在数据转换时比FP32或者FP64更节省时间。
单精度(也被称为32-bit)是通用的浮点数格式(在C扩展语言中表示为float),64-bit被称为双精度(double)。
如图所示,我们能够很直观的看到半精度的存储空间是单精度存储空间的一半。
1.2为什么使用混合精度训练
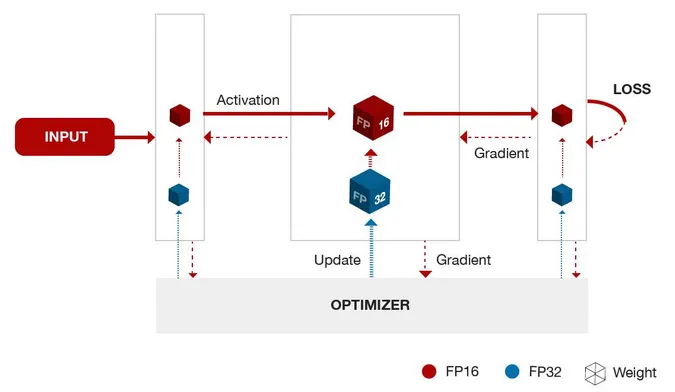
混合精度训练,指代的是单精度 float和半精度 float16 混合训练。
float16和float相比恰里,总结下来就是两个原因:内存占用更少,计算更快。
内存占用更少:这个是显然可见的,通用的模型 fp16 占用的内存只需原来的一半。memory-bandwidth 减半所带来的好处:
模型占用的内存更小,训练的时候可以用更大的batchsize。
模型训练时,通信量(特别是多卡,或者多机多卡)大幅减少,大幅减少等待时间,加快数据的流通。
计算更快:目前的不少GPU都有针对 fp16 的计算进行优化。论文指出:在近期的GPU中,半精度的计算吞吐量可以是单精度的 2-8 倍;
损失控制原理:
2 实验设计
本次实验主要从两个方面进行测试,分别在精度和速度两个部分进行对比。实验中采用ResNet-18作为测试对象,使用的数据集为美食数据集,共五种类别。
# 解压数据集
!cd data/data64280/ && unzip -q trainset.zip
2.1数据集预处理
import pandas as pd
import numpy as np
import os
all_file_dir = 'data/data64280/trainset'
img_list = []
label_list = []
label_id = 0
class_list = [c for c in os.listdir(all_file_dir) if os.path.isdir(os.path.join(all_file_dir, c))]
for class_dir in class_list:
image_path_pre = os.path.join(all_file_dir, class_dir)
for img in os.listdir(image_path_pre):
img_list.append(os.path.join(image_path_pre, img))
label_list.append(label_id)
label_id += 1
img_df = pd.DataFrame(img_list)
label_df = pd.DataFrame(label_list)
img_df.columns = ['images']
label_df.columns = ['label']
df = pd.concat([img_df, label_df], axis=1)
df = df.reindex(np.random.permutation(df.index))
df.to_csv('food_data.csv', index=0)
import pandas as pd
# 读取数据
df = pd.read_csv('food_data.csv')
image_path_list = df['images'].values
label_list = df['label'].values
# 划分训练集和校验集
all_size = len(image_path_list)
train_size = int(all_size * 0.8)
train_image_path_list = image_path_list[:train_size]
train_label_list = label_list[:train_size]
val_image_path_list = image_path_list[train_size:]
val_label_list = label_list[train_size:]
2.2自定义数据集
import numpy as np
from PIL import Image
from paddle.io import Dataset
import paddle.vision.transforms as T
import paddle as pd
class MyDataset(Dataset):
"""
步骤一:继承paddle.io.Dataset类
"""
def __init__(self, image, label, transform=None):
"""
步骤二:实现构造函数,定义数据读取方式,划分训练和测试数据集
"""
super(MyDataset, self).__init__()
imgs = image
labels = label
self.labels = labels
self.imgs = imgs
self.transform = transform
# self.loader = loader
def __getitem__(self, index): # 这个方法是必须要有的,用于按照索引读取每个元素的具体内容
fn = self.imgs
label = self.labels
# fn是图片path #fn和label分别获得imgs[index]也即是刚才每行中word[0]和word[1]的信息
for im,la in zip(fn, label):
img = Image.open(im)
img = img.convert("RGB")
img = np.array(img).astype('float32') / 255.0
label = np.array([la]).astype(dtype='int64')
# 按照路径读取图片
if self.transform is not None:
img = self.transform(img)
# 数据标签转换为Tensor
return img, label
# return回哪些内容,那么我们在训练时循环读取每个batch时,就能获得哪些内容
# ********************************** #使用__len__()初始化一些需要传入的参数及数据集的调用**********************
def __len__(self):
# 这个函数也必须要写,它返回的是数据集的长度,也就是多少张图片,要和loader的长度作区分
return len(self.imgs)
2.3训练准备
import paddle
from paddle.metric import Accuracy
import warnings
warnings.filterwarnings("ignore")
import paddle.vision.transforms as T
transform = T.Compose([
T.Resize([224, 224]),
T.ToTensor(),
# T.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5]),
# T.Transpose(),
])
train_dataset = MyDataset(image=train_image_path_list, label=train_label_list ,transform=transform)
train_loader = paddle.io.DataLoader(train_dataset, places=paddle.CPUPlace(), batch_size=16, shuffle=True)
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
import paddle
from paddle import ParamAttr
import paddle.nn as nn
import paddle.nn.functional as F
from paddle.nn import Conv2D, BatchNorm, Linear, Dropout
from paddle.nn import AdaptiveAvgPool2D, MaxPool2D, AvgPool2D
from paddle.nn.initializer import Uniform
import math
__all__ = ["ResNet18", "ResNet34", "ResNet50", "ResNet101", "ResNet152"]
class ConvBNLayer(nn.Layer):
def __init__(self,
num_channels,
num_filters,
filter_size,
stride=1,
groups=1,
act=None,
name=None,
data_format="NCHW"):
super(ConvBNLayer, self).__init__()
self._conv = Conv2D(
in_channels=num_channels,
out_channels=num_filters,
kernel_size=filter_size,
stride=stride,
padding=(filter_size - 1) // 2,
groups=groups,
weight_attr=ParamAttr(name=name + "_weights"),
bias_attr=False,
data_format=data_format)
if name == "conv1":
bn_name = "bn_" + name
else:
bn_name = "bn" + name[3:]
self._batch_norm = BatchNorm(
num_filters,
act=act,
param_attr=ParamAttr(name=bn_name + "_scale"),
bias_attr=ParamAttr(bn_name + "_offset"),
moving_mean_name=bn_name + "_mean",
moving_variance_name=bn_name + "_variance",
data_layout=data_format)
def forward(self, inputs):
y = self._conv(inputs)
y = self._batch_norm(y)
return y
class BottleneckBlock(nn.Layer):
def __init__(self,
num_channels,
num_filters,
stride,
shortcut=True,
name=None,
data_format="NCHW"):
super(BottleneckBlock, self).__init__()
self.conv0 = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters,
filter_size=1,
act="relu",
name=name + "_branch2a",
data_format=data_format)
self.conv1 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters,
filter_size=3,
stride=stride,
act="relu",
name=name + "_branch2b",
data_format=data_format)
self.conv2 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters * 4,
filter_size=1,
act=None,
name=name + "_branch2c",
data_format=data_format)
if not shortcut:
self.short = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters * 4,
filter_size=1,
stride=stride,
name=name + "_branch1",
data_format=data_format)
self.shortcut = shortcut
self._num_channels_out = num_filters * 4
def forward(self, inputs):
y = self.conv0(inputs)
conv1 = self.conv1(y)
conv2 = self.conv2(conv1)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = paddle.add(x=short, y=conv2)
y = F.relu(y)
return y
class BasicBlock(nn.Layer):
def __init__(self,
num_channels,
num_filters,
stride,
shortcut=True,
name=None,
data_format="NCHW"):
super(BasicBlock, self).__init__()
self.stride = stride
self.conv0 = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters,
filter_size=3,
stride=stride,
act="relu",
name=name + "_branch2a",
data_format=data_format)
self.conv1 = ConvBNLayer(
num_channels=num_filters,
num_filters=num_filters,
filter_size=3,
act=None,
name=name + "_branch2b",
data_format=data_format)
if not shortcut:
self.short = ConvBNLayer(
num_channels=num_channels,
num_filters=num_filters,
filter_size=1,
stride=stride,
name=name + "_branch1",
data_format=data_format)
self.shortcut = shortcut
def forward(self, inputs):
y = self.conv0(inputs)
conv1 = self.conv1(y)
if self.shortcut:
short = inputs
else:
short = self.short(inputs)
y = paddle.add(x=short, y=conv1)
y = F.relu(y)
return y
class ResNet(nn.Layer):
def __init__(self, layers=50, class_dim=1000, input_image_channel=3, data_format="NCHW"):
super(ResNet, self).__init__()
self.layers = layers
self.data_format = data_format
self.input_image_channel = input_image_channel
supported_layers = [18, 34, 50, 101, 152]
assert layers in supported_layers,
"supported layers are {} but input layer is {}".format(
supported_layers, layers)
if layers == 18:
depth = [2, 2, 2, 2]
elif layers == 34 or layers == 50:
depth = [3, 4, 6, 3]
elif layers == 101:
depth = [3, 4, 23, 3]
elif layers == 152:
depth = [3, 8, 36, 3]
num_channels = [64, 256, 512,
1024] if layers >= 50 else [64, 64, 128, 256]
num_filters = [64, 128, 256, 512]
self.conv = ConvBNLayer(
num_channels=self.input_image_channel,
num_filters=64,
filter_size=7,
stride=2,
act="relu",
name="conv1",
data_format=self.data_format)
self.pool2d_max = MaxPool2D(
kernel_size=3,
stride=2,
padding=1,
data_format=self.data_format)
self.block_list = []
if layers >= 50:
for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
if layers in [101, 152] and block == 2:
if i == 0:
conv_name = "res" + str(block + 2) + "a"
else:
conv_name = "res" + str(block + 2) + "b" + str(i)
else:
conv_name = "res" + str(block + 2) + chr(97 + i)
bottleneck_block = self.add_sublayer(
conv_name,
BottleneckBlock(
num_channels=num_channels[block]
if i == 0 else num_filters[block] * 4,
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
shortcut=shortcut,
name=conv_name,
data_format=self.data_format))
self.block_list.append(bottleneck_block)
shortcut = True
else:
for block in range(len(depth)):
shortcut = False
for i in range(depth[block]):
conv_name = "res" + str(block + 2) + chr(97 + i)
basic_block = self.add_sublayer(
conv_name,
BasicBlock(
num_channels=num_channels[block]
if i == 0 else num_filters[block],
num_filters=num_filters[block],
stride=2 if i == 0 and block != 0 else 1,
shortcut=shortcut,
name=conv_name,
data_format=self.data_format))
self.block_list.append(basic_block)
shortcut = True
self.pool2d_avg = AdaptiveAvgPool2D(1, data_format=self.data_format)
self.pool2d_avg_channels = num_channels[-1] * 2
stdv = 1.0 / math.sqrt(self.pool2d_avg_channels * 1.0)
self.out = Linear(
self.pool2d_avg_channels,
class_dim,
weight_attr=ParamAttr(
initializer=Uniform(-stdv, stdv), name="fc_0.w_0"),
bias_attr=ParamAttr(name="fc_0.b_0"))
def forward(self, inputs):
y = self.conv(inputs)
y = self.pool2d_max(y)
for block in self.block_list:
y = block(y)
y = self.pool2d_avg(y)
y = paddle.reshape(y, shape=[-1, self.pool2d_avg_channels])
y = self.out(y)
return y
def ResNet18(**args):
model = ResNet(layers=18, **args)
return model
2.4训练过程定义
import paddle
import numpy
import paddle.nn.functional as F
import time
def train(model):
model.train()
epochs = 5
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
# 用Adam作为优化函数
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0]
y_data = data[1]
# print(y_data)
predicts = model(x_data)
loss = F.cross_entropy(predicts, y_data)
# 计算损失
acc = paddle.metric.accuracy(predicts, y_data, k=2)
loss.backward()
if batch_id % 10 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(), acc.numpy()))
optim.step()
optim.clear_grad()
import paddle
import numpy
import paddle.nn.functional as F
import time
def train_amp(model):
model.train()
epochs = 5
optim = paddle.optimizer.Adam(learning_rate=0.001, parameters=model.parameters())
# 用Adam作为优化函数
for epoch in range(epochs):
for batch_id, data in enumerate(train_loader()):
x_data = data[0].astype('float16')
y_data = data[1]
scaler = paddle.amp.GradScaler(init_loss_scaling=1024)
with paddle.amp.auto_cast():
predicts = model(x_data)
loss = F.cross_entropy(predicts, y_data)
scaled = scaler.scale(loss) # scale the loss
scaled.backward() # do backward
acc = paddle.metric.accuracy(predicts, y_data, k=2)
if batch_id % 10 == 0:
print("epoch: {}, batch_id: {}, loss is: {}, acc is: {}".format(epoch, batch_id, loss.numpy(),
acc.numpy()))
optim.step()
optim.clear_grad()
2.5开启训练
此部分,分别对两种训练方式进行对比,主要关注模型的训练速度
model = ResNet18(class_dim=2)
strat = time.time()
train(model)
end = time.time()
print('no_amp:', end-strat)
epoch: 0, batch_id: 0, loss is: [0.21116894], acc is: [1.]
epoch: 1, batch_id: 0, loss is: [0.00010776], acc is: [1.]
epoch: 2, batch_id: 0, loss is: [2.5868081e-05], acc is: [1.]
epoch: 3, batch_id: 0, loss is: [1.442422e-05], acc is: [1.]
epoch: 4, batch_id: 0, loss is: [1.1086402e-05], acc is: [1.]
no_amp: 740.6813971996307
strat1 = time.time()
train_amp(model)
end1 = time.time()
print('with amp:', end1-strat1)
epoch: 0, batch_id: 0, loss is: [0.512834], acc is: [1.]
epoch: 1, batch_id: 0, loss is: [0.00025519], acc is: [1.]
epoch: 2, batch_id: 0, loss is: [5.9364465e-05], acc is: [1.]
epoch: 3, batch_id: 0, loss is: [3.2305197e-05], acc is: [1.]
epoch: 4, batch_id: 0, loss is: [2.4556812e-05], acc is: [1.]
with amp: 740.9603228569031
3 总结
对于本次实验,由于迭代轮数较少,只迭代了5次,故时间上的优势没有体现出来,大家有兴趣的可以增加迭代次数,或者换更深的网络进行测试。
从训练的结果来看,使用混合精度训练,其loss值是高于未使用混合精度训练模型的。
点击关注,第一时间了解华为云新鲜技术~
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
