
前言
各位同行有没有想过一件事,一个程序文件,比如 hello.go 是如何被编译器理解的,平常在编写程序时,IDE 又是如何提供代码提示的。在这奥妙无穷的背后, AST(Abstract Syntax Tree)抽象语法树功不可没,他站在每一行程序的身后,默默无闻的工作,为繁荣的互联网世界立下了汗马功劳。
AST 抽象语法树
AST 使用树状结构来表达编程语言的结构,树中的每一个节点都表示源码中的一个结构。听到这或许你的心里会咯噔一下,其实说通俗一点,在源代码解析后会得到一串数据,这个数据自然的呈现树状结构,它被称之为 CST(Concrete Syntax Tree) 具体语法树,在 CST 的基础上保留核心结构。忽略一些不重要的结构,比如标点符号,空白符,括号等,就得到了 AST。
如何生成 AST
生成 AST 大概需要两个步骤,词法分析lexical analysis和语法分析syntactic analysis。
词法分析 lexical analysis
lexical analysis 简称 lexer ,它表示字符串序列,也就是我们的源代码转化为 token 的过程,进行词法分析的工具叫做词法分析器(lexical analyzer,简称lexer),也叫扫描器(scanner)。Go 语言的 go/scanner 包提供词法分析。
func ScannerDemo() {
// 源代码
src := []byte(`
func demo() {
fmt.Println("When you are old and gray and full of sleep")
}
`)
// 初始化标记
var s服务器托管网 scanner.Scanner
fset := token.NewFileSet()
file := fset.AddFile("", fset.Base(), len(src))
s.Init(file, src, nil, scanner.ScanComments)
// Scan 进行扫码并打印出结果
for {
pos, tok, lit := s.Scan()
if tok == token.EOF {
break
}
fmt.Printf("%st%st%qn", fset.Position(pos), tok, lit)
}
}打印的结果我们接着往下看。
标记 token
标记(token) 是词法分析后留下的产物,是构成源代码的最小单位,但是这些 token 之间没有任何逻辑关系。以上述代码为例:
func demo() {
fmt.Println("When you are old and gray and full of sleep")
}经过词法分析后,会得到:
| token | literal(字面量,以string表示) |
| func | “func” |
| IDENT | “demo” |
| ( | “” |
| ) | “” |
| { | “” |
| IDENT | “fmt” |
| . | “” |
| IDENT | “Println” |
| ( | “” |
| STRING | “”When you are old and gray and full of sleep”” |
| ) | “” |
| ; | “n” |
| } | “” |
| ; | “n” |
在 Go 语言中,如果 token 类型就是一个字面量,例如整型,字符串类型等,那么它的值就是相对应的值,比如上表的 STRING;如果 token 是 Go 的关键词,那么它的值就是关键词,比如上表的 fun;对于分号,它的值则是换行符;其他 token 类要么是不合法的,如果是合法的,则值为空字符串,比如上表的 {。
语法分析 syntactic analysis
不具备逻辑关系的 token 经过语法分析(syntactic analysis,也叫 parsing)就可以得到具有逻辑关系的 CST 具体语法树,然后对 CST 进行分析提炼即可得到 AST 抽象语法树。完成语法分析的工具叫做语法分析器(parser)。Go 语言的go/parser 提供语法分析。
func ParserDemo() {
src := `
package main
`
fset := token.NewFileSet()
// 如果 src 为 nil,则使用第二个参数,它可以是一个 .go 文件地址
f, err := parser.ParseFile(fset, "", src, 0)
if err != nil {
panic(err)
}
ast.Print(fset, f)
}打印出来的 AST:
0 *ast.File {
1 . Package: 2:1
2 . Name: *ast.Ident {
3 . . NamePos: 2:9
4 . . Name: "main"
5 . }
6 . FileStart: 1:1
7 . FileEnd: 2:14
8 . Scope: *ast.Scope {
9 . . Objects: map[string]*ast.Object (len = 0) {}
10 . }
11 }它包含了源代码的结构信息,看起来像一个 JSON。
总结
源代码经过词法分析后得到 token(标记),token 经过语法分析得到 CST 具体语法树,在 CST 上创建 AST 抽象语法树。 来个图图或许更直观:
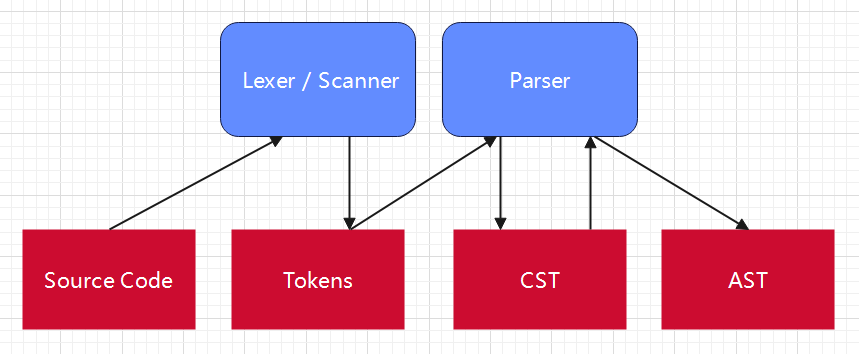
Go 的抽象语法树
这里我们以一个具体的例子来看:从 go 代码中提取所有结构体的名称。
// 源码
type A struct{}
type B struct{}
type C struct{}func ExampleGetStructName() {
fileSet := token.NewFileSet()
node, err := parser.ParseFile(fileSet, "demo.go", nil, parser.ParseComments)
if err != nil {
return
}
ast.Inspect(node, func(n ast.Node) bool {
if v, ok := n.(*ast.TypeSpec); ok {
fmt.Println(v.Name服务器托管网.Name)
}
return true
})
// Output:
// A
// B
// C
}服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
文章目录 结构体内存对齐 结构体内存对齐 对齐规则: 1.结构体的第一个成员,对齐到结构体在内存中存放位置的0偏移处 2.从第二个成员开始,每个成员都要对齐到(一个对齐数)的整数倍处对齐数。 对齐数:结构体成员服务器托管网自身大小和默认对齐数的较小值 VS:默…
