
文章目录
- 环境配置
- bean是什么
- 最终成品功能
- 数据库与缓存一致性
- 整个web系统后端的结构
- spring mvc相关
- controller常见的代码写法
- mybatis相关
- 常识
- 测试、调试相关
- 计网相关
- component相关注解
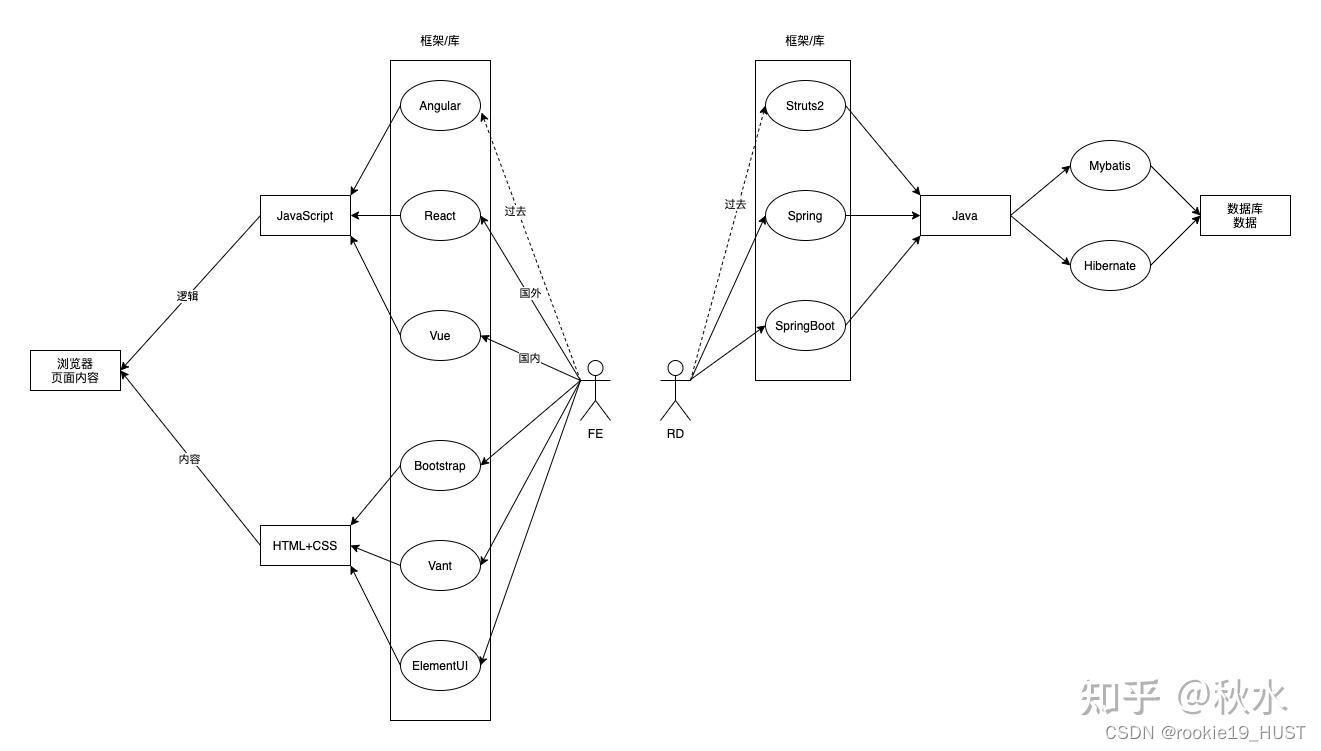
- spring全家桶族谱
-
- spring衍生框架
- run之后发生了什么
- 什么是spring,spring和bean的关系
- 形如factoryBean的写法
- 从请求到返回
- 重定向与转发
- 发邮件功能细节
- 注册功能细节
- 登录和会话功能
- 登录信息显示与拦截器
- 图片上传功能
- 发布帖子与异步请求
- 看帖子详情
- 评论,楼套楼
- 私信/系统通知功能
- 统一异常处理
- 统一日志处理与AOP思想
- redis相关与点赞/关注
- redis与网站数据统计
- kafka相关与系统通知功能
- ElasticSearch与贴子搜索
- spring security和csrf
- spring quartz与任务调度
- spring的事务管理
- 缓存与性能优化
- 缓存一致性
- jmeter压测
- 项目中能体现重载的点
- 存储位置盘点
- 附录
-
- redis命令行常用命令
- 贴子分数计算方法
- 生成长图
各官方文档都在spring.io。
比如查Thymeleaf配置项名称。
环境配置
idea中的maven报错信息确实不完整,该用命令行还是得用命令行。
idea社区版和专业版有区别,建议还是使用专业版,可以手动访问https://start.spring.io/。
pom里报包找不到的错误,先去本地看下包在不在,不在就mvn install。
bean是什么
Java语言欠缺属性、事件、多重继承功能。所以,如果要在Java程序中实现一些面向对象编程的常见需求,只能手写大量胶水代码。Java Bean正是编写这套胶水代码的惯用模式或约定,包括:
所有属性私有,提供getXxx、setXxx方法,
isXxx、addXxxListener、XxxEvent,
成员可序列化,自身可序列化,
有无参数构造器。
最终成品功能
一般规律是先开发展示功能,再开发增添功能。
用户模块:注册、登录、个人设置;
贴子模块:显示贴子、发帖、帖子详情;
评论模块:显示评论、发评论、评论的回复;
消息模块:私信、系统通知;
数据库与缓存一致性
下图这个是课程设计。
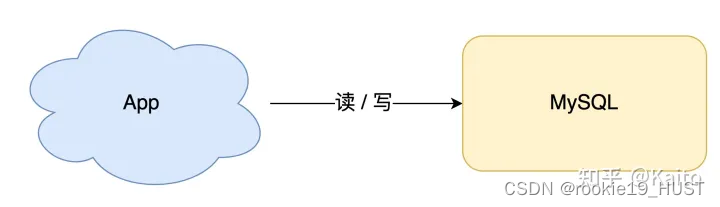
下面这个是现在比较流行的解决方案。
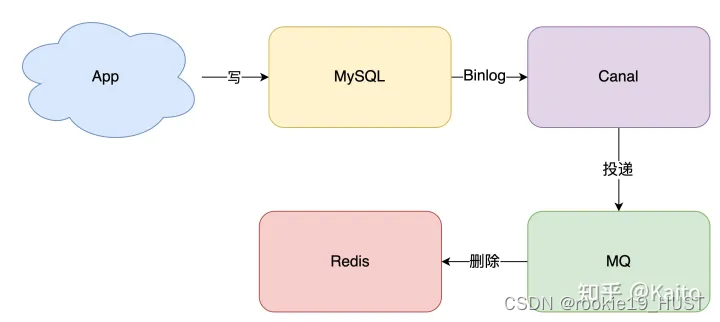
当一条数据发生修改时,MySQL 就会产生一条变更日志(Binlog),我们可以订阅这个日志,拿到具体操作的数据,然后再根据这条数据,去删除对应的缓存。
整个web系统后端的结构
应用层(Controller)、服务层(Service)、数据层(Dao)。
可以从目录结构上看出来,一个配置文件类,上面三个目录。
如果想用第三方bean,往往还会有config目录,里面是@configuration的配置类。
一般还会有Entity目录,比如User用户实体、Post贴子实体。
controller目录下会有所有动态资源访问路径。
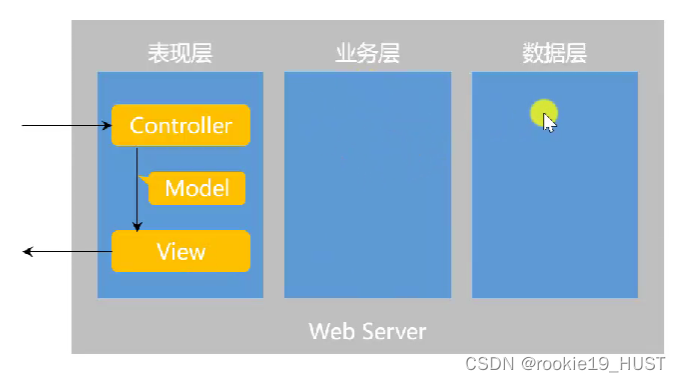
开发顺序,库字段设计/实体类-mapper-service-controller-html模板。
表现层,从外部获取数据、查询关联数据;
业务层,处理数据(转义、过滤敏感词);
数据层,增删改查。
spring mvc相关
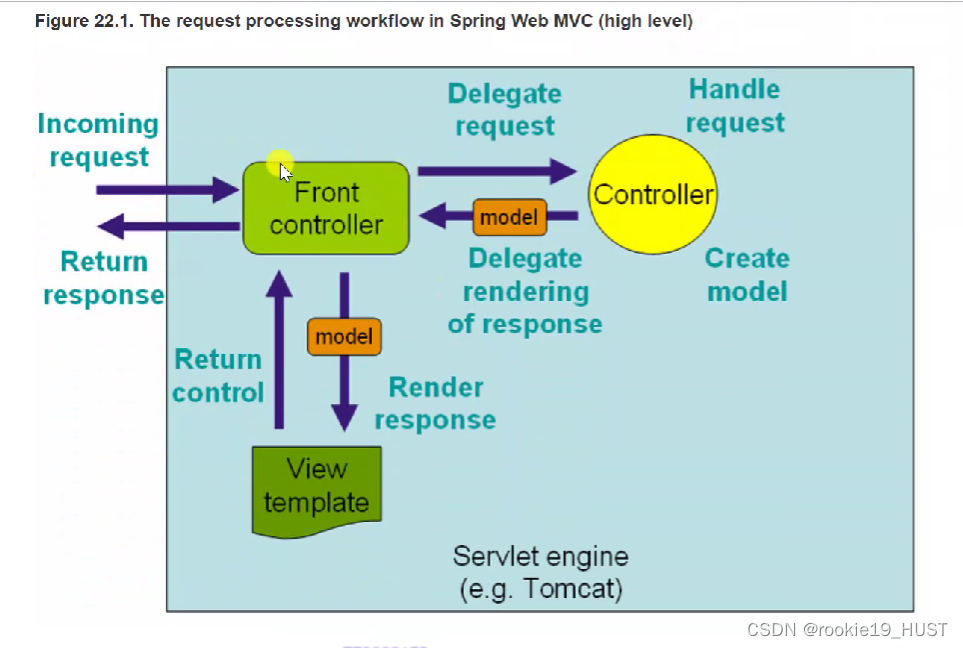
spring MVC就是解决表现层,Model做数据封装,view模板中的值用model里的数据来替换。
核心组件是Dispatcher Servlet,前端控制器,也就是下图中的front controller。
Thymeleaf是模板引擎,用在MVC结构的V,用模板+model给的数据,生成动态html。其它模板引擎未必以.html文件为模板。
在main的resources的application.properties中,开发环境需要关闭缓存,确保代码修改立即生效;生产环境需要开启缓存,降低服务器压力。
application.properties中的每一个配置项,都对应一个配置类中的一个属性,比如server.port对应ServerProperties类的port属性。
thymeleaf模板文件的写法,感觉封装程度很高。一般是在标签头加th:xx。常用的功能如:
th:each,比如ul标签下,列表列出20个贴子;
th:if,比如有置顶标记的才显示置顶图标;
th:utext,文本替换,u表示转义;
th:src=${map.user.headerUrl},map为model给的数据,这句话实际上相当于map.get(“user”).headerUrl,有很多所谓的“自动识别”,所以才说封装程度高。
dollar表示thymeleaf中的变量,井号用于函数调用(比如列表生成、日期格式化函数),at表示路径,比如:
a class="page-link" th:href="@{${page.path}(current=1)}">首页a>
thymeleaf的html中引用其它css等文件时,相对路径要改成thymeleaf风格(绝对路径可以不改),视频中有提到解决方案,th:src或者th:href配合at符号。我猜测公司里的前端部门会提供原始html,后端部门负责改写为thymeleaf风格。
controller常见的代码写法
针对get方法、请求的路径等,进行针对性处理。例如:
// /students?current=1&limit=20
@RequestMapping(path='/students', method=RequestMethod.GET)
@ResponseBody // 不加这个修饰默认返回html。
public String getStudents(
@RequestParam(name = "current", required = "False", defaultValue = "1") int current,
@RequestParam(name = "limit", required = "False", defaultValue = "20") int limit,
) {
//
}
// /students/123
// 这是另一种传参方式,路径拼接,有另外的写法,此处略。
此外,也能处理post请求。
可以返回html,也可以返回字符串,也可以返回json(返回值类型填map)。
理论上json可以承载任何数据。
mybatis相关
有了mybatis,操作属性就相当于操作数据库里的字段。前者是javaentity,驼峰命名,在mapper.xml中用#{}包裹;后者用下划线分词。
dao目录下,mapper接口,把准备写的增删改查方法声明一遍;
entity目录下,建一个类,类名和表名对应,把属性(字段)声明一遍,以及相应的get、set方法;
resources的mapper目录下,创建表名-mapper.xml,xml中把接口中各方法的sql语句写好;
其实未必要在xml里写sql,也可以在mapper接口中,把sql语句写在@insert等注解里。
xml的sql中有一些常用写法:
列出所有字段,而不是用星号;
用sql标签,类似宏定义,只用改一处;
对sql语句进行条件拼接,传进来的条件多,则where的and也变多。
日志等级设为debug,打印出实际执行的sql语句,以免xml里写错。
常识
tomcat,轻量web服务器。
springbootapplication注解表示这个类用作为配置文件。
注解可以由更多注解组成。
IoC的调用方依赖的是接口,接口可以随意做实现类。从而调用方与实现类解耦。
https://mvnrepository.com/上可以看想调某个第三方包时,需要怎么写pom。
spring整合了各个衍生框架,因此配置文件只用写一份儿。日志配置也写在这。
datasource,连接池,能控制资源上限、复用连接减少创建开销。如HikariDataSource。
idea中,alt+ins可以快速生成get set方法,或者toString方法。
select返回的是字段结构体,update、insert、delete返回的是行数。
表中的冗余字段可以减少关联查询。
查询第几行到第几行,mysql可以直接简写limit offset, rows,一般可以写为limit rows offset offset.
可以搞个global.js,里面放一些全局变量,充当配置文件来使用,达到改一处=改处处的效果。至于Java代码这边,全局变量可以写spring的properties里,然后@value就可以了。
服务器会创建线程来处理每一个请求。
字典树(前缀树)可以做敏感词过滤,而且可以跳过分隔符号,来防止绕过。此外字典树也能词频统计和字符串排序。
set方法的一个小技巧,返回对象本身,这样写的时候可以instance.set(a).set(b)。
把常量放在一个接口里,命名为xxxConstant,然后可以通过implement来引用这些常量。
swagger配合java注解,可以生成网页版的接口文档。
本项目使用jquery和bootstrap,后者是个ui组件库。
测试、调试相关
@ContextConfiguration这个注解通常与@RunWith(SpringJUnit4ClassRunner.class)联合使用用来测试。
带有@test注解的方法都可以单独运行。
想测谁,就在测试类里autowire注入。
js代码的调试,可以在浏览器中f12,sources,找到对应js文件,下断点等经典调试操作都支持。
计网相关
get和post理论上可以解决所有问题。get也能发送,但长度有限、而且裸奔。
为啥要有json,因为json可以跨语言。
http本身无状态(指请求之间没有关联),借助cookies可以创建有状态的会话。cookie由服务器创建,浏览器收到之后,之后的请求都会带上cookie。cookie可以作为session id。
component相关注解
带有component注解的bean,就会被扫描到。
service,业务;
controller,处理网络请求;
repository,数据库访问;
configuration,配置类。
也可以直接用component。
这些注解后的括号和字符串就是bean的名字,如果不加,默认是类名首字母小写。通过名字或者名字+类.class可以找到bean。
spring全家桶族谱
说spring一般是指spring framework。
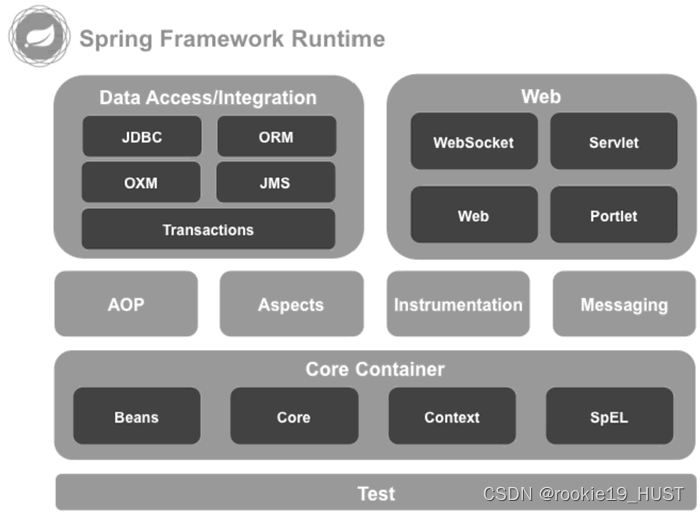
Core 模块:Spring 框架的基本组成部分,它包括控制反转及依赖注入功能。
Beans 模块:实现 Spring 对 Bean 的管理,包括自动装配机制等功能。
Context 模块:用于访问项目配置及自定义对象,ApplicationContext 接口是 Context 模块最重要的接口。
SpEL 模块(Spring Expression Language,表达式语言模块):提供在运行时查询和操作一个对象的表达式机制。
JDBC 模块:用于实现 JDBC API 的抽象层。
ORM 模块:对象关系数据库映射抽象层,基于该模块,Spring 框架可以方便地集成 Hibernate 和 MyBatis。
OXM 模块(XML消息绑定抽象层):基于该模块,使 Spring 框架能够支持 JAXB、Castor、XMLBeans、JiBX 和 XStream。
JMS 模块:Spring 支持 Java 消息服务的重要模块,集成了 JMS 的项目即可实现消息生产和消费的功能。
Transactions 模块:Spring 的事务模块,Spring 框架支持编程式和声明式的事务管理。
Web 模块:即 Spring MVC,提供了基于“模型-视图-控制器”的基础 Web 应用框架,可替代 Struts 2。
Servlet 模块:实现统一的监听器和面向 Web 应用的上下文,用以初始化 IoC 容器。
AOP 模块:用于 Spring 面向切面的编程实现。
Aspects 模块:Spring 与 AspectJ 的集成,可以使用 AspectJ 来实现面向切面编程。
Test 测试模块:支持 JUnit 和 TestNG 单元框架的集成,可以快速开展业务代码的单元测试。
spring衍生框架
Spring Boot:轻松地创建独立的基于 Spring 的生产级应用程序
Spring Cloud:快速构建一个分布式系统的框架。
Spring Data:为数据库的访问提供一个一致的基于 Spring 的编程模型,保留底层数据存储的框架。
Spring Cloud Data Flow:面向云计算和 Kubernetes 的基于微服务的流和数据批处理处理框架。
Spring Security:一个功能强大且高度可定制的身份验证和访问控制的安全框架。
Spring Session:在 Web 应用中管理用户会话信息的框架。
Spring AMQP:AMQP 消息解决方案,该框架为消息的发送和接收提供一个模板方法。
Spring Web Service:该框架用于创建文档驱动的 Web 服务。
run之后发生了什么
tomcat会启动;
spring容器会启动;
带有springbootapplication注解的类,自动扫描所在包和子包中带有component注解的bean,并添加到容器中。
什么是spring,spring和bean的关系
spring容器的顶层接口是beanFactory,常用其子接口ApplicationContext。
它可以创建、初始化(@postconstruct)、添加、销毁(@predestroy)bean,控制bean的作用域(@scope可以决定singleton还是prototype。前者单例,后者每次get都是新的。默认是前者,比较常用)。
虽然可以applicationcontext可以getbean,像这样主动获取,来调用bean,
但实际上一般是@Autowired修饰属性,spring会自动get bean然后放到声明的变量里,之后直接用即可。
@Qualifier可以与@Autowired配合。
不止是在入口类里,在bean里也可以autoWired,从而实现controller调用Dao的代码。
@bean可以装配第三方类和自定义类。
形如factoryBean的写法
XXXfactoryBean里写的是bean的实例化过程,
加上@Bean,装配到Spring容器里,
将XXXfactoryBean注入到其它bean里,
其它bean就可以得到XXX的对象实例。
从请求到返回
题外话,mozilla网站有http的官方文档。
以下内容可以f12 network看见。
DNS。
建立TCP连接。
http request
http response,一开始一般是个html,解析过程中发现引用了css、js、图片;
多轮request和response。
浏览器渲染完成。
重定向与转发
总结来说,能在不耦合的情况下实现功能跳转。
下图,做了删除操作后,没什么好返回的,就返回302,建议对方另作请求,对方查询后,能看见删除的效果。
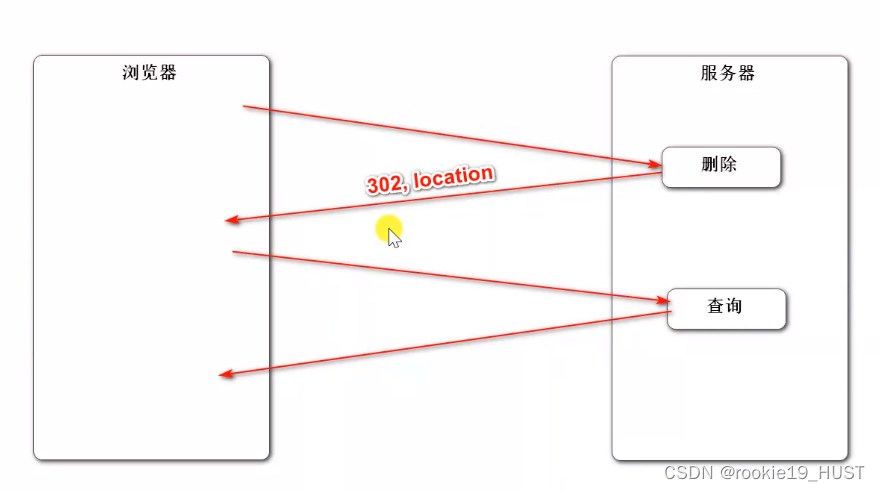
除了上图,另一个常见场景是注册完跳转到登录。
登录成功重定向,返回302,建议浏览器重新请求另一个路径,可以在地址栏看见地址发生变化。
重定向是低耦合的。
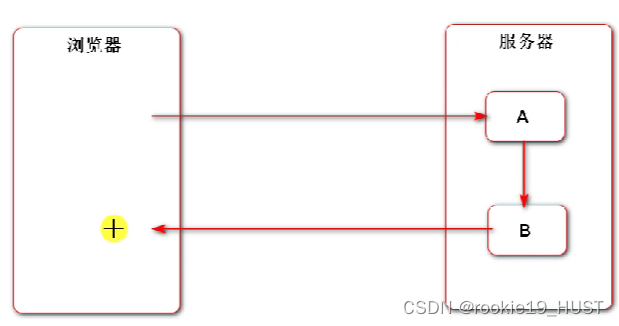
转发是与重定向并列的解决方案。
登录失败转发,A无法处理,内部转发给B,两者协作完成请求,存在耦合。
发邮件功能细节
整个行为的本质就是用java代码来模拟邮件客户端,来自动发邮件,从功能上来讲跟自己所写的主体web服务是可以分隔开的,真正做事的是邮件服务提供商。
需要注册一个邮箱,起一个官方的名字,
把smtp服务器(注册的新浪邮箱就是smtp.sina.com)、服务端口(465)、邮箱账号、邮箱密码等参数写在spring的properties里。
整个JavaMailSender类也比较简单,两个方法,构建邮件,发送邮件。
注册功能细节
分为三步,
第一步,点注册,要能展示注册页面;
第二步,提交数据,入库,生成激活链接;
第三步,接受激活。
第一步主要是表示层、tyhmeleaf的工作,不涉及数据层;controller中处理get和post;
第二步,可以用java.util.uuid生成随机字符串;然后要判断空、重复;生成salt和激活码写进库里;操作成功跳转操作成功界面;操作失败跳转回原界面,把用户的输入作为默认值留在原界面,并展示错误信息。
第三步,不能重复激活,不能用错误的激活码,或者激活成功。库里有两个字段,一个是int型的激活状态,一个是字符串型的激活码。
登录和会话功能
登陆状态维持、购物车,都会用到cookie。
cookie的生成就是用uuid,然后需要设置生效范围、生效时间。
nginx+多服务器的时候,如果是不同的服务器来处理,那session就丢失了。
一种方案是粘性session,即每个用户每次都在同一个服务器上处理,后果是负载不均衡。
一种方案是同步session,每个服务器存一份,存储和通信成本很大。
一种方案是专门一台服务器专门存session,其它服务器请求这台服务器,缺点是session服务器可能挂,不可靠、有性能瓶颈。
目前主流方案是session存在nosql数据库集群里,理由如下:
验证码一分钟内就会失效,看不清的时候会反复刷新;
访问很多地方都需要用到登录凭证和用户信息,使用频率高。
验证码生成一般用kaptcha库,kaptchaProducer输入字符串,输出图片;
将字符串答案记录到redis,key为新生成的UUID随机串,value为答案;
将key放在cookie里返回给用户;
登录逻辑的入参要包含刚刚的cookie;
用js实现刷新验证码,链接加随机数可以避免浏览器偷懒。
顺利通过登录逻辑的以下验证后:
验证码是否正确;
用户是否存在;
密码是否正确;
生成登录凭证ticket存入redis,并返回ticket给用户。这个ticket表的作用类似session。
ticket只需存在redis里,无需存在mysql里,不过user信息需要存两份。
存两份是因为访问频率高,又需要持久化。
相关逻辑:
查时先取redis;
查时取不到则存redis;
修改则删redis。
登录信息显示与拦截器
拦截器有点像插桩,或者装饰器。有三个执行时机,controller之前,controller之后~模板之前,模板引擎之后。
配置类中可以限制所有拦截器的生效范围(一对多),不过这种方法很麻烦。可以不exclude,拦截器拦截所有请求,利用反射获取注解,加了自定义注解的方法就鉴权,没加自定义注解的方法就直接放行。
拦截器的主要使用场景就是判断动态资源权限。权限判断、权限维持(把用户信息存在threadlocal里)。
图片上传功能
post请求,提交表单时enc-type=multipart/form-data。
图片和其它数据的区别不只是在提交,存储也不一样,存储存在服务器硬盘。
文件操作在表示层处理,Spring MVC的multifile。服务层只更新用户头像路径。
文件重命名并不是为了防文件上传漏洞,只是因为用户可能会用一样的名字。
发布帖子与异步请求
AJAX,异步javascript和xml。不过现在一般是用json。
目的是增量更新网页,而不需要刷新整个页面。
需要异步请求的例子是注册功能的“该昵称已被占用”,页面并没有刷新,但其实暗中请求了服务器;
另一个例子就是发帖。
实现异步请求,关键是html中的jquery。jquery发异步请求有三个参数,路径、数据、回调函数。
异步请求的http头会有x-requested-with。
dao层,发帖本质是增;
service层,转义标签(比如贴子内容里有html标签,应避免这个被解析)、过滤敏感词、调dao;
controller层,fastjson的基本使用(put),html中要写jQuery。
看帖子详情
dao层,看帖本质是select;
service层,直接调dao层mapper;
controller层,
此外,会影响首页index.html;
详情页的html里要展示头像、用户名、贴子标题、贴子内容。
评论,楼套楼
数据库字段有三个,实体类型,实体编号,目标。
实体类型是被评论对象类型,可以是贴子,可以是课程,也可以是评论。
实体编号是被评论对象id;
目标字段,仅在实体类型为评论时生效,表示被回复的对象。普通的评论的评论,没有目标;如果在楼中楼里发生相互回复,才有目标。
添加评论时需要用到事务管理,因为除了comment数据,也要连带修改贴子数据(评论数增加)。
私信/系统通知功能
可以展示和任何人的会话(多次对话),系统通知就是系统管理员和用户的私信;
可分为会话列表、私信详情(也就是私信列表)、发送私信,会话未读量要统计并可查。
数据库中每行是一条私信,关键字段:from id,to id,所属会话,私信内容,已读未读。
“所属会话”格式为小id_大id,因为a to b和b to a理应为同一个会话。
service层要想好提供什么查询,按user查会话数量/会话,按会话查消息数,按会话和user查未读量。
显示的时候,显示会话的另一方(而不是自己)。
统一异常处理
借助@controllerAdvice可以处理所有异常,少写很多代码。
统一在表现层处理异常,统一在全局advice类内处理表现层异常,
@controllerAdvice加在类上,这个类通常负责所有controller的全局配置,总揽各controller。
这个advice类里可以有带以下注解的方法:
@ExceptionHandler,各controller中出现异常后执行
@ModelAttribute,给model统一的共享参数(cur/next与异常处理无关,但与上一个并列)
@DataBinder,能把get等网络请求参数,转为对象的属性(各controller参数的自动转换就靠这个)
统一日志处理与AOP思想
我们希望把业务需求和系统需求(日志是系统需求)分开。
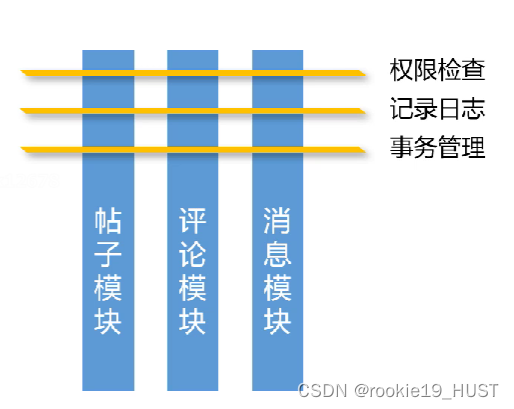
AOP与OOP互补,上图的三条横线就是切面。
切这个动作,英文是weaving,一般称为“织入”。
可织入位置被称为joinpoint,连接点。
编译时织入,使用特殊的编译器。好处是快,坏处是缺少运行时信息,不够精细。例子是AspectJ。
装载时织入,需要使用特殊的类装载器。
运行时织入,为目标生成代理对象。例子是Spring AOP。
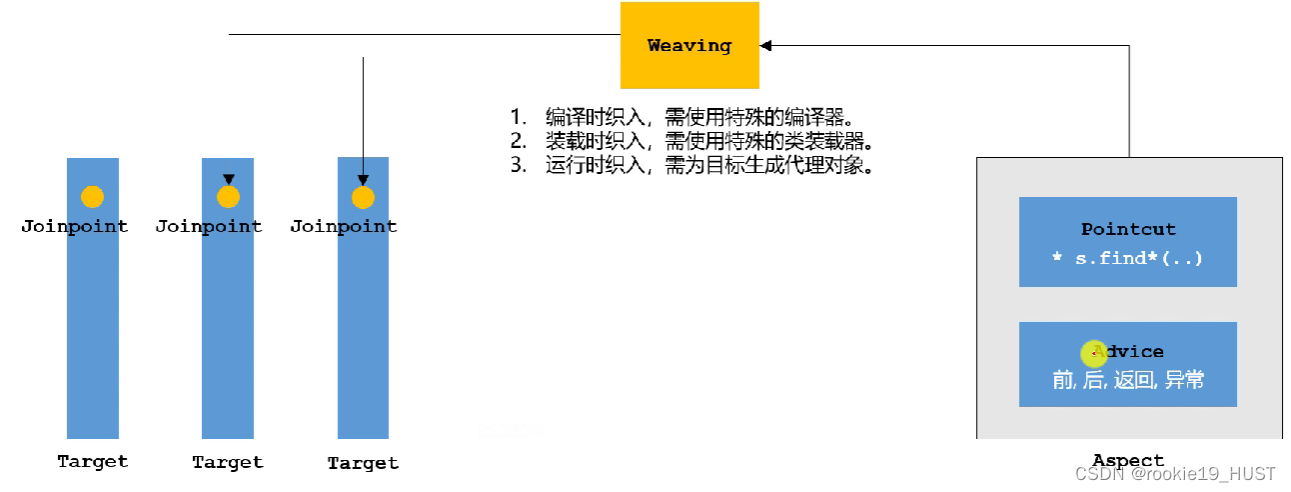
pointcut指定切入位置,advice则是切入内容。
实际运行时,目标对象不会被运行,代理对象才是真正运行的那个。
如果目标对象有接口,Spring AOP使用JDK动态代理,创建接口的代理实例。
如果目标对象没有接口,Spring AOP使用CGLib动态代理,创建子类的代理实例。
redis相关与点赞/关注
redis.io官网上,可以查命令。redis命令行常用指令见附录。
Redis 官方不建议在 windows 下使用 Redis,微软提供了一个老版本。
键值对nosql,全部在内存中。
偶尔往硬盘上写快照或日志,前者耗时(定时),后者耗空间、存时快(实时)、恢复慢。
典型应用场景,缓存、排行榜、计数器(贴子浏览量、点赞)。
java类型的数据,要存到redis里,需要做些转换,在RedisConfig类里,配置各种key的序列化方式。
配好之后,可以通过redisTemplate.opsForXXX() (此处的XXX为redis数据类型,比如string型对应opsForValue())来读写redis。
key一般是冒号连接的字符串,value是string、list、hash、set、ordered set等。
可以通过redisTemplate.boundValueOps绑定key,简化代码,否则每次操作都要指定key。
java中操作redis,命令会先进入服务器托管网队列,在事务提交时才会批量查询。事务中间查询,不会得到预期值。
点赞的设计,需要知道谁、给哪个类型、的哪一个实体、和背后的作者点了赞,userID,entityType,entityId,entityUserId四个参数。
redis中,与点赞相关的key有两大类:
userId为key,赞数为value;
以entityType:entityId为key,点赞者集合为value。
前者是为了方便按userId查点赞总数,后者是方便单数赞双数取消。
类似点赞,关注和取关也可反复点,也希望能按userId查关注/粉丝数。并且也可以给多种实体关注。
我的followee是我关注的人,我的follower是我的粉丝。
以userId:entityType为key,关注实体zset(entityId, followTime)为value。
以entityType:entityId为key,粉丝集合zset(userId, followTime)为value。
原视频在前端的处理是刷新页面(window.location.reload()),算是简化代码的dirty写法。
redis与网站数据统计
除了string,set,zset,list等基本数据类型以外,
HyperLogLog,基数算法,有误差但很小。常用于统计独立总数,同一个人一天内访问多次算一次,hyperloglog可以解决这种需要去重的情况(比如UV,unique visitor)。set也能实现,但hyperLogLog不管统计多少数据,只占12k。多个hyperLogLog之间可以很方便地用union方法合并。
bitmap,没这个类型,实际使用string型(写用opsForValue.setBit(),读用opsForValue.getBit(),统计用bitCount,此外还可以多个bitmap做与或非运算),可以看成byte数组。适合统计签到,也就是DAU(daily active user)。
kafka相关与系统通知功能
java自带阻塞队列BlockingQueue接口,解决线程通信问题。有put和take方法。
阻塞指的是,队列满了阻塞生产者,队列空了阻塞消费者,阻塞可以避免资源浪费。
原视频在test目录下写了个java原生阻塞队列(实现类之一叫ArrayBlockingQueue)的demo,可以作为生产-消费模式的demo来复习。
生产消费和发布订阅有些相似。区别是一个消息可能被消费的次数。生产消费模式始终为1。
kafka把数据存在硬盘,所以数据规模可以很大,
硬盘的顺序读取速度约200-300MB/s,接近内存随机读取速度的下限。
kafka使用zookeeper来管理集群。
kafka服务器称为broker,一个topic分为多个partition,replica副本决定复制的份数。
spring中,
生产者调kafkaTemplate.send(topic, data)
消费者调@KafkaListener(topics={“test”})修饰handleMessage方法。
评论、点赞、关注三大高频事件都要发通知,消息队列可以实现异步。
构造事件对象,开发事件生产者,开发事件消费者。
事件的属性:topic,userId,entityType,entityId,entityUserId,map。
在评论、点赞、关注的逻辑里构造事件,塞给producer;
生产者负责从事件中获取topic和data,然后调用kafkaTemplate.send;
消费者负责解析、处理data,然后存到message表里。
生产者的入参是Event类型,消费者的入参是ConsumerRecord类型。
每个topic对应一类需要消费的事件,除了上面提到的评论关注点赞(消费是发通知),还有贴子搜索一节中的发帖(消费是存取es,新帖和新评论都算发帖事件)。
ElasticSearch与贴子搜索
实时搜索。默认端口9300。
数据提交的时候就会在ES存一份,分词、建立索引。
ES6和ES7区别较大。ES7.0后,
ES的索引对标mysql的表,
ES的文档对标mysql的行,
ES的字段对标mysql的列。
分片提高并发能力,副本提高可用性。
中文环境需要配合ik插件。IKAnalyzer.cfg.xml中可以添加自定义的扩展词典。
停止词会被作为分隔符。
ES提供服务都是靠rest api。
curl -X可以指定请求方式,get、post、put等,可以用于测试restapi。
postman可以当curl用,有图形界面会方便一些,可以直接写body。
用户提交的搜索关键字也会被分词。
给实体类加elasticsearch的@Document(indexName, type, shards, replicas),
即可自动映射实体类和es库字段
es可以视为一种特殊的数据库,与帖子库共同增删改查,不过是异步,构造事件,塞给消息队列。
对实体类内部的字段也需要加注解,指定field type。
除了field type,还可以指定analyzer,指定存储时分词策略、搜索时分词策略。
对title指定analyzer为ik_max_word,指定search_analyzer为ik_smart。
extends es库的ElasticsearchRepository类,不需要填什么内容,
可以直接调用其实例的save和saveAll方法,写入/批量写入es库。
此外还有delete和deleteAll方法。
查的时候,需要先build一个query,
withQuery指定高级查询的关键词等选项,
withSort方法按置顶、精华、分数、时间来排序。
withHighLightFields可以给匹配到的关键词前后加em等html tag。
(此处未完全列举query构造过程,回想一下各个论坛的搜索功能即可)
构造好query后,可以用ElasticsearchTemplate或者ElasticsearchRepository,后者的封装程度更高。
在原视频中,高亮关键字的功能实现起来有点绕,用的elasticsearchTemplate。
查询会返回spring的page类型。
视图层,在首页的顶栏代码里处理搜索,其它页面复用此header即可。
展示搜索结果的页面和首页也比较相似。
spring security和csrf
提供身份认证和授权,防护csrf。
filter是Java EE的,可以在dispatcherServlet前进行拦截,servlet也是Java EE的。这种拦截类似interceptor在controller前的拦截。之前的鉴权用的是interceptor,security的拦截更早,更安全。
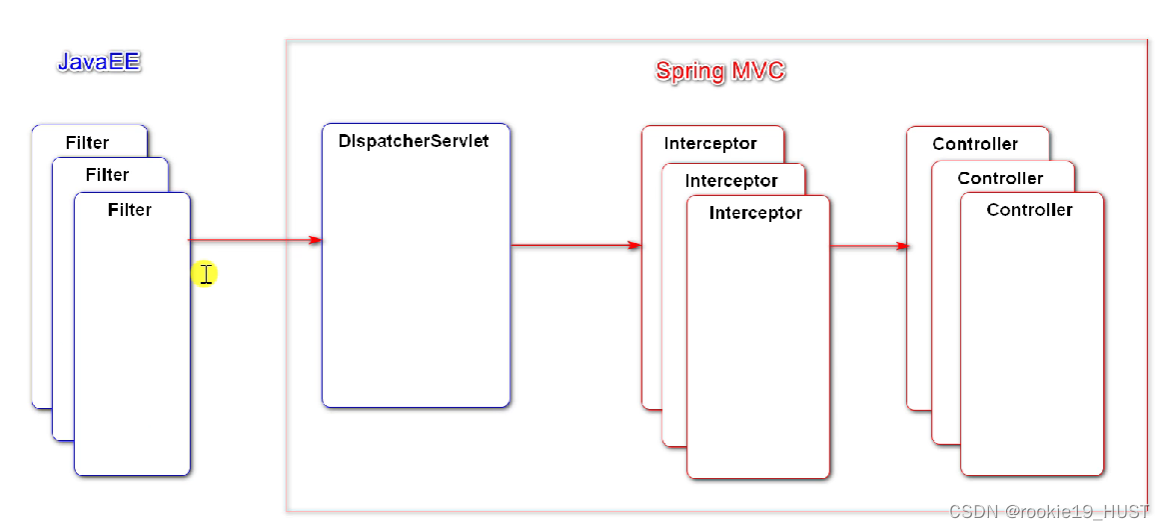
Spring security的核心就是11个filter,各司其职,比如其中一个专门验证账号密码,其中一个专门退出,等等。
可以自定义filter,filter可以在filter之前,比如先校验验证码,再校验账号密码。
让User实体类实现security的UserDetails接口,然后就要实现以下方法:
判断用户是否过期,是否锁定,是否可用,凭证是否过期,获取用户权限。
获取用户权限方法中,一个用户可能有多种身份/权限。
让UserService类实现security的UserDetailsService接口。
Spring Security会有一个统一的配置类。
AuthenticationManager是认证核心接口,ProviderManager是其实现类。
ProviderManager持有一组AuthenticationProvider,每个AuthenticationProvider负责一种认证(可能有多种登录方式,比如微信登录等等)。ProviderManager将认证委托给了AuthenticationProvider,这是委托设计模式。
configure方法里,可以对每个动态路径设置“可以访问的权限级别”,示例如下。
http.authorizeRequests().
antMatchers(
"/user/setting",
)
.hasAnyAuthority(
AUTHORITY_USER,
AUTHORITY_ADMIN,
AUTHORITY_MODERATOR
)
.anyRequest().permitAll(); //除了上面列出的,都允许随意访问
spring security可以与thymeleaf互动,使得高权限用户能看见的置顶、加精、删除的按钮。
可以把贴子id隐藏在页面里,方便发异步请求的时候获取。
spring security可以防范csrf,当用户请求表单页面,服务端在返回的表单中加入隐藏项:
input type="hidden" name="_csrf" value="随机字符串">
对于异步请求,没有表单,
服务端需要在html的head里加两个meta字段,分别是_csrf和_csrf_header;
服务端提供的js,会在ajax jQuery请求头里加上selector,获取html中的csrf token。
spring quartz与任务调度
每隔一小时计算贴子分数;(只需要对发生变化的贴子重新运算,变化时加入redis set)
每隔半小时清理服务器临时文件;
类似这样的需求,需要定时任务。自动运行,所以肯定是多线程。
ExecutorService和ScheduledExecutorService是JDK内置的线程池,后者是做定时任务的。
ThreadPoolTaskExecutor和ThreadPoolTaskScheduler是Spring的线程池,后者做定时任务。
另外,Spring还提供@Async、@Scheduled,分别作为Spring线程池、Spring定时任务线程池的简化方式。
普通线程用ThreadPoolTaskExecutor即可。
分布式环境下的定时任务一般用Spring整合quartz,而不用上面的,上面的基于内存,不同服务器不共享内存,因此多机可能会重复处理。而Quartz的相关配置存在单一数据库,有锁,任务就不会被重复做。
项目中用到的线程池参数,
core-size,核心线程,不会被释放。
max-size,线程池最大大小。
queue-size,排队长度。
Quartz的使用,先实现Job写好任务内容,然后用JobDetail(job名字、描述、组、对应类等配置)和Trigger(上一次执行时间、执行次数)。与Quartz数据库各表(比如JobDetail表、trigger表)字段对应。
spring的事务管理
声明式,可以通过XML或者@Transactional注解,声明某方法的事务特征(隔离级别、传播机制)。
编程式,用transactionTemplate类来实现,虽然麻烦,但可以精准操作一个方法中的局部步骤。
一般用编程式事务。
缓存与性能优化
分为两类,
本地缓存,如guava、caffeine(目前最佳),容量相对小。
分布式缓存,如memcache、redis集群,缓存在其它机器上,容量相对大。
caffeine缓存性能接近理论最优,结合了LRU和LFU的优点。
多级缓存是指三级存储:本地缓存-分布式缓存-DB
缓存击穿是指缓存失效,大量请求直达DB。
两种缓存同时失效的概率较小。
与用户强关联的数据应该缓存在分布式缓存。
对于热门贴子,访问频率高,希望能优化性能。
可以存在本地缓存。因为它不需要判断权限,所以不需要去分布式缓存里取用户信息。
性能优化的代码一般在service层。
caffeine的核心接口为cache,loadingCache(没查到就同步去取),AsyncLoadingCache。
缓存的更新时间,取决于变化频率和资源量。原视频设定是180s。
缓存一服务器托管网致性
原视频使用的是,
写数据的时候构造event,给kafka producer,然后消费者写数据库、删缓存。
流行的方案是写数据时直接写库,canal订阅mysql的binlog,canal给kafka,消费者写数据库、删缓存。
jmeter压测
创建测试计划,设置线程数,让它循环,设定运行时长。
指定协议、ip、端口、方法、参数。
创建定时器,随机间隔。
添加监听器,聚合报告,看吞吐量。
项目中能体现重载的点
比如报错不一定有msg,但一定有错误码;
再比如补充传一个.class,就不用强制父类转子类。
存储位置盘点
静态资源:存硬盘,用的文件系统
用户信息、贴子内容:存mysql数据库
用户登陆凭证、用户信息、验证码:存redis
用户上传的头像:客户端直接传给云服务器
分享生成长图:服务器传给云服务器
附录
redis命令行常用命令
通用指令:
select 0/1/2,换库
flushdb,清空
keys,看有哪些key,比如keys *,查看所有key;keys test*,正则匹配看test开头的key
type/exists/del key,查看key类型、是否存在、删除
expire key time,设置过期时间
操作字符串:
set key value
get key
incr/decr key
操作hash表
hset key field value
hget key field
操作list
lpush/rpop listname,左进、右出,也可以左出右进
llen listname,长度
lindex/lrange listname,下标访问/区间访问
操作set
sadd setname item1 item2 …, 添加元素
scard setname,大小
spop setname,随机弹出,可用于抽奖
smembers setname,显示全部元素
操作ordered set
zadd setname score1 item1 score2 item2 …,添加元素
zcard setname,大小
zscore setname item,查分
zrank setname item,查元素的大小顺序
贴子分数计算方法
考虑的变量如下:
反比:发布/更新时间(stackoverflow经常会更新问题),
正比:精华,阅读量,评论/回答数,(评论)点赞数,收藏/关注数(比如知乎就可以关注问题)。
对上面的几个数值,往往取log,最早的10个赞比后来的100个赞更有含金量。
生成长图
服务端可以用html转pdf的工具。如wkhtmltopdf。转完之后服务器传给云服务器。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
博客系统(二) 博客系统 获取当前用户的信息 对密服务器托管网码进行加密和解密的操作 设置统一的数据返回格式 设置未登录拦截 设置线程池 博客系统 博客系统是干什么的? CSDN就是一个典型的博客系统。而我在这里就是通过模拟实现一个博客系统,这是一个较为简单的…
