

- 之前我们会觉得cmdb自动发现没有上报很难排查,弄不清楚数据的上报链路;
- 监控指标的数据断点很难定位,flink对现场来说是一个黑盒子;
- apm数据更新服务器托管网不及时到底是上报异常还是入库失败呢?
现在控制台集成了对数据链路的监控,数据上报链路全透明,问题节点一目了然,极大的减少问题定位的难度。
「 全 链 路 监 控 」
全链路监控包括原始指标链路、告警链路、Trace原始链路、Trace聚合服务器托管网链路、资源发现链路、指标入库成功率报错。平台常用的数据链路都已纳管,可以清楚的判断数据链路是否异常。链路治理可以帮助我们分析整体情况,展示整个数据链路,但是个别的任务上报异常还是需要跟踪日志排查。
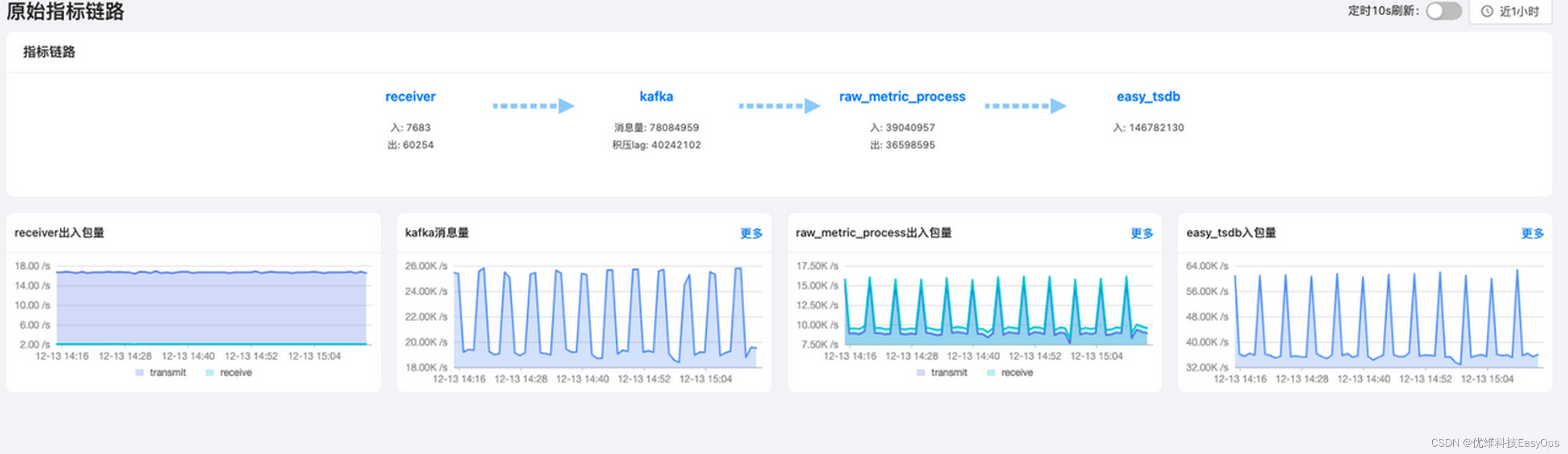
1.原始指标链路
监控原始指标的上报路径为agent(easy_process_sampler)–> receiver –>kafka –>raw_metric_process –> easy_tsdb
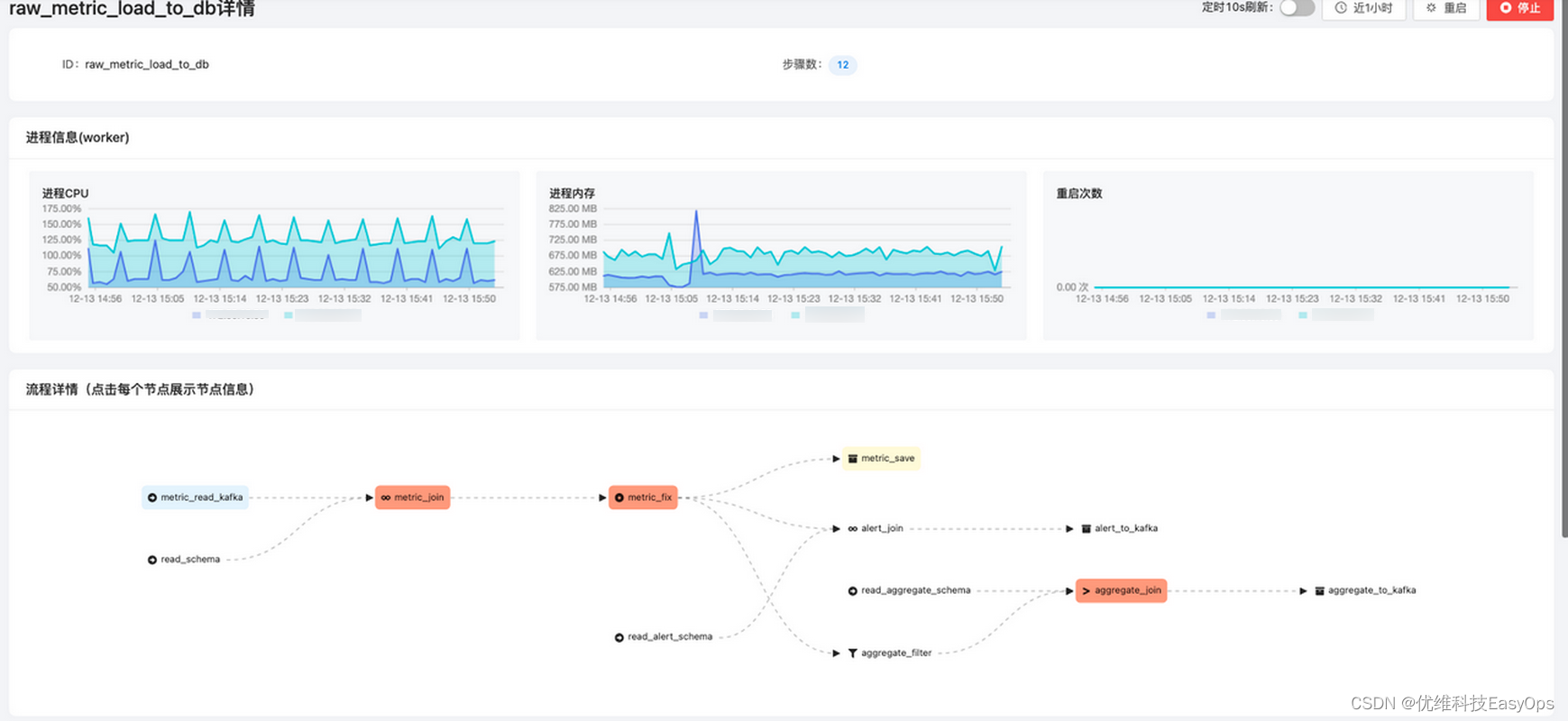
当我们发现监控平台大部分dashboard都出现断点或无数据的情况时,我们可以先查看该数据链路,查看各个节点的出入包量,如果发现某一个环节不断在累积,则可以定位是下一个节点出现了异常,没有消费,点击右上角的更多跳转到组件的详细页面查看。图中呈波浪状的情况是正常的,原因是raw_metric_process是批量消费kafka,再批量入库的,只要积压量不是随时间成正比增长,数据链路就是正常的。
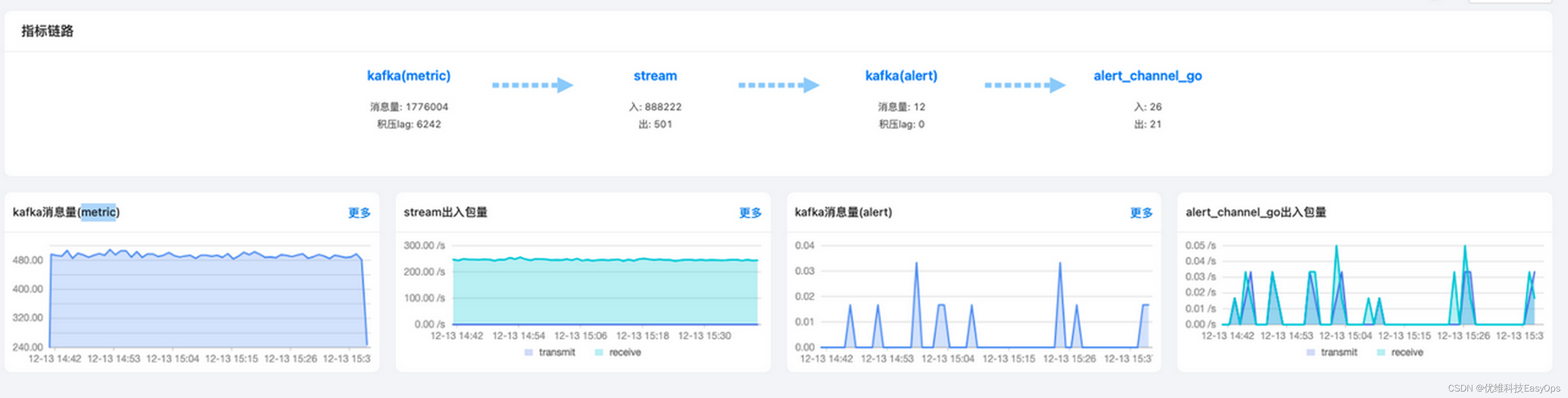
2.告警链路
监控告警链路为:kafka–>stream –>kafka –> alert_channel_go –>notify
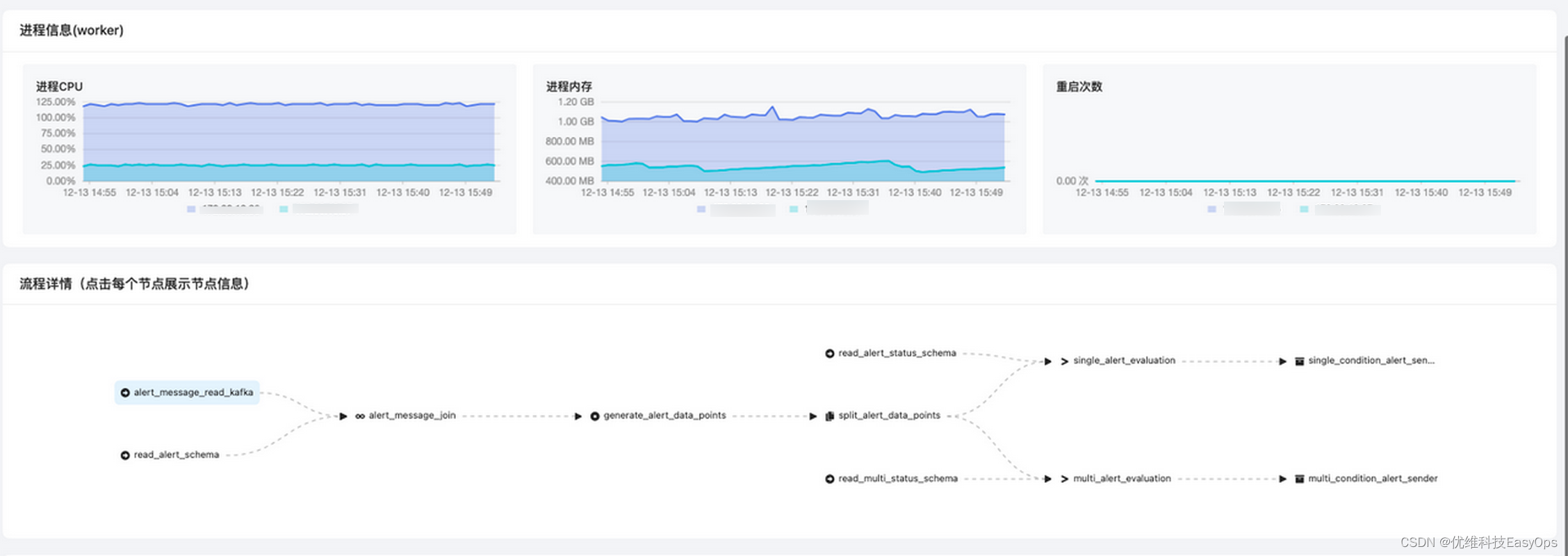
指标写入到kafka后经过流处理,匹配告警规则,符合告警条件就将告警写入到kafka中,alert_channel_go消费kafka的告警队列整合告警消息,通过notify发送给用户。
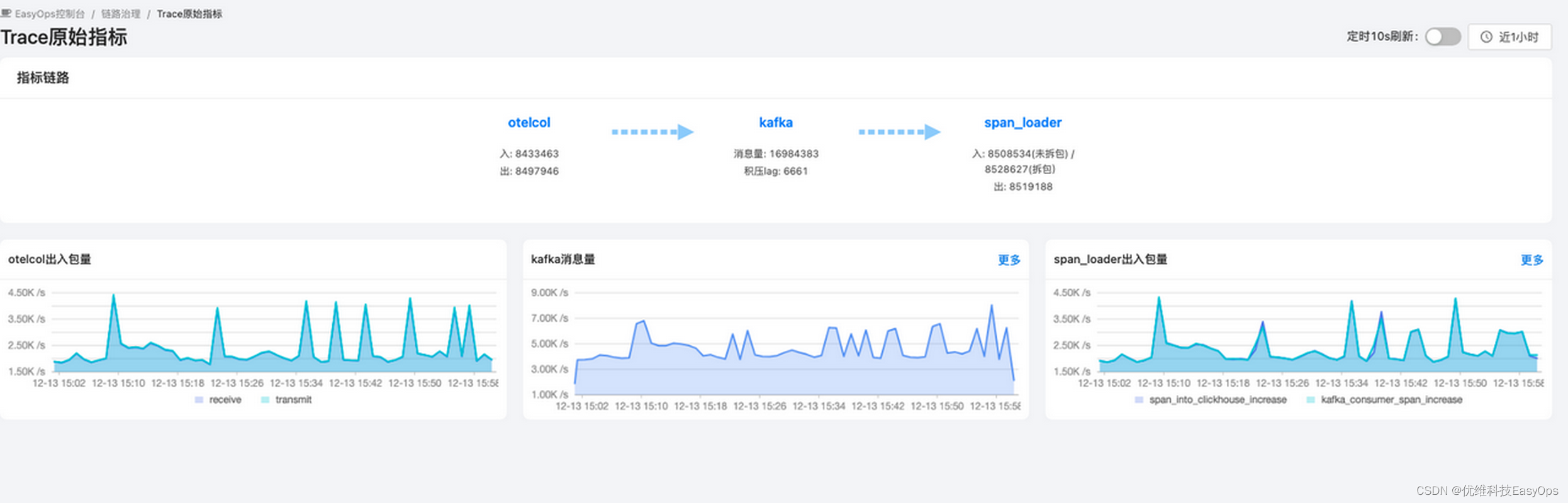
3.Trace原始指标链路
该链路是处理apm原始数据的入库的,agent (easy_trace_sampler)–>otelcol –>kafka –> span_loader –> clickhouse,当apm数据没有实时更新时可以查看该数据链路测处理情况。
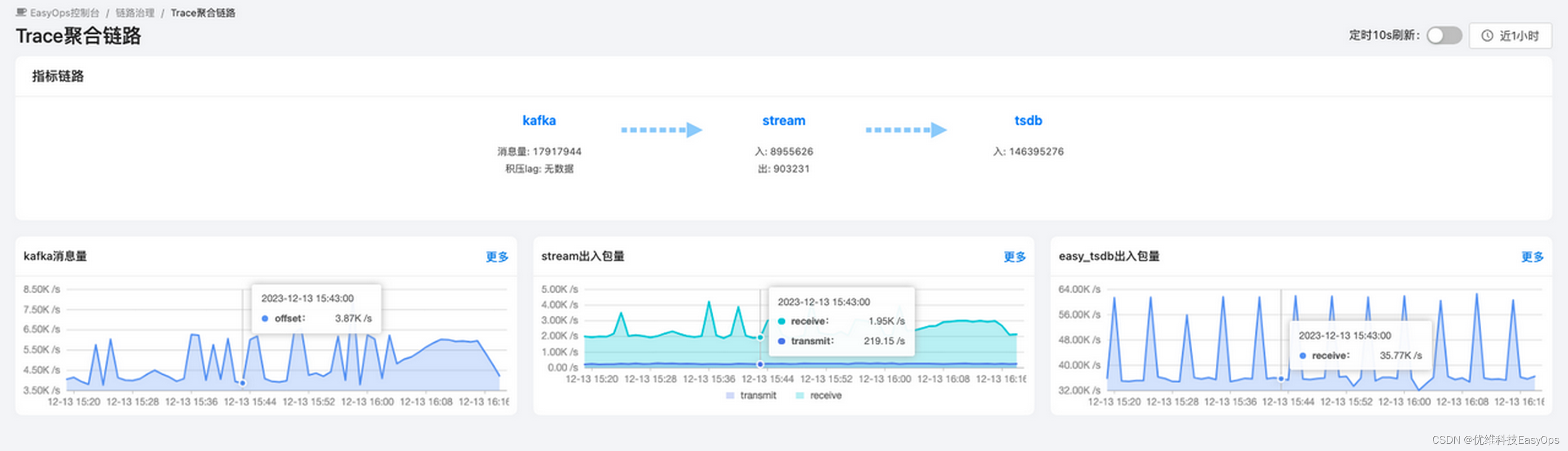
4.Trace聚合链路
Trace聚合链路用于统计apm数据的成功率、失败率、延时等整体情况指标。
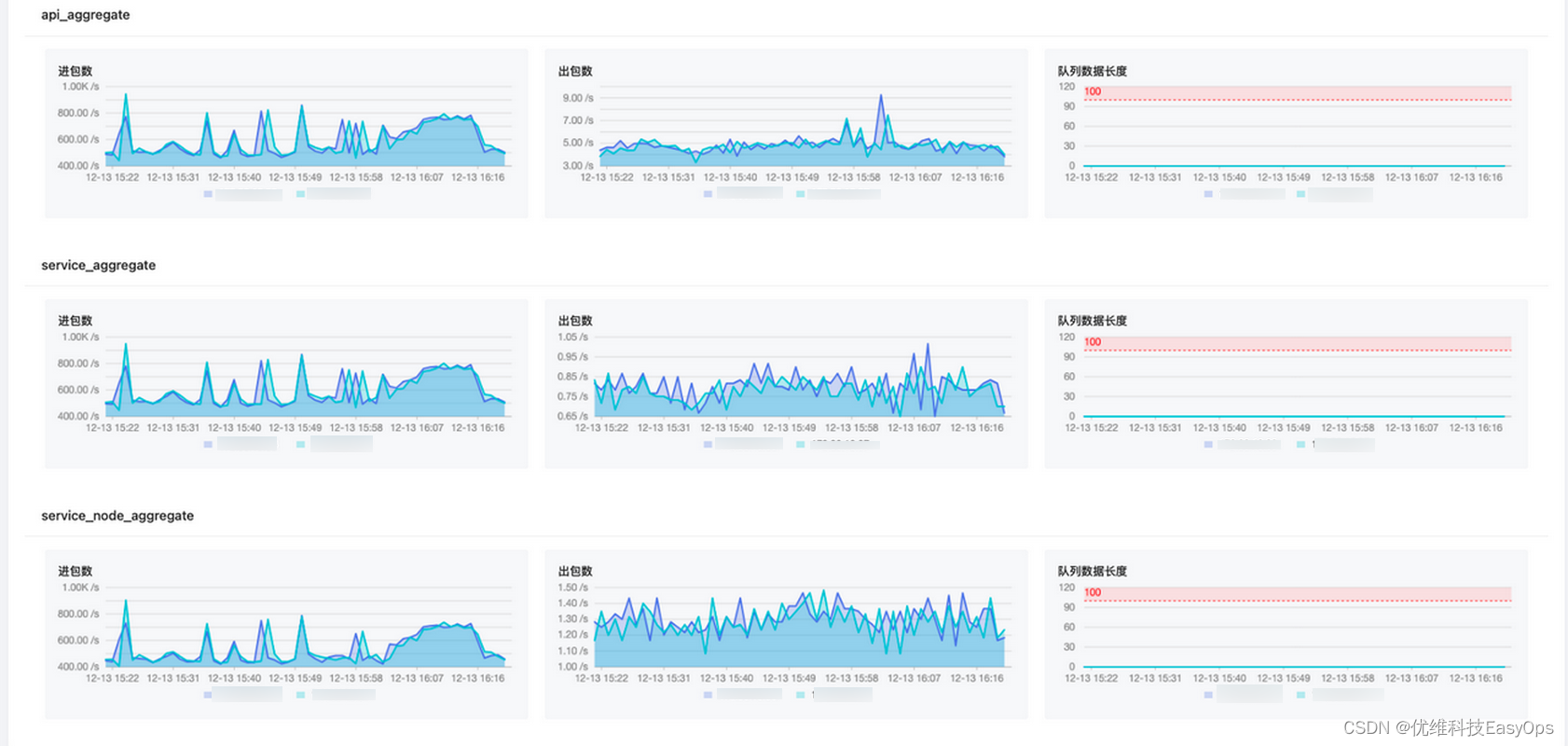
5.资源发现链路
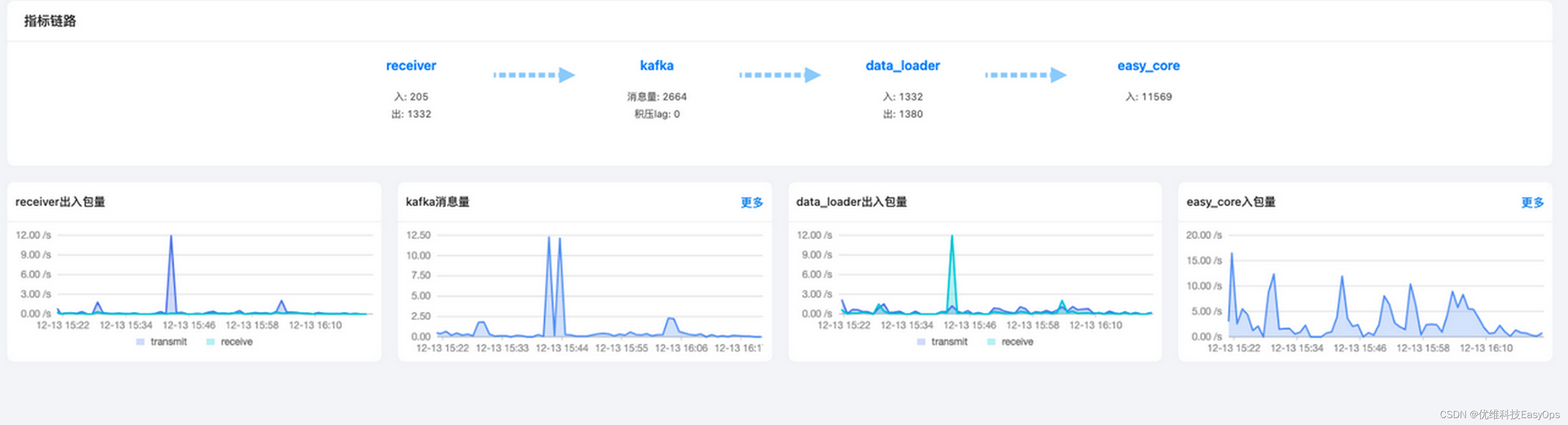
cmdb自动发现的数据上报链路:agent –> receiver –>kafka –> data_loader –>easy_core
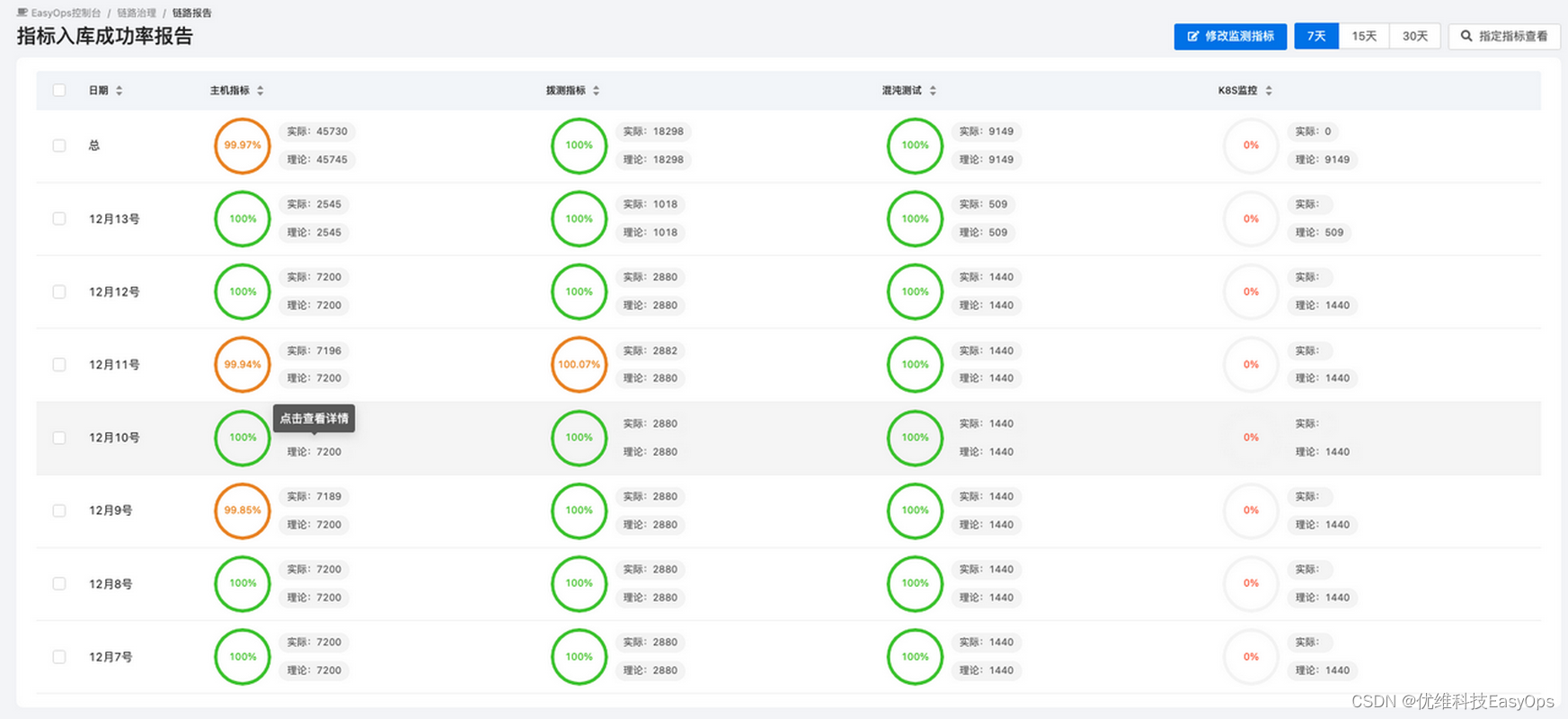
6.指标入库成功率报告
该页面主要展示一段时间内的指标入库情况,如果成功率持续呈比较低的情况,则需要针对该数据链路进行一个详细的排查。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
相关推荐: 文心大模型商业化领跑,百度在自我颠覆中重构生长力
随着科技巨头竞逐AI大模型,人工智能技术成为今年最受瞩目的新技术。但是,AI大模型的创新之路,还缺少一个足够有力的商业化答案。 作为全球最先发布大模型的互联网大厂,百度能否加速大模型的应用落地,以及文心大模型能够创造多少商业价值,一直是市场关注的焦点。 11月…
