
作者|邱鑫鑫,王彬,牟柏旭
公司背景和业务
数禾科技以大数据和技术为驱动,为金融机构提供高效的智能零售金融解决方案,服务银行、信托、消费金融公司、保险、小贷公司等持牌金融机构,业务涵盖消费信贷、小微企业信贷、场景分期等多个领域,提供营销获客、风险防控、运营管理等服务。数禾科技通过自主开发的消费信贷产品,连接金融机构与普罗大众,赋能金融机构数字化转型,迎接中国消费升级的大潮。
数禾当前有三款主要产品,还呗,还享花,小店邦。每款产品都有大量的受众,每天会产生大量的应用日志,数据通过压缩后归档到阿里云 OSS 存储,以达到最优的存储成本。
低效的数据处理
应用日志通过 SLS 收集,压缩并归档到 OSS,整个链路都非常顺滑。但日常有些业务需要查看详细的应用日志,由于日志收集会将 APP 上不同应用的日志都打到一起。因此,获取某个应用的日志,需要从 OSS 解压大量的文件,并从中过滤出特定的应用,才可以进一步分析排查。这个过程在实效性和数据处理效率上都存在很大的问题,为此,数禾运维团队计划从源头重构整个任务处理链路,以求以最低的开发成本,最高的处理效率,最优的资源费用,最好的扩展性打造高可用,易升级,低维护的解决方案。
首先想到的采用容器自建的方案。自建的处理程序从 Kafka 获取数据,并负责数据的处理,K8s 集群保证任务的弹缩,配合自建的发布平台,初步能够满足设计的需求。
该方案的优势在于,对于 K8s 的使用和任务发布平台,数禾运维团队都有了不少的积累,整体实施起来难度会比较小。但对比设想的链路目标,却还有些欠缺,主要表现在:
- 任务开发成本较高:从 Kafka 获取数据,数据的业务处理、异步压缩上传,任务的发布更新系统对接,K8s 的弹缩策略,都需要研发人员全新开发。
- 链路弹性有限:一是 K8s 通过指标弹出资源速度需要10+s,对于突发的日志流量,可能会出现资源弹出不及时的情况;二是 Kafka Topic 数据处理的并发度受限于 Topic Partition,当消费程序达到 Partition 数目时,消费程序没法继续水平扩大并发度。
- 资源利用率不够极致:在业务低峰期,特别是夜间,存在流量很小甚至是无流量的时段,但处理程序还是得最小保持1个实例的运行,造成了一定的资源浪费。
- 升级维护工作依然很多:业务处理逻辑的修改,发布平台的更新对接,K8s 平台的弹缩规则等,都需要持续的维护。
就在数禾运维团队陷入选型沉思的时候,阿里云函数计算(后面简称FC)团队的交流让数禾运维团队眼前一亮,阿里云函数计算在 Kafka->FC 的链路已经打磨多时,对于数禾的业务需求,正可以使用到函数计算很多的已有功能,数禾的研发团队只需要专注在自身的业务处理逻辑,就能快速的搭建一套高可用,易升级,低维护的任务处理链路。
函数计算的出现恰逢其时
函数计算是事件驱动的全托管计算服务。使用函数计算,客户无需采购与管理服务器等基础设施,只需编写并上传代码或镜像。函数计算会准备好计算资源,弹性地、可靠地运行任务,并提供日志查询、性能监控和报警等功能。
通过函数计算自带的 Kafka 触发器和定时触发器,数禾运维团队架构出了一套理想的解决方案。架构图如下:
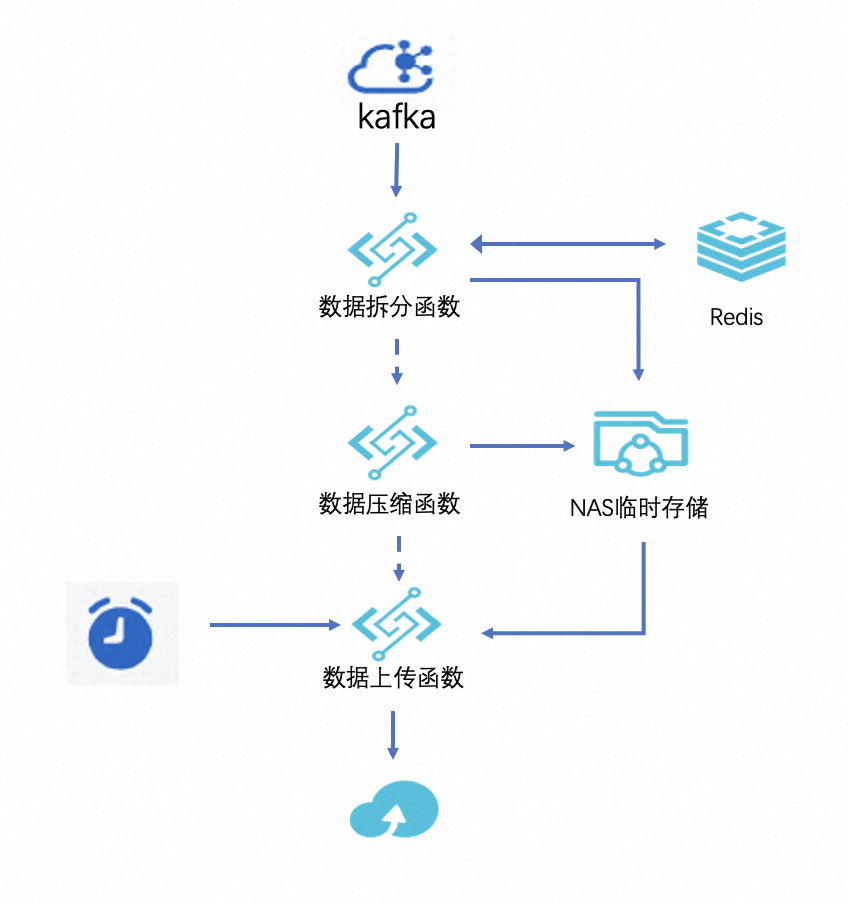
函数的处理逻辑如下:
- 数据拆分函数:通过 Kafka 触发器触发,触发器会将 Kafka 数据攒批,以batch的形式发送到函数计算,函数计算处理逻辑负责将数据块通过标识字段拆分,同一个应用的数据汇聚到一起,在 NAS 目录形成独立的文件。属于 io 密集型操作。
- 数据压缩函数:在一批数据到达函数计算拆分汇聚之后,先对数据进行压缩,然后将压缩后的数据追加到 NAS 目录对应的文件,在写 NAS 前,借助 Redis 处理并发锁的问题,大大减少了小文件的数量,属于算力密集型操作。
- 数据上传函数:通过定时触发器触发,将第二步压缩完成的数据上传到 OSS 对应目录,然后清理本地目录。属于 io 密集型操作。
通过将处理逻辑拆分,将对资源要求不同的操作拆分到不同函数,实现了每个函数资源利用率的最大化,降低了总体实现的费用成本。
相比通过 ECS/K8s 自建的方案,优势还是十分明显的:
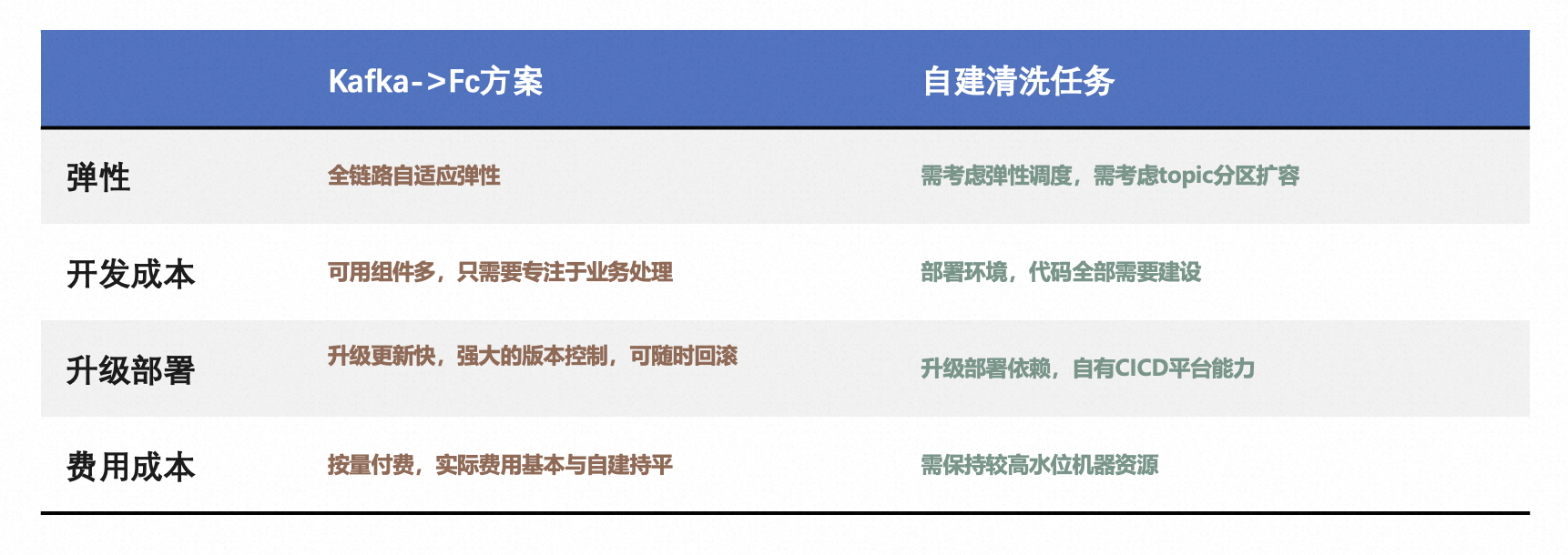
从对比可以看出,采用函数计算的方式,在开发效率,弹性,升级部署,费用成本方面,相对 ECS/K8s 自建方案,都有明显的优势。
落地中的问题
Serverless 理念跟整个任务的架构十分的契合,但在落地中还是可以看到有些处理不够优雅的地方,总结起来主要有两处:
- 函数计算同步调用的攒批大小是16M,异步调用的攒批大小是128K,为了降低调用函数的计算频率,达到更好的攒批效果,从而在成本和性能上都达到好的效果,使得触发器配置时只能配置同步调用,同步调用时,函数计算侧的并行度取决于调用方,这就要求触发器任务配置多任务分片,造成了一定的资源浪费。
- 在第一个函数中,主要处理逻辑是根据 Kafka 消息的应用id信息,拆分数据,将同一个id应用的数据聚合在一起,由于本身 NAS 和 OSS 都没有提供文件锁,所以当多个函数并发写同一个id应用文件时,如果程序层面不处理文件锁的问题,会导致写数据相互覆盖。对于每个函数实例拆分小文件的方案,由于 Kafka 消息中应用的种类很多,拆分数据总是会形成很多小文件,数据合并需要很长的时间。经过多种方案的检验比较,最终选择了通过 Redis 处理文件锁,每个应用全局最多产生10个并发写文件,函数计算运行实例写 NAS 文件时,先去 Redis 获取文件锁,获取成服务器托管网功才能真正开始写入。这种方案在写数据性能上有很好的表现,代码复杂度得到了一定的增加,但总体可控。
最终,这些问题没有成为数禾方案的卡点,通过交流和方案验证,最终都得到了一定程度的解决。
出色的效果和进一步的期待
在全链路角度看,整条链路非常的 Serverless,资源使用效率也非常高,再配合函数计算2023云栖大会推出的梯度计价,整个方案在资源成本上也达到了非常好的控制。
在期望方面,针对本次场景落地中遇到的问题,还是希望可以得到更好的优化。异步调用放宽消息体大小,可以以最少的触发器资源,达到函数计算的大并发处理。通过 NAS/OSS 原生支持文件锁的能力,可以减少文件的数量,同时也减少业务层代码在这方面的处理复杂度。
任务从1服务器托管网0月份上线以来,数禾运维团队在该任务的运维投入上得到了人力释放,几乎达到了0运维;在功能迭代上,通过函数计算控制台提供的多版本和灰度能力,快速的完成了升级的灰度。
后续数禾运维团队会将更多适合 Serverless 的业务采用函数计算方案,最大限度将精力专注在公司业务,逐渐剥离运维和底层资源的简单维护。数禾运维团队也十分开放的与函数计算团队探讨更多的场景,希望将公司的业务架构在新一代的 Serverless 架构上。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
Spring Boot + Vue中的Token续签机制 在这个示例中,我们将使用Spring Boot作为后端框架,Vue作为前端框架,演示如何在全栈应用中实现长短Token的续签。 1. Spring Boot后端 1.1 长Token的生成 在Sprin…
