
十一期间在家用期间研读了下Halcon的variation_model模型,基本上全系复现了他的所有技术要求和细节,这里做个记录。
其实这个模型的所有原理都不是很复杂的,而且Halcon中的帮助文档也讲的很是清楚,所以通过猜测、测试、编码基本能搞清楚是怎么回事。
关于这个模型,Halcon里有如下十来个函数:
create_variation_model、prepare_variation_model, train_variation_model、compare_variation_model、prepare_direct_variation_model、clear_variation_model, clear_train_data_variation_model, compare_ext_variation_model, ge服务器托管网t_thresh_images_variation_model, get_variation_model、 clear_train_data_variation_model, write_variation_model 。
看起来涉及到了蛮多的东西的。
那么一般的工作流程是:create_variation_model —> train_variation_model —> prepare_variation_model —> compare_variation_model —>clear_variation_mode。
即: 创建模型,然后训练模型,接着就是准备模型,这个时候就可以使用了,那么可以开始做输入比较了,比较完事了,清楚模型。
所谓的variation_model的模型呢,其实是从一系列已经确认是OK的样图中,训练出2幅结果图,即上限图和下限图,也可以认为是训练出图像公差带,当要进行比较的时候,就看输入的图像的每个像素是否位于这个公差带之类,如果是,则这个点是合格的,不是,则这个像素点就是不合格的区域。
那么在Halcon中,把这个工作就分解为了上面这一大堆函数。我们稍微来对每个函数做个解析。
一、create_variation_model 创建模型。
这个算子有如下几个参数:
create_variation_model( : : Width, Height, Type, Mode : ModelID)
这里主要是注意Type和Mode两个参数。
其中Type可以取’byte’, ‘int2’, ‘uint2’ 这三种类型,我这里的解读是这个算子支持我们常用的8位灰度图像 和 16位的Raw图像, 16位因为有signed short和unsigned short,所有这里也有int2 和uint2两种类型。
Mode参数有3个选择,: ‘standard’, ‘robust’, ‘direct’,这也是这个算子的灵魂所在,具体的做法后续再说,在创建时只是保存了他们的值,并没有做什么。
那么创建的工作要做的一个事情就是分配内存,Halcon里的帮助文章是这样描述的:
A variation model created with create_variation_model requires 12*Width*Height bytes of memory for Mode = ‘standard’ and Mode = ‘robust’ for Type = ‘byte’. For Type = ‘uint2’ and Type = ‘int2’, 14*Width*Height are required. For Mode = ‘direct’ and after the training data has been cleared with clear_train_data_variation_model, 2*Width*Height bytes are required for Type = ‘byte’ and 4*Width*Height for the other image types.
为什么是这样的内存,我们后续再说,接着看下一个函数。
二、train_variation_model 训练模型
这个算子是这个功能的最有特色的地方,他用于计算出variation_model 模型中的ideal image和variation image,即理想图像和方差图像。
当Mode选择’standard’, ‘robust’时,此算子有效,当Mode为’direct’无效。
Mode为’standard’时,训练采用求多幅平均值的方式获取理想图像以及对应的方差图像,Mode为’robust’时,采用,求多幅图像的中间值的方式获取理想图像以及对应的方差图像。
注意,这里的服务器托管网求均值和方差是针对同一坐标位置,不同图像而言的,而不是针对单一图像领域而言,这个概念一定不能能错了,比如训练5副图像,他们某一行的对应位置数据分别为:
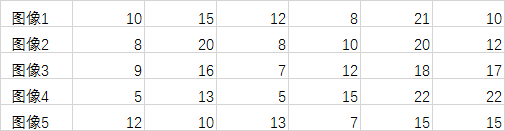
当选择模式为’standard’,训练结果的ideal image 值应该是(实际还需要四舍五入求整):

当选择模式为’robust’,训练结果的ideal image 值应该是:

当选择’standard’模式,我们可以在找到一副OK图像的时候,单独把这幅图像的数据训练到variation_model模型,而如果使用’robust’方式,则必须一次性把所有的OK图像添加到训练模型中,无法动态的添加对象,但是,由于’robust’模式采用的是中值的方式,因此,其抗噪音效果要好很多。
为什么’standard’模式可以随时添加,而’robust’只能一次性添加,其实这个也很简单,前一次求平均值的信息如果临时保存了,那么在新的OK图需要添加时,可以直接利用前一次的有关信息进行沟通,而如果是采用求中值的方式,前面的排序信息一是难以保存(数据量大),二是即使保存了,对本次排序的作用也不大。
这个时候我们停来下分析下前面Halcon文档里的提出的variation_model模型的内存占用大小,假如我们的Type是byte类型,使用’standard’模式,那么Ideal Image占用一份Width*Height字节内存,variation image必须是浮点类型的,占用 4 *Width*Height字节内存,另外,我们能随时添加新的OK的图像,应该还需要一个临时的int 类型的数据保存累加值(虽然Ideal Image保存了平均值,但是他是已经进行了取舍了, 精度不够),这需要额外的4 *Width*Height字节内存,后面我们提到variation_model还需要有2个width * height自己大小的内存用来保存上限和下限的图像数据,因此这里就有大概 1 + 4 + 4 + 2 = 11 * width * height的内存了,还差一个,呵呵,不知道干啥的了。
选择’robust’模式时,ideal image好说,就是取中间值,但是对于variation image,并不是普通的方差图像,在halcon中时这样描述的:The corresponding variation image is computed as a suitably scaled median absolute deviation of the training images and the median image at the respective image positions,实际上,他这里是计算的绝对中位差,即计算下面这个数的中间值了。
MAD=median(∣X−median(X)∣)
这个还需要举例说明吗????
对于使用‘standard’模式的计算优化,也是有很多技巧的,不过这个应该很多人能掌握吧。但是如果是’robust’模式,直接写求中值的方法大家应该都会,但是因为这是个小规模大批量的排序和求中值的过程,其实是非常耗时的,比如W = 1000, H=1000,如果训练20副图像,那么就是1000*1000 = 100万个20个数字的排序,而且还涉及到到一个非常严重的cache miss问题。 即这20个数字的读取每次都是跨越很大的内存地址差异的。
如何提高这个排序的过程,我觉得在这里指令集是有最大的优势的,他有两个好处,一是一次性处理多个字节,比如SSE处理16个字节,这样我也就可以一次性加载16个字节,整体而言就少了很多次cache miss,第二,如果我需要利用指令集,则我需要尽量的避免条件判断,因此,很多稍微显得高级一点的排序都不太合适,我需要找到那种固定循环次数的最为有效,比如冒泡排序,他就是固定的循环次数。
对于N个图像的逐像素排序求中值,一个简单的C代码如下所示:
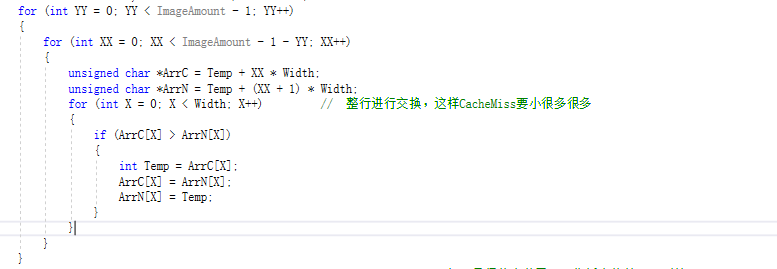
纯C代码的话,这个的效率绝对不是最高的,有很多优秀的排序算法都可以比这个快很多。但是他是最简单,也是最简洁的,最适合进行SIMD优化的。 看到中间的X循环了吗,那就是他主要的计算量所在,这个循环用指令集优化是不是很简单。
有人说这个循环就是个典型的判断分支语句啊,你刚刚说要避免分支,这明显不就是个矛盾吗,那么我如果把这个循环这样写呢:

他们结果是不是一样,还有分支吗,好了,到这一步,后面的SIMD指令应该不需要我说怎么写了吧,_mm_min_epu8 +_mm_max_epu8。
至于median absolute deviation的中值的计算,除了需要计算MAD值之外,其他有任何区别吗? MAD不恰好也可以用byte类型来记录吗,应该懂了吧。
三、prepare_variation_model 准备模型
这个算子的有如下几个参数:
prepare_variation_model( : : ModelID, AbsThreshold, VarThreshold : )
这个算子实际上是根据前面的训练结果结合输入的AbsThreshold和VarThreshold参数确定最终的上限和下限图像,即确认公差带。
Halcon内部的计算公式为:
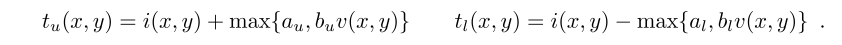
i(x,y)是前面得到的Ideal Image, v(x,y)为variation image, au/al/bu/bl即为算子的输入参数。这个没有啥好说的,具体可以看Halcon的帮助文档。
四、compare_variation_model 比较模型
算子原型为: compare_variation_model(Image : Region : ModelID : )
经过前面的一些列操作,我们的准备工作就完成了,现在可以用来进行检测了,检测的依据如下式:
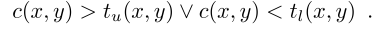
即在公差带内的图像为合格部分,否则为不合格部分。
五、其他算子
clear_variation_model – 删除模型数据,这个没啥好说的
prepare_direct_variation_model – 直接准备模型数据,这个在Mode设置为direct时有效,他无需经过训练,直接设置上下限数据,一般不使用
clear_train_data_variation_model – 清除训练数据,当我们训练完成后,那个Ideal Image 、variation image、临时数据等等都是没有用的了,都可以释放掉,只需要保留上下限的数据了。
还有几个算子没有必要说了吧。
总的来说,这是个比较简单的算子,实际应用中可能还需要结合模版匹配等等定位操作,然后在映射图像等,当然也有特殊场合可以直接使用的。
我这里做了一个DEMO,有兴趣的朋友可以试用一下:https://files.cnblogs.com/files/Imageshop/Variation_Model.rar?t=1697790804&download=true
翻译
搜索
复制
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
访问【WRITE-BUG数字空间】_[内附完整源码和文档] 基于欧式距离的聚类算法,其认为两个目标的距离越近,相似度越大。 该实验产生的点为二维空间中的点。 环境配置java环境,使用原生的Java UI组件JPanel和JFrame 算法原理基于欧式距离的聚…
