
xxljob在集群模式下调度高频任务时,有时会出现调度失败的问题,具体报错如下:
java.io.EOFException: HttpConnectionOverHTTP@6be8bf0c(l:/10.48.2.64:38538 r:/10.48.1.125:18989,closed=false)[HttpChannelOverHTTP@296ee40c(exchange=HttpExchange@4d219770 req=TERMINATED/null@null res=PENDING/null@null)[send=HttpSenderOverHTTP@3c6b8ccf(req=QUEUED,snd=COMPLETED,failure=null)[HttpGenerator{s=START}],recv=HttpReceiverOverHTTP@12554491(rsp=IDLE,failure=null)[HttpParser{s=CLOSED,0 of -1}]]] at org.eclipse.jetty.client.http.HttpReceiverOverHTTP.earlyEOF(HttpReceiverOverHTTP.java:277) at org.eclipse.jetty.http.HttpParser.parseNext(HttpParser.java:1305) at org.eclipse.jetty.client.http.HttpReceiverOverHTTP.shutdown(HttpReceiverOverHTTP.java:182) at org.eclipse.jetty.client.http.HttpReceiverOverHTTP.process(HttpReceiverOverHTTP.java:129) at org.eclipse.jetty.client.http.HttpReceiverOverHTTP.receive(HttpReceiverOverHTTP.java:69) at org.eclipse.jetty.client.http.HttpChannelOverHTTP.receive(HttpChannelOverHTTP.java:90) at org.eclipse.jetty.服务器托管网client.http.HttpConnectionOverHTTP.onFillable(HttpConnectionOverHTTP.java:174) at org.eclipse.jetty.io.AbstractConnection$2.run(AbstractConnection.java:544) at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:635) at org.eclipse.jetty.util.thread.QueuedThreadPool$3.run(QueuedThreadPool.java:555) at java.lang.Thread.run(Thread.java:748)
网上关于这个问题的原因和解决比较少,因此记录下来问题的排查过程,供大家参考,如果有心急的同学可以直接跳到结尾查看问题原因和解决方案
后续说明中的触发侧是指xxljob的服务端,执行侧是指任务执行的应用端
排查过程中需要对xxljob的执行原理有大概服务器托管网的了解,以及tcp的握手和挥手操作有一定的了解,最后还需要知道一些tcpdump命令结果的一些知识,如果有不明白的可以先查一下相关资料
首先,我看到这个问题之后先去网上搜一下有没有问题的原因说明和解决方案,但是查询之后发现虽然很多人都遇到了,但是没有说明具体的问题原因
所以,只好查看一下xxl的源码,发现触发操作是完全隔离的,集群下不同机器没有任何相互影响。而且非集群模式下没有这个问题,说明可以排除网络因素。
同时,我也将xxljob中发起触发请求的代码复制出来,然后进行高频率调用,但是没有复现出问题,说明问题的出现可能跟高频执行没有太大关系
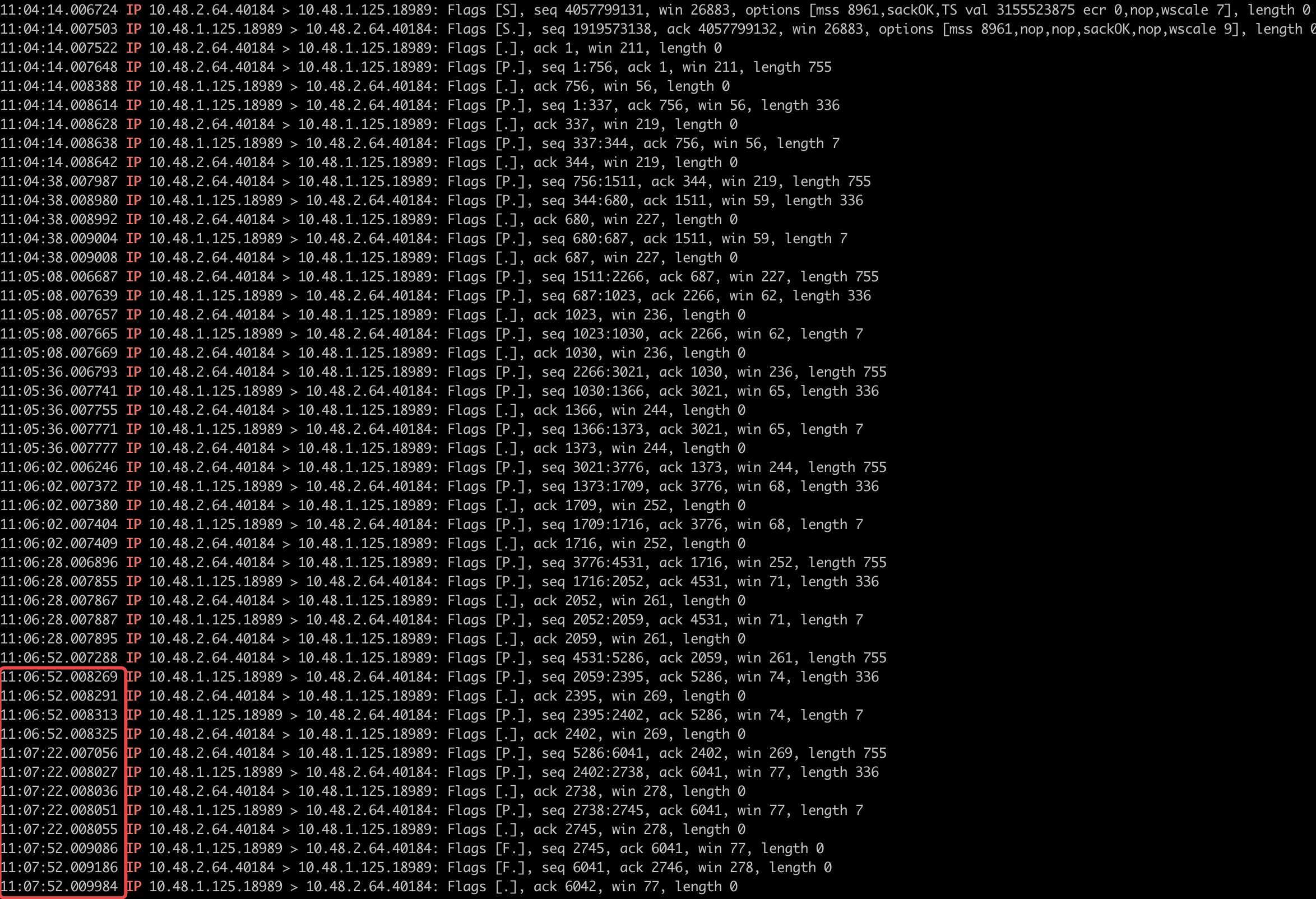
肯定是不同机器调度过程中导致的,仔细观察下图中的调度记录,可以看到出问题的时间点总是在切换调度机器的第一次请求时发生。但是调度机器触发操作是完全独立的,所以到这里就不明白为什么会出现这种情况
于是,为了进一步排查问题,只能去尝试抓一下网络请求,看网络请求有什么不同

下面这个图是通过tcpdump命令抓取的任务触发机器和任务执行机器的网络通信过程
看到这个我才发现,虽然xxljob是使用http进行通信的,但是并不是走的短连接,而是长连接。
所以第一时间我认为是可能不同机器都已经建立了长连接但是由于调度触发一直在其中一台机器上,所以另一台的连接可能已经断开了,当触发切换到另一台机器时,由于连接已经断开,但是应用层尚未感知到,所以造成的问题
另外,从这个网络交互日志中可以看到复用长连接的有效时间是30s(这个其实是后面发现问题的关键)
根据上面分析的结果,思考问题的其他表现时,发现上面的推断并不能解释所有的现象,比如下图的表现
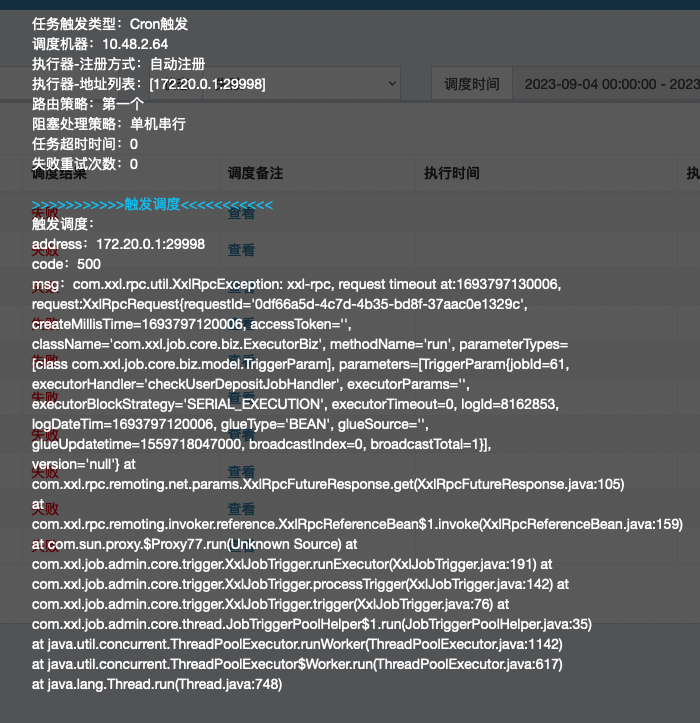
如果长连接已经中断,那么触发侧的请求无法发送到执行侧,执行侧的信息也无法反馈到触发侧才对。但是上面这个图中可以明显看到触发侧已经获取到了执行侧的报错信息,说明,执行侧报错之后已经通过原有连接将报错信息返回到了触发侧
这说明问题发生时,连接并没有中断,上面的分析是错误的。
之后又抓取到了问题发生时的网络交互日志,其中10.48.2.64.38538是xxljob服务端,也就是触发侧,10.48.1.125.18989是任务执行应用,也就是执行侧
16:26:46.008470 IP 10.48.2.64.38538 > 10.48.1.125.18989: Flags [P.], seq 756:1511, ack 344, win 219, length 755 16:26:46.009007 IP 10.48.1.125.18989 > 10.48.2.64.38538: Flags [F.], seq 344, ack 756, win 56, length 0 16:26:46.009192 IP 10.48.2.64.38538 > 10.48.1.125.18989: Flags [F.], seq 1511, ack 345, win 219, length 0 16:26:46.009916 IP 10.48.1.125.18989 > 10.48.2.64.38538: Flags [.], ack 1512, win 59, length 0
从上面这个日志中可以看到
第一条是触发侧去发送了一次请求到执行侧,发送的包的seq是756到1511
第二条是执行侧反馈的返回结果,执行侧直接发送了关闭连接的请求,并且ack只确认到756
第三条是触发侧确认了关闭请求,第四条执行侧确认了第三条的请求
所以2,3,4条是完整的走完了tcp的三次挥手操作,说明连接是执行侧主动关闭的
然后我们重新观察了一下正常的关闭连接的请求,发现每次都是由执行侧去关闭的连接,并且关闭的时间就是最后一次的请求的30s之后(空闲超时)
同时我们也从源码中可以看到超时时间默认就是30s
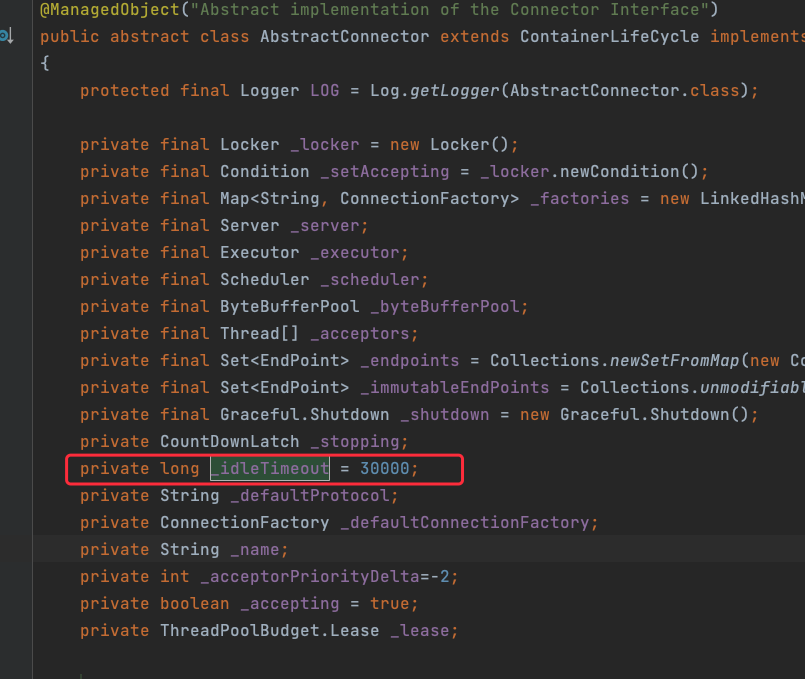
看到这里一切就都可以解释通了,由于执行侧30s超时时会断开连接,此时如果正好调度触发是从这台机器发起的,那么这次触发请求正好遇到执行侧关闭连接,执行侧发起关闭请求后,不会再接收来自触发侧的消息
所以应用由于无法读取请求的数据,所以报了eof错误
看明白报错的过程之后,我们来验证一下我们的猜想,看是否符合我们的预期
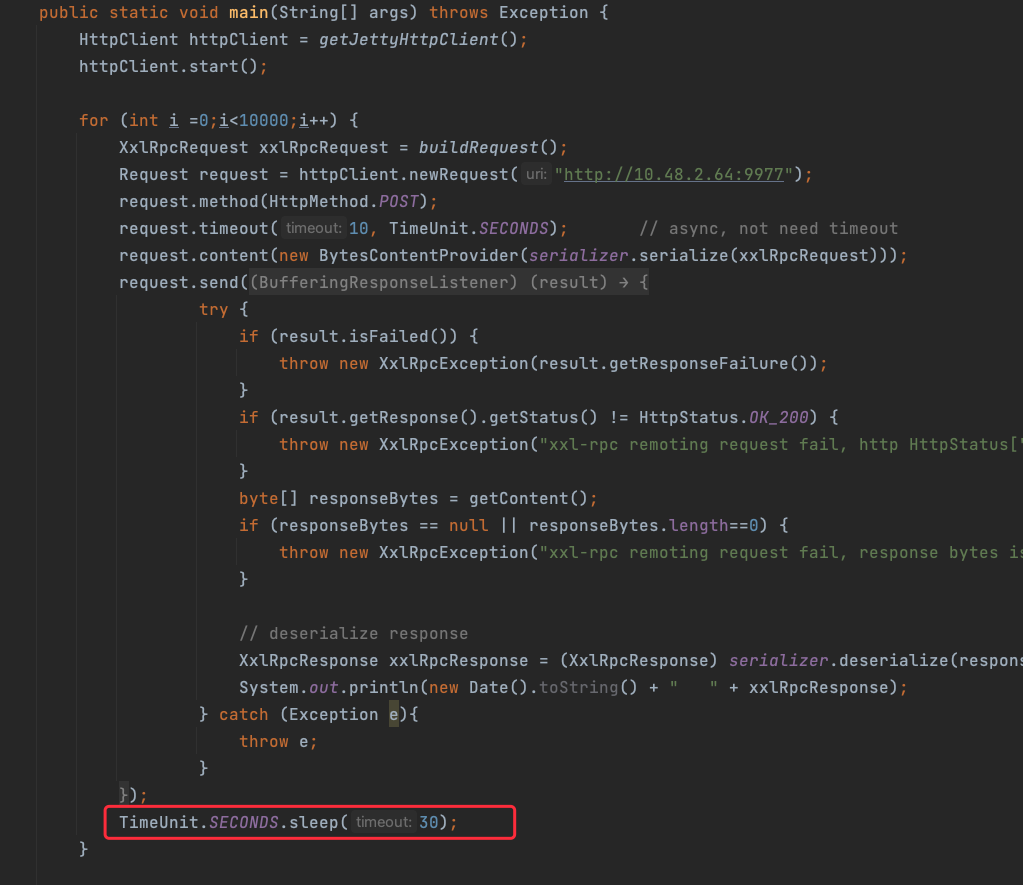
既然是30s超时会断开连接,那么如果我们的触发间隔设置为30s,那么就应该很容易碰到这种情况
因此,我将xxljob中发起触发请求的代码复制出来,然后将两次请求的间隔设置为30s,如下图:
通过下面的代码,可以很轻松的将问题复现出来,说明上面的分析是没有问题的
明白了问题所在,那么修复就比较简单了,我是采用修改空闲超时时间为10分钟,这样尽量避免调度切换和超时断开正好碰到一起
这种解决方式理论上仍然有报错的可能,但是概率大大降低了,同时也不需要修改xxljob源码,改动也比较小
如果有更好的解决方式欢迎评论区说明
测试类和修复类我都已经上传到csdn了,由于我比较贫穷,需要一些csdn的积分下载别的资源,所以希望各位支持一些积分给我
下载链接:https://download.csdn.net/download/wsss_fan/88299099
如果确实没有积分,可以联系我,我单独发给你
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: 2023-06-07:Redis 持久化方式有哪些?以及有什么区别?
2023-06-07:Redis 持久化方式有哪些?以及有什么区别? 答案2023-06-07: Redis提供了两种持久化机制:RDB和AOF。 RDB RDB持久化是将Redis当前进程中的数据生成快照并保存到硬盘的过程。快照指的是Redis在某一时刻的内…
