
导言
冒泡排序是最基本、最简单的排序算法之一,它通过多次遍历待排序的数组或列表,依次比较相邻的元素并交换位置,使得较大(或较小)的元素逐渐“浮”到数组的一端。
原理分析
冒泡排序算法通过多次遍历待排序的数组或列表,依次比较相邻的元素并交换位置,使得较大(或较小)的元素逐渐“浮”到数组的一端。具体来说,算法会从数组的第一个元素开始,比较它和它后面的元素,如果发现顺序有误则交换它们的位置。通过这样的操作,每次遍历都能将当前最大(或最小)的元素放到合适的位置上。
实现步骤
a. 首先,我们需要两层循环。外层循环控制遍历的次数,内层循环用于比较和交换相邻的元素。
b. 外层循环执行的次数是待排序数组的长度减去1,因为每一轮遍历都会把当前最大(或最小)的元素放到了正确的位置上,所以最后一个元素不需要再进行排序。
c. 内层循环在每一轮遍历中从数组的第一个元素开始,通过比较相邻的两个元素来判断是否需要进行交换操作。如果前一个元素大于后一个元素,则它们的位置需要互换。
d. 通过这样的遍历,每一轮都可以将当前最大(或最小)的元素放到合适的位置上。经过多轮的遍历,整个数组逐渐完成了排序。
注意,看完了这里的操作步骤,我们可以想一下,如果从头到尾进行操作是否可以?当然不可以,不过这样可以完成从小到大的排序。
假如我们要把 12、35、99、18、76 这 5 个数从大到小进行排序,那么数越大,越需要把它放在前面。冒泡排序的思想就是在每次遍历一遍未排序的数列之后,将一个数据元素浮上去(也就是排好了一个数据)。
我们从后开始遍历,首先比较 18 和 76,发现 76 比 18 大,就把两个数交换顺序,得到 12、35、99、76、18;接着比较 76 和 99,发现 76 比 99 小,所以不用交换顺序;接着比较 99 和 35,发现 99 比 35 大,交换顺序;接着比较 99 和 12,发现 99 比 12 大,交换顺序。最终第 1 趟排序的结果变成了 99、12、35、76、18,排序的过程如图1 所示。
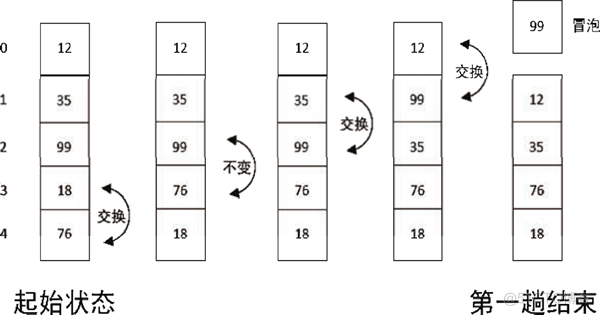
图 1 第 1 趟冒泡排序的过程示例
经过第 1 趟排序,我们已经找到了最大的元素,接下来的第 2 趟排序就只对剩下的 4 个元素排序。第 2 趟排序的过程示例如图 2 所示。
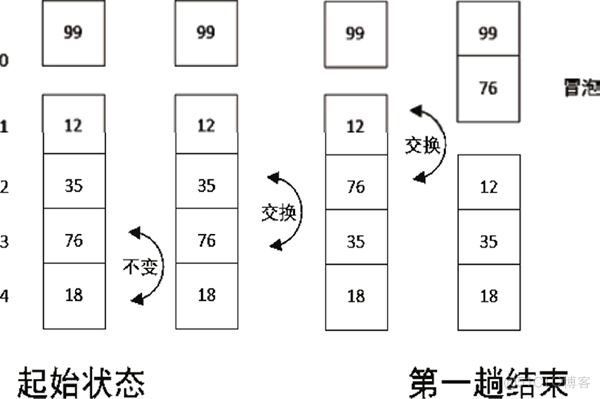
图 2 第 2 趟冒泡排序的过程示例
经过第 2 趟排序,结果为 99、76、12、35、18。接下来应该进行第 3 趟排序了,剩下的元素不多,比较次数也在减少。
第3趟排序的结果应该是 99、76、35、12、18,接下来第 4 趟排序的结果是 99、76、35、18、12,经过 4 趟排序之后,只剩一个 12 需要排序了,这时已经没有可比较的元素了,所以排序完成。
这个算法让我想起了小服务器托管网时候在操场排队跑步,老师总是说:“高的站前面,低的站后面”。我们一开始并不一定会站到准确的位置上,接着老师又说:“你比前面的高,和前面的换换,还高,再和前面换换”,就这样找到了自己的位置。
实现代码
下面是使用 C 语言实现的冒泡排序算法代码示例:
#include
void bubbleSort(int arr[], int n) {
for (int i = 0; i arr[j + 1]) {
// 交换相邻元素的位置
int temp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = temp;
}
}
}
}
int main() {
int arr[] = {64, 34, 25, 12, 22, 11, 90};
int n = sizeof(arr) / sizeof(arr[0]);
bubbleSort(arr, n);
printf("排序后的数组:n");
for (int i = 0; i 在上述代码中,bubbleSort 函数用于实现冒泡排序算法,main 函数展示了如何使用该函数对数组进行排序。最后,通过迭代输出数组中的元素,展示排序结果。
特点及性能
通过冒泡排序的算法思想,我们发现冒泡排序算法在每轮排序中会使一个元素排到一端,也就是最终需要 n-1 轮这样的排序(n 为待排序的数列的长度),而在每轮排序中都需要对相邻的两个元素进行比较,在最坏的情况下,每次比较之后都需要交换位置,所以这里的时间复杂度是O(n2)。其实冒泡排序在最好的情况下,时间复杂度可以达到O(n),这当然是在待排序的数列有序的情况下。在待排序的数列本身就是我们想要的排序结果时,时间复杂度的确是O(n),因为只需要一轮排序并且不用交换。但是实际上这种情况很少,所以冒泡排序的平均时间复杂度是O(n2)。
对于空间复杂度来说,冒泡排序用到的额外的存储空间只有一个,那就是用于交换位置的临时变量,其他所有操作都是在原有待排序列上处理的,所以空间复杂度为O(1)。
冒泡排序是稳定的,因为在比较过程中,只有后一个元素比前面的元素大时才会对它们交换位置并向上冒出,对于同样大小的元素,是不需要交换位置的,所以对于同样大小的元素来说,相对位置是不会改变的。
冒泡排序算法的时间复杂度其实比较高。从 1956 年开始就有人研究冒泡排序算法,后续也有很多人对这个算法进行改进,但结果都很一般,正如 1974 年的图灵奖获得者所说的:“冒泡排序除了它迷人的名字和引起的某些有趣的理论问题,似乎没有什么值得推荐的。”
优化策略
尽管冒泡排序算法简单易懂,但它的时间复杂度较高,为O(n^2),在大规模数据集上排序效率低下。因此,有几个优化策略可以提高冒泡排序的性能:
- 设置标志位:如果在一轮遍历中没有进行任何元素交换,说明数组已经完全有序,可以提前结束排序过程。
- 减少比较次数:每一轮遍历都将最大(或最小)的元素“浮”到了末尾。因此,下一轮遍历时无需再比较已经排好序的部分。
- 针对特定数据集进行优化:例如,对于大部分已经有序或基本有序的数据集,冒泡排序算法的效率较高。可以通过判断数据集的有序程度,选择是否采用冒泡排序。
结论
冒泡排序是最简单的排序算法之一,它通过多次遍历、相邻元素的比较和交换来实现排序。然而,其时间复杂度较高,在大规模数据集上的性能不佳。为了提高冒泡排序算法的效率,可以采用一些优化策略,如设置标志位、减少比较次数和针对特定数据集进行优化。这些优化方法可以显著提高冒泡排序算法的性能。
引用参考地址:https://www.runoob.com/ http://data.biancheng.net/
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
相关推荐: Java 程序示例:实现了一个简单的社交媒体平台:
Java 程序示例:实现了一个简单的社交媒体平台: import java.util.ArrayList; import java.util.HashMap; import java.util.List; import java.util.Map; class…
