
1.简介
最近我司上线使用了分布式任务调度框架:XXL-JOB,方便对任务的管理控制。本来一开始就想讲述一下该框架,但是在学习了解过程中发现该框架式基于Quartz思想开发实现的,Quartz 是一个很火的开源任务调度框架,完全由Java写成,可以说是 Java 定时任务领域的老大哥或者说参考标准,所以在这里先讲讲Quartz框架。
1.1.Quartz是什么
Quartz是OpenSymphony开源组织在Job scheduling领域又一个开源项目,是完全由java开发的一个开源的任务日程管理系统,“任务进度管理器”就是一个在预先确定(被纳入日程)的时间到达时,负责执行(或者通知)其他软件组件的系统。其功能类似于java.util.Timer。但是相较于Timer, Quartz增加了很多功能,作为一个优秀的开源调度框架,Quartz具有以下特点:
- 强大的调度功能,例如支持丰富多样的调度方法,可以满足各种常规及特殊需求
- 灵活的应用方式,支持调度数据的多种存储方式
- 分布式和集群能力
1.2.存储方式
RAMJobStore和JDBCJobStore 两者对比如下:
| 类型 | 优点 | 缺点 |
|---|---|---|
| RAMJobStore | 不要外部数据库,配置容易,运行速度快 | 因为调度程序信息是存储在被分配给JVM的内存里面,所以,当应用程序停止运行时,所有调度信息将被丢失。另外因为存储到JVM内存里面,所以可以存储多少个Job和Trigger将会受到限制 |
| JDBCJobStore | 支持集群,因为所有的任务信息都会保存到数据库中,可以控制事物,还有就是如果应用服务器关闭或者重启,任务信息都不会丢失,并且可以恢复因服务器关闭或者重启而导致执行失败的任务 | 运行速度的快慢取决与连接数据库的快慢 |
根据上面知道,要想支持分布式集群,必须属于JDBCJobStore,其需要借助数据库MySQL,数据库初始化表SQL下载:tables,表描述说明如下:
| 表名 | 说明 |
|---|---|
| qrtz_blob_triggers | Trigger作为Blob类型存储(用于Quartz用户用JDBC创建他们自己定制的Trigger类型,JobStore 并不知道如何存储实例的时候) |
| qrtz_calendars | 以Blob类型存储Quartz的Calendar日历信息, quartz可配置一个日历来指定一个时间范围 |
| qrtz_cron_triggers | 存储Cron Trigger,包括Cron表达式和时区信息 |
| qrtz_fired_triggers | 存储与已触发的Trigger相关的状态信息,以及相联Job的执行信息 |
| qrtz_job_details | 存储每一个已配置的Job的详细信息 |
| qrtz_locks | 存储程序的非观锁的信息(假如使用了悲观锁) |
| qrtz_paused_trigger_graps | 存储已暂停的Trigger组的信息 |
| qrtz_scheduler_state | 存储少量的有关 Scheduler的状态信息,和别的 Scheduler 实例(假如是用于一个集群中) |
| qrtz_simple_triggers | 存储简单的 Trigger,包括重复次数,间隔,以及已触的次数 |
| qrtz_triggers | 存储已配置的 Trigger的信息 |
项目推荐:基于SpringBoot2.x、SpringCloud和SpringCloudAlibaba企业级系统架构底层框架封装,解决业务开发时常见的非功能性需求,防止重复造轮子,方便业务快速开发和企业技术栈框架统一管理。引入组件化的思想实现高内聚低耦合并且高度可配置化,做到可插拔。严格控制包依赖和统一版本管理,做到最少化依赖。注重代码规范和注释,非常适合个人学习和企业使用
Github地址:https://github.com/plasticene/plasticene-boot-starter-parent
Gitee地址:https://gitee.com/plasticene3/plasticene-boot-starter-parent
微信公众号:Shepherd进阶笔记
交流探讨群:Shepherd_126
2.springboot整合示例
springboot整合quartz非常简单,这里我们演示集群模式,所以使用JDBCJobStore,相关所需依赖如下:
org.springframework.boot
spring-boot-starter-quartz
org.springframework.boot
spring-boot-starter-jdbc
mysql
mysql-connector-java
5.1.48
在创建任务之前,我们需要下载上面SQL语句执行一下,这里建表可以和业务数据库在同一个库,也可以单独放到一个数据库,如果单独建库建表,那么业务服务就是多数据源了,需要重新封装数据源连接。如下的多数据源配置:
@Configuration
public class DataSourceConfiguration {
/**
* 创建 user 数据源的配置对象
*/
@Primary
@Bean(name = "userDataSourceProperties")
@ConfigurationProperties(prefix = "spring.datasource.user") // 读取 spring.datasource.user 配置到 DataSourceProperties 对象
public DataSourceProperties userDataSourceProperties() {
return new DataSourceProperties();
}
/**
* 创建 user 数据源
*/
@Primary
@Bean(name = "userDataSource")
@ConfigurationProperties(prefix = "spring.datasource.user.hikari") // 读取 spring.datasource.user 配置到 HikariDataSource 对象
public DataSource userDataSource() {
// 获得 DataSourceProperties 对象
DataSourceProperties properties = this.userDataSourceProperties();
// 创建 HikariDataSource 对象
return createHikariDataSource(properties);
}
/**
* 创建 quartz 数据源的配置对象
*/
@Bean(name = "quartzDataSourceProperties")
@ConfigurationProperties(prefix = "spring.datasource.quartz") // 读取 spring.datasource.quartz 配置到 服务器托管网DataSourceProperties 对象
public DataSourceProperties quartzDataSourceProperties() {
return new DataSourceProperties();
}
/**
* 创建 quartz 数据源
*/
@Bean(name = "quartzDataSource")
@ConfigurationProperties(prefix = "spring.datasource.quartz.hikari")
@QuartzDataSource
public DataSource quartzDataSource() {
// 获得 DataSourceProperties 对象
DataSourceProperties properties = this.quartzDataSourceProperties();
// 创建 HikariDataSource 对象
return createHikariDataSource(properties);
}
private static HikariDataSource createHikariDataSource(DataSourceProperties properties) {
// 创建 HikariDataSource 对象
HikariDataSource dataSource = properties.initializeDataSourceBuilder().type(HikariDataSource.class).build();
// 设置线程池名
if (StringUtils.hasText(properties.getName())) {
dataSource.setPoolName(properties.getName());
}
return dataSource;
}
}
为了快速简单测试,我们把Quartz的建表放到业务库一起,然后如下配置即可:
spring:
datasource:
url: jdbc:mysql://10.10.0.10:3306/ptc_job?useSSL=false&useUnicode=true&characterEncoding=UTF-8
driver-class-name: com.mysql.jdbc.Driver
username: root
password: root
# Quartz 的配置,对应 QuartzProperties 配置类
quartz:
scheduler-name: clusteredScheduler # Scheduler 名字。默认为 schedulerName
job-store-type: jdbc # Job 存储器类型。默认为 memory 表示内存,可选 jdbc 使用数据库。
auto-startup: true # Quartz 是否自动启动
startup-delay: 0 # 延迟 N 秒启动
wait-for-jobs-to-complete-on-shutdown: true # 应用关闭时,是否等待定时任务执行完成。默认为 false ,建议设置为 true
overwrite-existing-jobs: true # 是否覆盖已有 Job 的配置,注意为false时,修改已存在的任务调度cron,周期不生效
jdbc: # 使用 JDBC 的 JobStore 的时候,JDBC 的配置
initialize-schema: never # 是否自动使用 SQL 初始化 Quartz 表结构。这里设置成 never ,我们手动创建表结构。
properties: # 添加 Quartz Scheduler 附加属性,更多可以看 http://www.quartz-scheduler.org/documentation/2.4.0-SNAPSHOT/configuration.html 文档
org:
quartz:
# JobStore 相关配置
jobStore:
# 数据源名称
dataSource: quartzDataSource # 使用的数据源
class: org.quartz.impl.jdbcjobstore.JobStoreTX # JobStore 实现类
driverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate
tablePrefix: QRTZ_ # Quartz 表前缀
isClustered: true # 是集群模式
clusterCheckinInterval: 1000
useProperties: false
# 线程池相关配置
threadPool:
threadCount: 25 # 线程池大小。默认为 10 。
threadPriority: 5 # 线程优先级
class: org.quartz.simpl.SimpleThreadPool # 线程池类型
创建任务Job1
@DisallowConcurrentExecution
public class Job1 extends QuartzJobBean {
private Logger logger = LoggerFactory.getLogger(getClass());
private static SimpleDateFormat fullDateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
private final AtomicInteger count = new AtomicInteger();
@Autowired
private DemoService demoService;
private String k1;
public void setK1(String k1) {
this.k1 = k1;
}
@Override
protected void executeInternal(JobExecutionContext context) {
logger.info("[job1的执行了,时间: {}, k1={}, count={}, demoService={}]", fullDateFormat.format(new Date()), k1,
count.incrementAndGet(), demoService);
}
}
继承 QuartzJobBean 抽象类,实现 #executeInternal(JobExecutionContext context) 方法,执行自定义的定时任务的逻辑。
QuartzJobBean 实现了 org.quartz.Job 接口,提供了 Quartz 每次创建 Job 执行定时逻辑时,将该 JobDataMap数据进行依赖属性注入到Job Bean中。
// QuartzJobBean.java
public final void execute(JobExecutionContext context) throws JobExecutionException {
try {
// 将当前对象,包装成 BeanWrapper 对象
BeanWrapper bw = PropertyAccessorFactory.forBeanPropertyAccess(this);
// 设置属性到 bw 中
MutablePropertyValues pvs = new MutablePropertyValues();
pvs.addPropertyValues(context.getScheduler().getContext());
pvs.addPropertyValues(context.getMergedJobDataMap());
bw.setPropertyValues(pvs, true);
} catch (SchedulerException ex) {
throw new JobExecutionException(ex);
}
// 执行提供给子类实现的抽象方法
this.executeInternal(context);
}
protected abstract void executeInternal(JobExecutionContext context) throws JobExecutionException;
注入Job任务配置如下:
@Bean
public JobDetail job1() {
return JobBuilder.newJob(Job1.class)
.withIdentity("job1")
.storeDurably()
.usingJobData("k1", "v1")
.build();
}
@Bean
public Trigger simpleJobTrigger() {
// 简单的调度计划的构造器
SimpleScheduleBuilder scheduleBuilder = SimpleScheduleBuilder.simpleSchedule()
.withIntervalInSeconds(30) // 频率 30s执行一次。
.repeatForever(); // 次数。
// Trigger 构造器
return TriggerBuilder.newTrigger()
.forJob(job1())
.withIdentity("job1Trigger")
.withSchedule(scheduleBuilder)
.build();
}
这时候启动项目查看日志如下:
2022-09-20 23:17:33.500 INFO 18982 --- [eduler_Worker-2] : [job1的执行了,时间: 2022-09-20 23:17:33, k1=v1, count=1, demoService=DemoService@3258ebff]
2022-09-20 23:18:03.463 INFO 18982 --- [eduler_Worker-3] : [job1的执行了,时间: 2022-09-20 23:18:03, k1=v1, count=1, demoService=DemoService@3258ebff]
2022-09-20 23:18:33.439 INFO 18982 --- [eduler_Worker-4] : [job1的执行了,时间: 2022-09-20 23:18:33, k1=v1, count=1, demoService=DemoService@3258ebff]
2022-09-20 23:19:03.448 INFO 18982 --- [eduler_Worker-5] : [job1的执行了,时间: 2022-09-20 23:19:03, k1=v1, count=1, demoService=DemoService@3258ebff]
从计数器count可以看出,每次 Job0 都会被 Quartz 创建出一个新的 Job 对象,执行任务,但是DemoService属性值相同,是Spring单例bean,同时JobData的数据自动映射注入到任务bean属性上。
上面是通过简单调度器simpleSchedule指定频率执行任务,当然我也可以使用主流的基于cron表达式实现任务周期执行:
@Bean
public JobDetail job1() {
return JobBuilder.newJob(Job1.class)
.withIdentity("job1")
.storeDurably()
.usingJobData("k1", "v1")
.build();
}
@Bean
public Trigger cronJobTrigger() {
// 每隔1分钟执行一次
CronScheduleBuilder scheduleBuilder = CronScheduleBuilder.cronSchedule("0 0/1 * * * ? *");
// Trigger 构造器
return TriggerBuilder.newTrigger()
.forJob(job1())
.withIdentity("job1Trigger")
.withSchedule(scheduleBuilder)
.build();
}
任务调度执行结果这里就不再展示了,和上面一回事。
3.实现原理
Quartz 是通过 Scheduler 调度器来进行任务的操作,它可以把任务 JobDetail 和触发器 Trigger 加入任务池中,可以把任务删除,也可以把任务停止,scheduler 把这些任务和触发器放到一个 JobStore 中,这里 jobStore 有内存形式的也有持久化形式的,当然也可以自定义扩展成独立的服务。
Quartz内部会通过一个调度线程 QuartzSchedulerThread 不断到 JobStore 中找出下次需要执行的任务,并把这些任务封装放到一个线程池 ThreadPool 中运行,组件结构如下图:
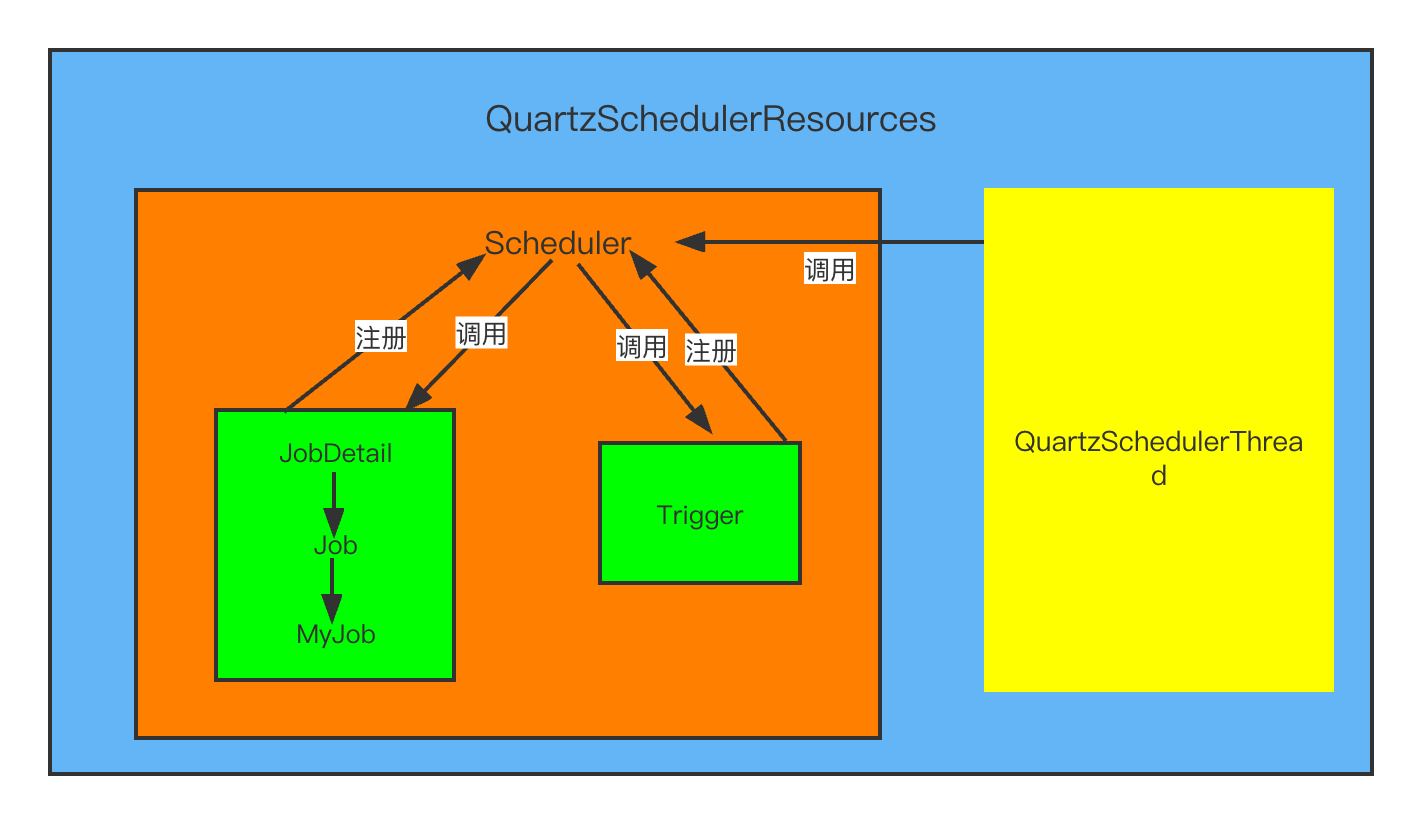
核心类
QuartzSchedulerThread:负责执行向QuartzScheduler注册的触发Trigger的工作的线程。 ThreadPool:Scheduler使用一个线程池作为任务运行的基础设施,任务通过共享线程池中的线程提供运行效率。 QuartzSchedulerResources:包含创建QuartzScheduler实例所需的所有资源(JobStore,ThreadPool等)。 SchedulerFactory :提供用于获取调度程序实例的客户端可用句柄的机制。 JobStore: 通过类实现的接口,这些类要为org.quartz.core.QuartzScheduler的使用提供一个org.quartz.Job和org.quartz.Trigger存储机制。作业和触发器的存储应该以其名称和组的组合为唯一性。 QuartzScheduler :这是Quartz的核心,它是org.quartz.Scheduler接口的间接实现,包含调度org.quartz.Jobs,注册org.quartz.JobListener实例等的方法。 Scheduler :这是Quartz Scheduler的主要接口,代表一个独立运行容器。调度程序维护JobDetails和触发器的注册表。 一旦注册,调度程序负责执行作业,当他们的相关联的触发器触发(当他们的预定时间到达时)。 Trigger :具有所有触发器通用属性的基本接口,描述了job执行的时间出发规则。 – 使用TriggerBuilder实例化实际触发器。 JobDetail :传递给定作业实例的详细信息属性。 JobDetails将使用JobBuilder创建/定义。 Job:要由表示要执行的“作业”的类实现的接口。只有一个方法 void execute(jobExecutionContext context) (jobExecutionContext 提供调度上下文各种信息,运行时数据保存在jobDataMap中)
Job有个子接口StatefulJob ,代表有状态任务。有状态任务不可并发,前次任务没有执行完,后面任务处于阻塞等到。 下面展示原生的Quartz创建任务、绑定触发器、注册任务和定时器、启动调度器,
/**
* 原生创建任务流程示例,有助于分析quartz实现原理
* @throws SchedulerException
*/
public static void test() throws SchedulerException {
//1.创建Scheduler的工厂
SchedulerFactory sf = new StdSchedulerFactory();
//2.从工厂中获取调度器实例
Scheduler scheduler = sf.getScheduler();
//3.创建JobDetail
JobDetail jb = JobBuilder.newJob(Job1.class)
.withDescription("this is a job") //job的描述
.withIdentity("job1", "test-job") //job 的name和group
.build();
//任务运行的时间,SimpleSchedule类型触发器有效
long time= System.currentTimeMillis() + 3*1000L; //3秒后启动任务
Date statTime = new Date(time);
//4.创建Trigger
//使用SimpleScheduleBuilder或者CronScheduleBuilder
Trigger t = TriggerBuilder.newTrigger()
.withDescription("")
.withIdentity("job1Trigger", "job1TriggerGroup")
//.withSchedule(SimpleScheduleBuilder.simpleSchedule())
.startAt(statTime) //默认当前时间启动
.withSchedule(CronScheduleBuilder.cronSchedule("0/10 * * * * ?")) //10秒执行一次
.build();
//5.注册任务和定时器
scheduler.scheduleJob(jb, t);//源码分析
//6.启动 调度器
scheduler.start();
}
public static void main(String[] args) throws SchedulerException {
test();
}
接下来对主要三个步骤:创建调度器、注册任务和触发器、启动调度器执行任务进行分析
调度器初始化
SchedulerFactory sf = new StdSchedulerFactory();
Scheduler scheduler = sf.getScheduler();
SchedulerFacotory 是创建调度器的工厂接口,它有两个实现,StdSchedulerFacotory 根据配置文件来创建 Scheduler,DirectSchedulerFactory 主要通过编码对 Scheduler 控制,通常为了侵入性更小、实现更方便我们用 StdSchedulerFacotory 类型来创建 StdScheduler,quartz.properties 里面的配置都对应到这个 StdSchedulerFactory 中,所以对某个配置不明白已经该配置的默认值可以看 StdSchedulerFactory 中获取配置的代码。
从sf.getScheduler()入手,进入StdSchedulerFacotory可以看到该方法逻辑:
public Scheduler getScheduler() throws SchedulerException {
// 第一步:加载配置文件,System的properties覆盖前面的配置
if (cfg == null) {
initialize();
}
SchedulerRepository schedRep = SchedulerRepository.getInstance();
Scheduler sched = schedRep.lookup(getSchedulerName());
if (sched != null) {
if (sched.isShutdown()) {
schedRep.remove(getSchedulerName());
} else {
return sched;
}
}
// 第二步:初始化,生成scheduler
sched = instantiate();
return sched;
}
这里一共完成两个逻辑:加载配置和生成scheduler,接下来进入核心方法instantiate(),这里面逻辑很多,其核心操作就是初始化各种调度所需要的对象,比如线程池、JobStore等等,最后把上面创建的对象放到 QuartzSchedulerResources 中并把线程池起来,这个相当于 QuartzScheduler 的资源存放处, 方法相关代码如下:
private Scheduler instantiate() throws SchedulerException{
......
// 要初始化的对象
JobStore js = null;
ThreadPool tp = null;
QuartzScheduler qs = null;
DBConnectionManager dbMgr = null;
String instanceIdGeneratorClass = null;
Properties tProps = null;
String userTXLocation = null;
boolean wrapJobInTx = false;
boolean autoId = false;
long idleWaitTime = -1;
long dbFailureRetry = 15000L; // 15 secs
String classLoadHelperClass;
String jobFactoryClass;
ThreadExecutor threadExecutor;
.....
QuartzSchedulerResources rsrcs = new QuartzSchedulerResources();
rsrcs.setName(schedName);
rsrcs.setThreadName(threadName);
rsrcs.setInstanceId(schedInstId);
rsrcs.setJobRunShellFactory(jrsf);
rsrcs.setMakeSchedulerThreadDaemon(makeSchedulerThreadDaemon);
rsrcs.setThreadsInheritInitializersClassLoadContext(threadsInheritInitalizersClassLoader);
rsrcs.setRunUpdateCheck(!skipUpdateCheck);
rsrcs.setBatchTimeWindow(batchTimeWindow);
rsrcs.setMaxBatchSize(maxBatchSize);
rsrcs.setInterruptJobsOnShutdown(interruptJobsOnShutdown);
rsrcs.setInterruptJobsOnShutdownWithWait(interruptJobsOnShutdownWithWait);
rsrcs.setJMXExport(jmxExport);
rsrcs.setJMXObjectName(jmxObjectName);
//这个线程执行者用于后面启动调度线程
rsrcs.setThreadExecutor(threadExecutor);
threadExecutor.initialize();
rsrcs.setThreadPool(tp);
if (tp instanceof SimpleThreadPool) {
if (threadsInheritInitalizersClassLoader)
((SimpleThreadPool) tp).setThreadsInheritContextClassLoaderOfInitializingThread(
threadsInheritInitalizersClassLoader);
}
//执行线程池启动
tp.initialize();
tpInited = true;
rsrcs.setJobStore(js);
// add plugins
for (int i = 0; i 经过上面调度器scheduler就初始化好了,接下来就可以定义Job和Trigger,然后通过scheduler.scheduleJob(jb, t)注册任务和触发器。
注册任务和触发器
scheduler.scheduleJob(jb, t)
进入StdScheduler#scheduleJob(JobDetail jobDetail, Trigger trigger)
public Date scheduleJob(JobDetail jobDetail, Trigger trigger)
throws SchedulerException {
return sched.scheduleJob(jobDetail, trigger);
}
这里的sched对象就是QuartzScheduler,进入sched.scheduleJob(jobDetail, trigger),这里就是注册任务和定时任务的核心逻辑。
public Date scheduleJob(JobDetail jobDetail, Trigger trigger) throws SchedulerException {
.....
//核心代码:存储给定的org.quartz.JobDetail和org.quartz.Trigger。
resources.getJobStore().storeJobAndTrigger(jobDetail, trig);
notifySchedulerListenersJobAdded(jobDetail);
notifySchedulerThread(trigger.getNextFireTime().getTime());
notifySchedulerListenersSchduled(trigger);
return ft;
}
这里的resources就是上面创建调度器scheduler时初始化各种对象然后放到资源管理处QuartzSchedulerResources,其里面包含对JobStore对象,然后再通过这个对象保存任务和触发器,至于保存逻辑的细节这里不在详述,请自行查看,反正核心逻辑这里上下文都对上了。
启动调度器执行任务
quartz 用一个线程不断轮询查找下次待执行的任务,并把任务交给线程池执行,这里涉及两种角色:调度线程和执行线程池。
scheduler.start();
scheduler.start() 调用 QuartzScheduler.start(),Quartz 的启动要调用start()方法进行线程的启动,线程中启动线程是调用start()方法,但是真正执行线程任务的操作在run()中
QuartzScheduler.start()代码如下:
public void start() throws SchedulerException {
if (shuttingDown|| closed) {
throw new SchedulerException(服务器托管网
"The Scheduler cannot be restarted after shutdown() has been called.");
}
notifySchedulerListenersStarting();
if (initialStart == null) {//初始化标识为null,进行初始化操作
initialStart = new Date();
this.resources.getJobStore().schedulerStarted();//1 主要分析的地方
startPlugins();
} else {
resources.getJobStore().schedulerResumed();//2 如果已经初始化过,则恢复jobStore
}
schedThread.togglePause(false);//3 唤醒所有等待的线程
getLog().info(
"Scheduler " + resources.getUniqueIdentifier() + " started.");
notifySchedulerListenersStarted();
}
this.resources.getJobStore().schedulerStarted() ;主要分析的地方,实际上是调用 QuartzSchedulerResources中的JobStore进行启动。
最后QuartzSchedulerThread.run()主要是在有可用线程的时候获取需要执行Trigger并出触发进行任务的调度!
看线程 QuartzSchedulerThread 的 run () 方法以 while (true) 的方式循环执行,不断从jobStore中获取下次要触发的触发器集合,将任务放到线程池中执行,这也是Quartz实现定时周期执行任务的核心所在,具体分析请看:https://my.oschina.net/chengxiaoyuan/blog/674603
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
