

日报&周刊合集 | 生产力工具与行业应用大全 | 点赞关注评论拜托啦!

华策影视AIGC工程师招聘,AIGC在「文娱领域」的真正落地

逛即刻时发现关注的AI博主 @杨昌 发布了自己公司的招聘信息,而且附上了团队氛围和工作感受等分享。华策影视是影视行业龙头企业,成立了 AIGC 应用研究院,重视AI且不算卷。岗位 base 上海,感兴趣可以前往社交媒体主页查看详情~ ⋙ 即刻 @杨昌 | 了解更多

百度 AGI Foundathon 大模型创业松,LLM 时代的应用层创业

https://aistudio.baidu.com/competition/detail/1040/0/task-definition
百度飞桨、文心大模型联合百度风投,举办了「AGI Foundathon 大模型创业松」,邀请世界各地的AI开发者和创业团队,基于「文心大模型」构建具备商业价值的 Generative AI 应用。
第一期活动分为三个方向,需要在初赛截止 (2023年10月11日) 前提交商业策划书:
创新应用:根据实际需求,自由选定方向构建应用
场景落地:理解需求场景,一起来进行大模型技术和企业需求场景的合作共建
文心一言插件赛道:结合D端或B端开发者能力、数据或第三方服务能力,建设插件 plugins ⋙ 了解更多

Runway 发布自定义镜头控制,人人都是导演的时代到来了

https://twitter.com/runwayml/status/1701218011984654403
Runway 是人工智能生成视频方向的独角兽,并在上周发布了生成视频的4种不同的运镜功能,并且这些功能之间还可以相互叠加。
这篇文章用同一个视频片段演示了几种非常不错的运镜方式,非常值得收藏和模仿:
1. Custom camera control 自定义摄像头控制
Speed 速度控制 (1~10)
Horizontal 水平运镜 (向左/向右)
Vertical 垂直运镜 (向上/向下)
Zoom 推近推远 (放大/缩小)
Roll 旋转运镜 (顺时针/逆时针)
2. 运镜叠加玩法两种模式
Horizontal 水平运镜 + Vertical 垂直运镜
Horizontal 水平运镜 + Zoom 推近拉远
Vertical 垂直运镜 + Zoom 推近推远
Roll 旋转运镜 + Zoom 推近推远
3. 运镜叠加玩法三种模式
- Horizontal 水平运镜 + Vertical 垂直运镜 + Zoom 推近推远 ⋙ 阅读原文

生成式AI的未来是什么?可以从这15张图表中一窥究竟

ShowMeAI 知识星球资源编码:R185
这是麦肯锡在8月底发布的一篇博文,切入视角非常有意思!作者回顾了麦肯锡在生成式AI爆发早期 (今年4月左右) 的一些报告和结论。
作者截选了15张图片来进行更详细的阐述。ShowMeAI 将所有图片整理成了一份 PDF 文档,可以扫码前往知识星球下载保存。今天的日报只选择其中几张进行展示:
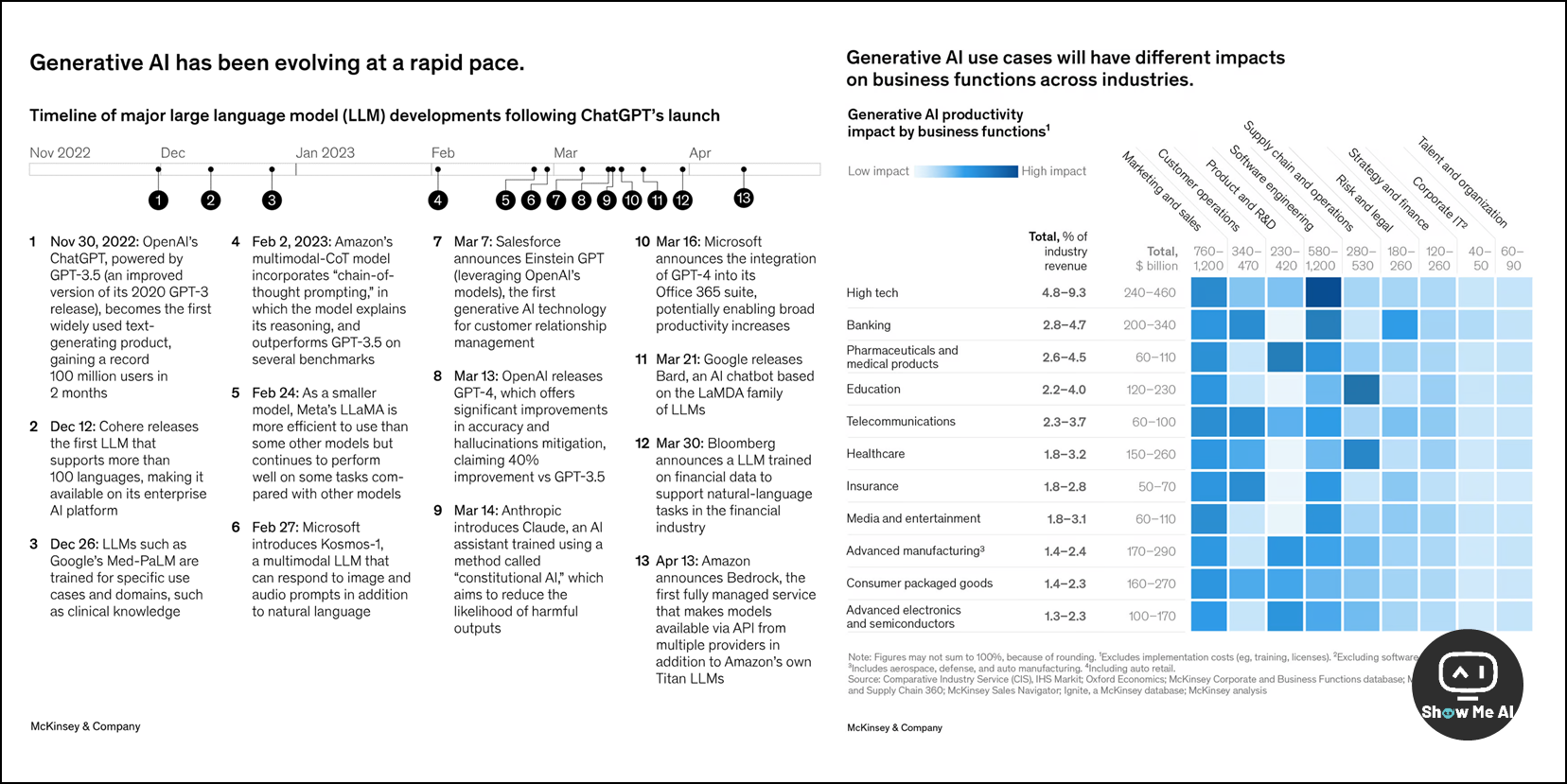
生成式AI技术正在快速迭代发展,各种新模型和应用层出不穷
生成式AI预计在本世纪内在许多技能上达到人类表现中等甚至较高水平,时间缩短了40年
生成式AI最大影响是知识型工作的自动化,如教育、法律、技术等领域
各行各业的特定应用正在不断涌现,专业化的应用更有价值
不同行业获得的价值各有不同,但销售营销作用普遍重大
评估业务,找出最高价值的具体使用案例非常关键
虽然生成式AI应用广阔,但大多数组织还很少使用
销售营销领导最看好提升主导权、营销优化和个性化外展等应用
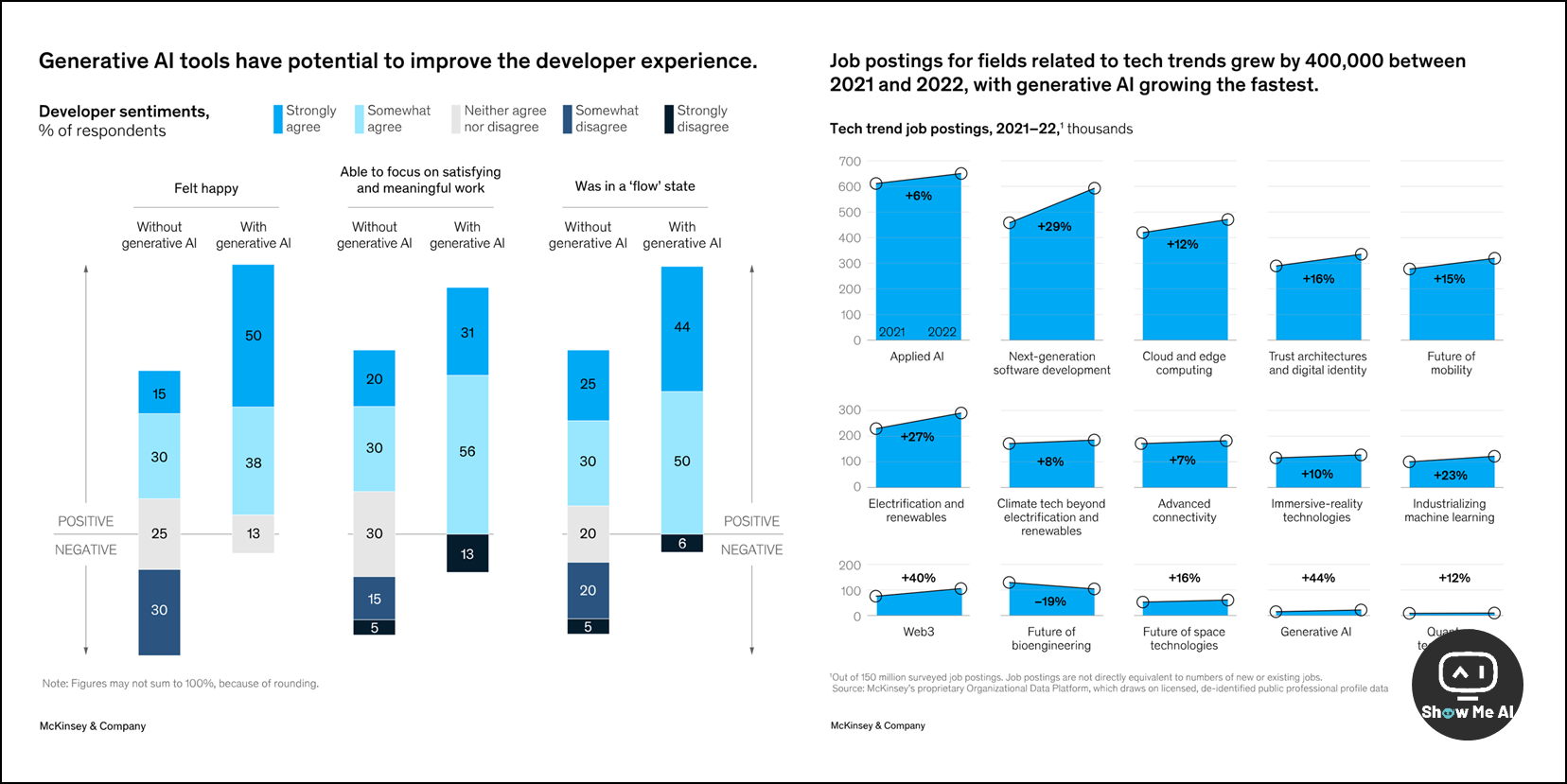
软件开发效率可能大幅提高,节省大量时间
生成式AI让开发者更快乐,更易保留人才
各行业员工已经开始广泛使用生成式AI工具
组织需要培养更多生成式AI人才以满足需求
应谨慎采用,注意风险,保持人工审查
如果培训员工掌握新技能,生成式AI可大幅提升全球GDP ⋙ 阅读原文

AI Grant (AI版YC) 公布第二期 29 个项目,扒一扒所有项目底细
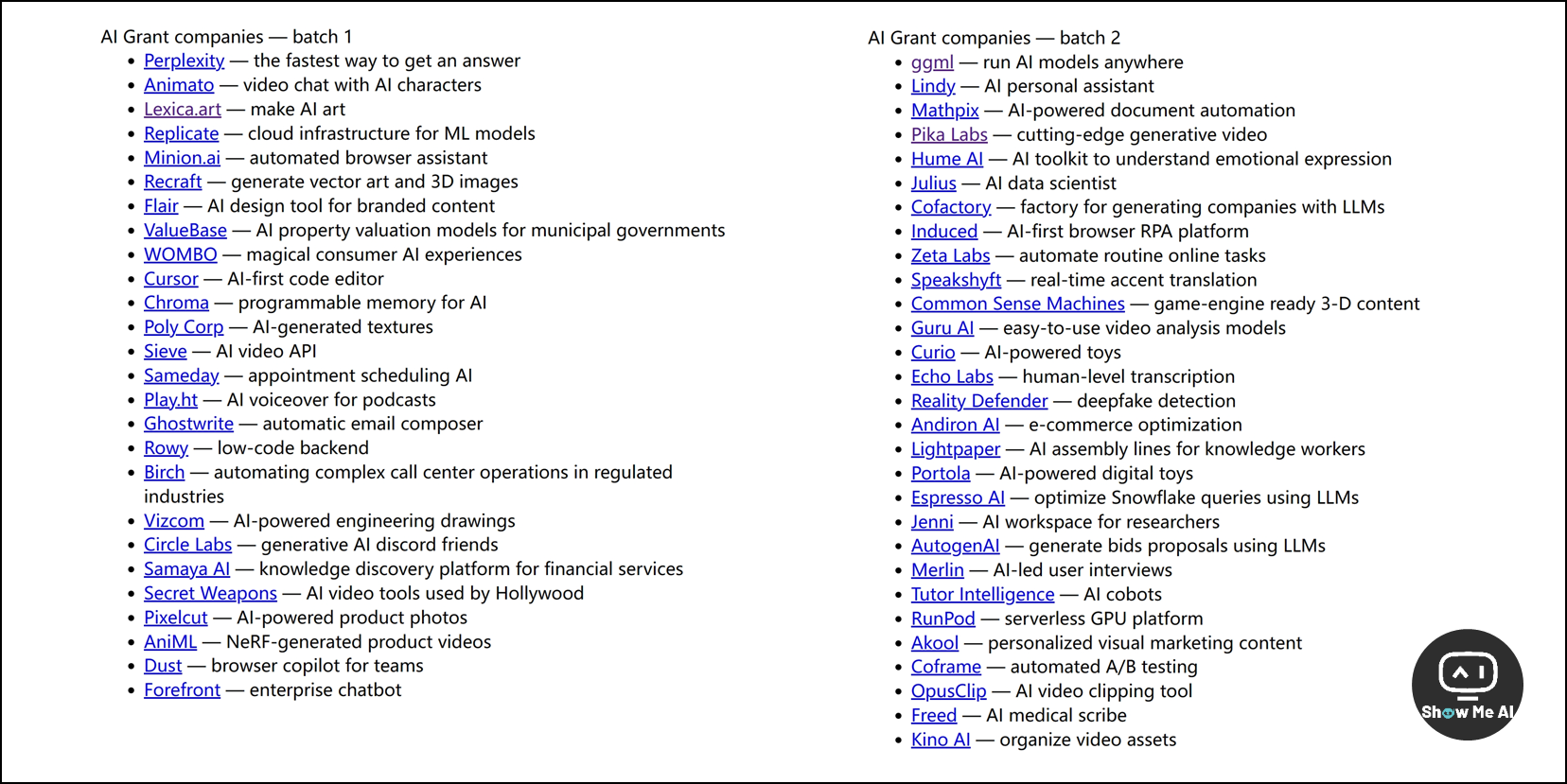
https://aigrant.com
AI Grant由Github前CEO / 知名投资人Nat Friedman和Daniel Gross共同设立,聚焦AI产品的投资孵化。入选项目将获得25万美金的投资和35万美金的Azure credits等创业激励。
AI Grant 第一期于去年8月开始,一共入选26个项目,包括今年热度很高的AI创业公司Perplexity、Relicate、Dust等。第二期项目于今年6月底开始,竞争空前激烈,并于上周公布了入选名单,一起来看看:
自动化效率工具
Lindy:你的AI个人助理
Induced:AI-first browser RPA platform.
Zeta Labs:Automate routine online tasks.
Lightpaper:AI assembly lines for knowledge workers.
聚焦细分场景的写作助手
Jenni:服务于研究人员的写作助手
AutogenAI:AI标书助手
效果导向的内容生成
Coframe:基于UI元素自动生成变体,通过A/B测试确定最优解
Opus Clip:一键将长视频分割成多个爆款短视频
用户体验提升
Merlin:能主导对话且跟进询问的AI用户访谈工具
Speakshyft:实时口音翻译工具
非结构化内容处理
5.1 Mathpix:服务于科研人员的文档效率工具
5.2 Freed:医疗场景的AI抄写员
Kino AI:对原始录像素材进行管理和搜索的桌面应用
人类情感模型
- Hume AI:专注于人类情绪的研究
AI风险
- Reality Defender:Deepfake技术探测器
AI玩具
Curio:可以讲话的玩具
Portola:给小孩的电子玩具 ⋙ 查看所有项目的详细介绍 | AI Grant第三期目前已经允许创业者申请

主流大语言模型的技术原理细节
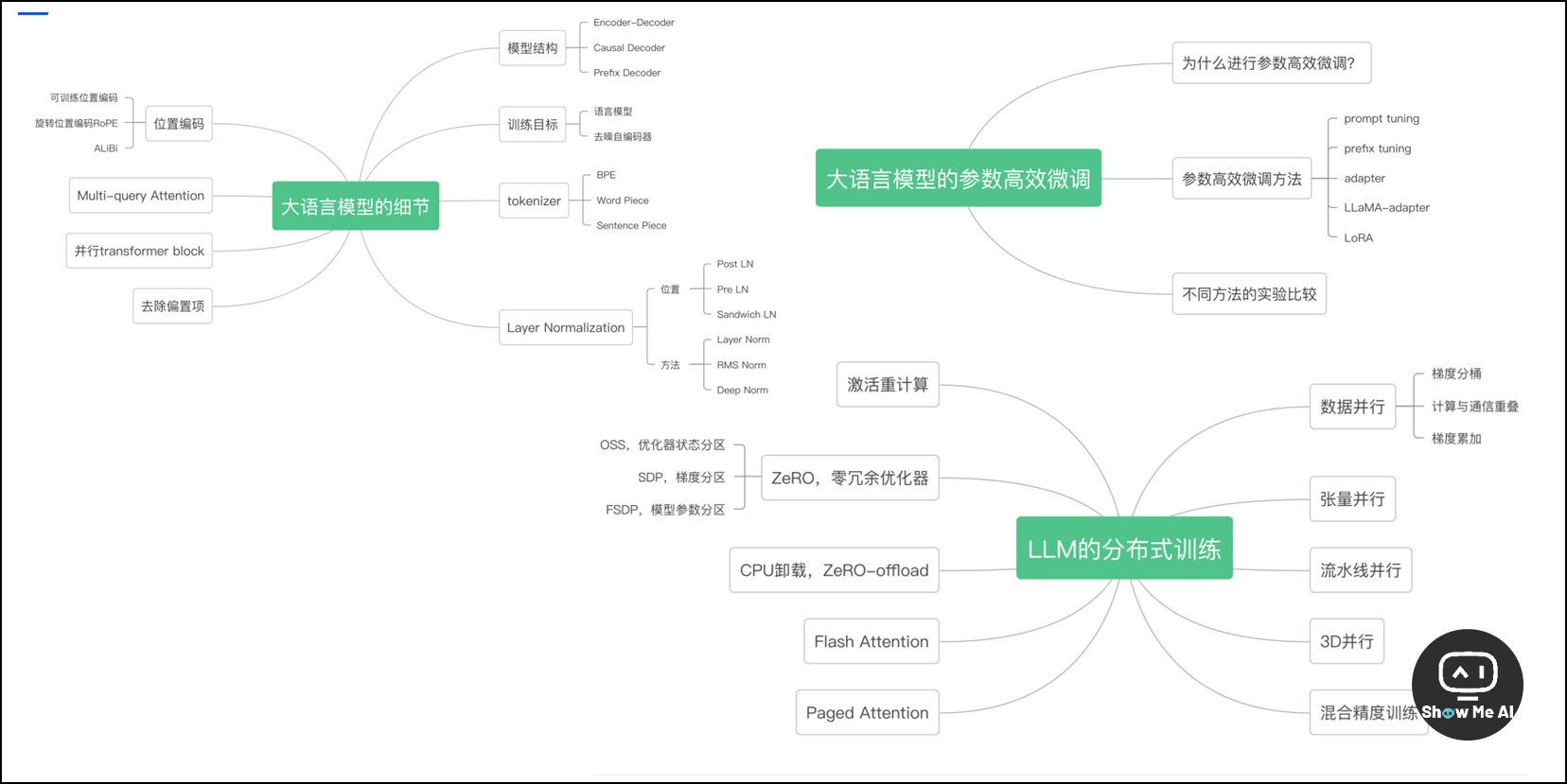
这是一篇技术感十足的文章,比较了 LLaMA、ChatGLM、Falcon 等大语言模型的细节,详细介绍了大语言模型的分布式训练技术、以及大语言模型的参数高效微调技术。
上方是课程要点思维导图,可以清晰地看到文章重点。以下是原文大纲,如果有你感兴趣的内容,可以前往对应位置查看技术细节内容的介绍:
1. 大语言模型的细节
transformer 与 LLM
模型结构
训练目标
tokenizer
位置编码
层归一化
激活函数
Multi-query Attention 与 Grouped-query Attention
并行 transformer block
总结-训练稳定性
2. LLM 的分布式预训练
点对点通信与集体通信
数据并行
张量并行
流水线并行
3D 并行
混合精度训练
激活重计算
ZeRO,零冗余优化器
CPU-offload,ZeRO-offload
Flash Attention
vLLM: Paged Attention
3. LLM 的参数高效微调
为什么进行参数高效微调?
prompt tuning
prefix tuning
adapter
- 服务器托管网
LLaMA adapter
LoRA
实验比较
4. 参考文献 ⋙ 阅读原文

AIGC 图像生成,Prompt 的七个缺陷与解决方案汇总

这是一篇非常「妙」的学习笔记,作者根据自己的经验对 Prompt 的种种限制进行了总结,并给出了当下比较有效的解决方案。当我们摸到了工具的能力边界,使用它们的时就能更从容和高效。
写作技能:将三维的画面转化为一维的文字是有挑战性的 → 需要反复书写带来的经验累积或是专门的学习
文本特性:文本的多义性会使得模型的理解发生偏差,生成内容无法切中创作者的真实意图 → 基于错误反馈不断对导致歧义的内容进行替换和校正
字数限制:超过AI模型对字数理解的「上限」后,Prompt 中添加再多的细节描述也无法被正确理解 → 限制提示词的字数
规则格式:模板化的提示词更容易被模型理解而且更稳定 → 需要学习并熟练掌握基于技术逻辑反推出的指令公式,以及控制各类权重的命令参数
作用关系:同一条 Prompt 中出现冗余甚至相互对立的信息 → 通过删A留B、删B留A的方式反复比对来定位修改点
细节控制:需要对形式、位置、比例、层次、关系等要素进行专业严谨处理的场景,模型能否精准执行 → 依靠 Prompt 进行精细化控制并不现实
生成预期:生成前不能预测结果,生成过程又类似于黑箱 → 先生成几张看看什么效果,找到符合预期的那张再继续深入
为了降低 Prompt 的学习和使用门槛,平台从产品、工具和教程等进行了很多的努力,比如一键复制、智能补全、创作手册、撰写教程。
当然技术侧的进展更快,涂抹、叠加、扩展等二次编辑能力,以Lora为代表的微调模型,还有Controlnet技术,支持边缘检测、草图处理、姿势识别等前沿黑科技,都在试图融合更多其他模态的意图信息,与Prompt形成互补,让生成结果更加精服务器托管网准可控 ⋙ 阅读原文

Hugging Face 的 Diffusion Models (扩散模型) 课程
这是由 Hugging Face 组织的一门关于扩散模型 (Diffusion Models) 的免费课程,可以帮助学生全面理解扩散模型,并通过多个实践项目掌握使用和训练扩散模型的技能。课程适合有一定深度学习和PyTorch基础的学生学习。
以下是对该课程的4个章节的关键内容总结,感兴趣可以前往 GitHub 阅读详细的教程:
第1章:Diffusion 模型入门
介绍什么是 Diffusion 模型及其生成图像的迭代优化过程
使用 Diffusers 库实际体验 Diffusion 模型的训练和采样过程
从零开始实现一个Diffusion模型,了解各个组件的设计决策
第2章:微调与引导
使用现有模型进行微调以生成新类型的数据
使用引导技术在无条件模型中添加控制生成过程的能力
条件模型:利用类标签进行条件图像生成
第3章:Stable Diffusion
Stable Diffusion 使用潜在扩散提高运算效率
基于CLIP的文本编码进行条件图像生成
无分类器引导增强文本梯度
使用 DreamBooth 技术对 Stable Diffusion 进行微调
第4章:探索扩散模型的更多应用
知识蒸馏获得更快的采样速度
训练技巧提高模型性能
更好地控制生成过程:img2img、掩码引导、交叉注意力控制等
视频和音频生成
新型模型架构:基于Transformer和标记化表示的迭代优化 ⋙ GitHub
感谢贡献一手资讯、资料与使用体验的 ShowMeAI 社区同学们!

◉ 点击 日报&周刊合集,订阅话题 #ShowMeAI日报,一览AI领域发展前沿,抓住最新发展机会!
◉ 点击 生产力工具与行业应用大全,一起在信息浪潮里扑腾起来吧!
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
