
你好呀,我是歪歪。
定时任务,大家在开发的过程中肯定都是接触过的。
歪师傅面试的时候关于定时任务一般都会问这样的一个问题:在实际开发的过程中,你们是如何避免定时任务重复执行的呢?
什么意思呢?
我给你上个图你就明白了。
假设我们有个订单服务的微服务,它部署在两台机器上:
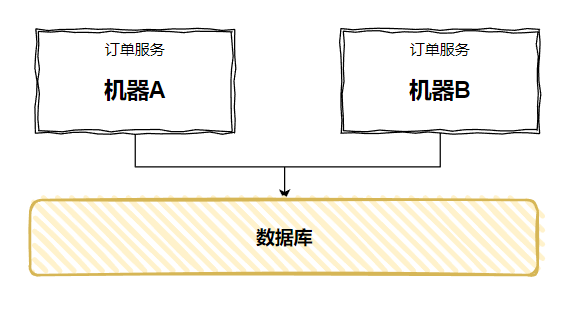
这是一个再正常不过的部署方案了吧。
现在有一个需求来了:要从数据库里面获取前一日状态为成功的订单,然后把这些订单一笔笔的调用其他服务的接口,通知给他们。
写代码的时候很简单,基于 Quartz 框架,咔嚓几下就能搞出一个定时任务来,伪代码如下:
//每天10点触发一次
@Scheduled(cron="0010**?")
publicvoidsendOrder(){
//查询前一日状态为成功的订单
ListorderList=selectSuccessOrder();
for(Orderorder:orderList){
//发送订单到数据分析服务
sendOrder(order);
}
}
测试的时候也非常的正常,看不出任何毛病。
但是一上生产就完犊子了,为什么呢?
因为测试环境一般来说就只部署一台服务器,但是生产环境是多台呀:
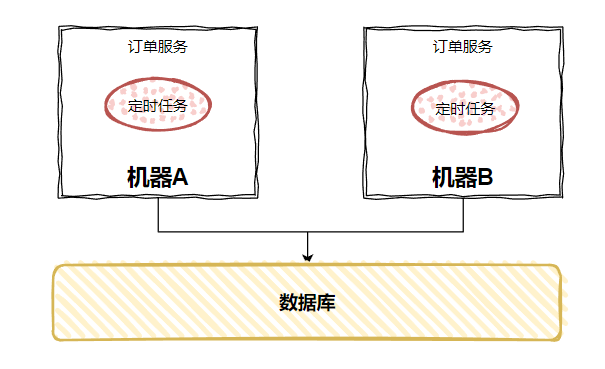
每天 10 点一到,两台机器都跑起来了…

同样的逻辑跑了两次,一下就瓜起了涩,这肯定不是我们想要的结果。
问:这个情况你怎么处理?
在实际开发的过程中,我理解大家理论上都会遇到这个问题的。
歪师傅当年还是一个小萌新,第一次遇到这个问题的时候,是怎么考虑的呢?
抠了抠脑袋,想到一个自己觉得非常靠谱的解决方案。
各个微服务提供接口,接口内部实现定时任务的业务逻辑。然后抽离出一个专门的定时任务微服务,在这个服务中开发定时任务,来调用对应的接口:
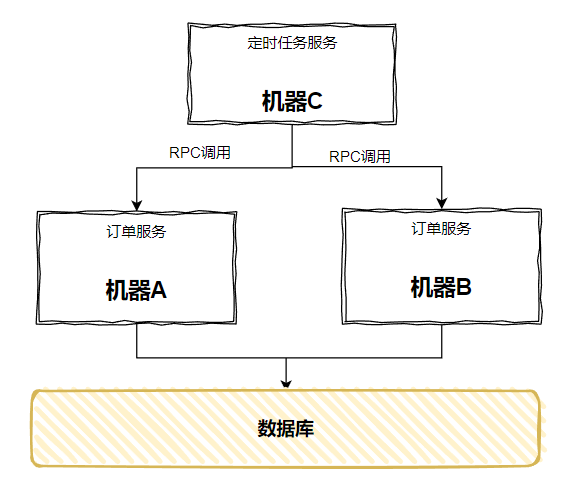
由于“定时任务微服务”只部署在一台服务器上,所以当定时任务的时间一到,只会发起一次 RPC 调用,具体调用哪一台服务,由 RPC 的负载均服务器托管网衡来决定。
从而规避了前面提到的“触发两次”的问题。
当时我还觉得微服务的思想还是真是厉害,这样一抽离之后,业务代码和定时逻辑彻底分离开来,横向扩展也不需要考虑“多次触发”的问题:
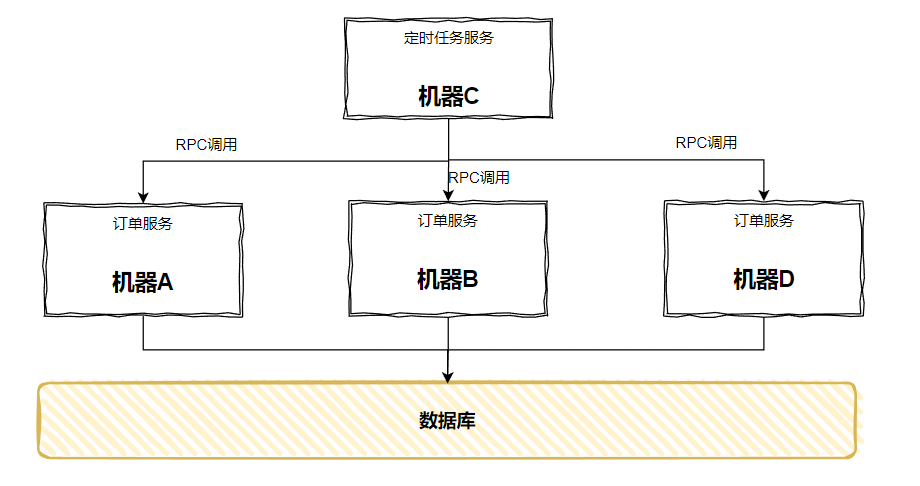
但是,问题随着就来了:定时任务服务只部署了一台,它有单点风险啊,它挂了,所有的定时任务不就都挂了吗?
我知道在有的公司,实际情况就是这样的,知道服务有单点风险,但是评估下来,觉得是可以接受的,大不了就是做好服务监控,出了问题就赶紧重启一波服务。
所以遇到这个问题的解决方案就是:不管它。

但是,朋友,面试的时候你能这样回答吗,你是去调侃面试官的吗?
所以,该怎么办?
单点问题,很好解决,针对“定时任务服务”多部署一台服务器就行了:
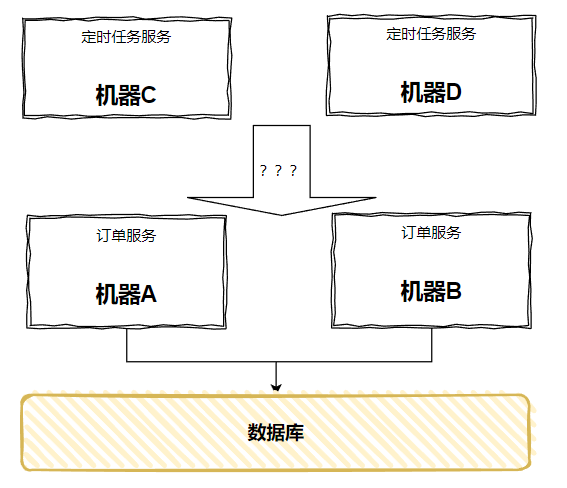
但是,调用关系怎么办呢?
时间一到,咔的一下,两台“定时任务服务”都跑起来了,都对下游发起了 RPC 调用,这不又出现了前面这样“调用两次”的问题吗:

开始套娃了,你说怎么办?
这个时候歪师傅又抠了抠脑袋,又想到一个自己觉得非常靠谱的解决方案。
关于这个问题,我先换个壳问你:如果有多个请求过来,但是我们同一时间只想让一个请求正常执行,请问你怎么办?
一般来说我们都会想到加锁嘛。
单机的话,什么 synchronized,ReentrantLock 这些玩意就使劲儿往上怼。
多台服务就上分布式锁嘛,Redis、Zookeeper 拿出来秀一秀嘛,对不对?
比如,如果我们用 Redis,怎么做?
在发起 RPC 调用之前先从 Redis 里面拿锁,多台机器,谁拿到了,谁就可以执行:
//每天10点触发一次
@Scheduled(cron="0010**?")
publicvoidsendOrder(){
//获取redis锁
if(SETkeyvalueexpireTimenx){
//拿到锁的才能调用订单服务发送成功订单逻辑的接口
callOrderRPC();
}
}
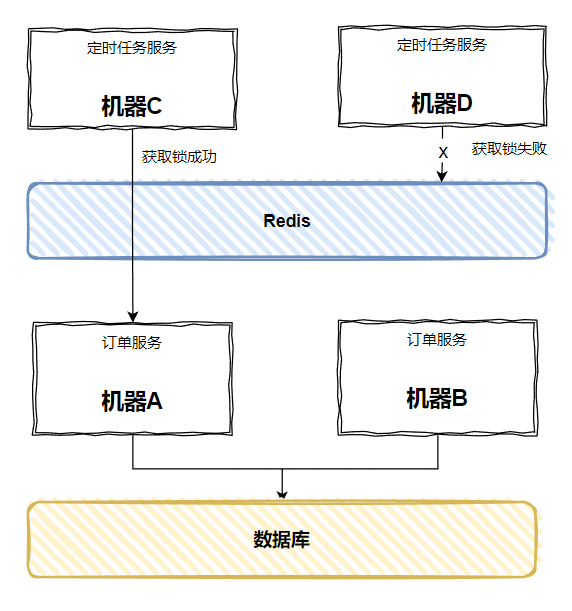
这样即使某一台服务器上的服务挂了,另外一台也能确保定时任务按时触发,并表示非常开心:很好,没人和我抢锁了。
或者说基于 zookeeper 来做。
比如我们定时任务的服务启动的时候,以服务名称维度向 zk 申请一个临时节点。
谁申请成功了,谁就算加锁成功了,虽然到点之后每个定时任务都会按时触发,但是和 Redis 同理,只有拿到锁的实例才能执行定时任务。
没有拿到锁的怎么办呢?
监听这个临时节点,处于随时待命状态。如果当前持有锁的服务挂了,那么临时节点也就没了,相当于锁就释放了,就可以上手抢锁了。
抢到锁,就可以执行定时任务,这样也能保证高可用。
如果是面试,针对“避免定时任务重复执行”能回答到分布式锁这里,我认为就可以了。
但是,朋友,这可是面试,面试一般是出连招的。
如果我突然画风一转,顺势提出下一个问题:
用分布式锁,可以通过只让一台机器运行的方式解决重复运行的问题。现在我换个场景,问问题,如果我昨日成功的订单数据量比较多,假设有 100w 笔吧,如果只在一台机器上跑,即使开启多线程,也需要很长的时间,而且是一台机器忙的不行,不太机器在旁边闲的不行。如果我想要充分把机器利用起来,让两台机器都来处理这 100w 笔订单,各自处理 50w 条,时间不就缩短了吗?
就像是这样:
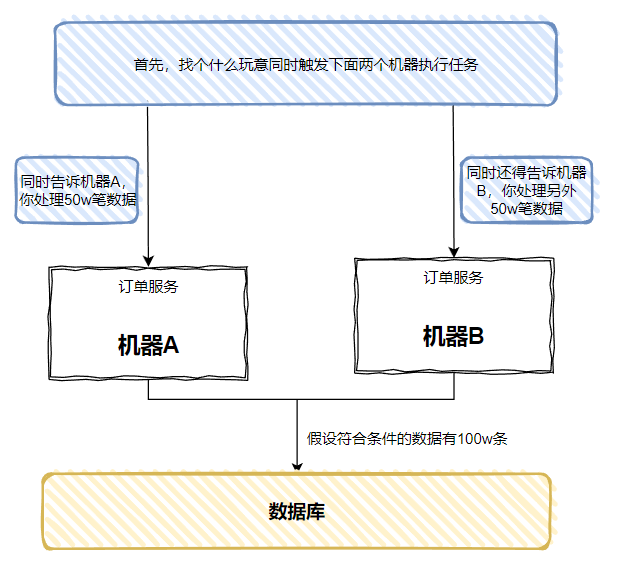
请问,阁下又该如何应对?
ElasticJob
好了,前面铺垫了这么多,终于要引出 ElasticJob 这个玩意了。
这是官方文档的地址:
https://shardingsphere.apache.org/elasticjob/current/cn/overview/
其中有一个章节叫做“弹性调度”:
弹性调度是 ElasticJob 最重要的功能,也是这款产品名称的由来。 它是一款能够让任务通过分片进行水平扩展的任务处理系统。
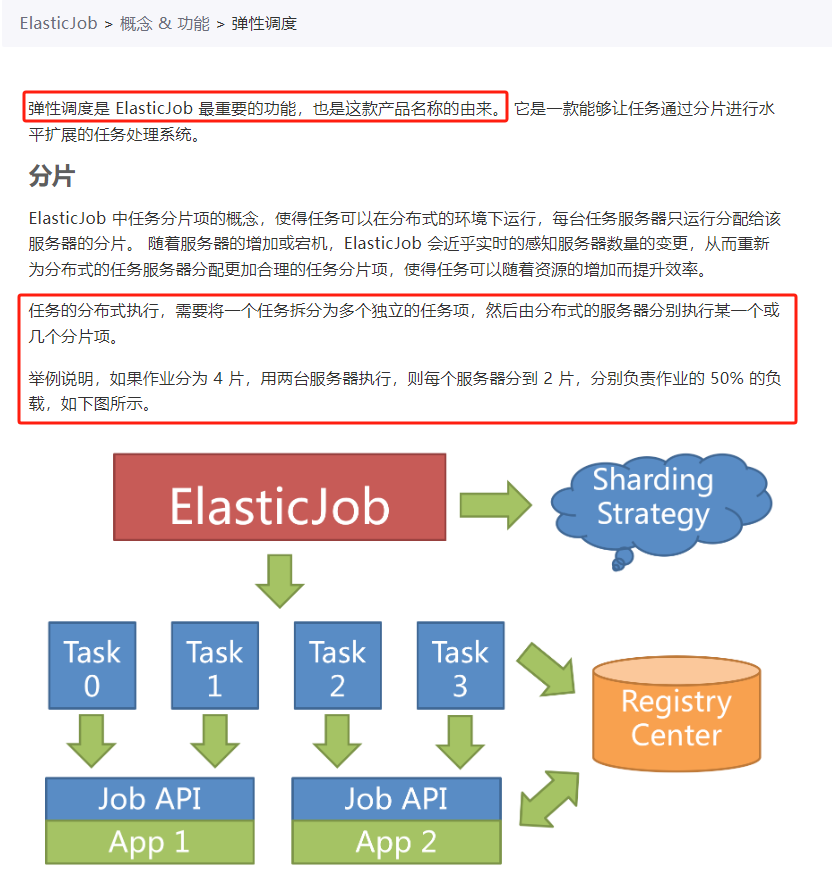
从关于“分片”的描述中,我们知道也许能在这里找到问题的答案。
虽然答案就在眼前,但是别猴急。按照歪师傅的风格,还是得先上个 Demo 作为引子,给你抽丝剥个茧。
这里顺便吐槽一句官方文档:

你这个“快速入门”写的是什么玩意,根本就不能用好吧?
quick start 不能拿来即用,对于本白嫖党来说,是很难受的,好吗。
害得我还得自己摸索一下,还好整体并不复杂,你按照歪师傅给你提供的“快速入门”,五分钟足够搭个 Demo 了。
首先,新建一个 Spring Boot 项目,在 pom 文件中加入相关引用:
org.apache.shardingsphere.elasticjob
elasticjob-lite-spring-boot-starter
3.0.1
然后实现 SimpleJob 接口,自定义一个定时任务:
packagecom.example.elasticjobtest;
@Slf4j
@Component
publicclassSpringBootJobimplementsSimpleJob{
@Override
publicvoidexecute(ShardingContextshardingContext){
log.info("SpringBootJob作业,分片总数是【{}】,当前分片是【{}】,分片参数是【{}】",
shardingContext.getShardingTotalCount(),
shardingContext.getShardingItem(),
shardingContext.getShardingParameter());
}
}
接着在 application.yml 里面添加配置:
elasticjob:
#注册中心配置
regcenter:
serverlists:127.0.0.1:2181
#ZooKeeper的命名空间
namespace:why-elastic-job
#作业配置
jobs:
springJob:#job的名称
elasticJobClass:com.example.elasticjobtest.SpringBootJob
cron:0/5****?
shardingTotalCount:2
shardingItemParameters:0=Beijing,1=Shanghai
就这几行代码,Demo 就算搭完了。
你自己说,这整个流程是不是五分钟够够的了?
在把服务启动起来之前,针对 application.yml 的配置,我先多 BB 几句。
里面这两个玩意是什么东西呢:
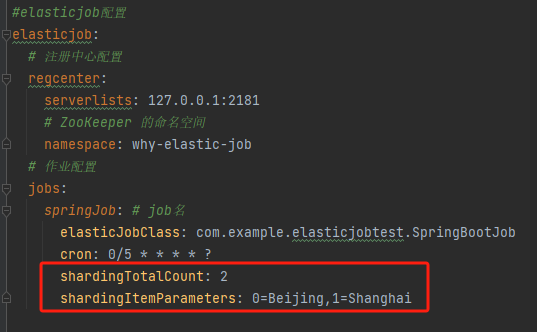
可以参考官方文档中的描述:
https://shardingsphere.apache.org/elasticjob/current/cn/user-manual/configuration/
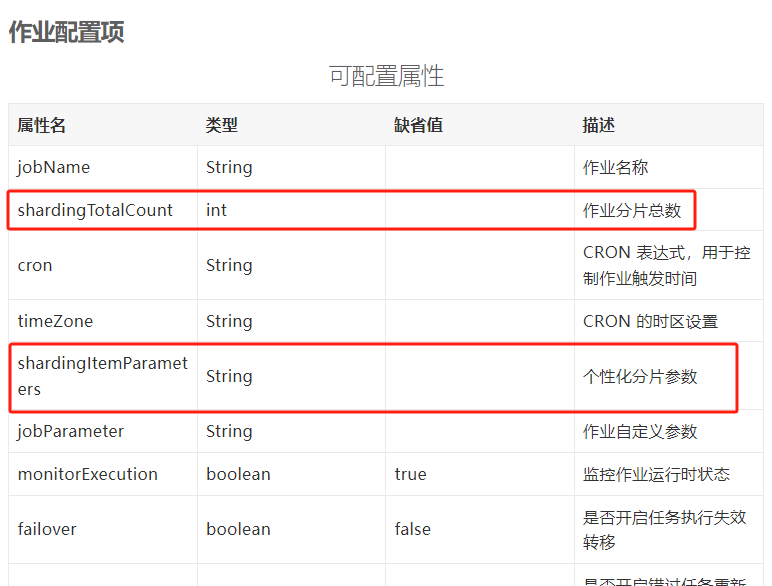
shardingTotalCount 叫做作业分片总数,这个概念非常重要,理解了这个概念,就理解了 ElasticJob 的核心理念,先按下不表。
shardingItemParameters 叫做个性化分片参数,我这里写的是 0=Beijing,1=Shanghai,看起来很奇怪对不对,怎么突然冒出了北京和上海呢?
因为这也是官方文档中的案例:

这只是实例而已,当你理解了这个概念的用途之后,就可以按照自己的需求进行“个性化”配置。
Demo 跑起来
这个是 ElasticJob 的架构示意图:
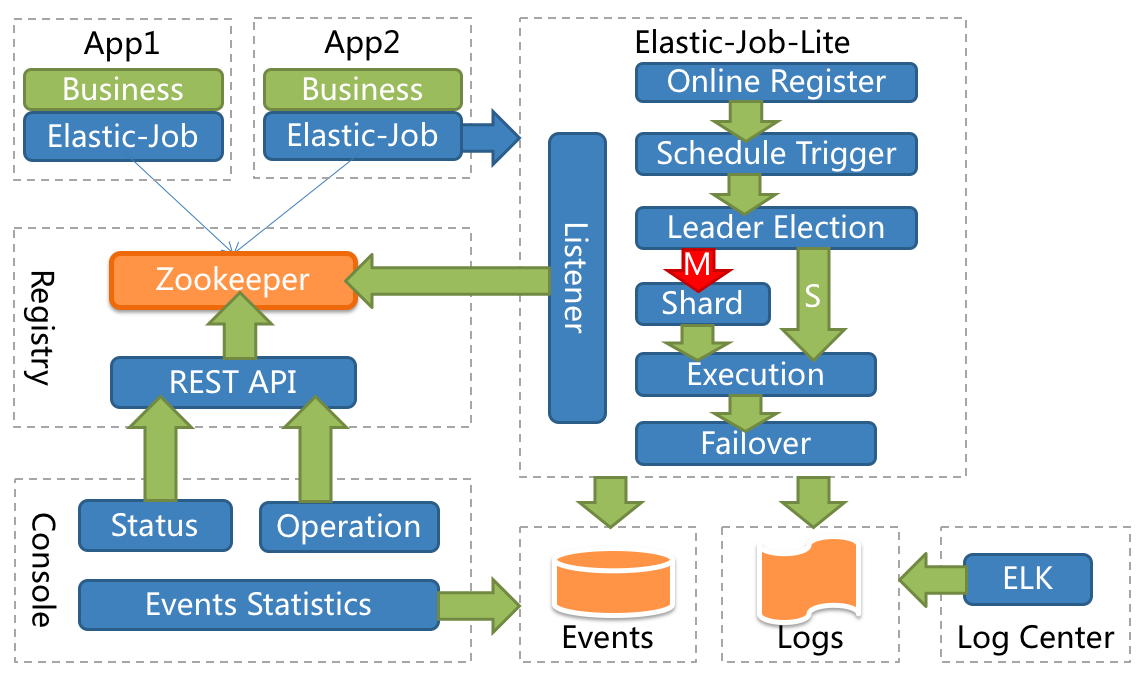
可以看到它选择了 Zookeeper 做为自己的注册中心,所以在启动 Demo 之前,需要你把你本地的 Zookeeper 启动起来。
然后把 Demo 运行起来,观察日志输出:
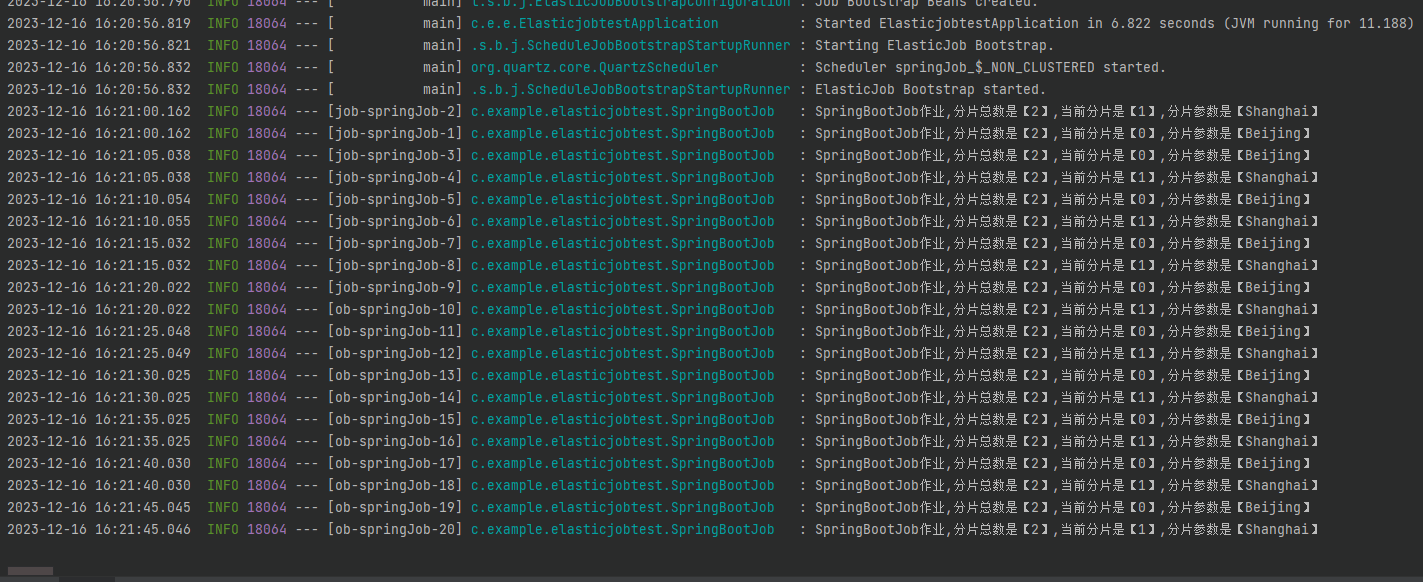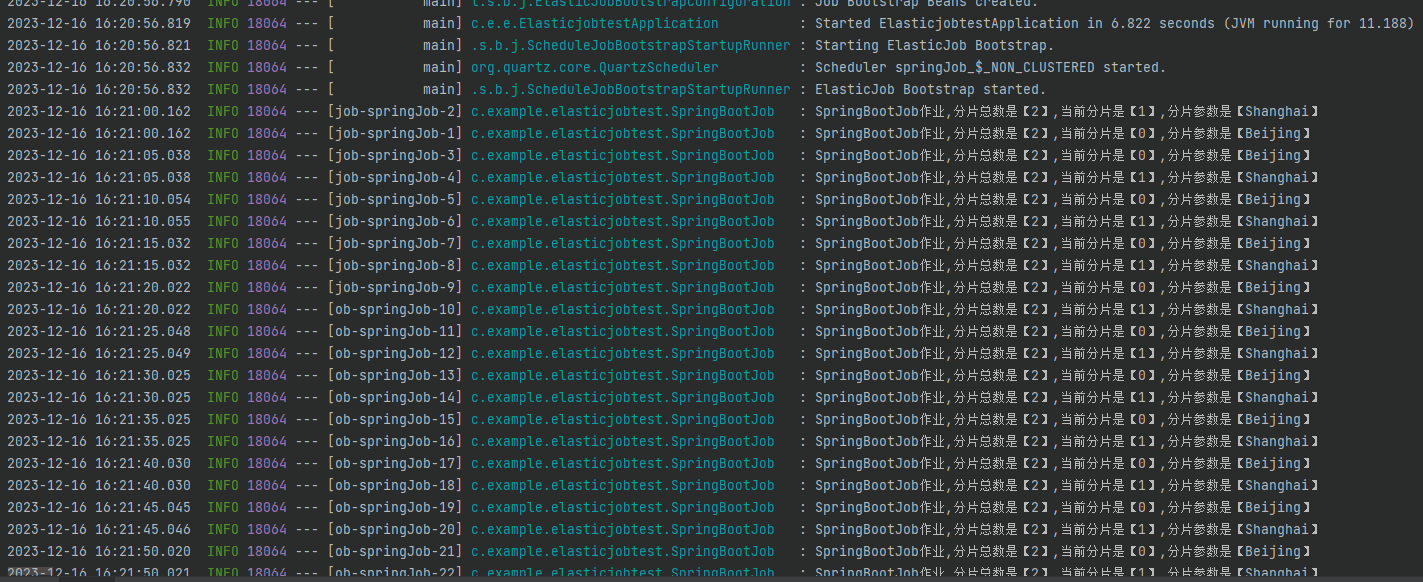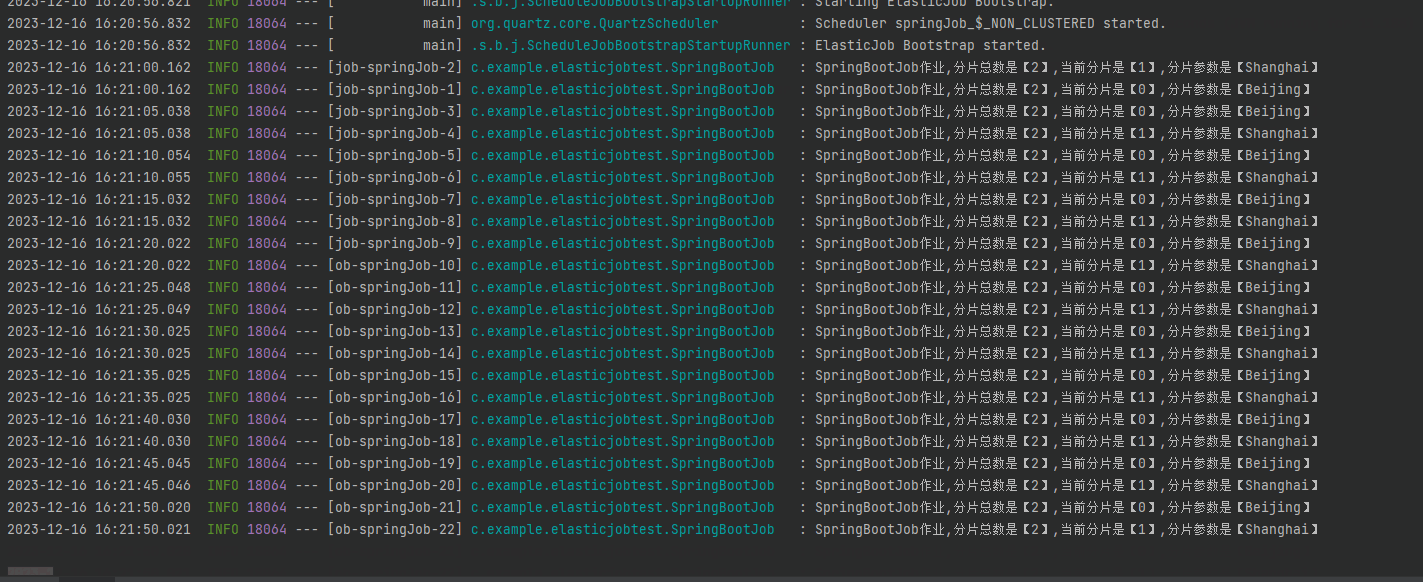
你会发现每隔 5s 就会输出这样的日志:
2023-12-1616:31:45.020SpringBootJob作业,分片总数是【2】,当前分片是【0】,分片参数是【Beijing】
2023-12-1616:31:45.020SpringBootJob作业,分片总数是【2】,当前分片是【1】,分片参数是【Shanghai】
怎么样,看到日志输出之后是不是稍微品出了点淡淡的味道,就是那种虽然不知道怎么回事,但是总感觉马上就摸到门道的感觉。

保持住这种感觉,歪师傅马上就让你摸到门把手了。
为了模拟多个服务部署的情况,所以我们需要再多启动一个服务。
在 Idea 里面点击这个:

然后把“Allow multiple instances(运行多实例运行)”勾选上:
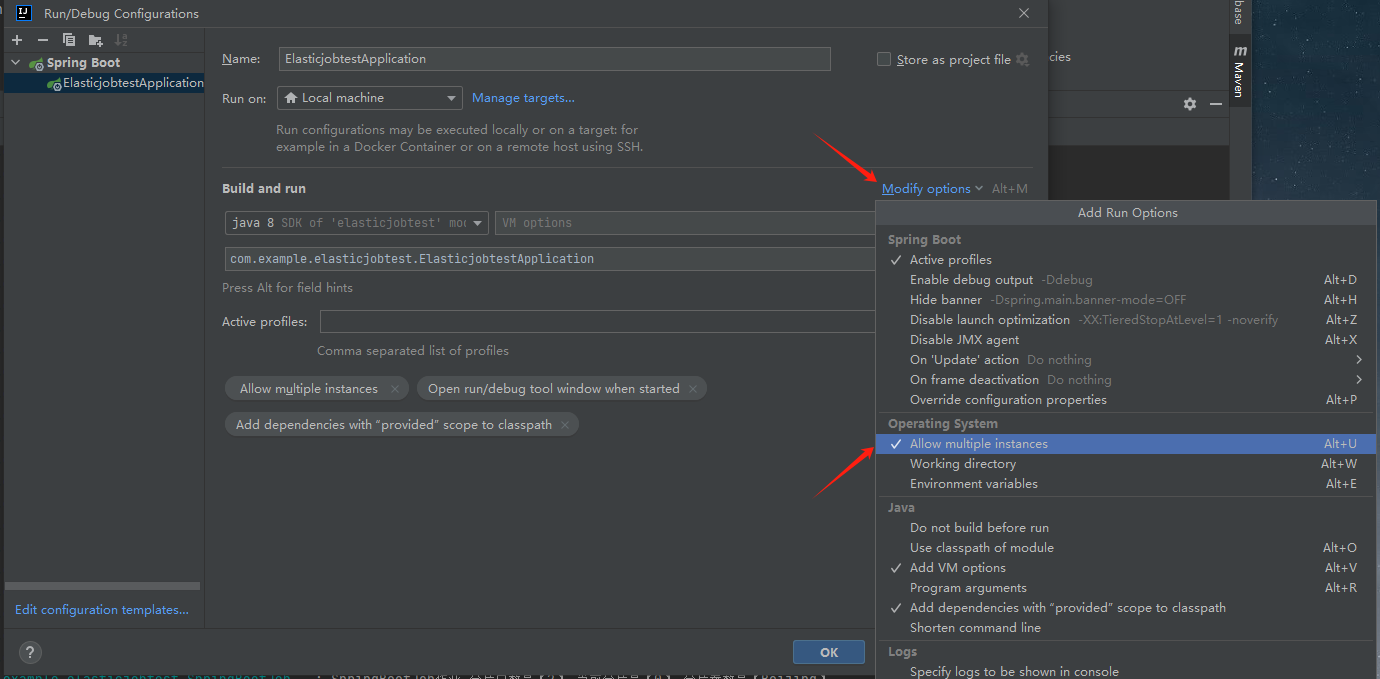
修改一下服务端口,避免端口冲突:
接着再次启动 Demo,观察一下日志:
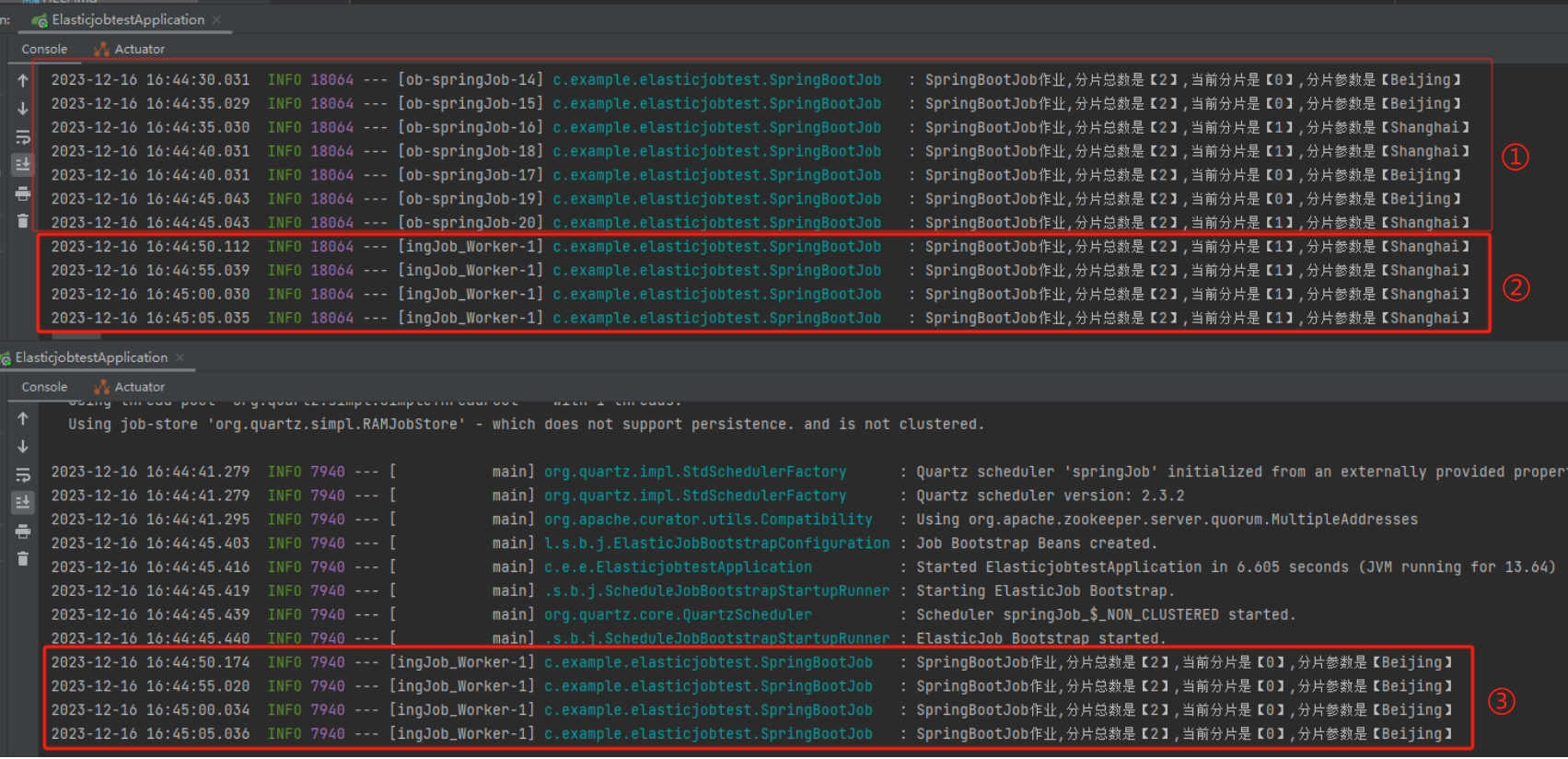
标号为 ① 的地方是仅一台服务器运行的情况,两个分片都在这一个服务器上运行。
标号为 ② 和 ③ 的地方是两台服务器都运行起来的情况,同样的代码、同样的配置,跑在不同的端口而已。
一台的日志输出是这样的:
SpringBootJob作业,分片总数是【2】,当前分片是【1】,分片参数是【Shanghai】
SpringBootJob作业,分片总数是【2】,当前分片是【1】,分片参数是【Shanghai】
另外一台的日志输出是这样的:
SpringBootJob作业,分片总数是【2】,当前分片是【0】,分片参数是【Beijing】
SpringBootJob作业,分片总数是【2】,当前分片是【0】,分片参数是【Beijing】
可以看到,每隔五秒钟两台服务器都同时触发了定时任务,但是一台拿到的参数是 Shanghai,一台拿到的参数是 Beijing。
这个时候我们再回去看面试官的这个问题:
假设有 100w 笔吧,如果只在一台机器上跑,即使开启多线程,也需要很长的时间,而且是一台机器忙的不行,不太机器在旁边闲的不行。如果我想要充分把机器利用起来,让两台机器都来处理这 100w 笔订单,各自处理 50w 条,时间不就缩短了吗?
然后我再给你上个图:
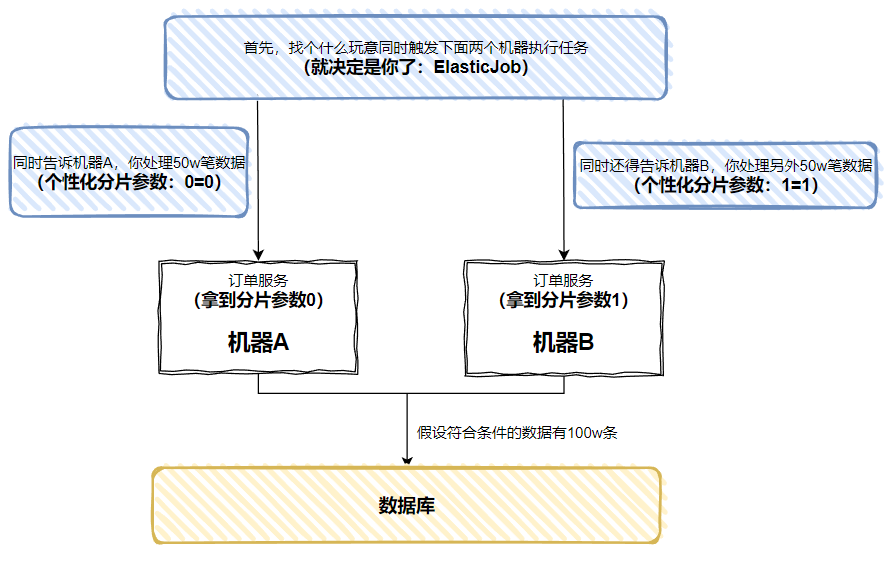
每个机器上运行的代码是一样的,但是通过 ElasticJob 能让每个机器在运行定时任务的时候,拿到不一样的参数。
基于这个不一样的参数,我们就能搞很多事情了嘛。
比如 100w 数据,分为两组,一组 50w 条。假设 ID 是连续自增的,是不是可以这样判断奇偶数:
偶数:id % 2 == 0
奇数:id % 2 == 1
在这个表达式里面,每个数据的 id 是确定的,而这个“2”,你看它像不像是我们的“分片数”?至于这个“0”和“1”,是不是可以通过我们的“个性化分片参数”传递进来?
id % 分片数 == 个性化分片参数
比如我们写个这样的代码:
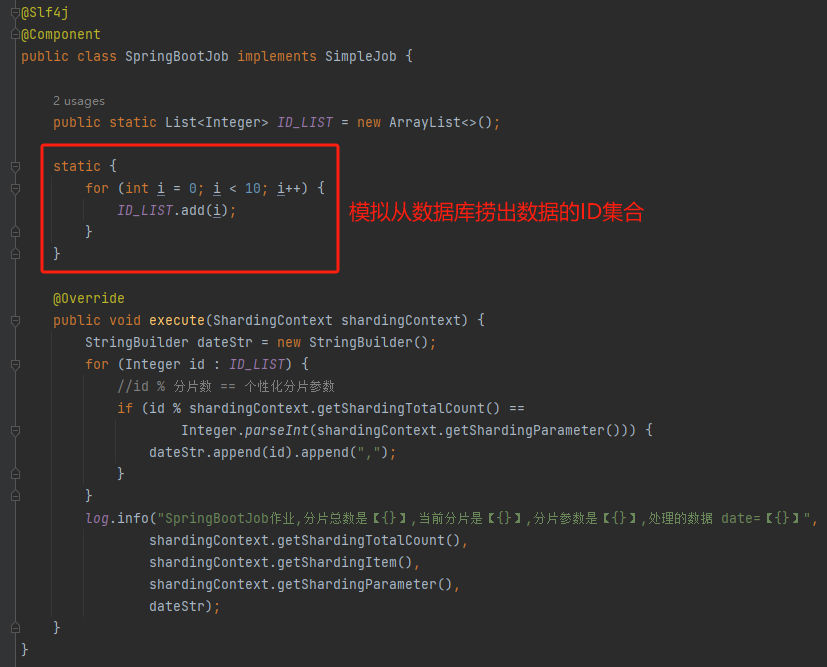
然后把作业配置改成这样的:
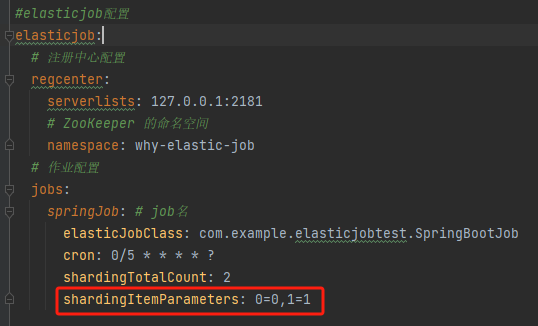
然后启动两个服务,我们观察一下日志输出:
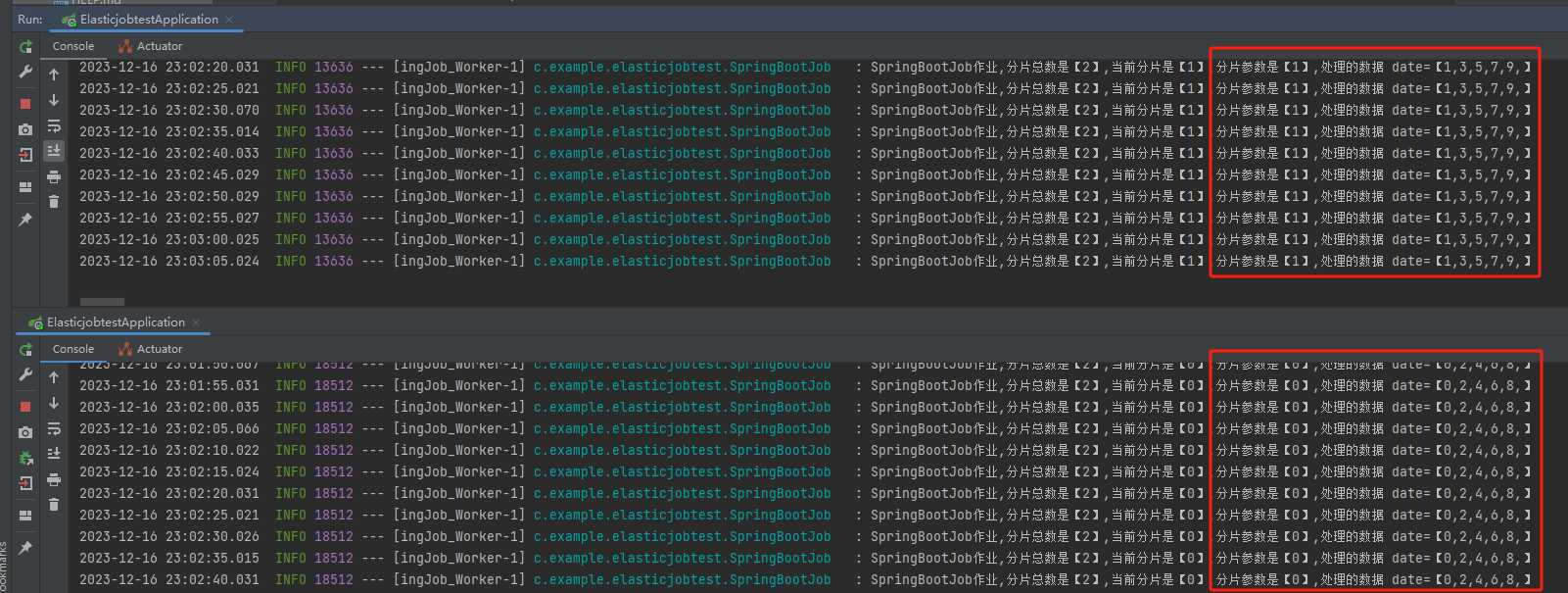
一台机器处理的是 “1,3,5,7,9”,一台机器处理的是“0,2,4,6,8”
刚刚面试官的问题是啥来着?
两台机器处理 100w 笔订单,各自处理 50w 条?
这不就实现了吗?

再给你看一个神奇的东西,假设我在运行时把 shardingTotalCount 修改为 3,即分片数变成 3,对应的自定义参数也进行对应的修改,会发生什么事情呢?
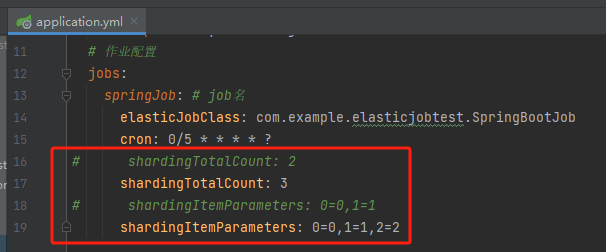
按照我们之前的这个逻辑:
id % 分片数 == 个性化分片参数
0 到 9 这十个数字分别对 3 取模,那么就会分成下面这三组:
-
第一组:0,3,6,9 -
第二组:1,4,7 -
第三组:2,5,8
这个没有任何毛病,对不对?
然后还需要特别注意的是,我说的是“在运行时”修改。
怎么修改?
很简单,ElasticJob 其实提供了对应的管理后台页面可以进行参数修改,但是我这里偷个懒,难得去部署对应的管理后台,,准备换个简单的思路。
因为前面说了,ElasticJob 使用的是 zk 做为自己的注册中心,我直接用工具连接上 zk,然后修改 zk 节点就行了。
我是怎么知道修改 zk 的哪个节点的呢?
别着急,等下就讲,歪师傅先带你看效果。
我这里用的工具是 ZooInspector,修改之后直接点击保存:
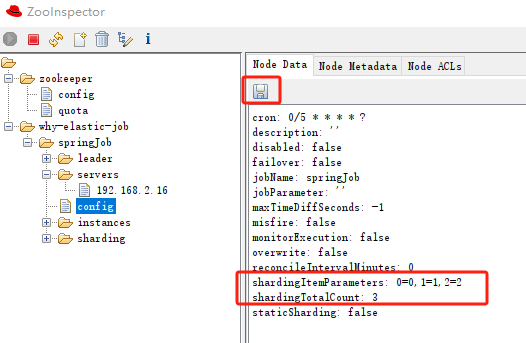
然后,朋友们,注意了,看日志输出
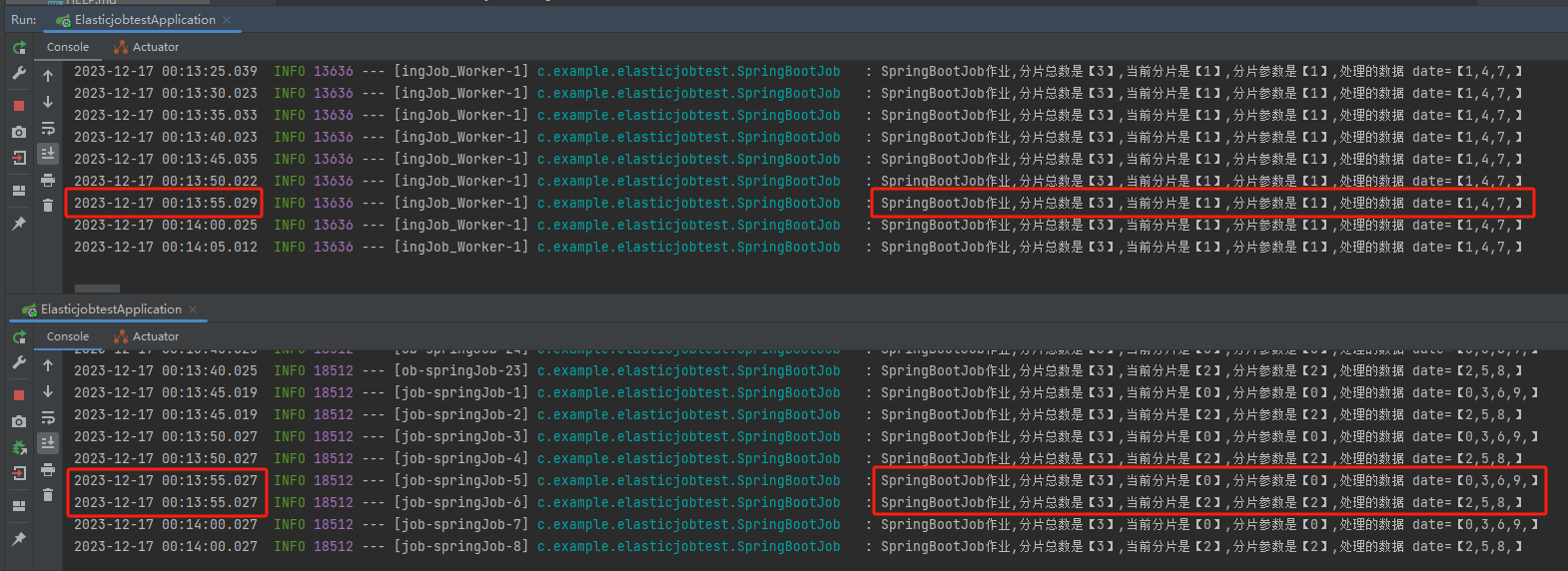
为了让你看的更加清楚,我把关键日志单独拿出来:
第一台机器上的日志是这样的:
分片总数是【3】,当前分片是【1】,分片参数是【1】,处理的数据 date=【1,4,7,】
第二台机器上的日志是这样的:
分片总数是【3】,当前分片是【0】,分片参数是【0】,处理的数据 date=【0,3,6,9,】
分片总数是【3】,当前分片是【2】,分片参数是【2】,处理的数据 date=【2,5,8,】
和我们前面推理的结果一模一样。
好,到这里就可以解答我的一个“按下不表”了。
首先,shardingTotalCount 叫做作业分片总数,在我前面的例子中,作业分片总数一共是 3 片:
-
第一组(第一片):0,3,6,9 -
第二组(第二片):1,4,7 -
第三组(第三片):2,5,8
分成三片之后,Elasticjob 怎么知道每一片应该处理哪些数据呢?
它不知道,它也不用知道。它只需要告诉每一台服务器:“来,哥们,给你一个号你拿着。你们这波一共有多少多少个人,你是第几片。”
就完事了。
因为“昨日成功的订单”这个总的要处理的数据是服务器托管网不变的,所有每一台服务器知道一共要把这批数据分成几片,自己是第几片后,通过代码就能拿到对应的该处理的数据。
然后你再去看官方描述中关于“分片项”你大概就能知道这到底是个啥玩意了:

有的哥们比较猛,一次拿到两个号,也没关系,就是多处理一份数据嘛。这种情况就适用于两台机器的性能不一致的情况。
但是我用这个案例并不是为了引出“性能不一致”这种极少数的情况,而是为了这个…
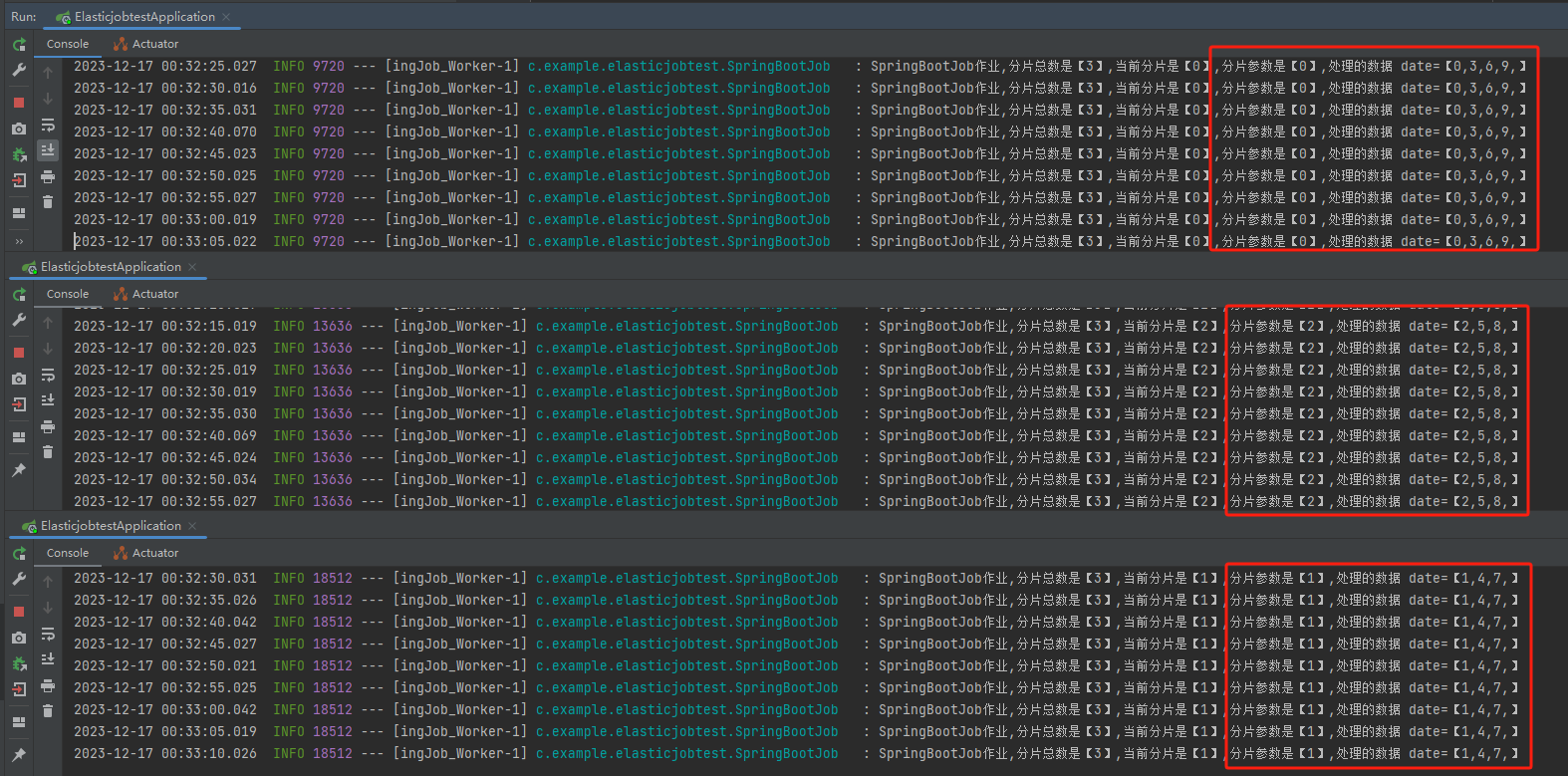
当我再启动一个新的服务器,当第三台服务器加入之后,我们啥也没干,它自己就开始处理任务了。
3 个分片,一台服务器处理一个分片的数据。
能自动加入,就能自动退出,所以假设我把一台服务给关闭了:
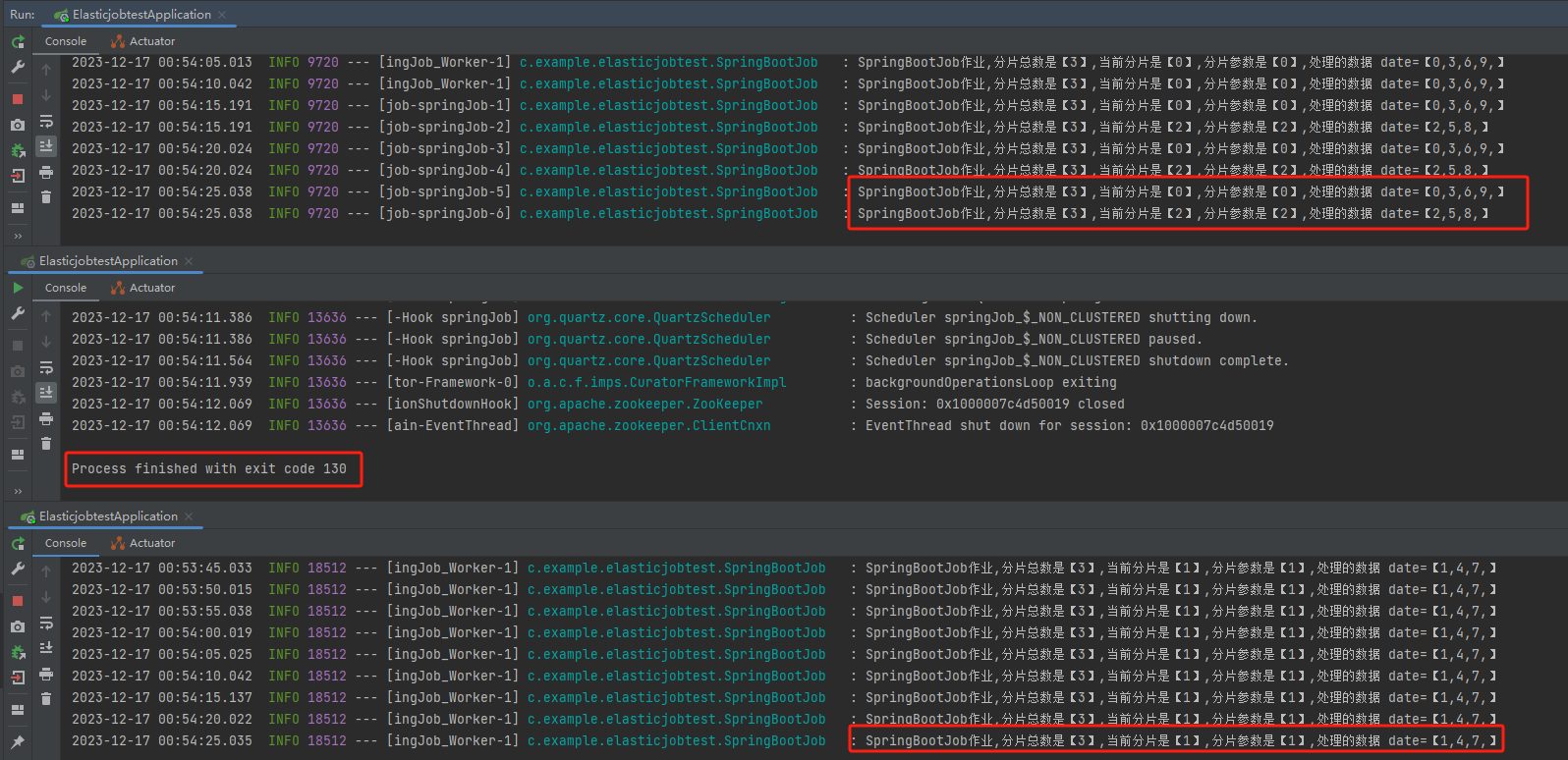
从日志可以看出来,数据并没有丢。
第一台机器把本来该在下线的这台服务器上处理的数据给接管了:
分片总数是【3】,当前分片是【2】,分片参数是【2】,处理的数据 date=【2,5,8,】
分片总数是【3】,当前分片是【0】,分片参数是【0】,处理的数据 date=【0,3,6,9,】
好了,到这里,基本功能就算演示完成,可以适当的响起一些掌声了。

啥原理啊?
其实关于原理,官方文档上也按照步骤进行了比较详细的说明:
https://shardingsphere.apache.org/elasticjob/current/cn/features/elastic/
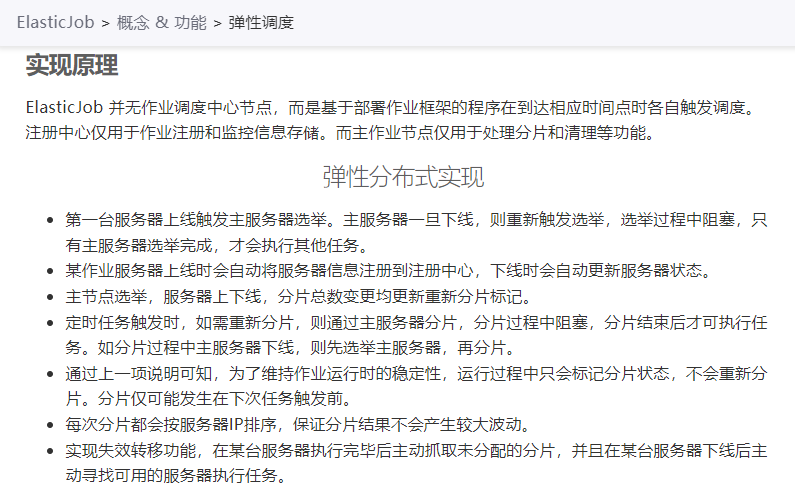
如果你不了解 zk 的大致工作原理、节点特性、监听机制啥的,后面肯定会看得比较懵逼。
所以需要先去补一下这方面的信息,对于这部分的描述和源码的解读有很大帮助。
如果你能大致理解 zk 的工作原理,那么整体读下来其实没有什么特别难以理解的地方,如果要深入理解每一个步骤的话,那肯定要读一下源码的。
步骤都有了,去找对应的源码,不就是按图索骥,手拿把掐的事情吗。
在阅读源码之前,还有一个非常重要的东西要铺垫一下,前面也说了:基于 zk 做的注册中心。
所以你必须要了解“注册中心的数据结构”是怎么样的,每个节点是干啥的,才能理解代码里面操作 zk 节点的时候,到底是什么含义。
关于注册中心的数据结构,文档上也有介绍:
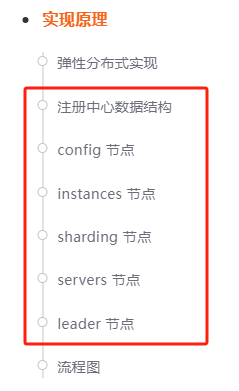
我觉得这个还是非常重要的,所以我多啰嗦几句,主要给你看看实际的数据是怎么样的。
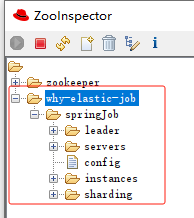
还是以我本地启动三个服务为例。
启动起来之后,看 zk 上注册了这些节点:
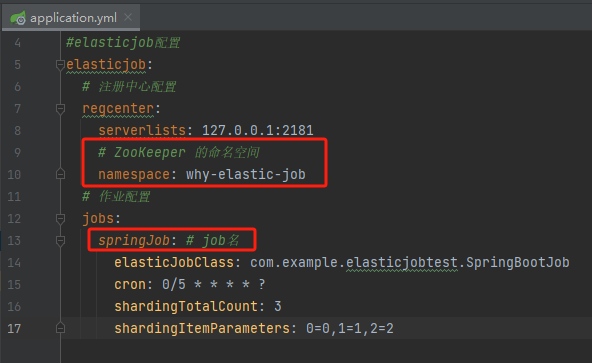
其中“why-elastic-job”和“springJob”分别是我们写在 application.yml 里面的 ZooKeeper 的命名空间和 Job 名称:
config 节点
config 节点里面是作业配置信息,以 YAML 格式存储:
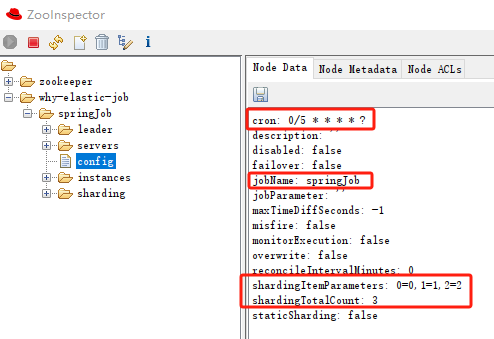
可以看到节点里面实际的值比我们配置的多,因为有很多默认项。每个默认项是干啥的,就自己去研究吧。
前面我说的“运行时修改”,就修改的是这个地方信息。
我为什么知道改这里?
还不是官网告诉我的。
instances 节点
该节点是作业运行实例信息,子节点是当前作业运行实例的主键。
作业运行实例主键由作业运行服务器的 IP 地址和 PID 构成。
作业运行实例主键均为临时节点,当作业实例上线时注册,下线时自动清理。注册中心可以监控这些节点的变化,来协调分布式作业的分片以及高可用。
具体到我们这个案例中,是这样的:
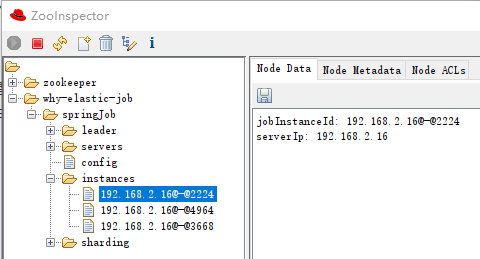
instances 下面有三个子节点,代表有三个微服务。
假设我停止运行一个服务,由于是 zk 的临时节点,这个地方就会变成 2 个:
sharding 节点
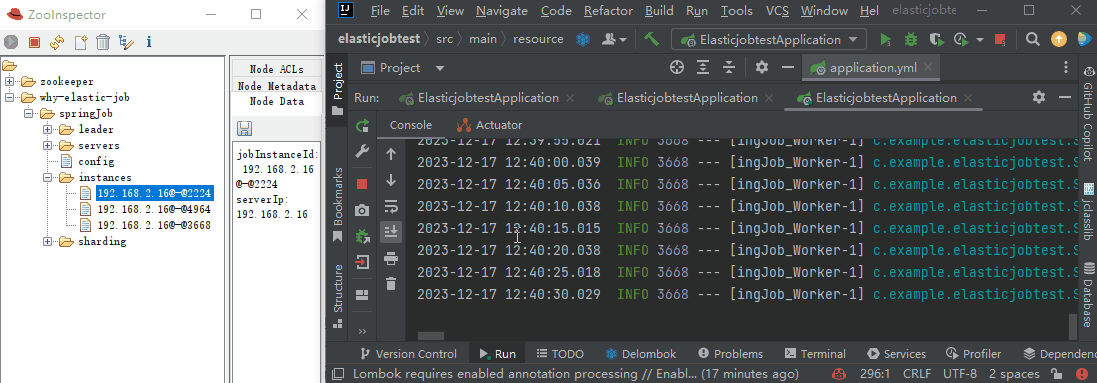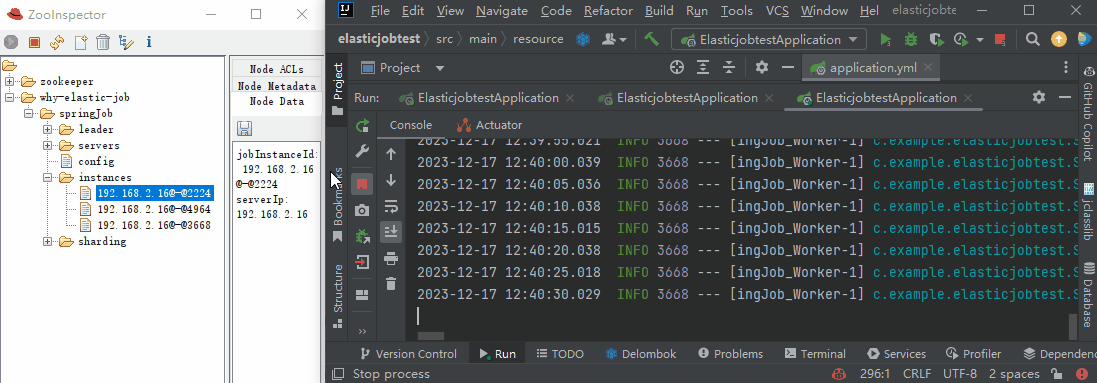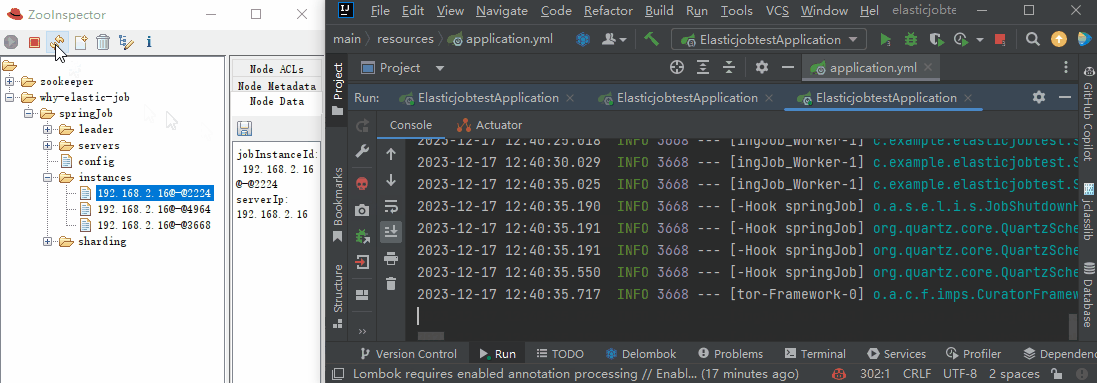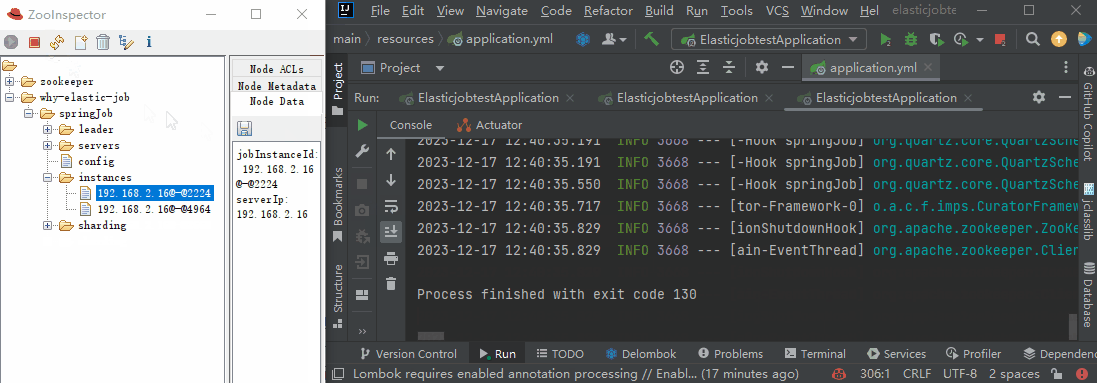
作业分片信息,子节点是分片项序号,从零开始,至分片总数减一。比如我们这里就是 0 到 2:
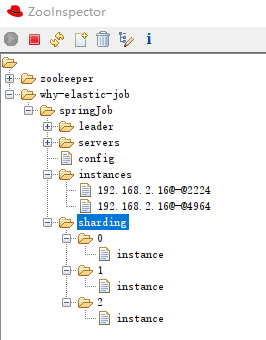
分片项序号的子节点存储详细信息,每个分片项下的子节点用于控制和记录分片运行状态:
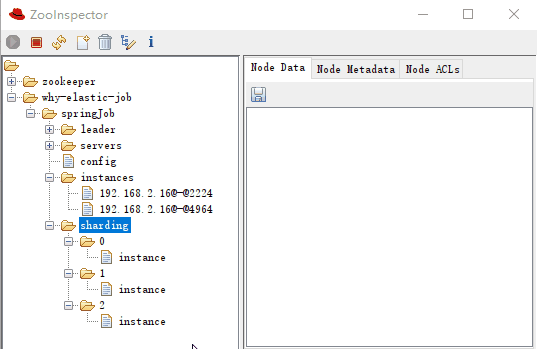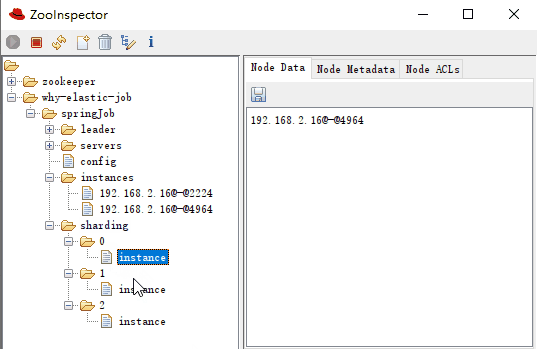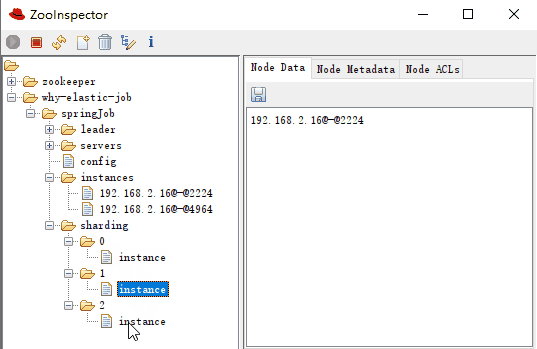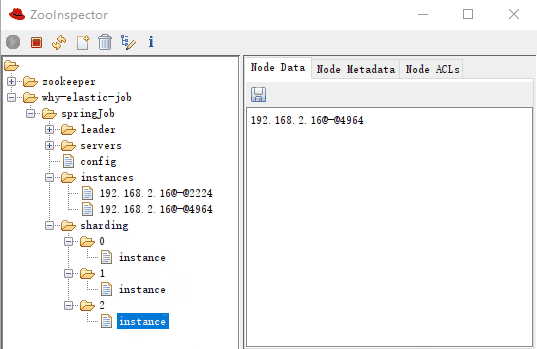
-
sharding-0-instance:192.168.2.16@-@4964 -
sharding-1-instance:192.168.2.16@-@2224 -
sharding-2-instance:192.168.2.16@-@4964
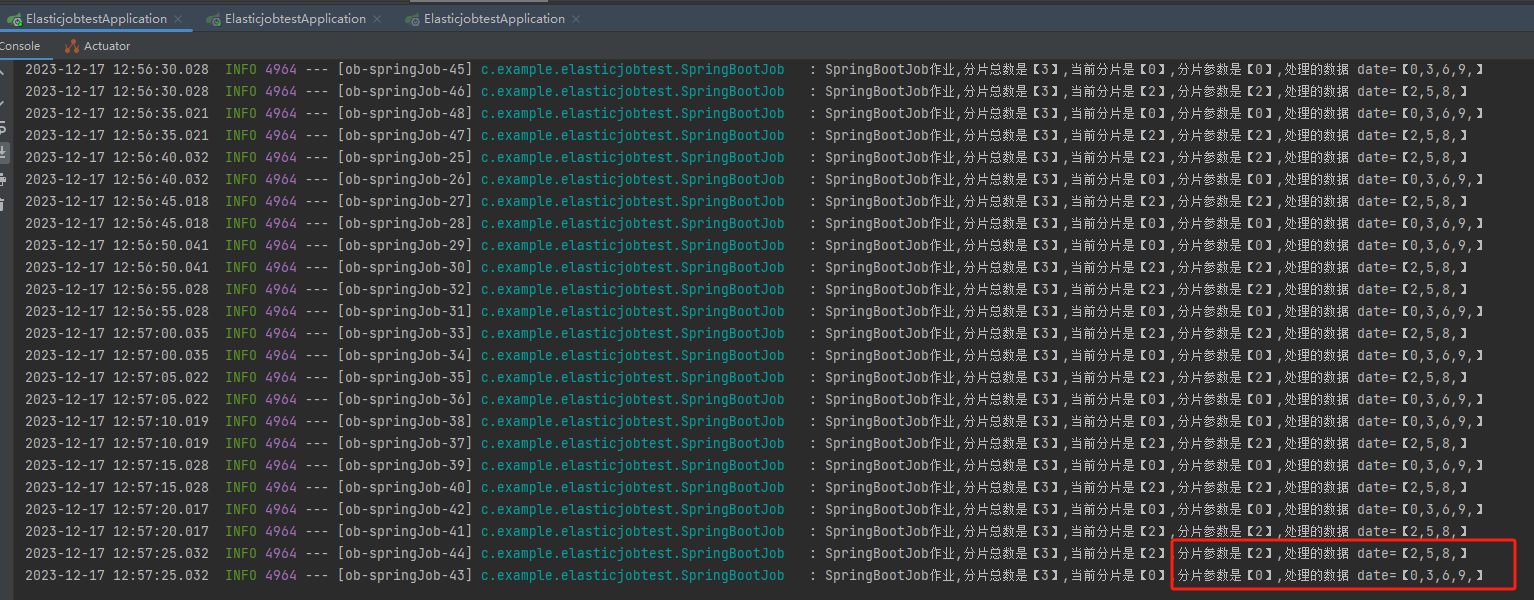
可以看到 0,2 分片是运行在同一个 instance 上的,这一点和日志是匹配的:
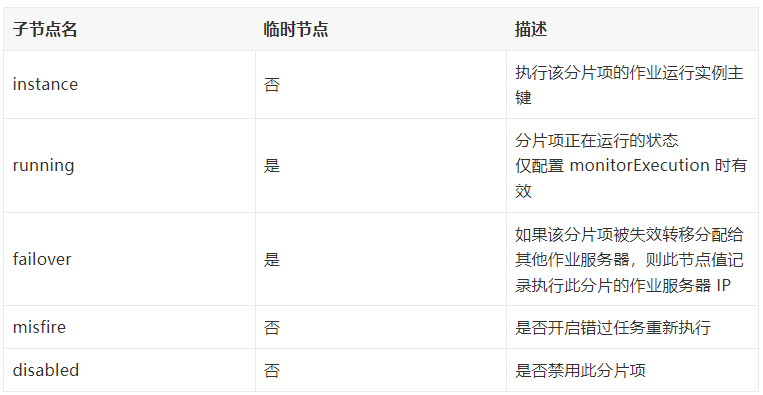
sharding 下除了 instance 节点外,可能还有其他的节点,详细信息说明如下:
servers 节点
作业服务器信息,子节点是作业服务器的 IP 地址。
可在 IP 地址节点写入 DISABLED 表示该服务器禁用。
在新的云原生架构下,servers 节点大幅弱化,仅包含控制服务器是否可以禁用这一功能。
为了更加纯粹的实现作业核心,servers 功能未来可能删除,控制服务器是否禁用的能力应该下放至自动化部署系统。
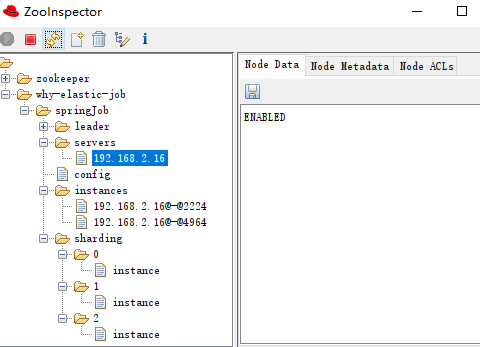
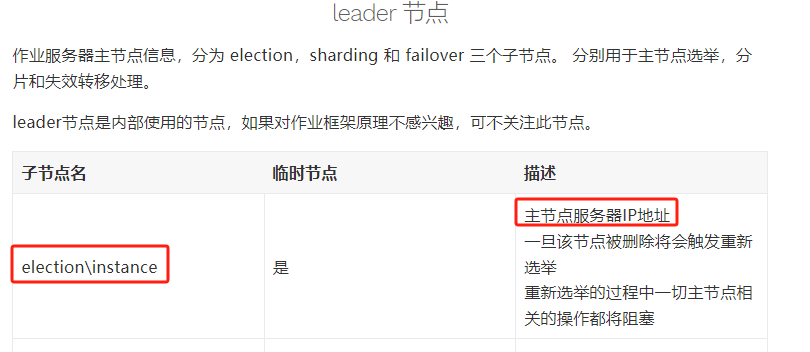
leader 节点
作业服务器主节点信息,下面有三个子节点:
-
election:用于主节点选举 -
sharding:用于分片 -
failover:用于失效转移处理
除了节点介绍外,在官网描述上有这样的一句话:
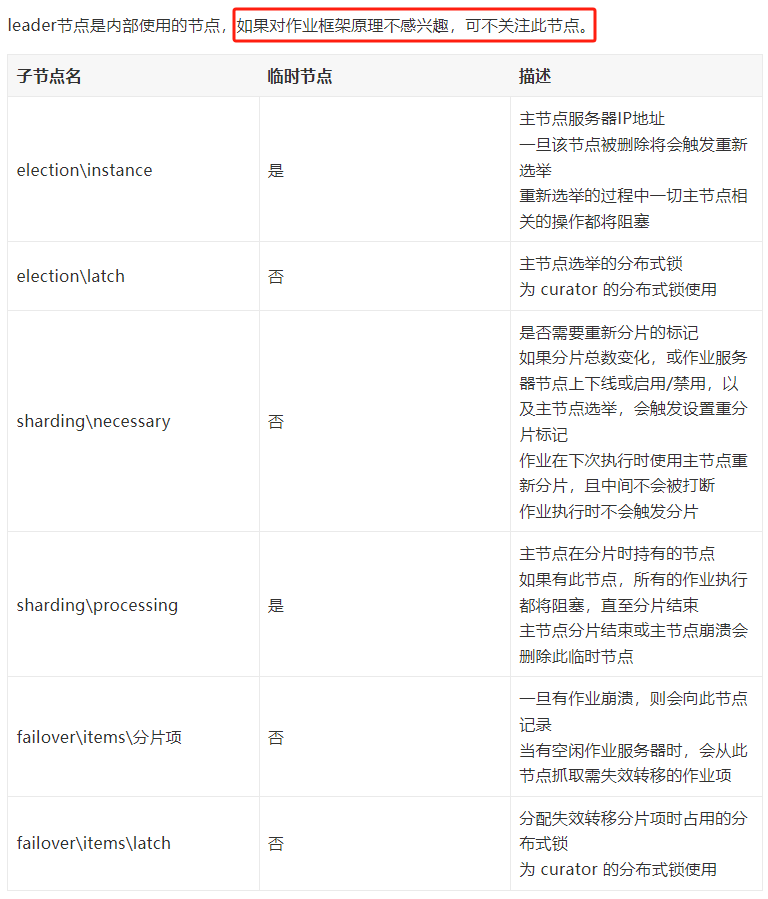
换句话说就是,如果你想了解作业,那这个节点是很重要的。看源码的时候,需要特别关注对于 leader 节点下的操作。
在我们的案例中,instance 里面的信息是这样的:
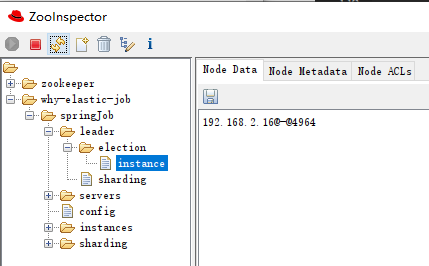
表示这个节点是主节点。
源码
知道了 zk 上每个节点的用处,看源码的时候比着看就行了。
源码比较多,歪师傅这里只能带着你做个非常简单的导读。
首先,因为很多逻辑都是基于 zk 节点在来做的,所以最重要的是各种各样的 zk 节点监听器,ElasticJob 在启动时,会执行这个方法,开启监听器:
org.apache.shardingsphere.elasticjob.kernel.internal.listener.ListenerManager#startAllListeners
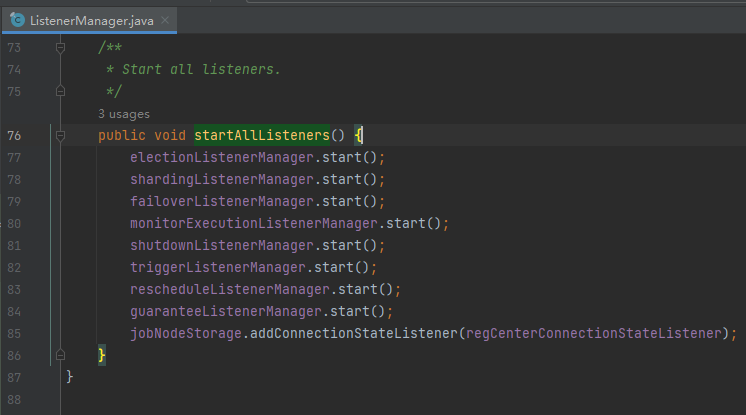
比如前面说的这个节点:
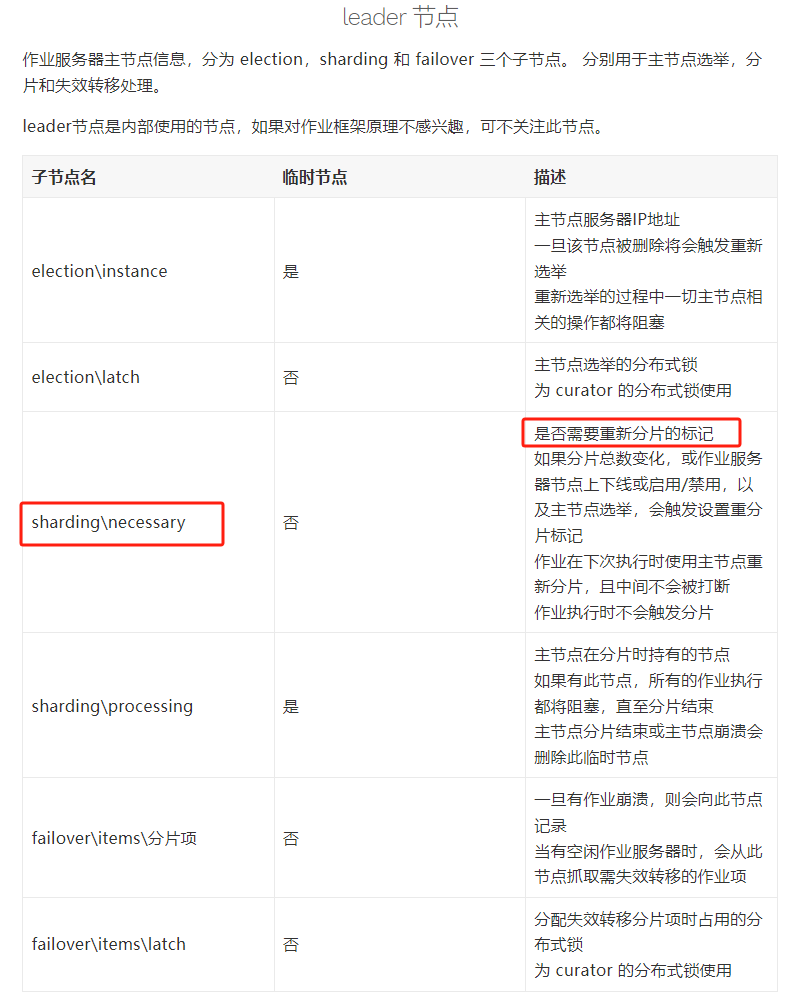
如果这个节点存在,则说明需要重新分片,对应的监听器是这个:
shardingListenerManager.start();
那么什么时候会触发“重新分片”呢?
-
如果分片总数变化,或作业服务器节点上下线或启用/禁用,以及主节点选举,会触发设置重分片标记 -
作业在下次执行时使用主节点重新分片,且中间不会被打断作业执行时不会触发分片
所以在 shardingListenerManager 监听器里面我们可以看到这两个逻辑:
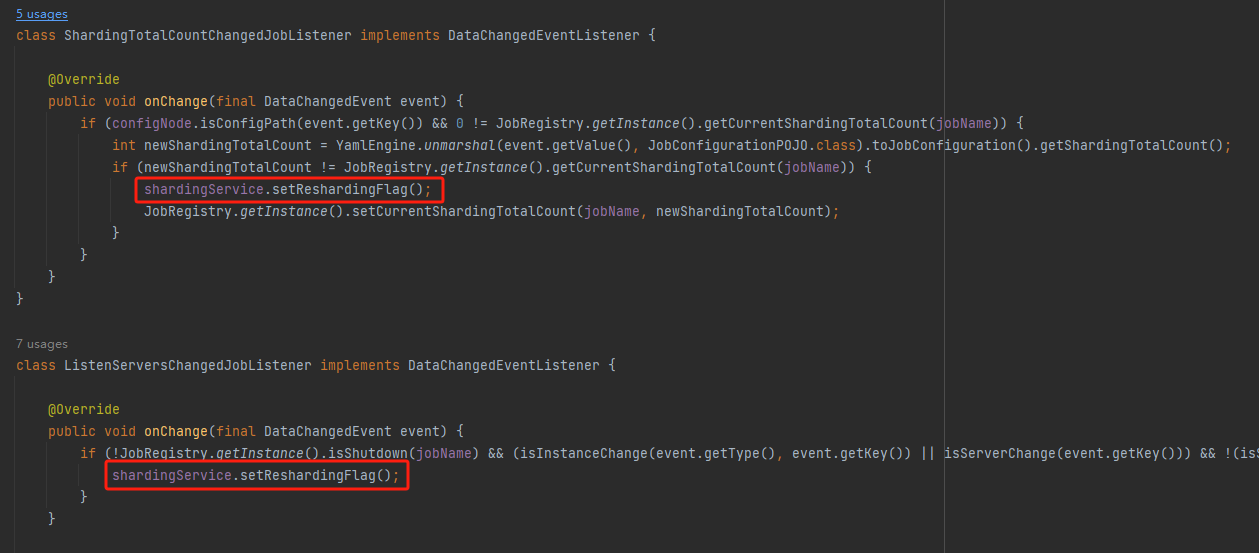
满足条件之后,就会执行设置重新分片标识的代码:
shardingService.setReshardingFlag();
该方法里面,创建了一个新的节点:
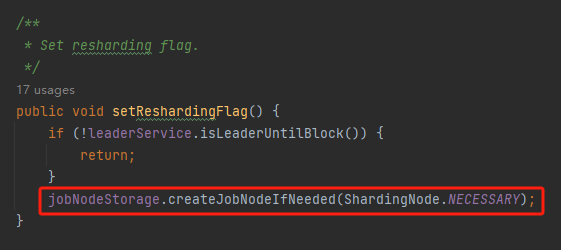
这个节点,就是它:
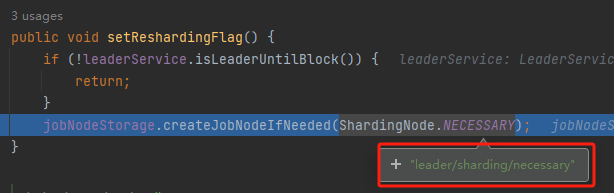
再比如,看看这个方法:
org.apache.shardingsphere.elasticjob.lite.internal.sharding.ShardingService#shardingIfNecessary
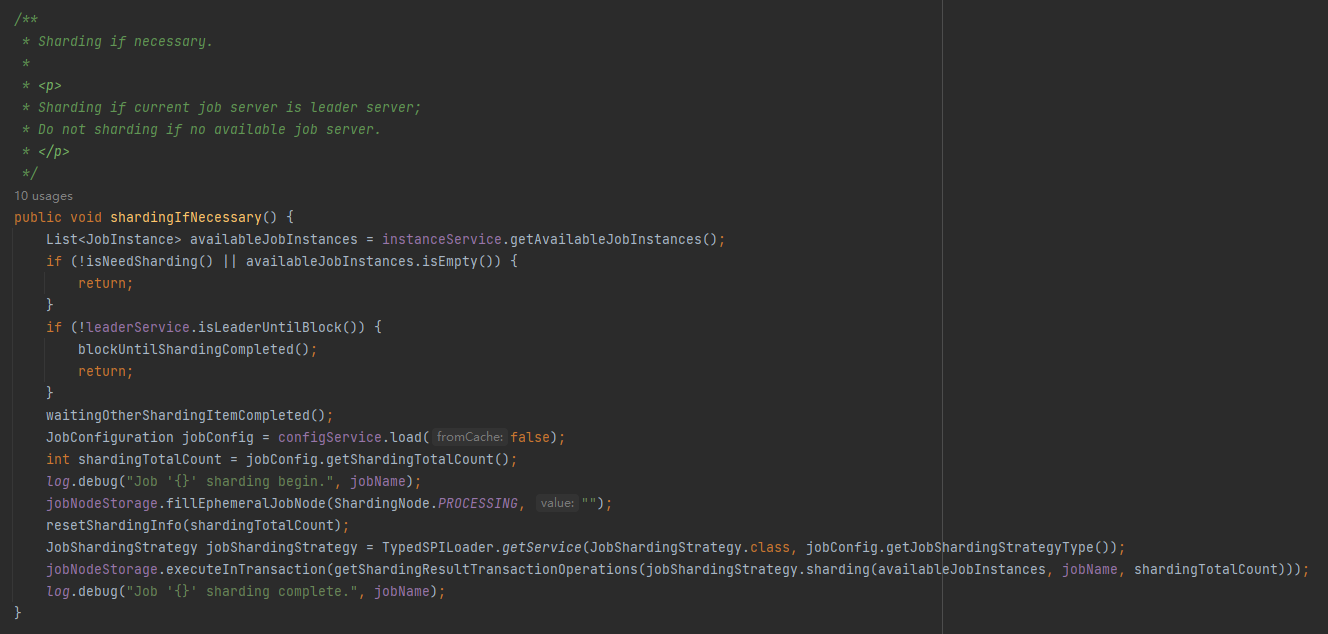
这个方法是做对作业进行分片逻辑的。
对作业进行分片,首先我们要知道当前有哪些实例在运行,对不对?
那怎么才能知道呢?
instances 节点请求出战:

shardingIfNecessary 方法的第一行逻辑就是读取 instances 节点下的数据:

获取到节点之后,是不是就可以分片了?
理论上是这样的,但是别着急,你看源码里面还有这样一个判断:
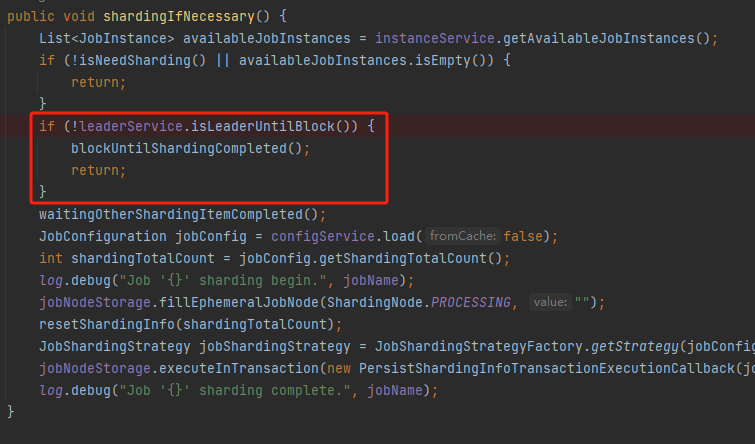
isLeaderUntilBlock,看方法名称也知道了,看看 Leader 节点是不是到位了,如果没到位,需要等一下 Leader 选举结束。
怎么判断 Leader 节点是不是到位了?
前面文档中说了,就是看这个节点是否存在:

对应到源码就是这样的:
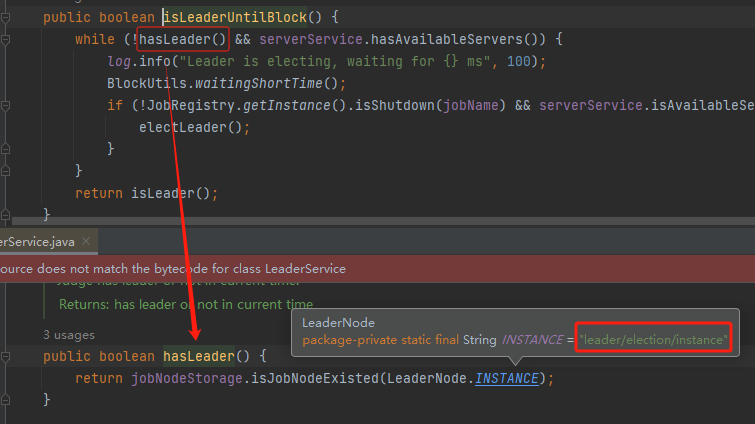
所以这就是我前面说的,你看源码的时候得结合 zk 节点的用途一起看,知道节点的用途就能理解源码里面操作节点的目的是什么。
然后,在这里多说一句。
shardingIfNecessary 这个方法是读取配置,处理分片逻辑的。
但是这个方法在每一个实例中都会运行,岂不是每个实例都会执行一次分片逻辑?
这样处理的话,由于多个地方执行分片逻辑,就需要考虑冲突和一致性的问题,导致逻辑非常的复杂。
虽然这个方法每个实例都会执行,但是其实只需要有一个实例执行分片逻辑就行了。
那么哪个节点来执行呢?
你肯定也猜到了,当然是主节点来干这个事儿嘛。如果当前节点不是主节点 return 就完事了:
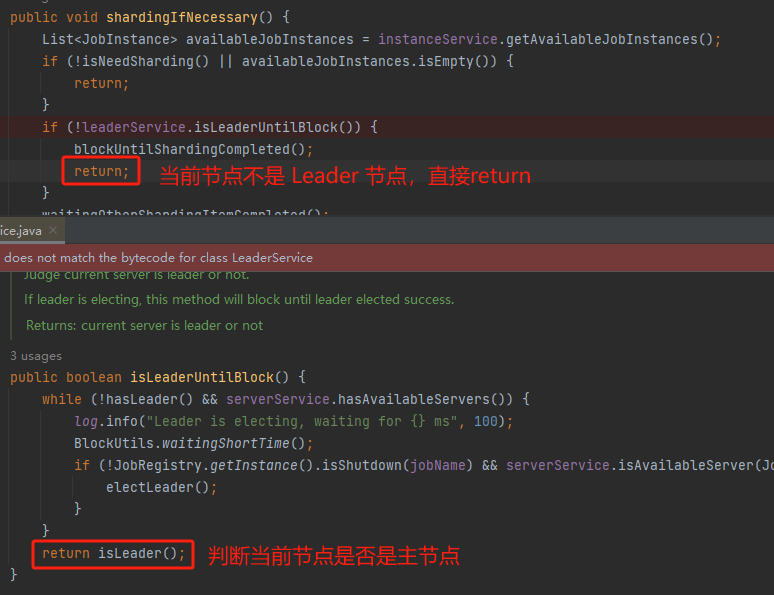
怎么看当前节点是否是主节点呢?
前面已经出现多次了,zk 里面记录着的:
如果当然节点是主节点,就接着往下执行,就是“作业分片策略”了:
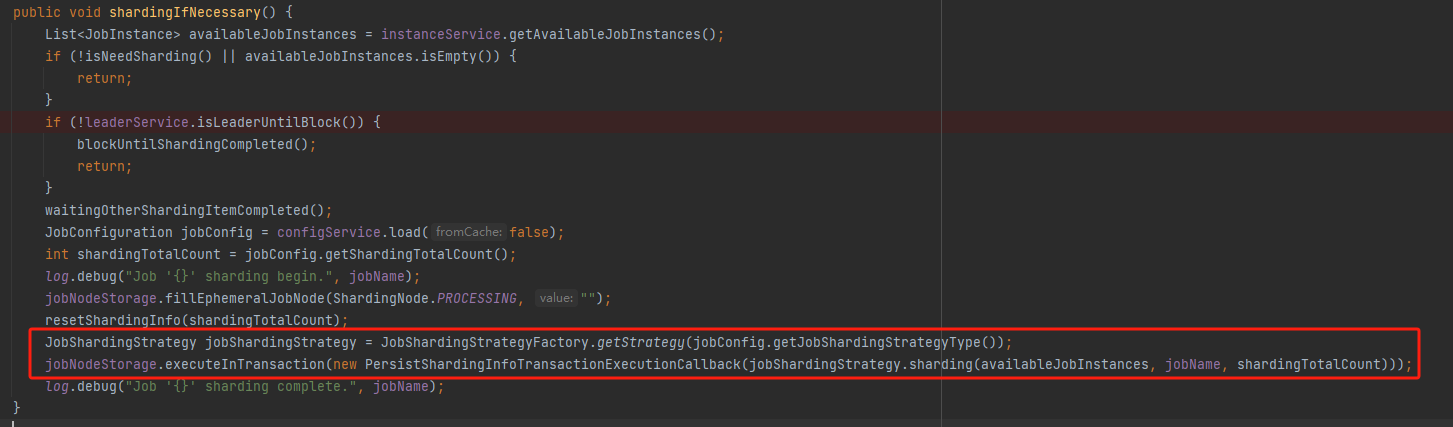
目前官方提供了三个不同的分片策略:

对应的实现类是这样的:

逻辑都非常简单,上手 Debug 两次就能摸清楚。
建议直接把项目拉下来,然后从测试用例入手。
好了,源码导读就到这里了。
我觉得我已经算是告诉你关于 ElasticJob 源码阅读的方式和注意点,如果你掌握到了,留言区留言“清晰”二字,支持一波。
如果你还是云里雾里的,没事,是我的问题。大胆的说出来:什么玩意?看求不懂。呸,垃圾作者。
如果你是第一次接触到 ElasticJob,那么读到这里的时候,你的内心关于 ElasticJob 应该还有很多疑问以及不清楚的细节。
很好,带着你的问题,去翻源码吧。
源码之下无秘密。
下面这个环节叫做[荒腔走板],技术文章后面我偶尔会记录、分享点生活相关的事情,和技术毫无关系。我知道看起来很突兀,但是我喜欢,因为这是一个普通博主的生活气息。
荒腔走板

这周终于是把《长安三万里》看了,之前一直想看,但是又被三个小时的时长劝退。
我个人觉得确实是值得豆瓣高分的。
看完之后,包括看的过程中,我老是想起之前在网上看到的一段话,关于“一颗子弹”和“教育闭环”的。
“一颗子弹”是指在《我与地坛》看到的一段书评,其内容是:一个人十三四岁的夏天,在路上捡到一支真枪,因为年少无知,天不怕地不怕,他扣下扳机。没有人死,也没有人受伤,他认为自己开了空枪。后来他三十岁或者更老,走在路上听到背后隐隐约约的风声。他停下来回过身去,子弹正中眉心。
“教育闭环”是指教育具有长期性和滞后性,起初你只能理解表层的道理,直到多年后的某个瞬间,你才能真正领悟到书上知识的真谛,此时教育的任务才算真正完成。
我小时候读到“两岸猿声啼不住,轻舟已过万重山”的时候,重点总是在“两岸猿声”上,想象着猿猴的叫声是什么样的,那是一番怎样有趣的画面。
后来,甚至可以说是今年,这个电影上映之后,我才明白当年读书的时候我忽略的“轻舟已过万重山”背后才是有更加蜿蜒曲折、激动人心的故事。
这句诗就是当年的那一颗子弹,命中了马上三十岁的我,至此,教育才算完成了闭环。
今年,让我产生同样感受的,还有当年完全忽略的这句话:孔乙己是站着喝酒而穿长衫的唯一的人穿的虽然是长衫,可是又脏又破似平十多年没有补,也没有洗。他对人说话,总是满口之乎者也叫人半懂不懂的。
此外,电影中多次提到“长安”,虽然我们学的是同样的课本,读的是一样的诗,但是每个人对与“长安”的认知和理解是不一样的。
现在提到长安,我脑海中出现的第一个画面永远是当年看《河西走廊》纪录片的时候那一个画面。
第一集《使者》,张骞出使西域,被匈奴囚禁九年后同随从堂邑父出逃,继续西行。
靠强大意志力穿越塔克拉玛干沙漠和帕米尔高原,到达西域。回程再次被俘,数年后带匈奴妻子和堂邑父又一次出逃东归。
十三年后,终于再次望到长安城,张骞匍匐在地,长跪不起。
西北望长安,可怜无数山。
这一跪,看的我眼泪婆娑。
服务器托管,北京服务器托管,服务器租用 http://www.fwqtg.net
机房租用,北京机房租用,IDC机房托管, http://www.fwqtg.net
